Systematic country allocation for dollar-based equity investors #
Get packages and JPMaQS data #
Get packages #
import os
# Retrieve credentials
client_id: str = os.getenv("DQ_CLIENT_ID")
client_secret: str = os.getenv("DQ_CLIENT_SECRET")
# Define any Proxy settings required (http/https)
PROXY = {}
START_DATE = "1995-01-01"
import tqdm
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import warnings
import os
import gc
from datetime import date, datetime
from sklearn.linear_model import LinearRegression, Ridge
from sklearn.ensemble import RandomForestRegressor
from sklearn.pipeline import Pipeline
from sklearn.metrics import make_scorer, mean_squared_error
import macrosynergy.management as msm
import macrosynergy.panel as msp
import macrosynergy.signal as mss
import macrosynergy.pnl as msn
import macrosynergy.learning as msl
import macrosynergy.visuals as msv
from macrosynergy.panel.cross_asset_effects import cross_asset_effects
from macrosynergy.panel.panel_imputer import MeanPanelImputer
from macrosynergy.panel.adjust_weights import adjust_weights
from macrosynergy.download import JPMaQSDownload
warnings.simplefilter("ignore")
This notebook uses macrosynergy package version 1.3.8dev0+28f8af1
Special convenience functions for this notebook #
# Wrapper for SignalOptimizer class
def run_single_signal_optimizer(
df: pd.DataFrame,
xcats: list,
cids: list,
blacklist,
signal_freq: str,
signal_name: str,
models: dict,
hyperparameters: dict,
learning_config: dict,
) -> tuple:
"""
Wrapping function around msl.SignalOptimizer for a given set of models and hyperparameters
"""
assert set(models.keys()) == set(hyperparameters.keys()), "The provided pair of model and grid names do not match."
required_config = ["scorer", "splitter", "test_size", "min_cids", "min_periods", "split_functions"]
assert all([learning_config.get(x, None) is not None for x in required_config])
so = msl.SignalOptimizer(
df=df,
xcats=xcats,
cids=cids,
blacklist=blacklist,
freq=signal_freq,
lag=1,
xcat_aggs=["last", "sum"],
)
so.calculate_predictions(
name=signal_name,
models=models,
scorers=learning_config.get("scorer"),
hyperparameters=hyperparameters,
inner_splitters=learning_config.get("splitter"),
test_size=learning_config.get("test_size"),
min_cids=learning_config.get("min_cids"),
min_periods=learning_config.get("min_periods"),
n_jobs_outer=-1,
split_functions=learning_config.get("split_functions"),
)
# cleanup
gc.collect()
return so
Get data from JPMaQS #
# Cross-sections of interest - equity markets
cids_dmeq = [
'AUD',
'CAD',
'CHF',
'EUR',
'GBP',
'JPY',
'SEK',
'SGD',
'USD',
]
cids_emeq = [
'BRL',
'CNY',
'INR',
'KRW',
'MXN',
'MYR',
'PLN',
'THB',
'TWD',
'ZAR'
]
cids_eq = sorted(cids_dmeq + cids_emeq)
# Category tickers
inf = (
[
f"{cat}_{at}"
for cat in [
"CPIXFE",
"CPIH",
]
for at in [
"SJA_P3M3ML3AR",
"SJA_P1Q1QL1AR",
"SA_P1M1ML12",
"SA_P1Q1QL4",
]
]
+ ["INFTEFF_NSA"]
)
cons = [
f"{cat}_{at}"
for cat in ["RPCONS", "RRSALES"]
for at in [
"SA_P3M3ML3AR",
"SA_P1Q1QL1AR",
"SA_P1M1ML12",
"SA_P1Q1QL4",
]
]
surveys = [
f"{cat}_{at}"
for cat in ["CCSCORE", "MBCSCORE"]
for at in [
"SA",
"SA_D3M3ML3",
"SA_D1Q1QL1",
"SA_D1M1ML12",
"SA_D1Q1QL4",
]
]
labour = [
"UNEMPLRATE_NSA_3MMA_D1M1ML12",
"UNEMPLRATE_NSA_D1Q1QL4",
"UNEMPLRATE_SA_3MMAv5YMA",
]
liquid = ["INTLIQGDP_NSA_D1M1ML3", "INTLIQGDP_NSA_D1M1ML6"]
flows = [
f"{flow}_NSA_D1M1ML12" for flow in ["NIIPGDP", "IIPLIABGDP"]
]
trade = (
[
f"{cat}_{at}"
for cat in ["CABGDPRATIO", "MTBGDPRATIO"]
for at in [
"SA_3MMAv60MMA",
"SA_1QMAv20QMA",
"NSA_12MMA",
"NSA_1YMA",
]
]
)
fxrel = [
f"{cat}_NSA_{t}"
for cat in ["REEROADJ", "CTOT"]
for t in ["P1W4WL1", "P1M1ML12", "P1M12ML1"]
] + [f"PPPFXOVERVALUE_NSA_{t}" for t in ["P1M12ML1"]]
fin = [
"RIR_NSA",
"RYLDIRS02Y_NSA",
"RYLDIRS05Y_NSA",
"EQCRR_VT10",
]
add = [
"RGDP_SA_P1Q1QL4_20QMM",
]
eco = (
inf
+ cons
+ labour
+ surveys
+ liquid
+ flows
+ trade
+ fxrel
+ fin
+ add
)
mkt = [
"EQXR_NSA",
"EQXR_VT10",
"FXXRUSD_NSA",
"EQXRxEASD_NSA",
"EQCALLRUSD_NSA",
"EQCALLXRxEASD_NSA", # Support for eq futures vol
"FXXRUSDxEASD_NSA",
"FXTARGETED_NSA",
"FXUNTRADABLE_NSA",
]
xcats = eco + mkt
# Resultant indicator tickers
tickers = [cid + "_" + xcat for cid in cids_eq for xcat in xcats] + ["USD_DU05YXR_NSA", "GLD_COXR_NSA"]
print(f"Maximum number of tickers is {len(tickers)}")
Maximum number of tickers is 1199
# Download from DataQuery
with JPMaQSDownload(
client_id=client_id, client_secret=client_secret
) as downloader:
df: pd.DataFrame = downloader.download(
tickers=tickers,
start_date=START_DATE,
metrics=["value"],
suppress_warning=True,
show_progress=True,
report_time_taken=True,
proxy=PROXY,
)
Downloading data from JPMaQS.
Timestamp UTC: 2025-09-19 14:51:45
Connection successful!
Requesting data: 100%|█████████████████████████████████████████████████████████████████| 60/60 [00:12<00:00, 4.88it/s]
Downloading data: 100%|████████████████████████████████████████████████████████████████| 60/60 [00:41<00:00, 1.46it/s]
Time taken to download data: 56.79 seconds.
Some expressions are missing from the downloaded data. Check logger output for complete list.
343 out of 1199 expressions are missing. To download the catalogue of all available expressions and filter the unavailable expressions, set `get_catalogue=True` in the call to `JPMaQSDownload.download()`.
dfx = df.copy()
Availability and pre-processing #
Data cleaning and renaming #
# Removing Australia and New Zealand CPI multiple transformation frequencies - maintaining monthly version now
dfx = dfx.loc[
~(
(dfx["cid"].isin(["AUD", "NZD"])) & (dfx["xcat"].isin(inf)) & (dfx["xcat"].str.contains("Q"))
)
]
# Replace quarterly tickers with approximately equivalent monthly tickers
dict_repl = {
"CPIXFE_SJA_P1Q1QL1AR": "CPIXFE_SJA_P3M3ML3AR",
"CPIXFE_SA_P1Q1QL4": "CPIXFE_SA_P1M1ML12",
"CPIH_SJA_P1Q1QL1AR": "CPIH_SJA_P3M3ML3AR",
"CPIH_SA_P1Q1QL4": "CPIH_SA_P1M1ML12",
"UNEMPLRATE_NSA_D1Q1QL4":"UNEMPLRATE_NSA_3MMA_D1M1ML12",
"RPCONS_SA_P1Q1QL4": "RPCONS_SA_P1M1ML12",
"RPCONS_SA_P1Q1QL1AR": "RPCONS_SA_P3M3ML3AR",
"RRSALES_SA_P1Q1QL1AR": "RRSALES_SA_P3M3ML3AR",
"RRSALES_SA_P1Q1QL4": "RRSALES_SA_P1M1ML12",
"CCSCORE_SA_D1Q1QL1": "CCSCORE_SA_D3M3ML3",
"MBCSCORE_SA_D1Q1QL1": "MBCSCORE_SA_D3M3ML3",
"SBCSCORE_SA_D1Q1QL1": "SBCSCORE_SA_D3M3ML3",
"CCSCORE_SA_D1Q1QL4": "CCSCORE_SA_D1M1ML12",
"MBCSCORE_SA_D1Q1QL4": "MBCSCORE_SA_D1M1ML12",
"SBCSCORE_SA_D1Q1QL4": "SBCSCORE_SA_D1M1ML12",
"CABGDPRATIO_SA_1QMAv20QMA": "CABGDPRATIO_SA_3MMAv60MMA",
"CABGDPRATIO_NSA_1YMA": "CABGDPRATIO_NSA_12MMA",
"MTBGDPRATIO_NSA_1YMA": "MTBGDPRATIO_NSA_12MMA",
}
dfx["xcat2"] = dfx["xcat"].map(dict_repl).fillna(dfx["xcat"])
dfx = dfx.drop(columns="xcat").rename(columns={"xcat2": "xcat"})
Availability before and after renaming #
xcatx = inf
msm.check_availability(df=df, xcats=xcatx, cids=cids_eq, missing_recent=False)
msm.check_availability(df=dfx, xcats=sorted(list(set(xcatx) - set(dict_repl.keys()))), cids=cids_eq, missing_recent=False)

xcatx = surveys
msm.check_availability(df=df, xcats=xcatx, cids=cids_eq, missing_recent=False)
msm.check_availability(df=dfx, xcats=sorted(list(set(xcatx) - set(dict_repl.keys()))), cids=cids_eq, missing_recent=False)

xcatx = labour
msm.check_availability(df=df, xcats=xcatx, cids=cids_eq, missing_recent=False)
msm.check_availability(df=dfx, xcats=sorted(list(set(xcatx) - set(dict_repl.keys()))), cids=cids_eq, missing_recent=False)


xcatx = flows
msm.check_availability(df=dfx, xcats=xcatx, cids=cids_eq, missing_recent=False)

xcatx = trade
msm.check_availability(df=df, xcats=xcatx, cids=cids_eq, missing_recent=False)
msm.check_availability(df=dfx, xcats=sorted(list(set(xcatx) - set(dict_repl.keys()))), cids=cids_eq, missing_recent=False)


xcatx = mkt + add
msm.check_availability(df=dfx, xcats=xcatx, cids=cids_eq, missing_recent=False)
# Initiate dictionary for conceptual factors
concept_factors = {}
Blacklisting #
Before running the analysis, we use
make_blacklist()
helper function from
macrosynergy
package, which creates a standardized dictionary of blacklist periods, i.e. periods that affect the validity of an indicator, based on standardized panels of binary categories.
Put simply, this function allows converting category variables into blacklist dictionaries that can then be passed to other functions. Below, we picked two indicators for FX tradability and flexibility.
FXTARGETED_NSA
is an exchange rate target dummy, which takes a value of 1 if the exchange rate is targeted through a peg or any regime that significantly reduces exchange rate flexibility and 0 otherwise.
FXUNTRADABLE_NSA
is also a dummy variable that takes the value one if liquidity in the main FX forward market is limited or there is a distortion between tradable offshore and untradable onshore contracts.
# Binary flag from JPMaQS
fxuntrad = ["FXUNTRADABLE_NSA"]
fxuntrad = dfx[dfx["xcat"].isin(fxuntrad)].loc[:, ["cid", "xcat", "real_date", "value"]]
# Constructing a binary variable based on history availability of equity futures returns in local currency
equity_target = "EQXR_NSA"
eq_ret_availability = dfx.loc[dfx["xcat"] == equity_target].groupby(["cid"])["real_date"].min()
earliest_return = eq_ret_availability.min()
equntrad = pd.DataFrame(
{"value": 0},
index=pd.MultiIndex.from_product([cids_eq, pd.date_range(start=earliest_return, end=datetime.today().date(), freq="B")], names=["cid", "real_date"])
).reset_index(drop=False).assign(
xcat="EQUNTRADABLE_NSA"
)
equntrad["eqxr_start"] = equntrad["cid"].map(eq_ret_availability)
mask = pd.to_datetime(equntrad["real_date"]) <= pd.to_datetime(equntrad["eqxr_start"])
equntrad.loc[mask, "value"] = 1.0
# Combining the two
total_untrad = pd.concat([fxuntrad, equntrad], axis=0, ignore_index=True).sort_values(["cid", "xcat", "real_date"])
# Create blacklisting dictionary
equsdblack = (
total_untrad.groupby(["cid", "real_date"])
.aggregate(value=pd.NamedAgg(column="value", aggfunc="max"))
.reset_index()
)
equsdblack["xcat"] = "EQUSDBLACK"
equsdblack = msp.make_blacklist(equsdblack, "EQUSDBLACK")
equsdblack
{'AUD': (Timestamp('1995-01-02 00:00:00'), Timestamp('2000-05-03 00:00:00')),
'BRL': (Timestamp('1995-01-02 00:00:00'), Timestamp('1995-03-01 00:00:00')),
'CAD': (Timestamp('1995-01-02 00:00:00'), Timestamp('1999-11-24 00:00:00')),
'CHF': (Timestamp('1995-01-02 00:00:00'), Timestamp('1995-01-02 00:00:00')),
'CNY': (Timestamp('1995-01-02 00:00:00'), Timestamp('2010-04-19 00:00:00')),
'EUR': (Timestamp('1995-01-02 00:00:00'), Timestamp('1998-06-23 00:00:00')),
'GBP': (Timestamp('1995-01-02 00:00:00'), Timestamp('1995-01-02 00:00:00')),
'INR': (Timestamp('1995-01-02 00:00:00'), Timestamp('2000-09-26 00:00:00')),
'JPY': (Timestamp('1995-01-02 00:00:00'), Timestamp('1995-01-02 00:00:00')),
'KRW': (Timestamp('1995-01-02 00:00:00'), Timestamp('1996-05-06 00:00:00')),
'MXN': (Timestamp('1995-01-02 00:00:00'), Timestamp('1999-12-02 00:00:00')),
'MYR_1': (Timestamp('1995-01-02 00:00:00'), Timestamp('1995-12-18 00:00:00')),
'MYR_2': (Timestamp('2018-07-02 00:00:00'), Timestamp('2025-09-18 00:00:00')),
'PLN': (Timestamp('1995-01-02 00:00:00'), Timestamp('2013-09-24 00:00:00')),
'SEK': (Timestamp('1995-01-02 00:00:00'), Timestamp('2005-02-16 00:00:00')),
'SGD': (Timestamp('1995-01-02 00:00:00'), Timestamp('1998-09-08 00:00:00')),
'THB_1': (Timestamp('1995-01-02 00:00:00'), Timestamp('2006-05-01 00:00:00')),
'THB_2': (Timestamp('2007-01-01 00:00:00'), Timestamp('2008-11-28 00:00:00')),
'TWD': (Timestamp('1995-01-02 00:00:00'), Timestamp('1998-07-22 00:00:00')),
'USD': (Timestamp('1995-01-02 00:00:00'), Timestamp('1995-01-02 00:00:00')),
'ZAR': (Timestamp('1995-01-02 00:00:00'), Timestamp('1995-01-02 00:00:00'))}
Feature engineering #
Auxiliary and benchmark categories #
# Stitching for India and China: extending consistent core with corresponding headline
cidx = ["INR", "CNY"]
merging_xcatx = {
"CPIXFE_SA_P1M1ML12": ["CPIXFE_SA_P1M1ML12", "CPIH_SA_P1M1ML12"],
"CPIXFE_SJA_P3M3ML3AR": ["CPIXFE_SJA_P3M3ML3AR", "CPIH_SJA_P3M3ML3AR"],
}
for new_cat, xcatx in merging_xcatx.items():
dfa = msm.merge_categories(df=dfx, xcats=xcatx, new_xcat=new_cat, cids=cidx)
dfx = msm.update_df(dfx, dfa)
# Benchmark categories used for several calculations
cidx = cids_eq
calcs = [
"INFTEBASIS = INFTEFF_NSA.clip(lower=2)",
"LTNGROWTH_SA = RGDP_SA_P1Q1QL4_20QMM + INFTEFF_NSA",
"LTNGROWTHBASIS_SA = RGDP_SA_P1Q1QL4_20QMM + INFTEBASIS",
]
dfa = msp.panel_calculator(dfx, calcs=calcs, cids=cidx)
dfx = msm.update_df(dfx, dfa)
# Extend equity volatility for countries with late-starting futures using cash indices
cidx = cids_eq
merging_xcatx = {
"EQXRxEASD_NSA_EXT": ["EQXRxEASD_NSA", "EQCALLXRxEASD_NSA",]
}
for new_cat, xcatx in merging_xcatx.items():
dfa = msm.merge_categories(df=dfx, xcats=xcatx, new_xcat=new_cat, cids=cidx)
dfx = msm.update_df(dfx, dfa)
# Pseudo U.S. series with logical zero values
cidx = ["USD"]
calcs = ["FXXRUSDxEASD_NSA = 0 * RIR_NSA",]
dfa = msp.panel_calculator(dfx, calcs=calcs, cids=cidx)
dfx = msm.update_df(dfx, dfa)
Excess inflation #
# Scaled excess inflation and changes thereof
cidx = cids_eq
calcs = [
# Centering the price trends around inflation target
f"X{cat}_{atf}S = ( {cat}_{atf} - INFTEFF_NSA ) / INFTEBASIS"
for cat in ["CPIXFE", "CPIH",]
for atf in ["SJA_P3M3ML3AR", "SA_P1M1ML12"]
]
dfa = msp.panel_calculator(dfx, calcs=calcs, cids=cidx)
dfx = msm.update_df(dfx, dfa)
# All constituents, signs, and weights
xinf = {
"XCPIXFE_SJA_P3M3ML3ARS": {"eq_sign": -1, "fx_sign": 1, "weight": 1 / 4},
"XCPIXFE_SA_P1M1ML12S": {"eq_sign": -1, "fx_sign": 1, "weight": 1 / 4},
"XCPIH_SJA_P3M3ML3ARS": {"eq_sign": -1, "fx_sign": 1, "weight": 1 / 4},
"XCPIH_SA_P1M1ML12S": {"eq_sign": -1, "fx_sign": 1, "weight": 1 / 4},
}
# Differentials to USD
xcatx = list(xinf.keys())
cidx = cids_eq
for xc in xcatx:
dfa = msp.make_relative_value(
dfx,
xcats=xcatx,
cids=cidx,
basket=["USD"], # basket does not use all cross-sections
rel_meth="subtract",
postfix="vUSD",
)
dfx = msm.update_df(df=dfx, df_add=dfa)
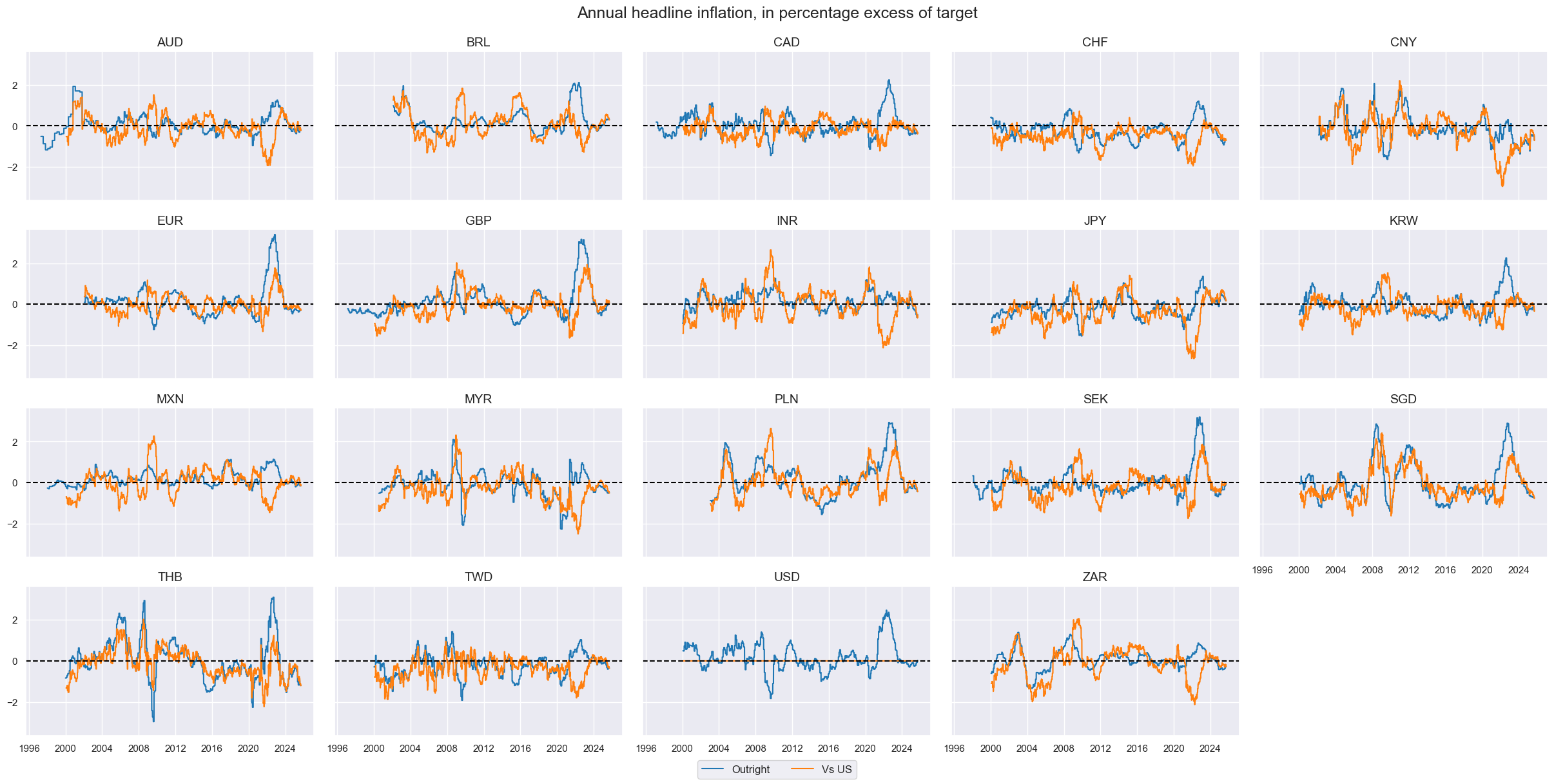
# Visualize
xcatx = ["XCPIH_SA_P1M1ML12S", "XCPIH_SA_P1M1ML12SvUSD"]
cidx = cids_eq
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=5,
start="1995-01-01",
same_y=True,
height=2,
title="Annual headline inflation, in percentage excess of target",
xcat_labels=[
"Outright",
"Vs US"
]
)
# Extract USD equity effects
cidx = cids_eq
for xc, params in xinf.items():
dfa = cross_asset_effects(
df=dfx,
cids=cidx,
effect_name=xc + "_F",
signal_xcats={"eq": xc, "fx": xc + "vUSD"},
weights_xcats={"eq": "EQXRxEASD_NSA_EXT", "fx": "FXXRUSDxEASD_NSA"},
signal_signs={k.replace("_sign", ""): v for k, v in params.items() if "sign" in k},
)
dfx = msm.update_df(dfx, dfa.loc[dfa["xcat"] == f"{xc}_F"])
# Visualize
xcatx = ["XCPIH_SA_P1M1ML12S", "XCPIH_SA_P1M1ML12S_F"]
cidx = cids_eq
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=5,
start="1995-01-01",
same_y=True,
height=2,
title="Annual headline inflation signals",
xcat_labels=["Simple", "Controlling for cross asset effects"]
)
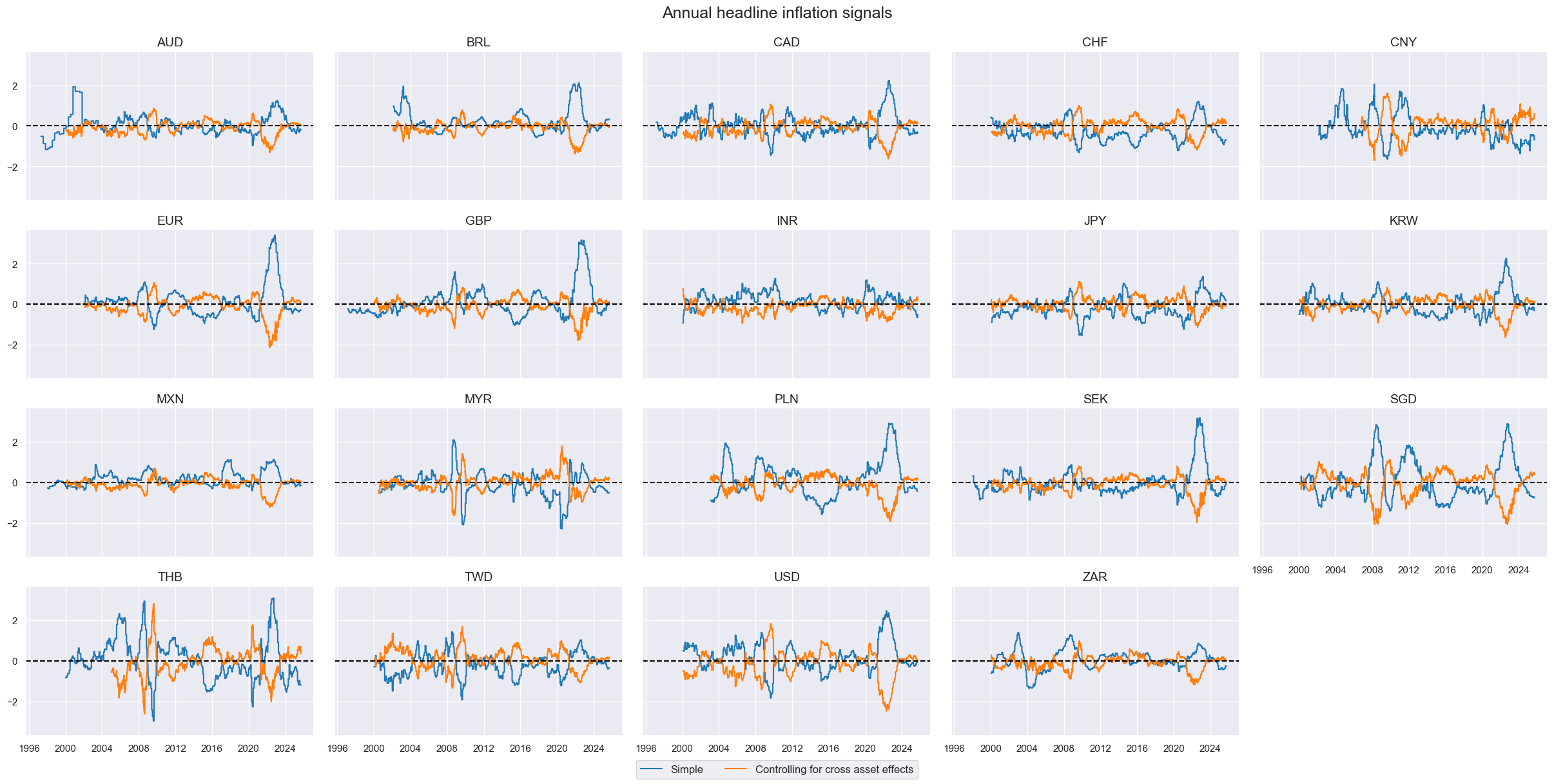
# Score the quantamental factors
xcatx = [xc + "_F" for xc in list(xinf.keys())]
cidx = cids_eq
for xc in xcatx:
dfa = msp.make_zn_scores(
dfx,
xcat=xc,
cids=cidx,
sequential=True,
min_obs=261 * 3,
neutral="zero",
pan_weight=1,
thresh=3,
postfix="ZN",
est_freq="m",
)
dfx = msm.update_df(dfx, dfa)
# Visualize
xcatx = ["XCPIH_SJA_P3M3ML3ARS_FZN", "XCPIH_SA_P1M1ML12S_FZN"]
cidx = cids_eq
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=5,
start="1995-01-01",
same_y=True,
height=2,
)
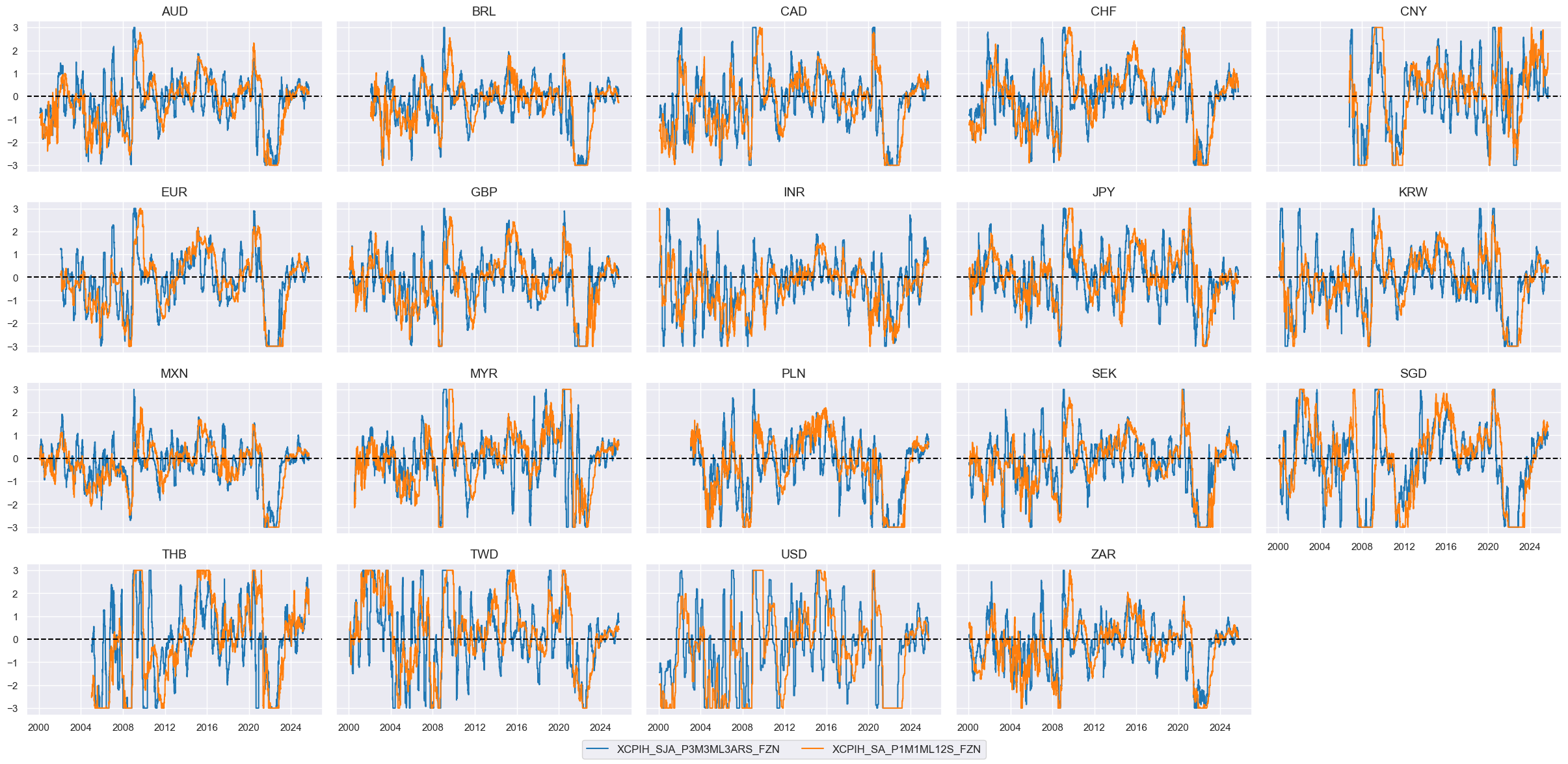
# Calculate the conceptual factor score
xcatx = [xc + "_FZN" for xc in list(xinf.keys())]
cidx = cids_eq
weights = [xinf[xc]["weight"] for xc in list(xinf.keys())]
cfs = "XINF"
dfa = msp.linear_composite(
df=dfx,
xcats=xcatx,
cids=cids_eq,
weights=weights,
new_xcat=cfs,
complete_xcats=False,
)
dfx= msm.update_df(dfx, dfa)
# Re-score
dfa = msp.make_zn_scores(
dfx,
xcat=cfs,
cids=cidx,
sequential=True,
min_obs=261 * 3,
neutral="zero",
pan_weight=1,
thresh=3,
postfix="_ZN",
est_freq="m",
)
dfx = msm.update_df(dfx, dfa)
concept_factors[cfs] = "Inflation effect"
# Visualize
cfs = "XINF"
xcatx = [cfs, f"{cfs}_ZN"]
cidx = cids_eq
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=5,
start="1995-01-01",
same_y=True,
height=2,
)
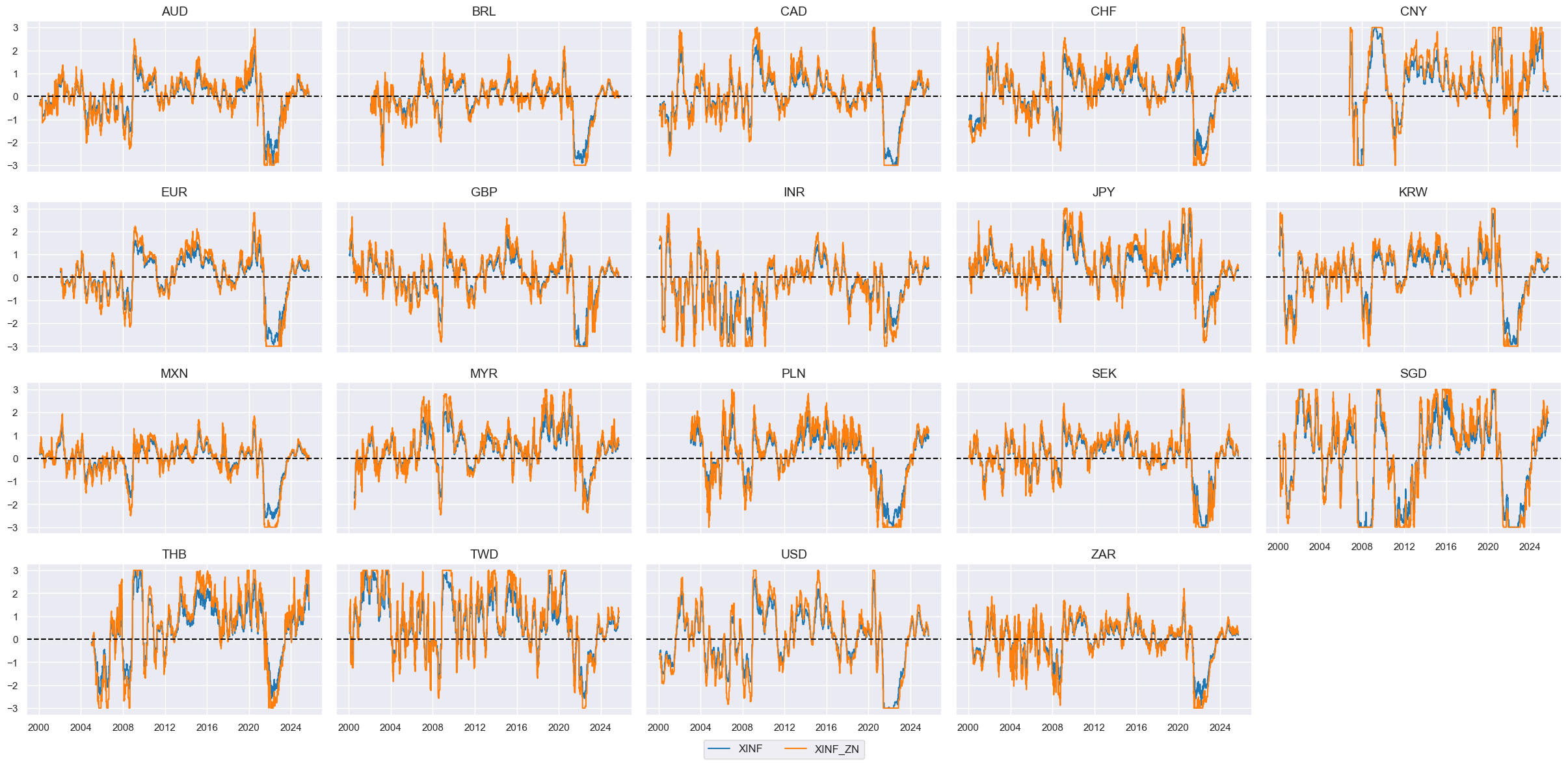
Currency weakness #
# Imputing PPP for USD
cidx = ["USD"]
calcs = [
f"PPPFXOVERVALUE_NSA_{t} = 0 * EQXR_VT10" for t in ["P1M12ML1"]
]
dfa = msp.panel_calculator(dfx, calcs=calcs, cids=cidx)
dfx = msm.update_df(dfx, dfa)
# TWD unavailable for this indicator (will only use REERs)
# All constituents, signs, and weights
fx_weak = {
'PPPFXOVERVALUE_NSA_P1M12ML1': {"eq_sign": -1, "fx_sign": -1, "weight": 3/6},
'REEROADJ_NSA_P1M12ML1': {"eq_sign": -1, "fx_sign": -1, "weight": 1/6},
'REEROADJ_NSA_P1M1ML12': {"eq_sign": -1, "fx_sign": -1, "weight": 1/6},
'REEROADJ_NSA_P1W4WL1': {"eq_sign": -1, "fx_sign": -1, "weight": 1/6},
}
# USD equity effects are indicators with appropriate signs
cidx = cids_eq
calcs = []
for xc, params in fx_weak.items():
s = "N" if params["eq_sign"] < 0 else ""
calcs.append(f"{xc}{s}_F = {xc} * {params["eq_sign"]}")
dfa = msp.panel_calculator(dfx, calcs=calcs, cids=cidx)
dfx = msm.update_df(dfx, dfa)
# Score the quantamental factors
postfixes = ["N" if v["eq_sign"] < 0 else "" for v in fx_weak.values()]
fx_weaks = [k + s + "_F" for k, s in zip(fx_weak.keys(), postfixes)]
xcatx = fx_weaks
cidx = cids_eq
for xc in xcatx:
dfa = msp.make_zn_scores(
dfx,
xcat=xc,
cids=cidx,
sequential=True,
min_obs=261 * 3,
neutral="zero",
pan_weight=1,
thresh=3,
postfix="ZN",
est_freq="m",
)
dfx = msm.update_df(dfx, dfa)
# Visualize
xcatx = [xc + "ZN" for xc in fx_weaks]
cidx = cids_eq
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=5,
start="1995-01-01",
same_y=True,
height=2,
)
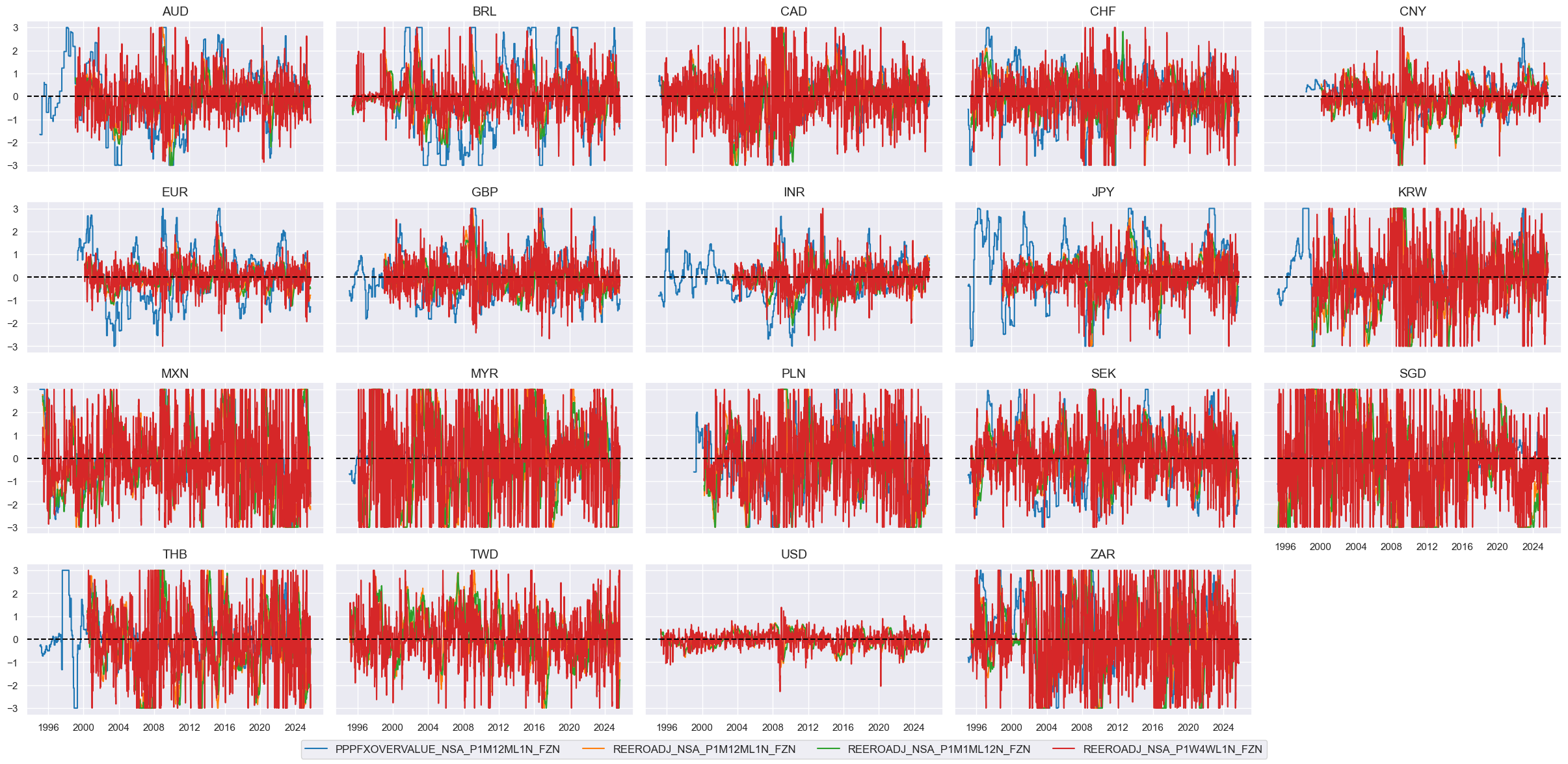
# Calculate the conceptual factor score
xcatx = [xc + "ZN" for xc in fx_weaks]
cidx = cids_eq
weights = [fx_weak[xc]["weight"] for xc in list(fx_weak.keys())]
cfs = "FXWEAK"
dfa = msp.linear_composite(
df=dfx,
xcats=xcatx,
cids=cids_eq,
weights=weights,
new_xcat=cfs,
complete_xcats=False,
)
dfx= msm.update_df(dfx, dfa)
# Re-score
dfa = msp.make_zn_scores(
dfx,
xcat=cfs,
cids=cidx,
sequential=True,
min_obs=261 * 3,
neutral="zero",
pan_weight=1,
thresh=3,
postfix="_ZN",
est_freq="m",
)
dfx = msm.update_df(dfx, dfa)
concept_factors[cfs] = "Currency weakness"
# Visualize
cfs = "FXWEAK"
xcatx = [cfs, f"{cfs}_ZN"]
cidx = cids_eq
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=5,
start="1995-01-01",
same_y=True,
height=2,
)
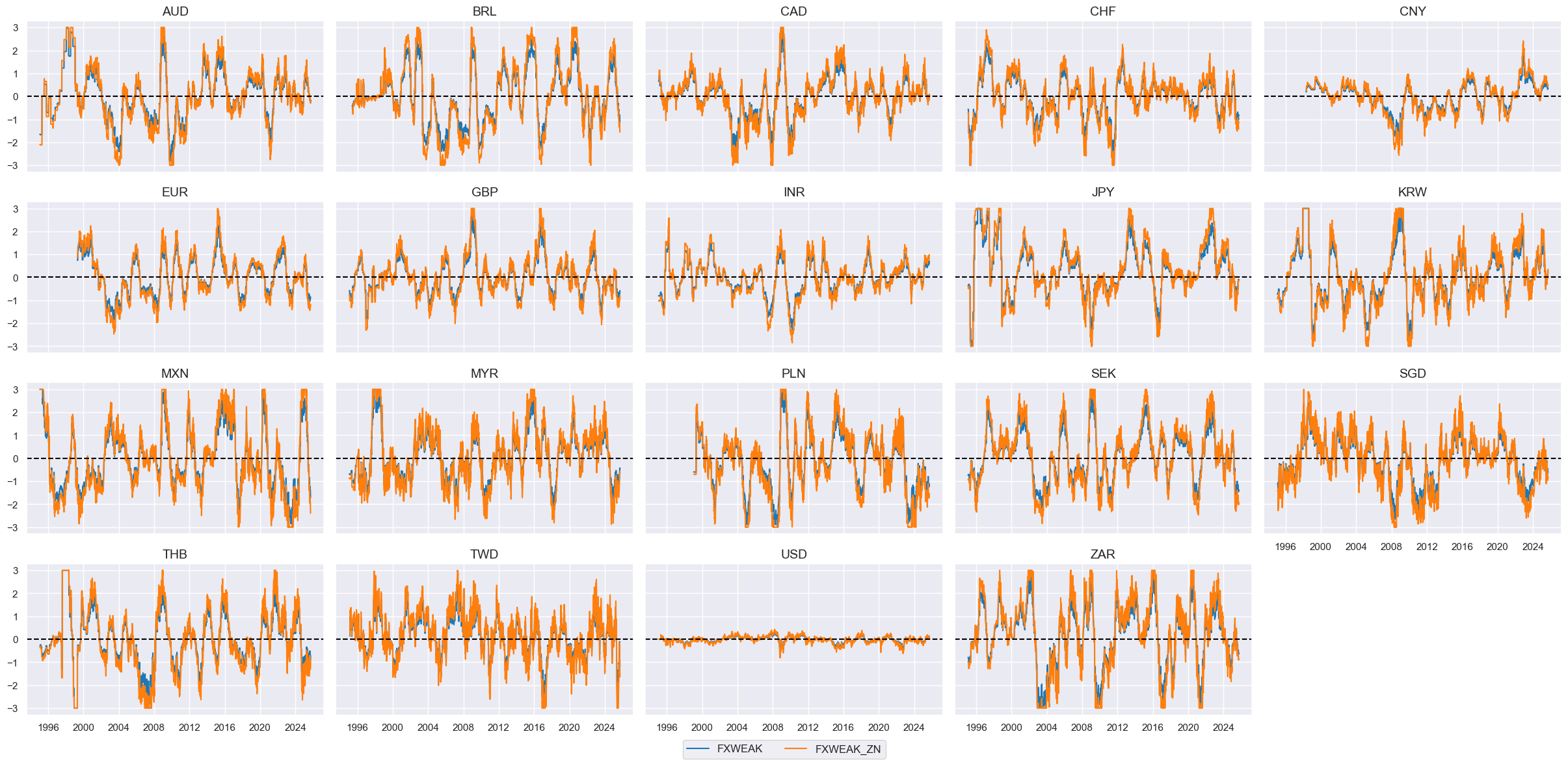
Terms-of-trade improvement #
# All constituents, signs, and weights
tot = {
'CTOT_NSA_P1M12ML1': {"eq_sign": 1, "fx_sign": 1, "weight": 1/3},
'CTOT_NSA_P1M1ML12': {"eq_sign": 1, "fx_sign": 1, "weight": 1/3},
'CTOT_NSA_P1W4WL1': {"eq_sign": 1, "fx_sign": 1, "weight": 1/3},
}
# USD equity effects are indicators with appropriate signs
cidx = cids_eq
calcs = []
for xc, params in tot.items():
s = "N" if params["eq_sign"] < 0 else ""
calcs.append(f"{xc}{s}_F = {xc} * {params["eq_sign"]}")
dfa = msp.panel_calculator(dfx, calcs=calcs, cids=cidx)
dfx = msm.update_df(dfx, dfa)
# Score the quantamental factors
postfixes = ["N" if v["eq_sign"] < 0 else "" for v in tot.values()]
tots = [k + s + "_F" for k, s in zip(tot.keys(), postfixes)]
xcatx = tots
cidx = cids_eq
for xc in xcatx:
dfa = msp.make_zn_scores(
dfx,
xcat=xc,
cids=cidx,
sequential=True,
min_obs=261 * 3,
neutral="zero",
pan_weight=1,
thresh=3,
postfix="ZN",
est_freq="m",
)
dfx = msm.update_df(dfx, dfa)
# Visualize
xcatx = [xc + "ZN" for xc in tots]
cidx = cids_eq
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=5,
start="1995-01-01",
same_y=True,
height=2,
)
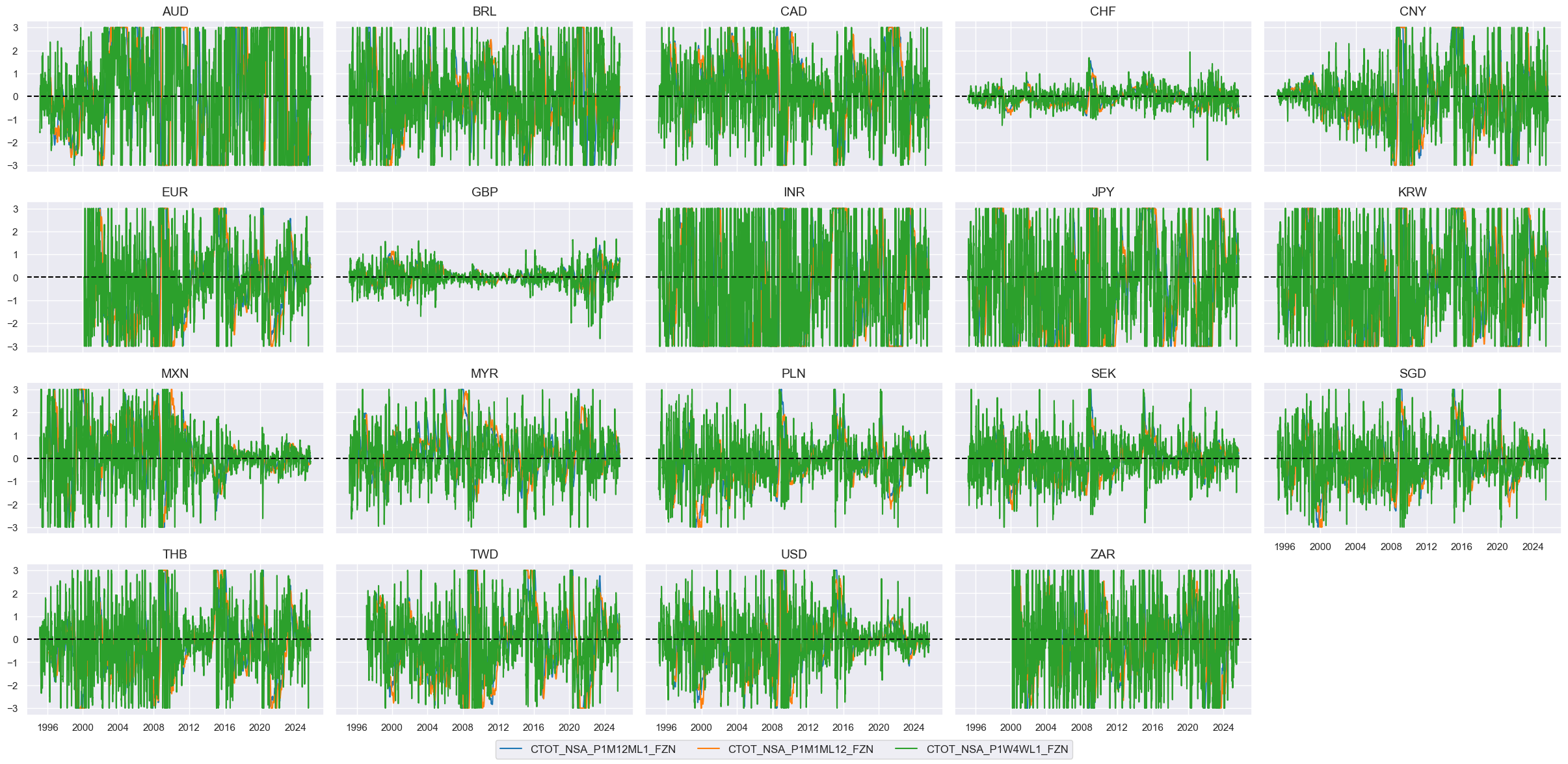
# Calculate the conceptual factor score
xcatx = [xc + "ZN" for xc in tots]
cidx = cids_eq
weights = [tot[xc]["weight"] for xc in list(tot.keys())]
cfs = "TOTIMPROVE"
dfa = msp.linear_composite(
df=dfx,
xcats=xcatx,
cids=cids_eq,
weights=weights,
new_xcat=cfs,
complete_xcats=False,
)
dfx= msm.update_df(dfx, dfa)
# Re-score
dfa = msp.make_zn_scores(
dfx,
xcat=cfs,
cids=cidx,
sequential=True,
min_obs=261 * 3,
neutral="zero",
pan_weight=1,
thresh=3,
postfix="_ZN",
est_freq="m",
)
dfx = msm.update_df(dfx, dfa)
concept_factors[cfs] = "Terms-of-trade improvement"
# Visualize
cfs = "TOTIMPROVE"
xcatx = [cfs, f"{cfs}_ZN"]
cidx = cids_eq
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=5,
start="1995-01-01",
same_y=True,
height=2,
)
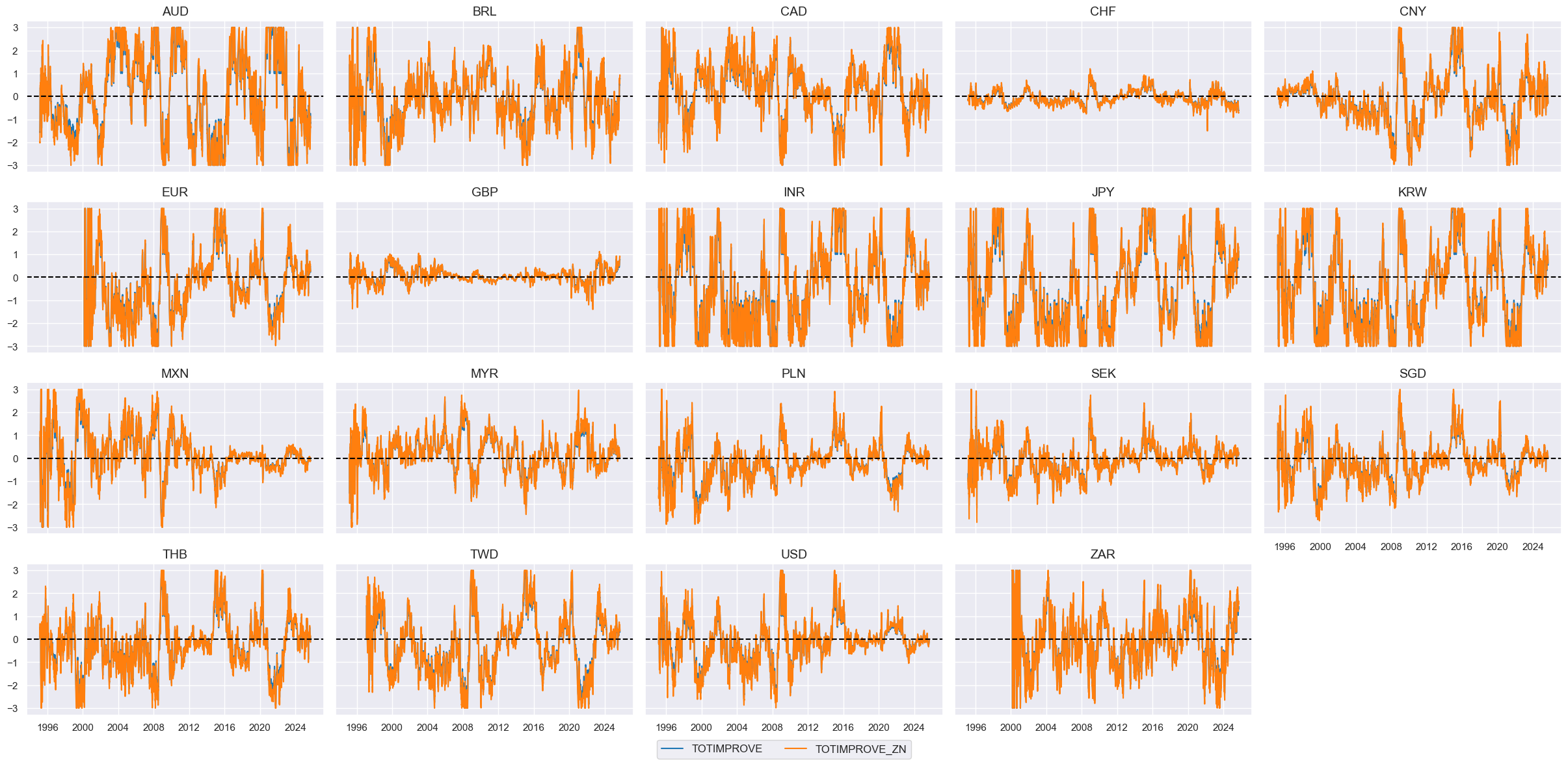
External balances #
# All constituents, signs, and weights
xbal = {
'MTBGDPRATIO_NSA_12MMA': {"eq_sign": 1, "fx_sign": 1, "weight": 1/4},
'MTBGDPRATIO_SA_3MMAv60MMA': {"eq_sign": 1, "fx_sign": 1, "weight": 1/4},
'CABGDPRATIO_NSA_12MMA': {"eq_sign": 1, "fx_sign": 1, "weight": 1/4},
'CABGDPRATIO_SA_3MMAv60MMA': {"eq_sign": 1, "fx_sign": 1, "weight": 1/4},
}
# USD equity effects are indicators with appropriate signs
cidx = cids_eq
calcs = []
for xc, params in xbal.items():
s = "N" if params["eq_sign"] < 0 else ""
calcs.append(f"{xc}{s}_F = {xc} * {params["eq_sign"]}")
dfa = msp.panel_calculator(dfx, calcs=calcs, cids=cidx)
dfx = msm.update_df(dfx, dfa)
# Score the quantamental factors
postfixes = ["N" if v["eq_sign"] < 0 else "" for v in xbal.values()]
xbals = [k + s + "_F" for k, s in zip(xbal.keys(), postfixes)]
xcatx = xbals
cidx = cids_eq
for xc in xcatx:
dfa = msp.make_zn_scores(
dfx,
xcat=xc,
cids=cidx,
sequential=True,
min_obs=261 * 3,
neutral="zero",
pan_weight=1,
thresh=3,
postfix="ZN",
est_freq="m",
)
dfx = msm.update_df(dfx, dfa)
# Visualize
xcatx = [xc + "ZN" for xc in xbals]
cidx = cids_eq
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=5,
start="1995-01-01",
same_y=True,
height=2,
)
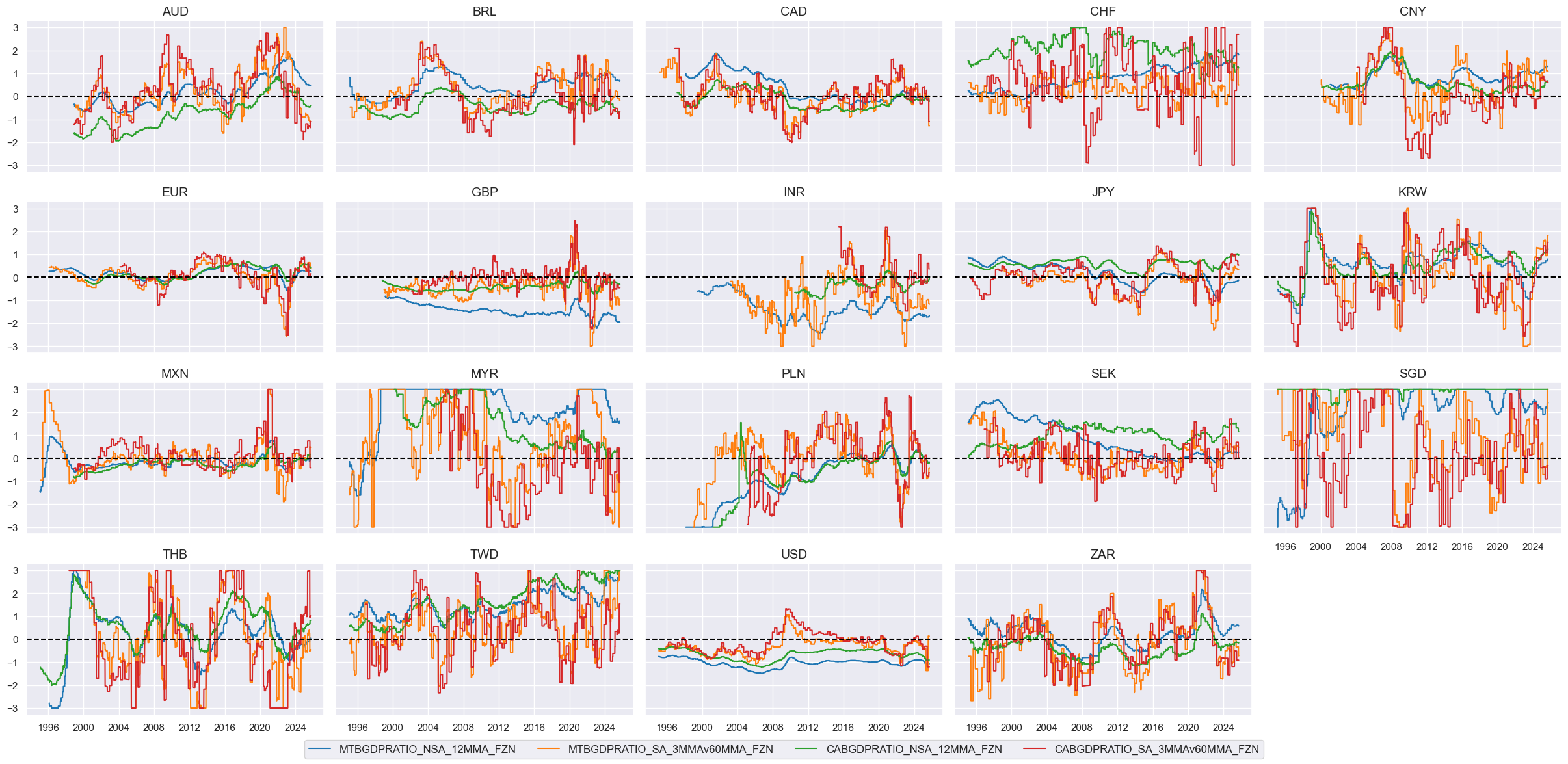
# Calculate the conceptual factor score
xcatx = [xc + "ZN" for xc in xbals]
cidx = cids_eq
weights = [xbal[xc]["weight"] for xc in list(xbal.keys())]
cfs = "XBALSTRENGTH"
dfa = msp.linear_composite(
df=dfx,
xcats=xcatx,
cids=cids_eq,
weights=weights,
new_xcat=cfs,
complete_xcats=False,
)
dfx= msm.update_df(dfx, dfa)
# Re-score
dfa = msp.make_zn_scores(
dfx,
xcat=cfs,
cids=cidx,
sequential=True,
min_obs=261 * 3,
neutral="zero",
pan_weight=1,
thresh=3,
postfix="_ZN",
est_freq="m",
)
dfx = msm.update_df(dfx, dfa)
concept_factors[cfs] = "External balance strength"
# Visualize
cfs = "XBALSTRENGTH"
xcatx = [cfs, f"{cfs}_ZN"]
cidx = cids_eq
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=5,
start="1995-01-01",
same_y=True,
height=2,
)
Investment position improvement #
# All constituents, signs, and weights
iip = {
'IIPLIABGDP_NSA_D1M1ML12': {"eq_sign": -1, "fx_sign": -1, "weight": 1/2},
'NIIPGDP_NSA_D1M1ML12': {"eq_sign": 1, "fx_sign": 1, "weight": 1/2},
}
# USD equity effects are indicators with appropriate signs
cidx = cids_eq
calcs = []
for xc, params in iip.items():
s = "N" if params["eq_sign"] < 0 else ""
calcs.append(f"{xc}{s}_F = {xc} * {params["eq_sign"]}")
dfa = msp.panel_calculator(dfx, calcs=calcs, cids=cidx)
dfx = msm.update_df(dfx, dfa)
# Score the quantamental factors
postfixes = ["N" if v["eq_sign"] < 0 else "" for v in iip.values()]
iips = [k + s + "_F" for k, s in zip(iip.keys(), postfixes)]
xcatx = iips
cidx = cids_eq
for xc in xcatx:
dfa = msp.make_zn_scores(
dfx,
xcat=xc,
cids=cidx,
sequential=True,
min_obs=261 * 3,
neutral="zero",
pan_weight=1,
thresh=3,
postfix="ZN",
est_freq="m",
)
dfx = msm.update_df(dfx, dfa)
# Visualize
xcatx = [xc + "ZN" for xc in iips]
cidx = cids_eq
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=5,
start="1995-01-01",
same_y=True,
height=2,
)
# Calculate the conceptual factor score
xcatx = [xc + "ZN" for xc in iips]
cidx = cids_eq
weights = [iip[xc]["weight"] for xc in list(iip.keys())]
cfs = "IIPIMPROVE"
dfa = msp.linear_composite(
df=dfx,
xcats=xcatx,
cids=cids_eq,
weights=weights,
new_xcat=cfs,
complete_xcats=False,
)
dfx= msm.update_df(dfx, dfa)
# Re-score
dfa = msp.make_zn_scores(
dfx,
xcat=cfs,
cids=cidx,
sequential=True,
min_obs=261 * 3,
neutral="zero",
pan_weight=1,
thresh=3,
postfix="_ZN",
est_freq="m",
)
dfx = msm.update_df(dfx, dfa)
concept_factors[cfs] = "Investment position improvement"
# Visualize
cfs = "IIPIMPROVE"
xcatx = [cfs, f"{cfs}_ZN"]
cidx = cids_eq
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=5,
start="1995-01-01",
same_y=True,
height=2,
)
Liquidity growth #
# All constituents, signs, and weights
liq = {
'INTLIQGDP_NSA_D1M1ML3': {"eq_sign": 1, "fx_sign": 1, "weight": 1/2},
'INTLIQGDP_NSA_D1M1ML6': {"eq_sign": 1, "fx_sign": 1, "weight": 1/2},
}
# USD equity effects are indicators with appropriate signs
cidx = cids_eq
calcs = []
for xc, params in liq.items():
s = "N" if params["eq_sign"] < 0 else ""
calcs.append(f"{xc}{s}_F = {xc} * {params["eq_sign"]}")
dfa = msp.panel_calculator(dfx, calcs=calcs, cids=cidx)
dfx = msm.update_df(dfx, dfa)
# Score the quantamental factors
postfixes = ["N" if v["eq_sign"] < 0 else "" for v in liq.values()]
liqs = [k + s + "_F" for k, s in zip(liq.keys(), postfixes)]
xcatx = liqs
cidx = cids_eq
for xc in xcatx:
dfa = msp.make_zn_scores(
dfx,
xcat=xc,
cids=cidx,
sequential=True,
min_obs=261 * 3,
neutral="zero",
pan_weight=1,
thresh=3,
postfix="ZN",
est_freq="m",
)
dfx = msm.update_df(dfx, dfa)
# Visualize
xcatx = [xc + "ZN" for xc in liqs]
cidx = cids_eq
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=5,
start="1995-01-01",
same_y=True,
height=2,
)
# Calculate the conceptual factor score
xcatx = [xc + "ZN" for xc in liqs]
cidx = cids_eq
weights = [liq[xc]["weight"] for xc in list(liq.keys())]
cfs = "LIQGROW"
dfa = msp.linear_composite(
df=dfx,
xcats=xcatx,
cids=cids_eq,
weights=weights,
new_xcat=cfs,
complete_xcats=False,
)
dfx= msm.update_df(dfx, dfa)
# Re-score
dfa = msp.make_zn_scores(
dfx,
xcat=cfs,
cids=cidx,
sequential=True,
min_obs=261 * 3,
neutral="zero",
pan_weight=1,
thresh=3,
postfix="_ZN",
est_freq="m",
)
dfx = msm.update_df(dfx, dfa)
concept_factors[cfs] = "Liquidity growth"
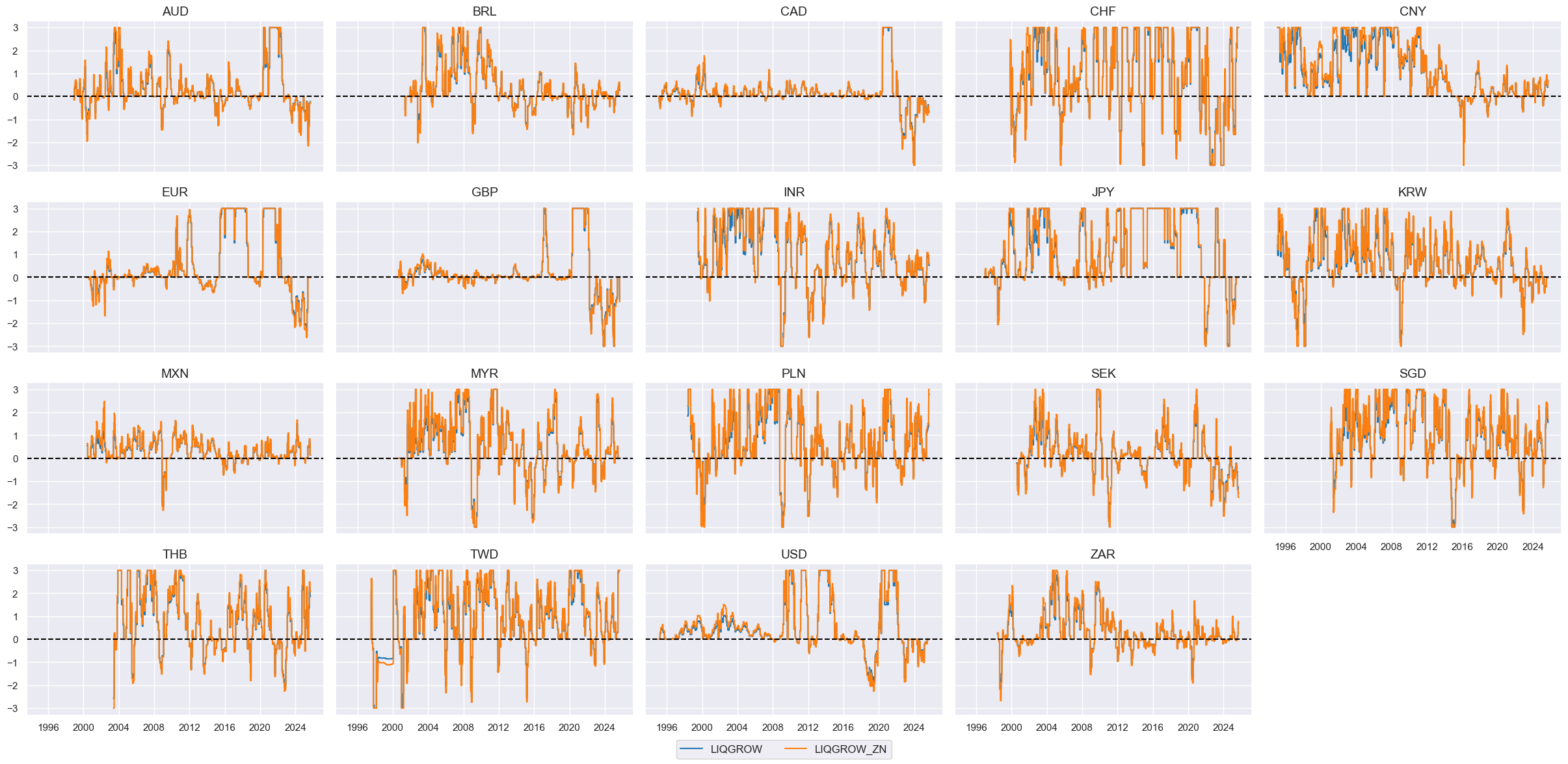
# Visualize
cfs = "LIQGROW"
xcatx = [cfs, f"{cfs}_ZN"]
cidx = cids_eq
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=5,
start="1995-01-01",
same_y=True,
height=2,
)
Overheating #
# Computing real consumption / sales trends in excess of long term growth support
cidx = cids_eq
calcs = [
"XRPCONS_SA_P1M1ML12 = RPCONS_SA_P1M1ML12 - RGDP_SA_P1Q1QL4_20QMM",
"XRRSALES_SA_P1M1ML12 = RRSALES_SA_P1M1ML12 - RGDP_SA_P1Q1QL4_20QMM"
]
dfa = msp.panel_calculator(dfx, calcs=calcs, cids=cidx)
dfx = msm.update_df(dfx, dfa)
# All constituents, signs, and weights
xdem = {
'XRPCONS_SA_P1M1ML12': {"eq_sign": -1, "fx_sign": 1, "weight": 1/4},
'XRRSALES_SA_P1M1ML12': {"eq_sign": -1, "fx_sign": 1, "weight": 1/4},
'UNEMPLRATE_NSA_3MMA_D1M1ML12': {"eq_sign": 1, "fx_sign": -1, "weight": 1/4},
'UNEMPLRATE_SA_3MMAv5YMA': {"eq_sign": 1, "fx_sign": -1, "weight": 1/4},
}
# Differentials to USD
xcatx = list(xdem.keys())
cidx = cids_eq
for xc in xcatx:
dfa = msp.make_relative_value(
dfx,
xcats=xcatx,
cids=cidx,
basket=["USD"], # basket does not use all cross-sections
rel_meth="subtract",
postfix="vUSD",
)
dfx = msm.update_df(df=dfx, df_add=dfa)
# Visualize
xcatx = ["UNEMPLRATE_NSA_3MMA_D1M1ML12", "UNEMPLRATE_NSA_3MMA_D1M1ML12vUSD"]
cidx = cids_eq
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=5,
start="1995-01-01",
same_y=True,
height=2,
)
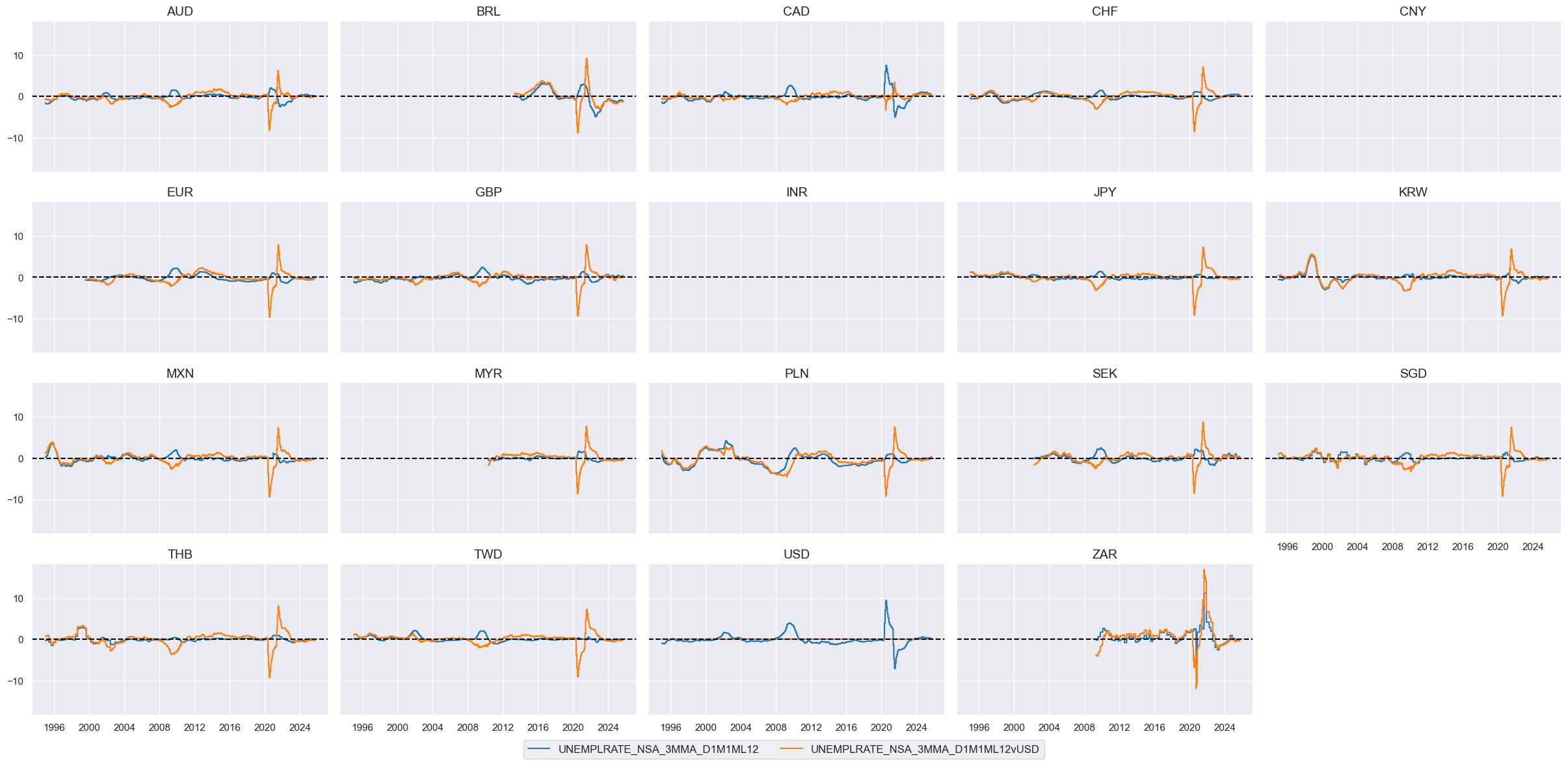
# Extract USD equity effects
cidx = cids_eq
for xc, params in xdem.items():
dfa = cross_asset_effects(
df=dfx,
cids=cidx,
effect_name=xc + "_F",
signal_xcats={"eq": xc, "fx": xc + "vUSD"},
weights_xcats={"eq": "EQXRxEASD_NSA_EXT", "fx": "FXXRUSDxEASD_NSA"},
signal_signs={k.replace("_sign", ""): v for k, v in params.items() if "sign" in k},
)
dfx = msm.update_df(dfx, dfa.loc[dfa["xcat"] == f"{xc}_F"])
# Visualize
xcatx = ["XRPCONS_SA_P1M1ML12", "XRPCONS_SA_P1M1ML12_F"]
cidx = cids_eq
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=5,
start="1995-01-01",
same_y=True,
height=2,
title="Annual real condumption growth signals",
xcat_labels=["Simple", "Controlling for cross asset effects"]
)
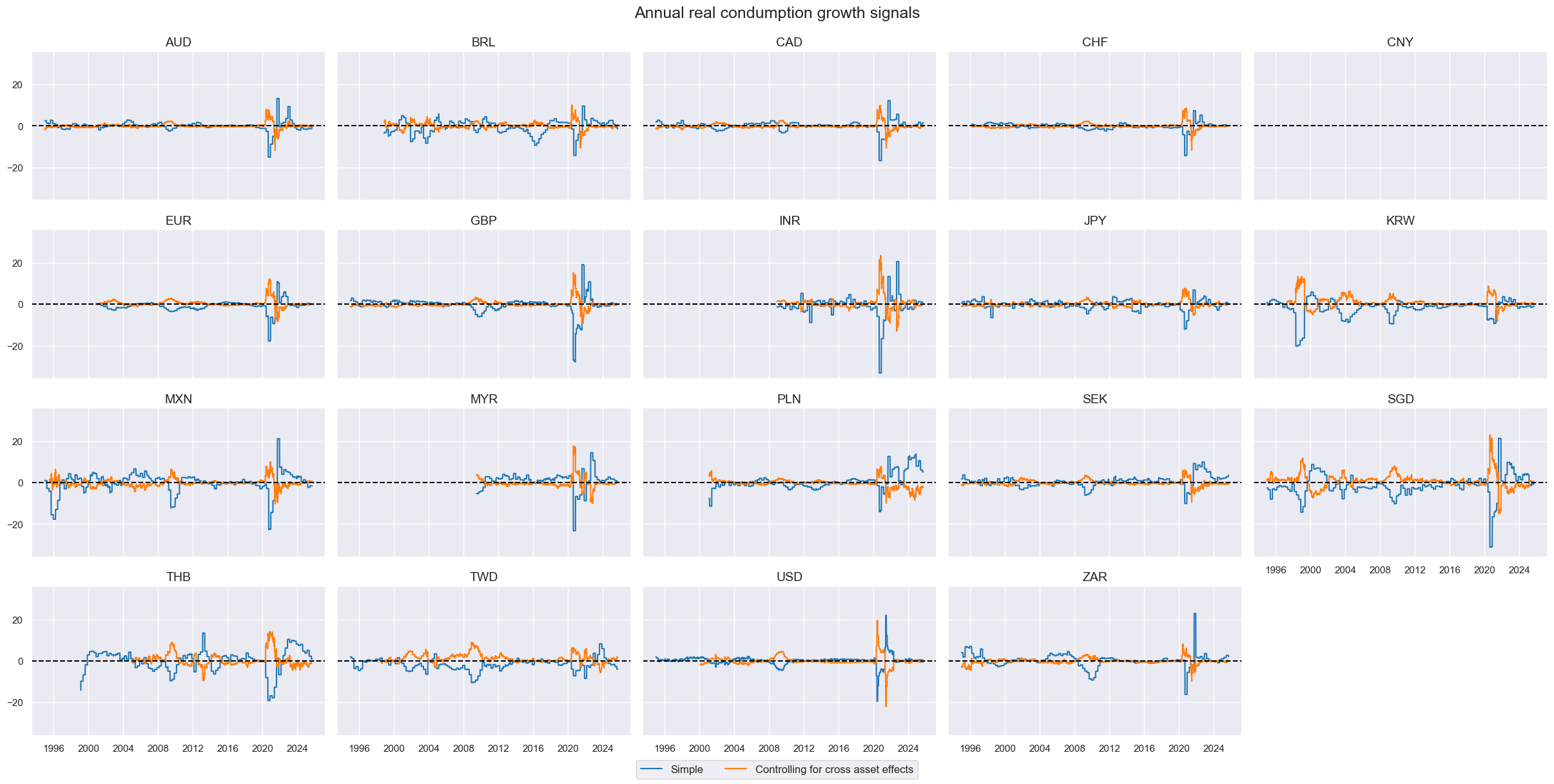
# Score the quantamental factors
xcatx = [xc + "_F" for xc in list(xdem.keys())]
cidx = cids_eq
for xc in xcatx:
dfa = msp.make_zn_scores(
dfx,
xcat=xc,
cids=cidx,
sequential=True,
min_obs=261 * 3,
neutral="zero",
pan_weight=1,
thresh=3,
postfix="ZN",
est_freq="m",
)
dfx = msm.update_df(dfx, dfa)
# Visualize
xcatx = [xc + "_FZN" for xc in list(xdem.keys())]
cidx = cids_eq
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=5,
start="1995-01-01",
same_y=True,
height=2,
)
# Calculate the conceptual factor score
xcatx = [xc + "_FZN" for xc in list(xdem.keys())]
cidx = cids_eq
weights = [xdem[xc]["weight"] for xc in list(xdem.keys())]
cfs = "OVERHEAT"
dfa = msp.linear_composite(
df=dfx,
xcats=xcatx,
cids=cids_eq,
weights=weights,
new_xcat=cfs,
complete_xcats=False,
)
dfx= msm.update_df(dfx, dfa)
# Re-score
dfa = msp.make_zn_scores(
dfx,
xcat=cfs,
cids=cidx,
sequential=True,
min_obs=261 * 3,
neutral="zero",
pan_weight=1,
thresh=3,
postfix="_ZN",
est_freq="m",
)
dfx = msm.update_df(dfx, dfa)
concept_factors[cfs] = "Overheating effect"
# Visualize
cfs = "OVERHEAT"
xcatx = [cfs, f"{cfs}_ZN"]
cidx = cids_eq
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=5,
start="1995-01-01",
same_y=True,
height=2,
)
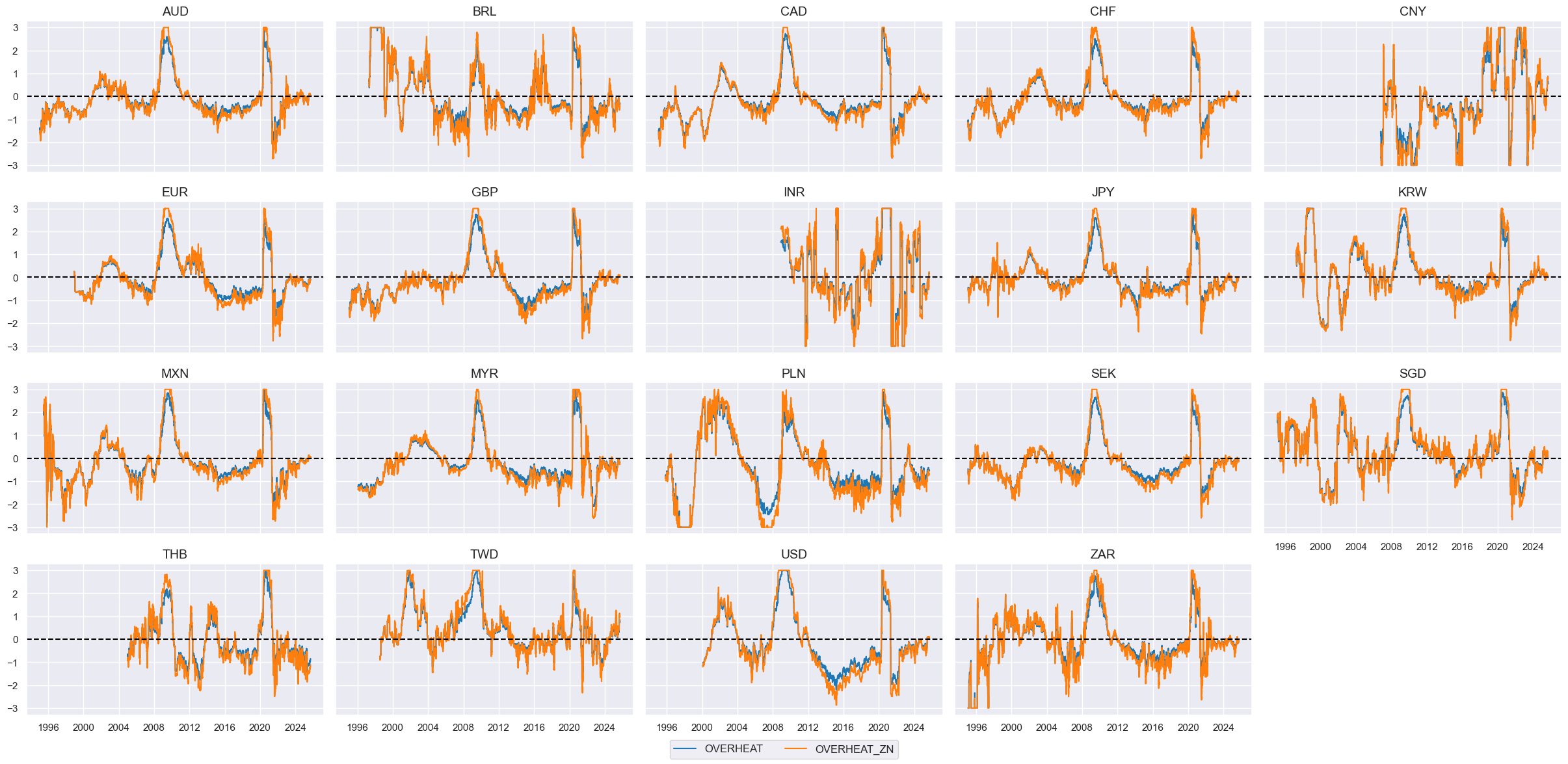
Confidence improvement #
# All constituents, signs, and weights
conf = {
'MBCSCORE_SA_D3M3ML3': {"eq_sign": 1, "fx_sign": 1, "weight": 1/4},
'MBCSCORE_SA_D1M1ML12': {"eq_sign": 1, "fx_sign": 1, "weight": 1/4},
'CCSCORE_SA_D3M3ML3': {"eq_sign": 1, "fx_sign": 1, "weight": 1/4},
'CCSCORE_SA_D1M1ML12': {"eq_sign": 1, "fx_sign": 1, "weight": 1/4},
}
# USD equity effects are indicators with appropriate signs
cidx = cids_eq
calcs = []
for xc, params in conf.items():
s = "N" if params["eq_sign"] < 0 else ""
calcs.append(f"{xc}{s}_F = {xc} * {params["eq_sign"]}")
dfa = msp.panel_calculator(dfx, calcs=calcs, cids=cidx)
dfx = msm.update_df(dfx, dfa)
# Score the quantamental factors
postfixes = ["N" if v["eq_sign"] < 0 else "" for v in conf.values()]
confs = [k + s + "_F" for k, s in zip(conf.keys(), postfixes)]
xcatx = confs
cidx = cids_eq
for xc in xcatx:
dfa = msp.make_zn_scores(
dfx,
xcat=xc,
cids=cidx,
sequential=True,
min_obs=261 * 3,
neutral="zero",
pan_weight=1,
thresh=3,
postfix="ZN",
est_freq="m",
)
dfx = msm.update_df(dfx, dfa)
# Visualize
xcatx = [xc + "ZN" for xc in confs]
cidx = cids_eq
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=5,
start="1995-01-01",
same_y=True,
height=2,
)
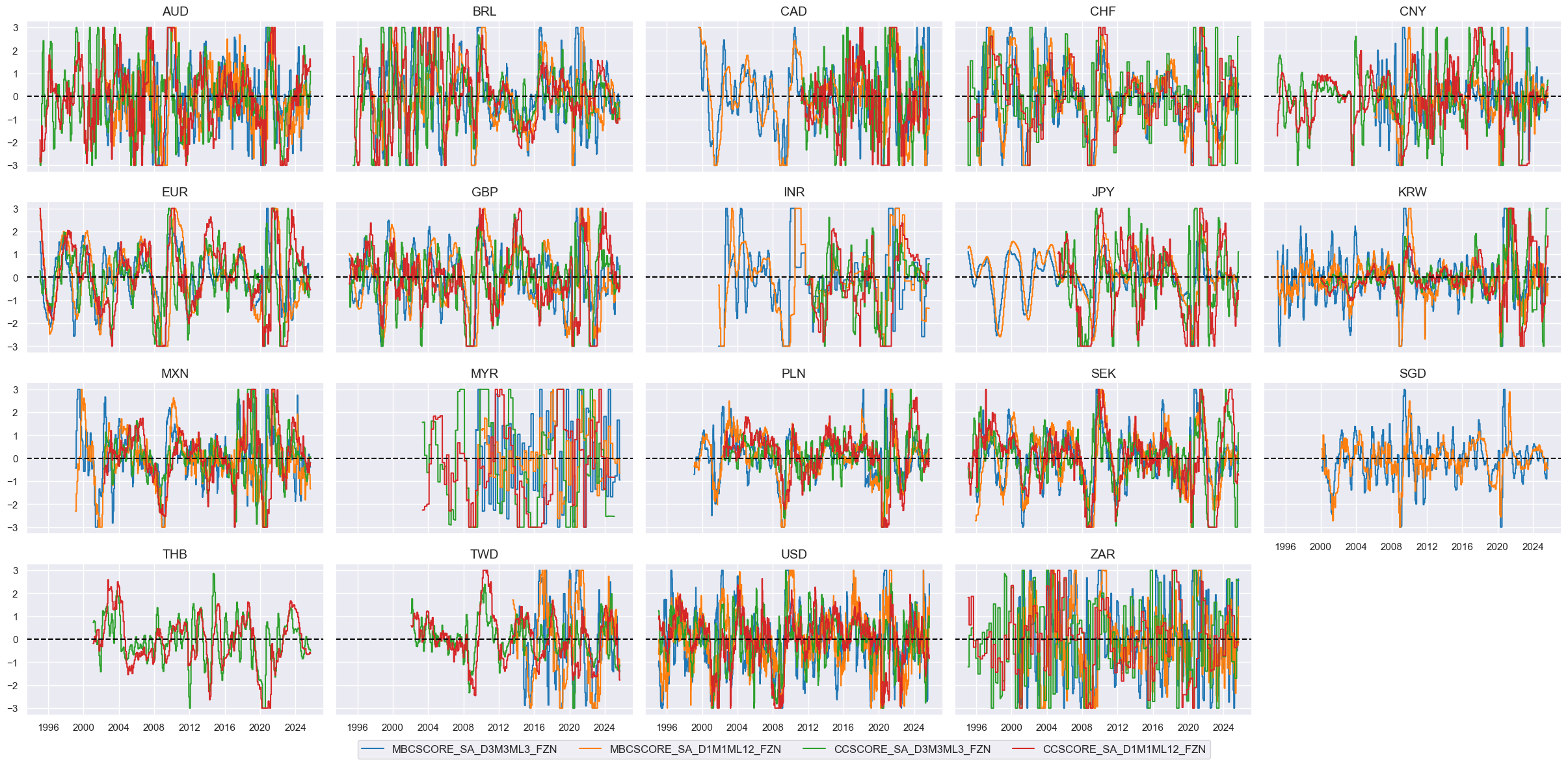
# Calculate the conceptual factor score
xcatx = [xc + "ZN" for xc in confs]
cidx = cids_eq
weights = [conf[xc]["weight"] for xc in list(conf.keys())]
cfs = "CONFUP"
dfa = msp.linear_composite(
df=dfx,
xcats=xcatx,
cids=cids_eq,
weights=weights,
new_xcat=cfs,
complete_xcats=False,
)
dfx= msm.update_df(dfx, dfa)
# Re-score
dfa = msp.make_zn_scores(
dfx,
xcat=cfs,
cids=cidx,
sequential=True,
min_obs=261 * 3,
neutral="zero",
pan_weight=1,
thresh=3,
postfix="_ZN",
est_freq="m",
)
dfx = msm.update_df(dfx, dfa)
concept_factors[cfs] = "Confidence improvement"
# Visualize
cfs = "CONFUP"
xcatx = [cfs, f"{cfs}_ZN"]
cidx = cids_eq
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=5,
start="1995-01-01",
same_y=True,
height=2,
)
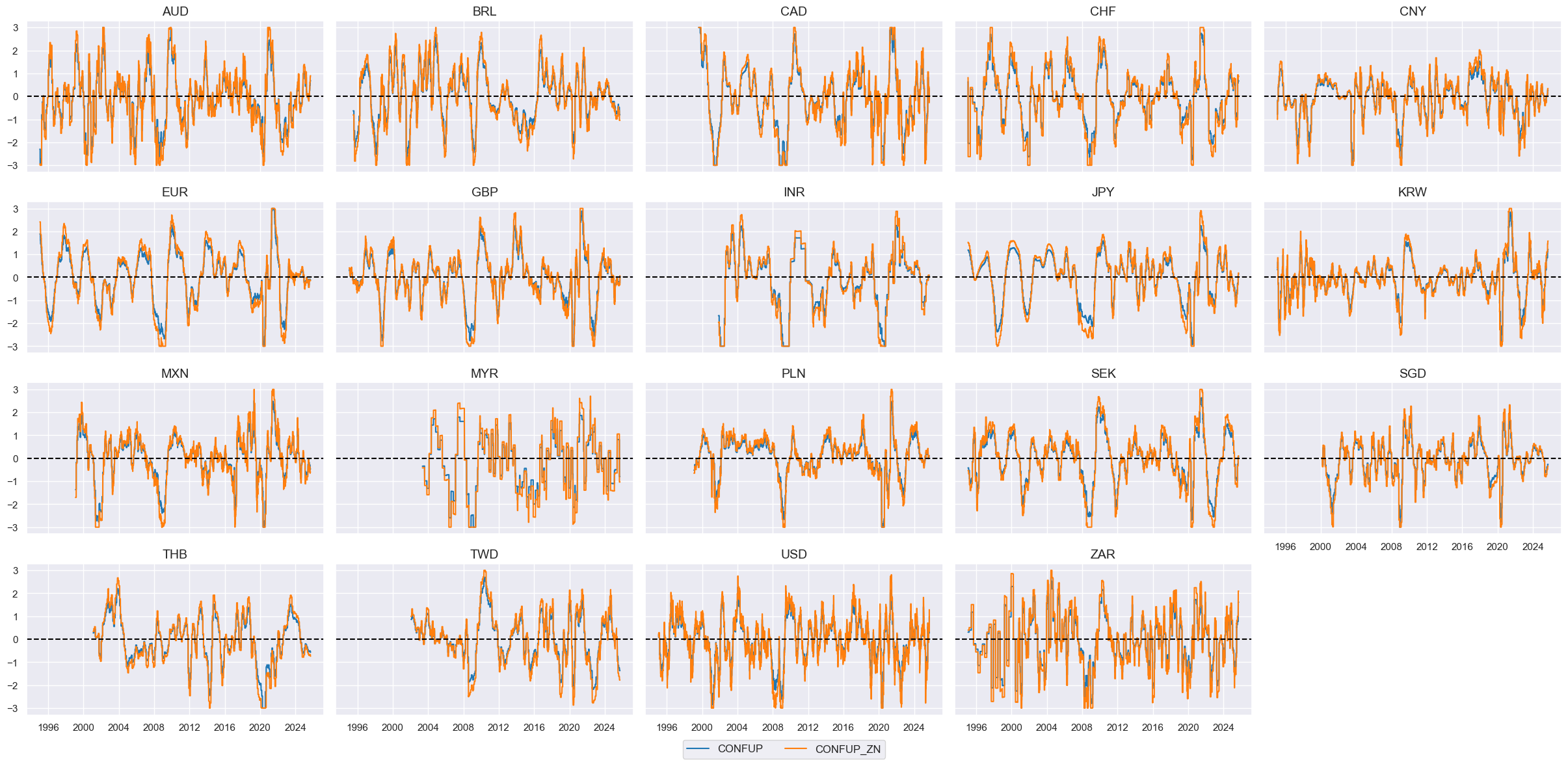
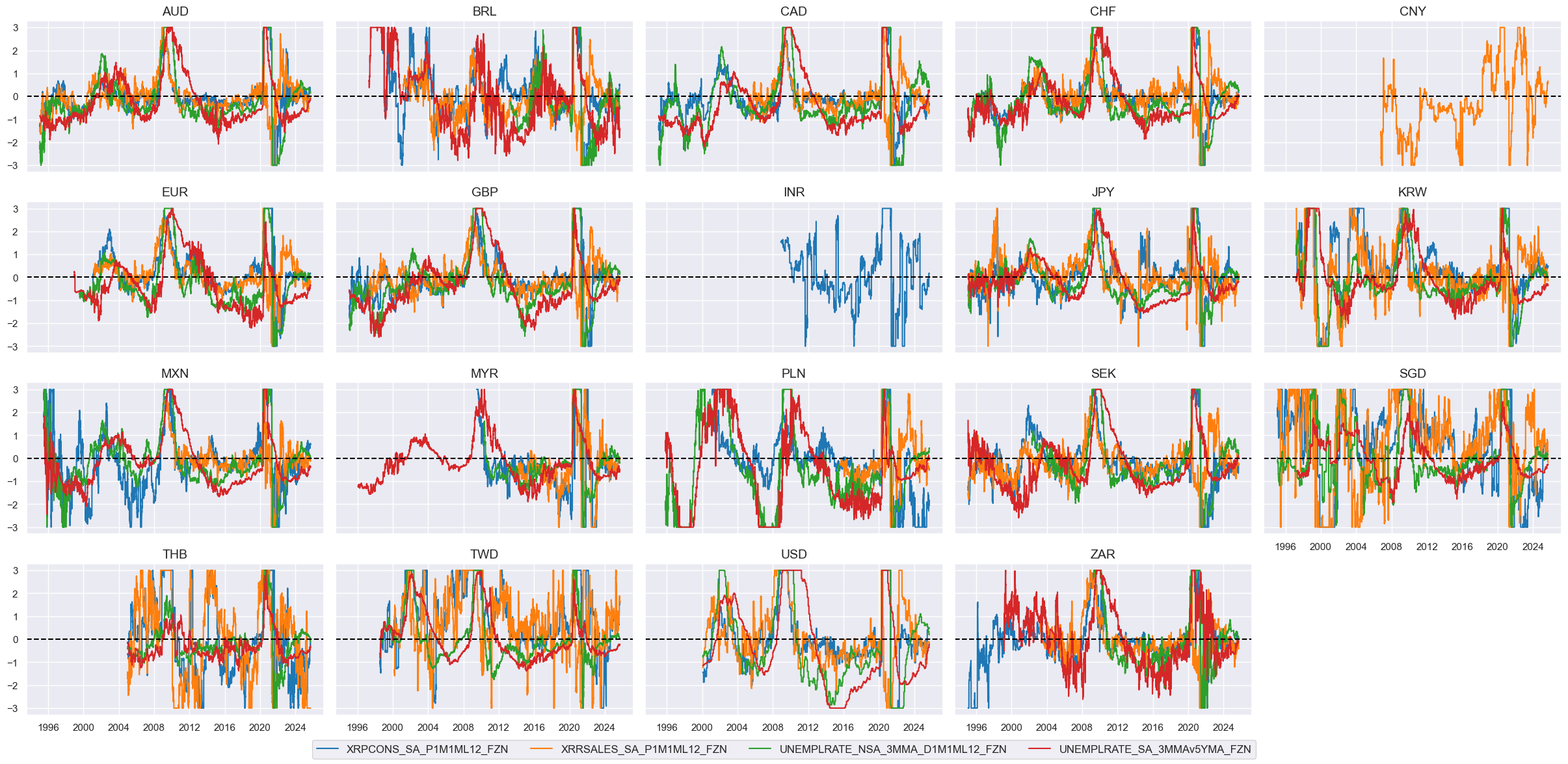
Real yields #
# Real rate dynamics
cidx = cids_eq
calcs = [
"RIR_NSA_1MMA = RIR_NSA.rolling(21).mean()",
"RIR_NSA_1MMAL1 = RIR_NSA.shift(21)",
"RIR_NSA_D1M1ML1 = RIR_NSA_1MMA - RIR_NSA_1MMAL1",
"RYLDIRS02Y_NSA_1MMA = RYLDIRS02Y_NSA.rolling(21).mean()",
"RYLDIRS02Y_NSA_1MMA_L1 = RYLDIRS02Y_NSA_1MMA.shift(21)",
"RYLDIRS02Y_NSA_D1M1ML1 = RYLDIRS02Y_NSA_1MMA - RYLDIRS02Y_NSA_1MMA_L1",
"RYLDIRS05Y_NSA_1MMA = RYLDIRS05Y_NSA.rolling(21).mean()",
"RYLDIRS05Y_NSA_1MMA_L1 = RYLDIRS05Y_NSA_1MMA.shift(21)",
"RYLDIRS05Y_NSA_D1M1ML1 = RYLDIRS05Y_NSA_1MMA - RYLDIRS05Y_NSA_1MMA_L1"
]
dfa = msp.panel_calculator(dfx, calcs=calcs, cids=cidx)
dfx = msm.update_df(dfx, dfa)
# All constituents, signs, and weights
ryield = {
'RIR_NSA': {"eq_sign": -1, "fx_sign": 1, "weight": 1/6},
'RIR_NSA_D1M1ML1': {"eq_sign": -1, "fx_sign": 1, "weight": 1/6},
'RYLDIRS02Y_NSA': {"eq_sign": -1, "fx_sign": 1, "weight": 1/6},
'RYLDIRS02Y_NSA_D1M1ML1': {"eq_sign": -1, "fx_sign": 1, "weight": 1/6},
'RYLDIRS05Y_NSA': {"eq_sign": -1, "fx_sign": 1, "weight": 1/6},
'RYLDIRS05Y_NSA_D1M1ML1': {"eq_sign": -1, "fx_sign": 1, "weight": 1/6},
}
# Differentials to USD
xcatx = list(ryield.keys())
cidx = cids_eq
for xc in xcatx:
dfa = msp.make_relative_value(
dfx,
xcats=xcatx,
cids=cidx,
basket=["USD"], # basket does not use all cross-sections
rel_meth="subtract",
postfix="vUSD",
)
dfx = msm.update_df(df=dfx, df_add=dfa)
# Visualize
xcatx = ["RIR_NSA", "RIR_NSAvUSD"]
cidx = cids_eq
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=5,
start="1995-01-01",
same_y=True,
height=2,
)
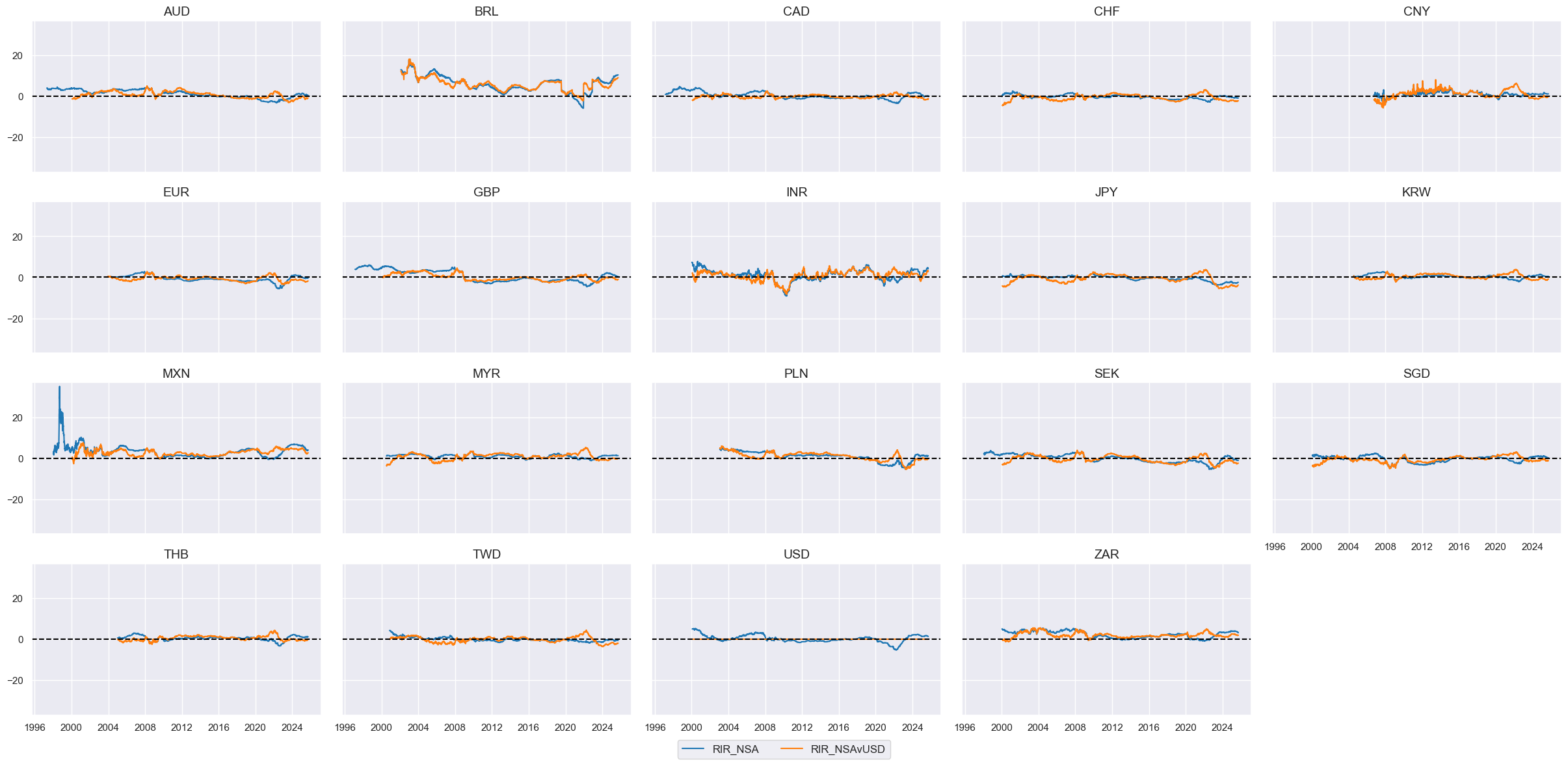
# Extract USD equity effects
cidx = cids_eq
for xc, params in ryield.items():
dfa = cross_asset_effects(
df=dfx,
cids=cidx,
effect_name=xc + "_F",
signal_xcats={"eq": xc, "fx": xc + "vUSD"},
weights_xcats={"eq": "EQXRxEASD_NSA_EXT", "fx": "FXXRUSDxEASD_NSA"},
signal_signs={k.replace("_sign", ""): v for k, v in params.items() if "sign" in k},
)
dfx = msm.update_df(dfx, dfa.loc[dfa["xcat"] == f"{xc}_F"])
# Visualize
xcatx = ["RIR_NSA", "RIR_NSA_F"]
cidx = cids_eq
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=5,
start="1995-01-01",
same_y=True,
height=2,
)
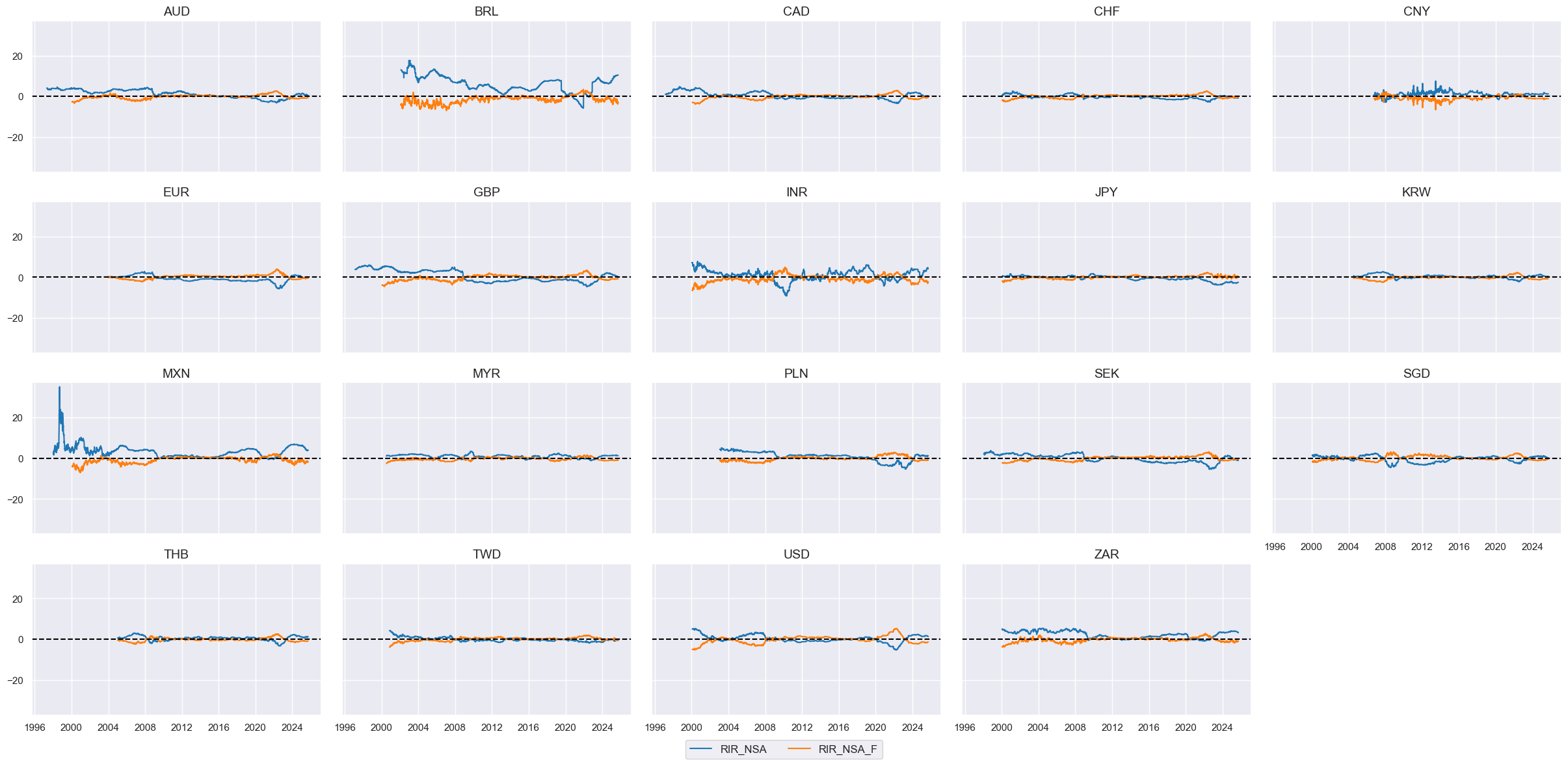
# Score the quantamental factors
xcatx = [xc + "_F" for xc in list(ryield.keys())]
cidx = cids_eq
for xc in xcatx:
dfa = msp.make_zn_scores(
dfx,
xcat=xc,
cids=cidx,
sequential=True,
min_obs=261 * 3,
neutral="zero",
pan_weight=1,
thresh=3,
postfix="ZN",
est_freq="m",
)
dfx = msm.update_df(dfx, dfa)
# Visualize
xcatx = ["RIR_NSA_F", "RIR_NSA_FZN"]
cidx = cids_eq
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=5,
start="1995-01-01",
same_y=True,
height=2,
)
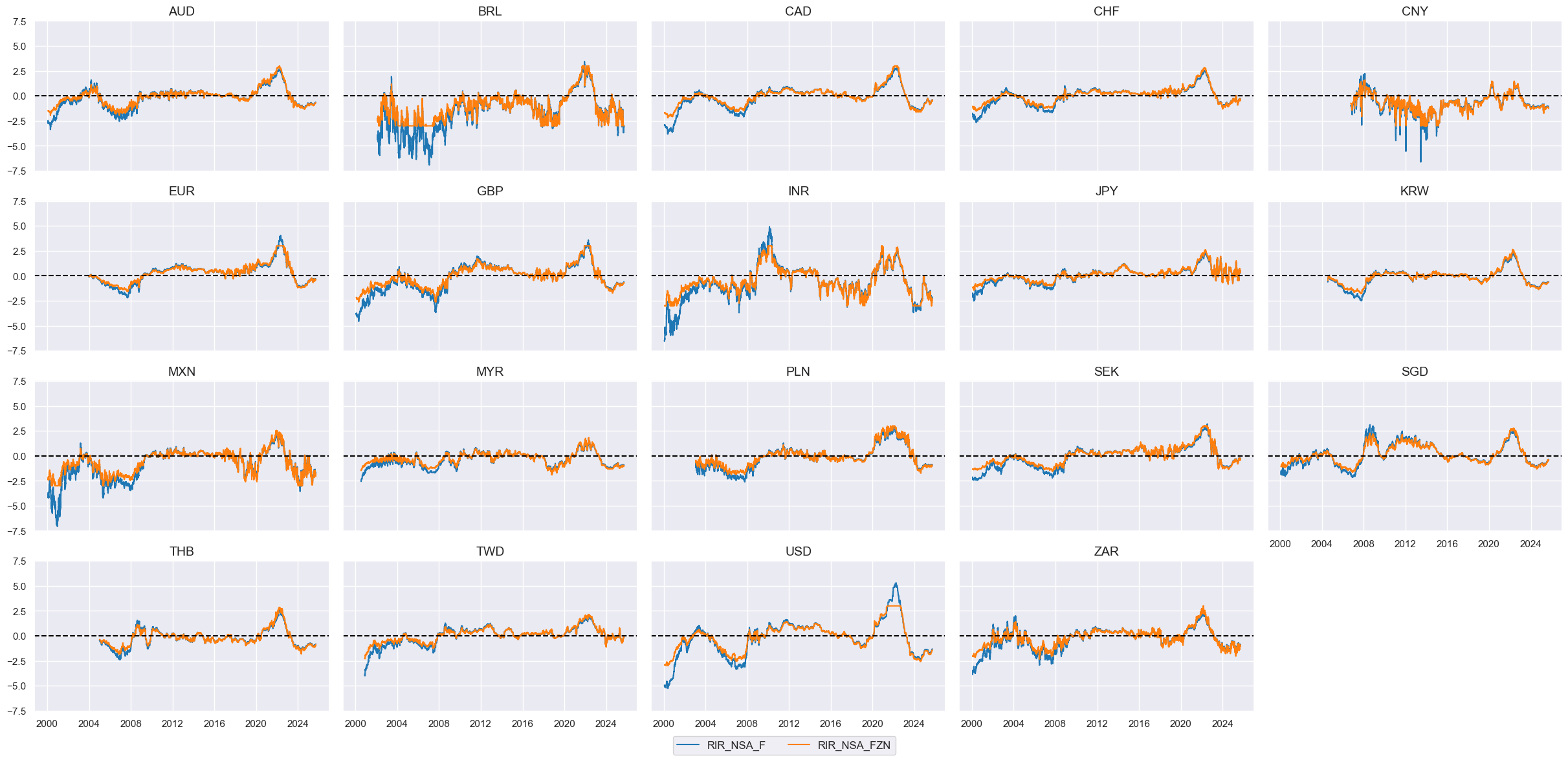
# Calculate the conceptual factor score
xcatx = [xc + "_FZN" for xc in list(ryield.keys())]
cidx = cids_eq
weights = [ryield[xc]["weight"] for xc in list(ryield.keys())]
cfs = "RYIELD"
dfa = msp.linear_composite(
df=dfx,
xcats=xcatx,
cids=cids_eq,
weights=weights,
new_xcat=cfs,
complete_xcats=False,
)
dfx= msm.update_df(dfx, dfa)
# Re-score
dfa = msp.make_zn_scores(
dfx,
xcat=cfs,
cids=cidx,
sequential=True,
min_obs=261 * 3,
neutral="zero",
pan_weight=1,
thresh=3,
postfix="_ZN",
est_freq="m",
)
dfx = msm.update_df(dfx, dfa)
concept_factors[cfs] = "Real yield effect"
# Visualize
cfs = "RYIELD"
xcatx = [cfs, f"{cfs}_ZN"]
cidx = cids_eq
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=5,
start="1995-01-01",
same_y=True,
height=2,
)
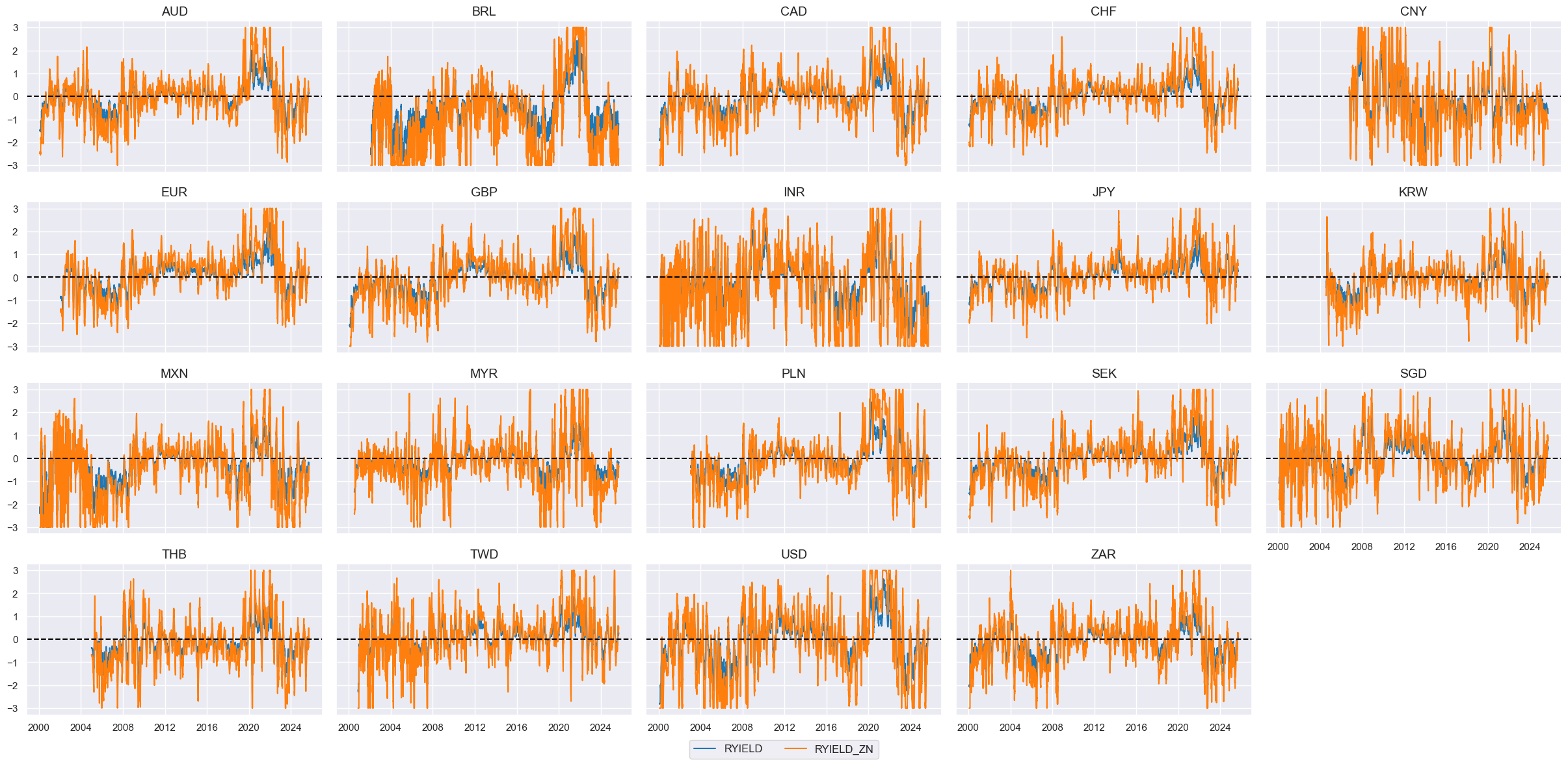
Joint factor visualizations and relative factor calculation #
cfs_names = {k + "_ZN": v for k, v in concept_factors.items()}
rcfs_names = {k + "_ZNvGLB": v for k, v in concept_factors.items()}
xcatx = list(cfs_names.keys())
msm.check_availability(
df=dfx,
xcats=xcatx,
cids=cids_eq,
missing_recent=False,
start="1995-01-01",
xcat_labels=cfs_names,
)
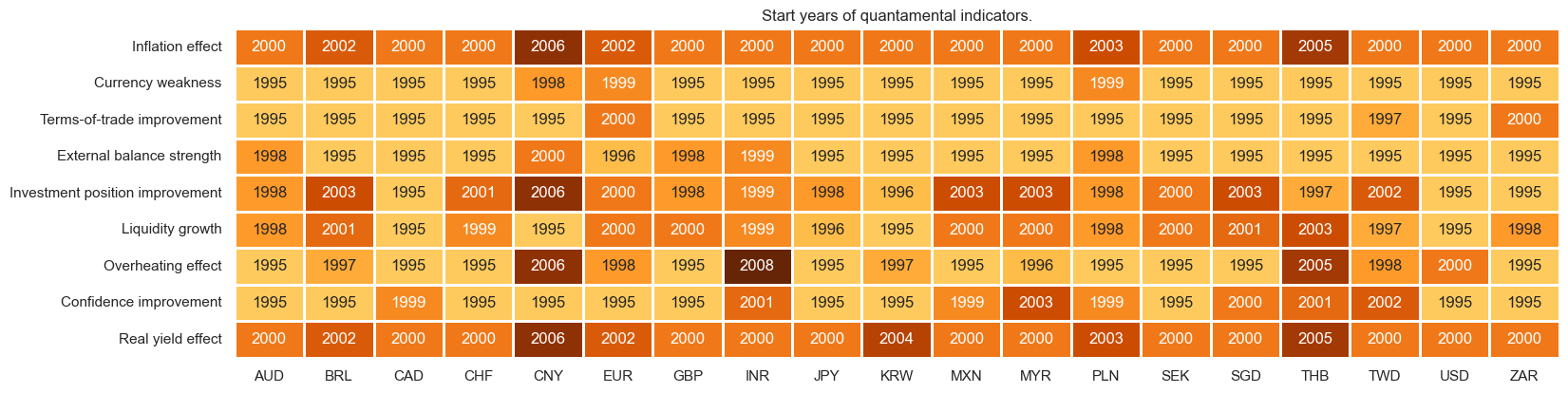
cidx = cids_eq
xcatx = list(cfs_names.keys())
start = "1995-01-01"
msp.correl_matrix(
dfx,
cids=cidx,
xcats=xcatx,
max_color=1.0,
annot=True,
fmt=".1f",
freq="M",
cluster=False,
title="Conceptual factor scores: cross correlations for all 19 currency areas, since 1995",
xcat_labels=cfs_names,
start=start,
size=(14, 10)
)
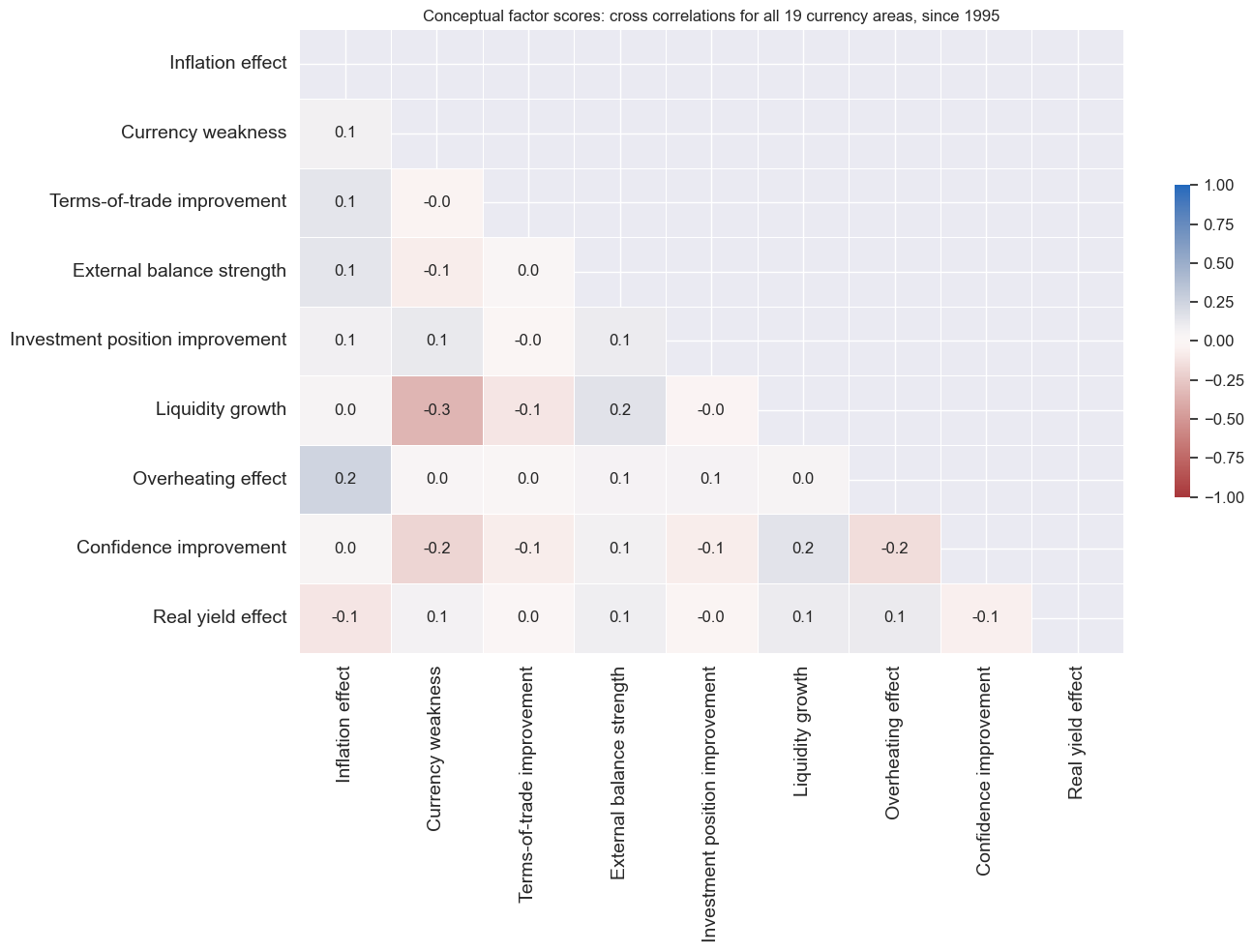
cidx = cids_eq
xcatx = list(cfs_names.keys())
start_date = "1995-01-01"
dfa = msp.make_relative_value(
dfx,
xcats=xcatx,
cids=cidx,
start=start_date,
blacklist=equsdblack,
rel_meth="subtract",
complete_cross=False,
postfix="vGLB",
)
dfx = msm.update_df(dfx, dfa)
xcatx = list(rcfs_names.keys())
msm.check_availability(
df=dfx,
xcats=xcatx,
cids=cids_eq,
missing_recent=False,
start="1995-01-01",
xcat_labels=rcfs_names,
)
cidx = cids_eq
xcatx = list(rcfs_names.keys())
start = "1995-01-01"
msp.correl_matrix(
dfx,
cids=cidx,
xcats=xcatx,
max_color=1.0,
annot=True,
fmt=".1f",
freq="M",
cluster=False,
title="Relative conceptual factor scores: cross correlations for all 19 currency areas, since 1995",
xcat_labels=rcfs_names,
start=start,
size=(14, 10)
)
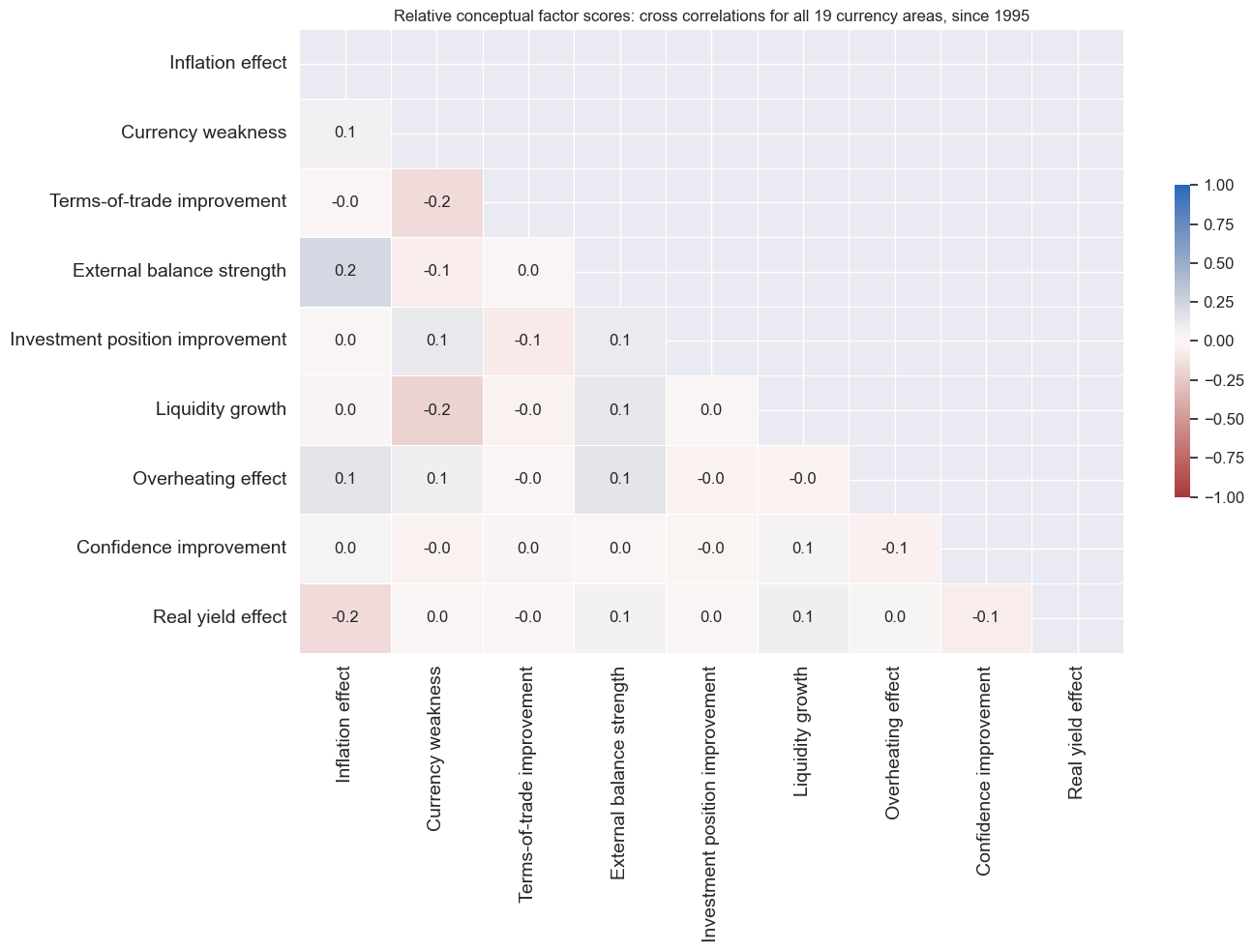
Conceptual risk-parity #
xcatx = list(rcfs_names.keys())
cidx = cids_eq
new_cat = "MACRO_REL"
dfa = msp.linear_composite(
dfx,
xcats=xcatx,
cids=cidx,
normalize_weights=True,
complete_xcats=False,
new_xcat=new_cat,
)
dfx = msm.update_df(dfx, dfa)
dfazn = msp.make_zn_scores(
dfx,
xcat=new_cat,
cids=cidx,
sequential=True,
min_obs=261 * 3,
neutral="zero",
pan_weight=1,
thresh=3,
postfix="_ZN",
est_freq="m",
)
dfx = msm.update_df(dfx, dfazn)
# Visualize
xcatx = ["MACRO_REL_ZN"]
cidx = cids_eq
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=5,
start="1995-01-01",
same_y=True,
)
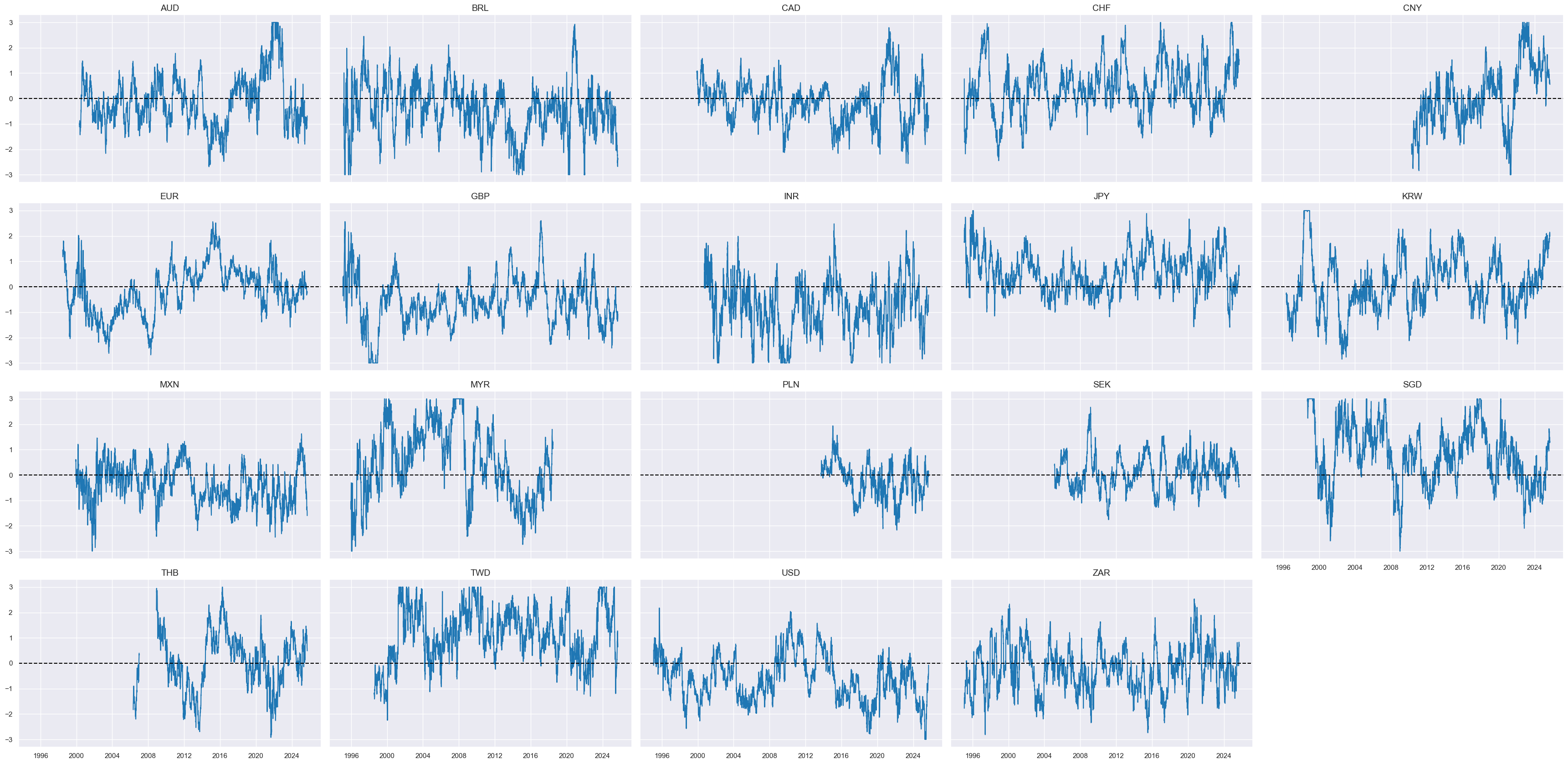
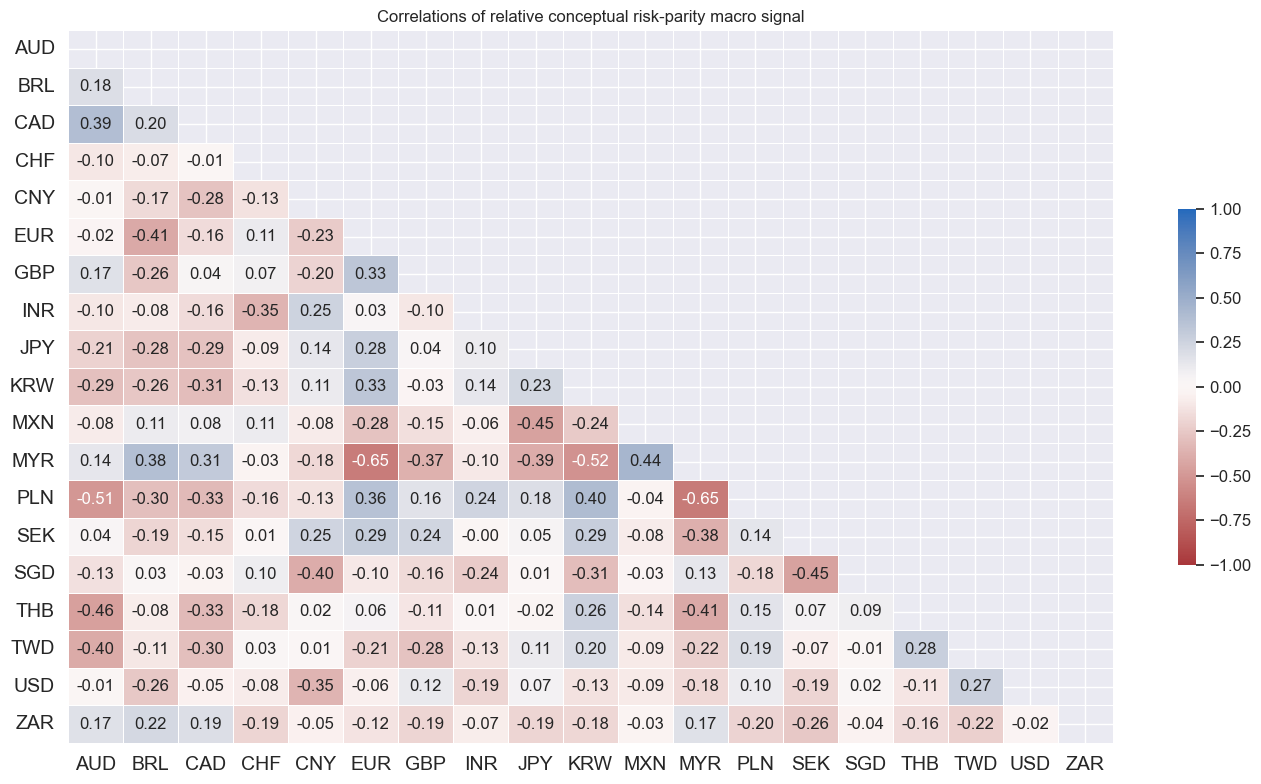
cidx = cids_eq
msp.correl_matrix(
dfx,
cids=cidx,
xcats=["MACRO_REL_ZN"],
max_color=1.0,
annot=True,
fmt=".2f",
cluster=False,
start="2000-01-01",
title="Correlations of relative conceptual risk-parity macro signal",
)
Targets #
Synthetic equity index returns in USD #
cidx = list(set(cids_eq) - {"USD"})
calcs = ["EQXRUSD_NSA = EQXR_NSA + FXXRUSD_NSA"]
dfa = msp.panel_calculator(dfx, calcs=calcs, cids=cidx)
dfx = msm.update_df(dfx, dfa)
calcs = ["EQXRUSD_NSA = EQXR_NSA"]
dfa = msp.panel_calculator(dfx, calcs=calcs, cids=["USD"])
dfx = msm.update_df(dfx, dfa)
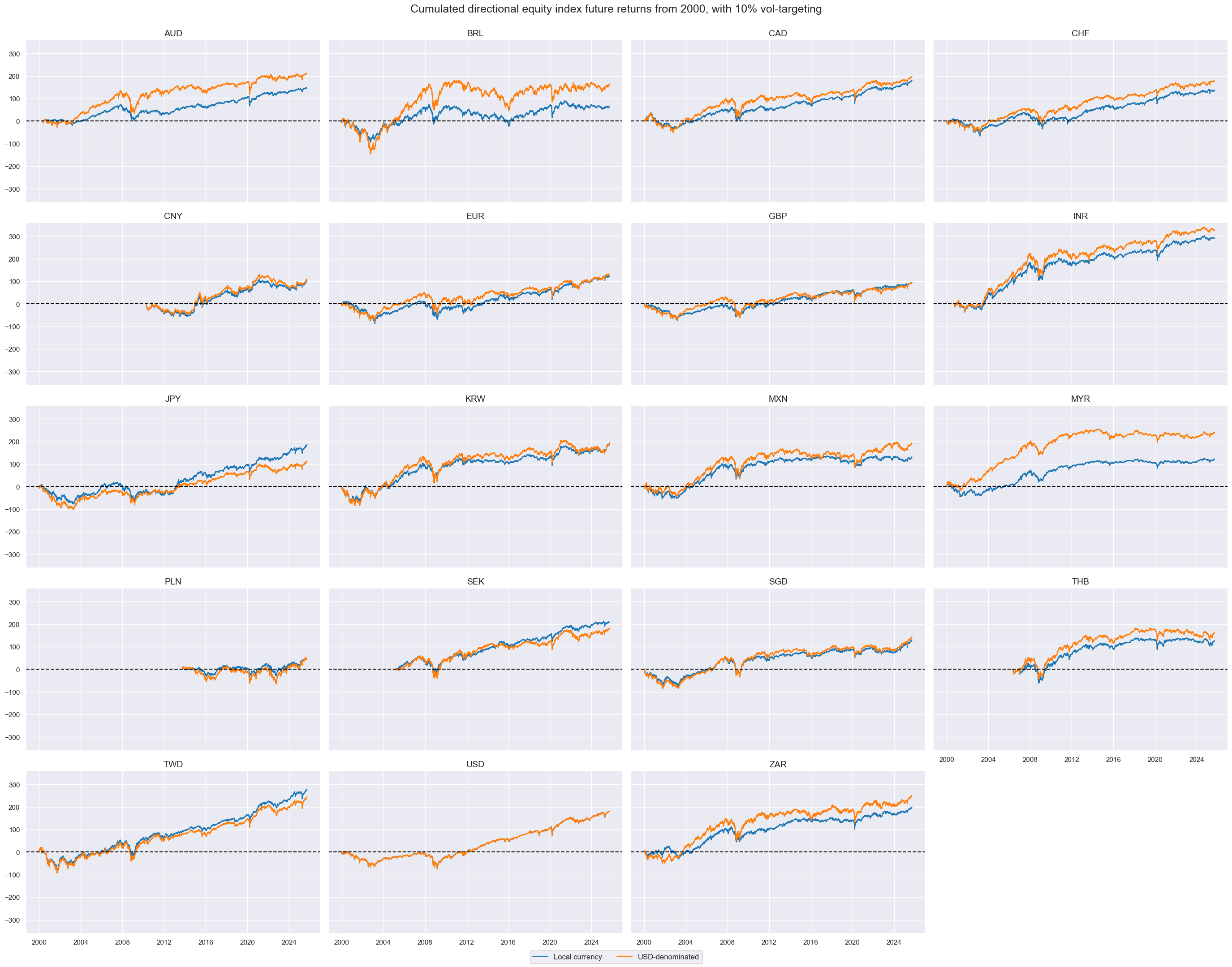
cidx = cids_eq
xcatx = ["EQXR_NSA", "EQXRUSD_NSA"]
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=4,
start="2000-01-01",
same_y=True,
cumsum=True,
title="Cumulated directional equity index future returns from 2000, with 10% vol-targeting",
xcat_labels=["Local currency", "USD-denominated"],
)
Vol-targeted country index returns in USD #
cidx = cids_eq
dfa = msp.historic_vol(
dfx,
xcat="EQXRUSD_NSA",
cids=cidx,
lback_meth="sq",
half_life=11,
lback_periods=37,
postfix="_ASD",
est_freq="M",
)
dfx = msm.update_df(dfx, dfa)
cidx = cids_eq
calcs = [
"EQXRUSD_NSA_ASDL1 = EQXRUSD_NSA_ASD.shift(1)",
"EQXRUSD_VT10 = 10 * EQXRUSD_NSA / EQXRUSD_NSA_ASDL1",
]
dfa = msp.panel_calculator(dfx, calcs=calcs, cids=cidx)
dfx = msm.update_df(dfx, dfa)
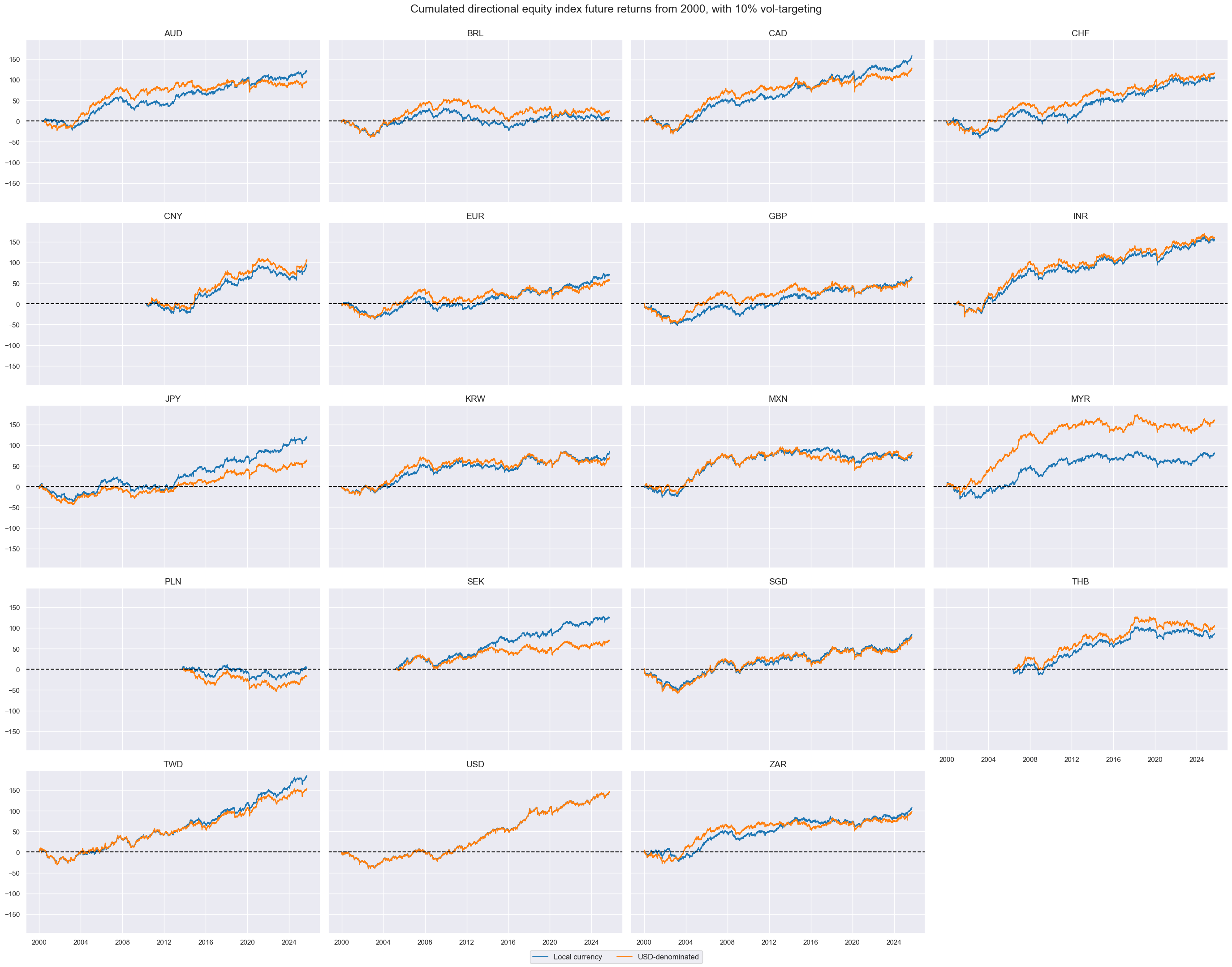
cidx = cids_eq
xcatx = ["EQXR_VT10", "EQXRUSD_VT10"]
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=4,
start="2000-01-01",
same_y=True,
cumsum=True,
title="Cumulated directional equity index future returns from 2000, with 10% vol-targeting",
xcat_labels=["Local currency", "USD-denominated"]
)
Relative country equity returns #
cidx = cids_eq
xcatx = ["EQXR_NSA", "EQXR_VT10"]
start_date = "1995-01-01"
dfa = msp.make_relative_value(
dfx,
xcats=xcatx,
cids=cidx,
start=start_date,
blacklist=None,
rel_meth="subtract",
complete_cross=False,
postfix="vGLB",
)
dfx = msm.update_df(dfx, dfa)
cidx = cids_eq
xcatx = ["EQXRUSD_NSA", "EQXRUSD_VT10", "EQCALLRUSD_NSA"]
start_date = "1995-01-01"
dfa = msp.make_relative_value(
dfx,
xcats=xcatx,
cids=cidx,
start=start_date,
blacklist=equsdblack, # Using the FX Blacklisting for returns in USD
rel_meth="subtract",
complete_cross=False,
postfix="vGLB",
)
dfx = msm.update_df(dfx, dfa)
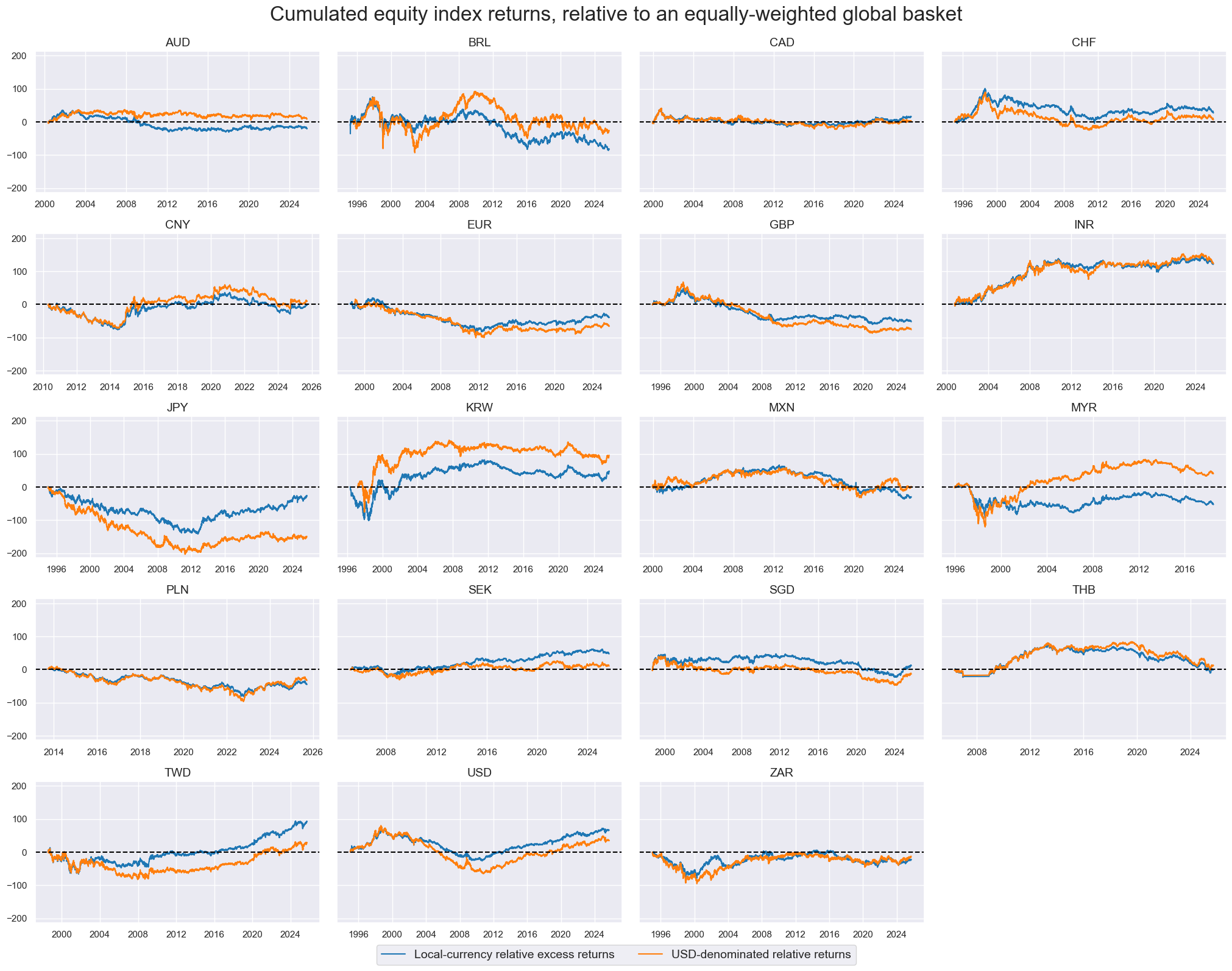
cidx = cids_eq
xcatx = ["EQXR_NSAvGLB", "EQXRUSD_NSAvGLB"]
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=4,
start="1995-01-01",
same_y=True,
cumsum=True,
all_xticks=True,
title="Cumulated equity index returns, relative to an equally-weighted global basket",
title_fontsize=24,
xcat_labels=["Local-currency relative excess returns", "USD-denominated relative returns"],
legend_fontsize=14,
height=2.1,
blacklist=equsdblack,
)
Value checks #
Statistical learning preparation #
default_learn_config = {
"scorer": {"negmse": make_scorer(mean_squared_error, greater_is_better=False)},
"splitter": {"Expanding": msl.ExpandingKFoldPanelSplit(n_splits=3)},
"split_functions": {"Expanding": lambda n: n // 24},
# retraining interval in months
"test_size": 3,
# minimum number of cids to start predicting
"min_cids": 2,
# minimum number of periods to start predicting
"min_periods": 24,
}
# List of dictionaries for two learning pipelines
learning_models = [
{
"ols": msl.ModifiedLinearRegression(method="analytic", positive=True),
"twls": msl.ModifiedTimeWeightedLinearRegression(method="analytic", positive=True),
},
{
"ridge": Ridge(positive=True),
},
]
# Hyperparameter grid
learning_grid = [
{
"ols": {"fit_intercept": [True, False]},
"twls": {"half_life": [12, 24, 36, 60], "fit_intercept": [True, False]},
},
{
"ridge": {
"fit_intercept": [True, False],
"alpha": [
1,
10,
100,
250,
500,
1000,
2000,
],
},
},
]
# list of tuples containg both the model specification and the corresponding hyperparameter grid search
model_and_grids = list(zip(learning_models, learning_grid))
default_start_date = "2002-12-31" # start date for the PnL analysis
Cross-country equity trading strategy #
dict_eq_rel = {
"sigs": ["MACRO_REL_ZN"] + list(rcfs_names.keys()),
"targs": ["EQXRUSD_VT10vGLB"],
"cidx": cids_eq,
"start": default_start_date,
"black": equsdblack,
"freq": "M",
"srr": None,
"pnls": None,
}
Statistical learning #
dix = dict_eq_rel
factors = list(rcfs_names.keys())
ret = dix["targs"][0]
cidx = dix["cidx"]
freq = dix["freq"]
blax = dix["black"]
trained_rel_models = {}
for pair in model_and_grids:
model, grid = pair
opt_pipeline_name = '-'.join(list(model.keys()))
signal_name = f"{opt_pipeline_name.upper()}_REL"
trained_rel_models[signal_name] = run_single_signal_optimizer(
df=dfx,
xcats=factors + [ret],
cids=cidx,
blacklist=blax,
signal_freq=freq,
signal_name=signal_name,
models=model,
hyperparameters=grid,
learning_config=default_learn_config,
)
dfa = trained_rel_models[signal_name].get_optimized_signals()
dfx = msm.update_df(dfx, dfa)
# z-scoring the expected returns for a given model
dfazn = msp.make_zn_scores(
dfx,
xcat=signal_name,
cids=cidx,
sequential=True,
min_obs=261 * 3,
neutral="zero",
pan_weight=1,
thresh=3,
postfix="_ZN",
est_freq="m",
)
dfx = msm.update_df(dfx, dfazn)
dix["models"] = trained_rel_models.values()
dix["sigs"] = list(set([x+"_ZN" for x in list(trained_rel_models.keys())] + dix["sigs"]))
dix = dict_eq_rel
trained_models = list(dix["models"])
learned_sigx = "OLS-TWLS_REL"
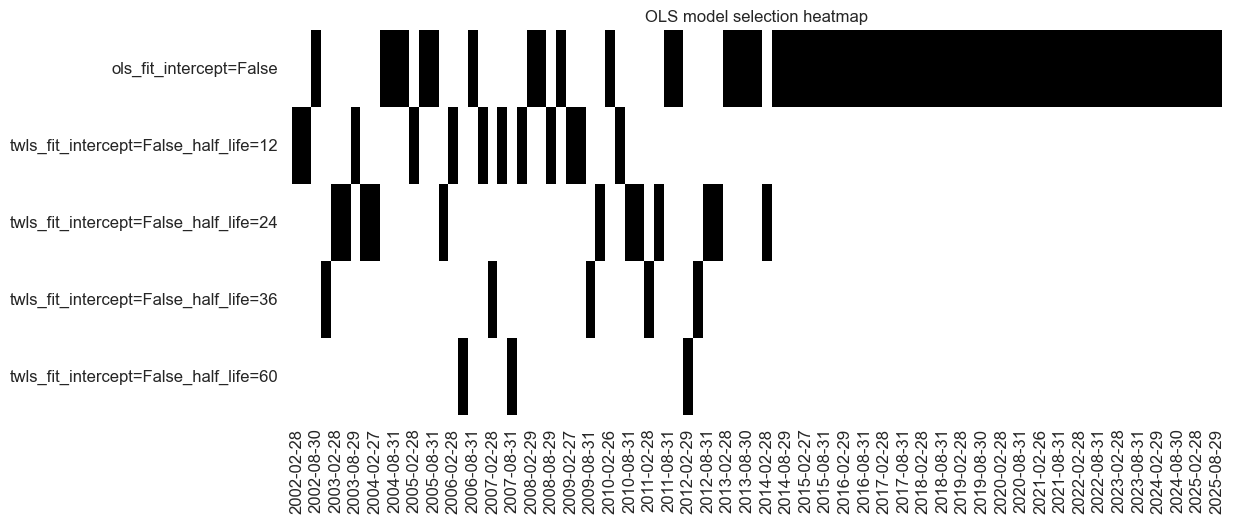
trained_models[0].models_heatmap(
learned_sigx,
cap=10,
figsize=(12, 5),
title=f"OLS model selection heatmap",
)
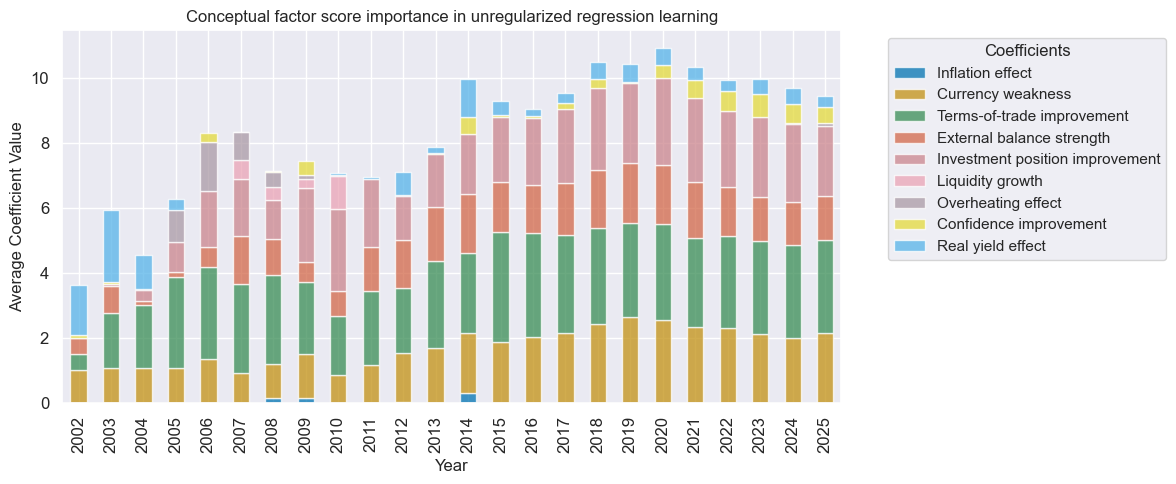
trained_models[0].coefs_stackedbarplot(
name=learned_sigx,
figsize=(12, 5),
ftrs_renamed=rcfs_names,
title="Conceptual factor score importance in unregularized regression learning",
)
dix = dict_eq_rel
trained_models = list(dix["models"])
learned_sigx = "RIDGE_REL"
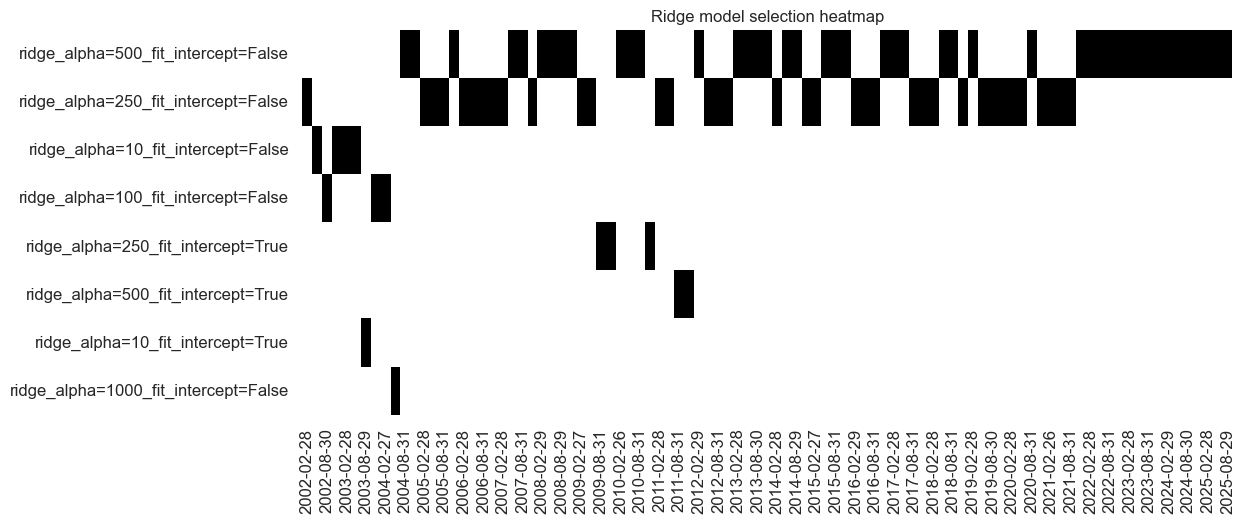
trained_models[1].models_heatmap(
learned_sigx,
cap=10,
figsize=(12, 5),
title="Ridge model selection heatmap",
)
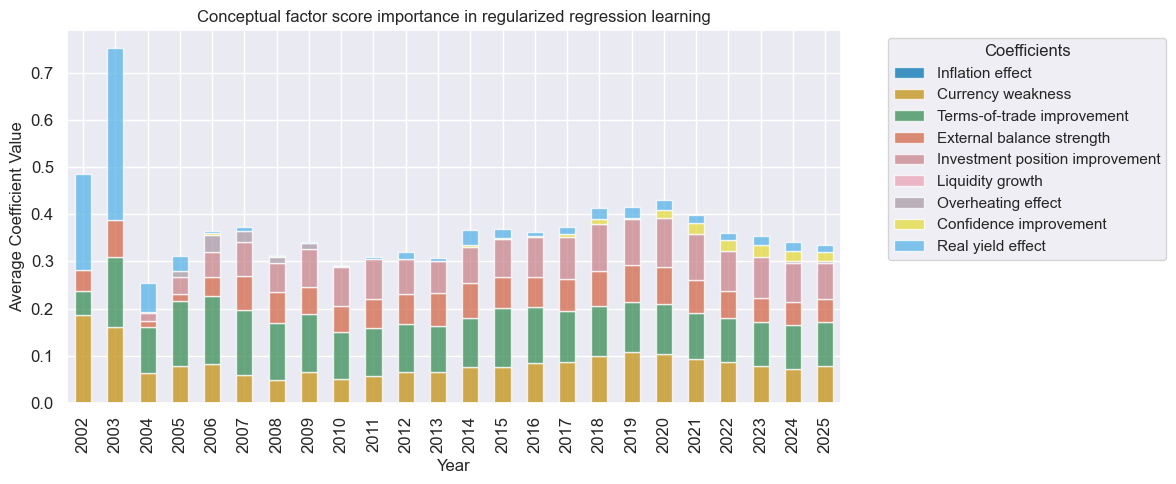
trained_models[1].coefs_stackedbarplot(
name=learned_sigx,
figsize=(12, 5),
ftrs_renamed=rcfs_names,
title="Conceptual factor score importance in regularized regression learning",
)
Specs and panel test #
dix = dict_eq_rel
cidx = dix["cidx"]
sigs = ["MACRO_REL_ZN", "OLS-TWLS_REL_ZN", "RIDGE_REL_ZN"]
targ = dix["targs"][0]
blax = dix["black"]
start = dix["start"]
catregs = {
x: msp.CategoryRelations(
df=dfx,
xcats=[x, targ],
cids=cidx,
freq="Q",
lag=1,
blacklist=blax,
xcat_aggs=["last", "sum"],
slip=1,
)
for x in sigs
}
dix["catregs"] = catregs
catregs = dix["catregs"]
msv.multiple_reg_scatter(
cat_rels=list(catregs.values())[1:],
ncol=2,
nrow=1,
figsize=(14, 8),
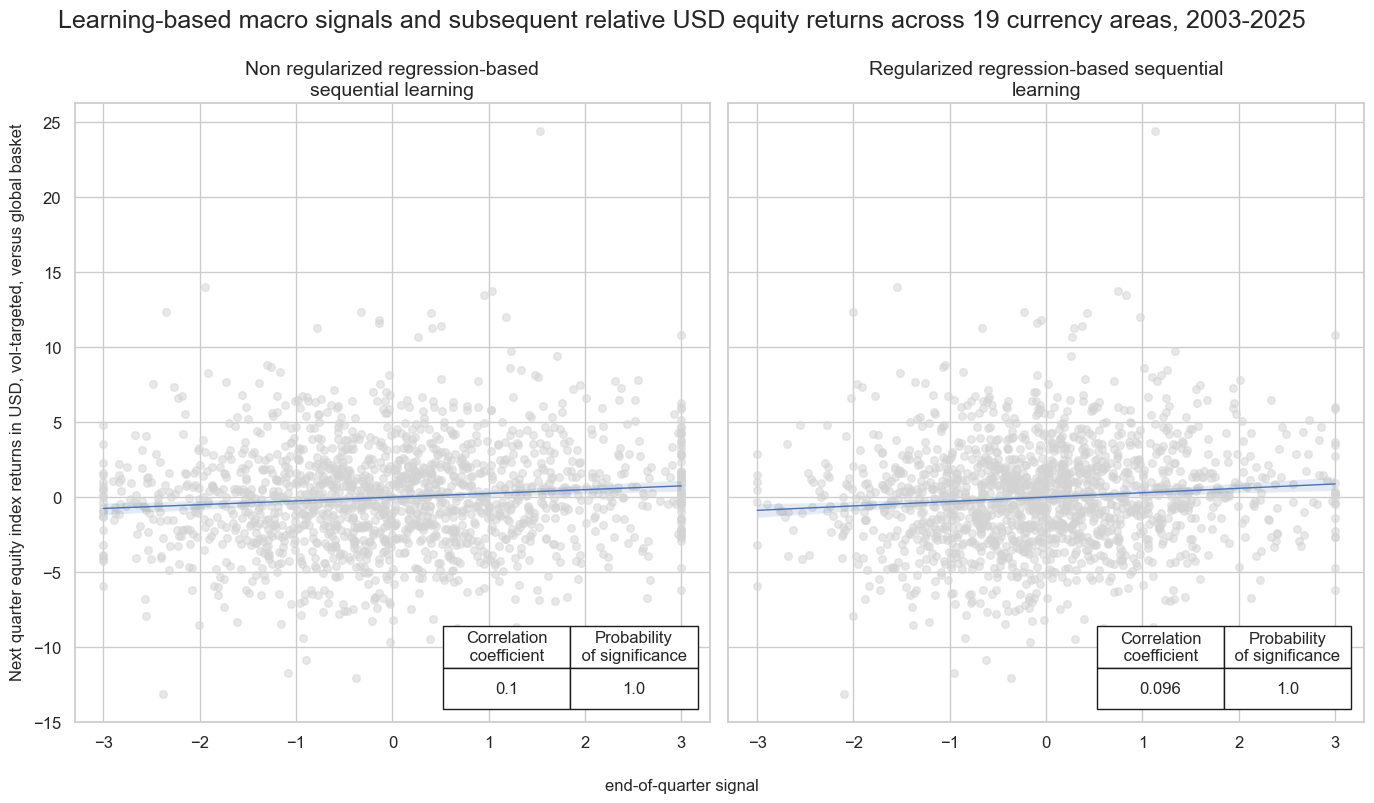
title=f"Learning-based macro signals and subsequent relative USD equity returns across 19 currency areas, 2003-2025",
title_xadj=0.5,
title_yadj=0.99,
title_fontsize=18,
xlab="end-of-quarter signal",
ylab="Next quarter equity index returns in USD, vol-targeted, versus global basket",
coef_box="lower right",
prob_est="map",
single_chart=True,
subplot_titles=[
"Non regularized regression-based sequential learning",
"Regularized regression-based sequential learning",
],
)
Accuracy and correlation check #
dix = dict_eq_rel
sigx = ["OLS-TWLS_REL_ZN", "RIDGE_REL_ZN"]
targx = dix["targs"]
cidx = dix["cidx"]
start = dix["start"]
blax = dix["black"]
srr = mss.SignalReturnRelations(
dfx,
cids=cidx,
sigs=sigx,
rets=targx,
freqs="M",
start=start,
blacklist=blax,
)
dix["srr"] = srr
dix = dict_eq_rel
srr = dix["srr"]
display(srr.multiple_relations_table().astype("float").round(3))
| accuracy | bal_accuracy | pos_sigr | pos_retr | pos_prec | neg_prec | pearson | pearson_pval | kendall | kendall_pval | auc | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Return | Signal | Frequency | Aggregation | |||||||||||
| EQXRUSD_VT10vGLB | OLS-TWLS_REL_ZN | M | last | 0.516 | 0.515 | 0.487 | 0.488 | 0.504 | 0.527 | 0.066 | 0.0 | 0.041 | 0.0 | 0.515 |
| RIDGE_REL_ZN | M | last | 0.519 | 0.518 | 0.481 | 0.488 | 0.507 | 0.530 | 0.069 | 0.0 | 0.042 | 0.0 | 0.518 |
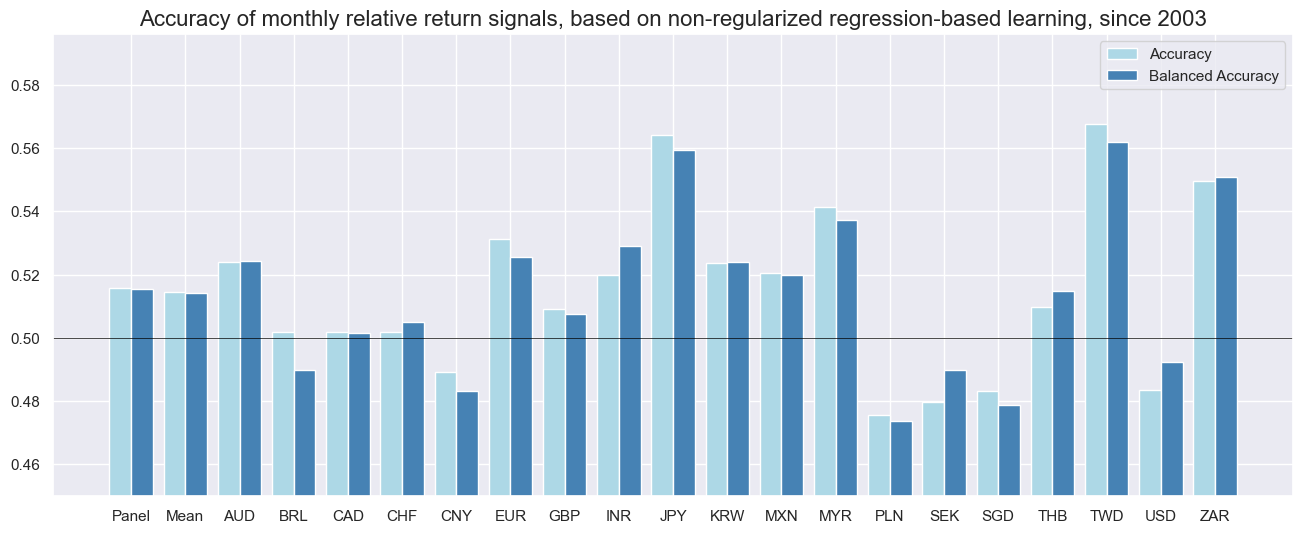
srr.accuracy_bars(
sigs=["OLS-TWLS_REL_ZN"],
type="cross_section",
title="Accuracy of monthly relative return signals, based on non-regularized regression-based learning, since 2003",
size=(16, 6),
)
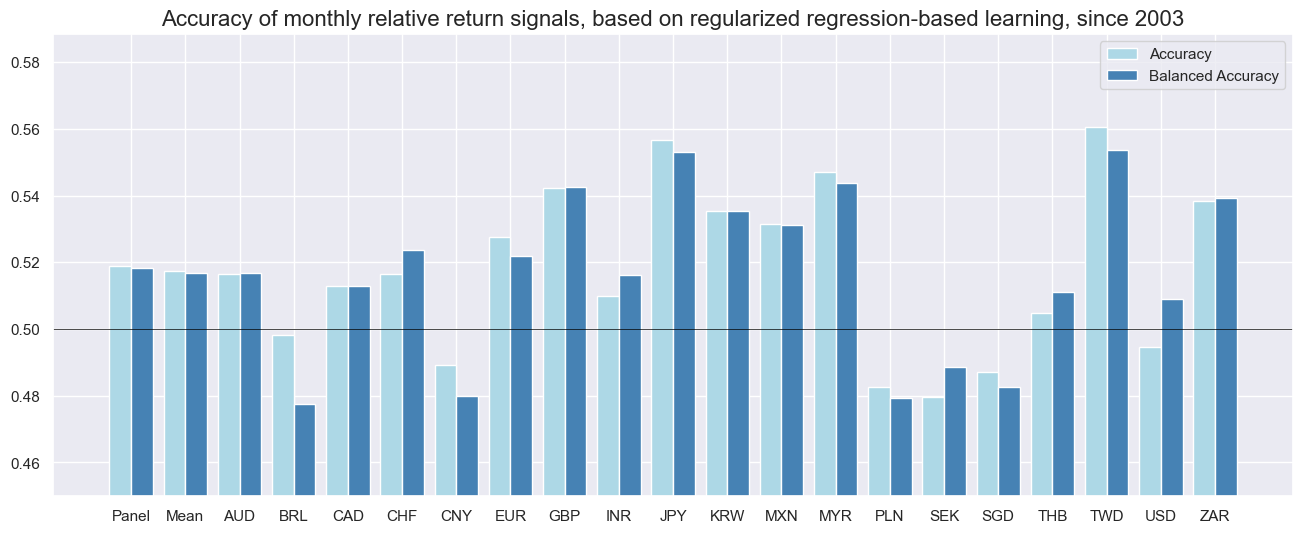
srr.accuracy_bars(
sigs=["RIDGE_REL_ZN"],
type="cross_section",
title="Accuracy of monthly relative return signals, based on regularized regression-based learning, since 2003",
size=(16, 6),
)
Naive PnL #
dix = dict_eq_rel
sigx = dix["sigs"]
targx = dix["targs"][0]
cidx = dix["cidx"]
start = dix["start"]
blax = dix["black"]
pnl = msn.NaivePnL(
df=dfx,
ret=targx,
sigs=sigx,
cids=cidx,
start=start,
blacklist=blax,
bms=["USD_EQXRUSD_VT10", "USD_DU05YXR_NSA", "GLD_COXR_NSA"],
)
for sig in sigx:
pnl.make_pnl(
sig=sig,
sig_op="zn_score_pan",
rebal_freq="monthly",
neutral="zero",
rebal_slip=1,
vol_scale=10,
thresh=3,
pnl_name=f"PNL_{sig}_PZN",
)
pnl.make_long_pnl(vol_scale=10, label="Long only")
dix["pnls"] = pnl
dix = dict_eq_rel
pnl = dix["pnls"]
sigx = [
"OLS-TWLS_REL_ZN",
"RIDGE_REL_ZN",
]
pns = [f"PNL_{sig}_PZN" for sig in sigx]
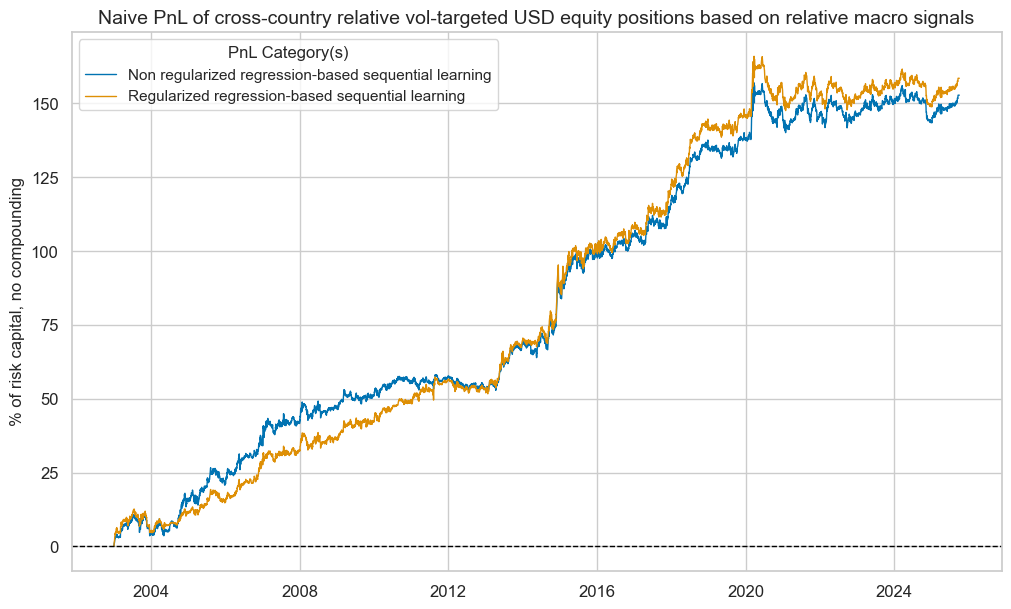
pnl.plot_pnls(
pnl_cats=pns,
title="Naive PnL of cross-country relative vol-targeted USD equity positions based on relative macro signals",
xcat_labels={
"PNL_OLS-TWLS_REL_ZN_PZN": "Non regularized regression-based sequential learning",
"PNL_RIDGE_REL_ZN_PZN": "Regularized regression-based sequential learning",
},
title_fontsize=14,
)
display(pnl.evaluate_pnls(pnl_cats=pns).astype("float").round(3))
| xcat | PNL_OLS-TWLS_REL_ZN_PZN | PNL_RIDGE_REL_ZN_PZN |
|---|---|---|
| Return % | 6.719 | 6.970 |
| St. Dev. % | 10.000 | 10.000 |
| Sharpe Ratio | 0.672 | 0.697 |
| Sortino Ratio | 0.979 | 1.016 |
| Max 21-Day Draw % | -7.851 | -8.401 |
| Max 6-Month Draw % | -12.200 | -13.513 |
| Peak to Trough Draw % | -16.853 | -18.377 |
| Top 5% Monthly PnL Share | 0.556 | 0.564 |
| USD_EQXRUSD_VT10 correl | -0.149 | -0.155 |
| USD_DU05YXR_NSA correl | 0.047 | 0.040 |
| GLD_COXR_NSA correl | 0.009 | 0.002 |
| Traded Months | 274.000 | 274.000 |
dix = dict_eq_rel
pnl = dix["pnls"]
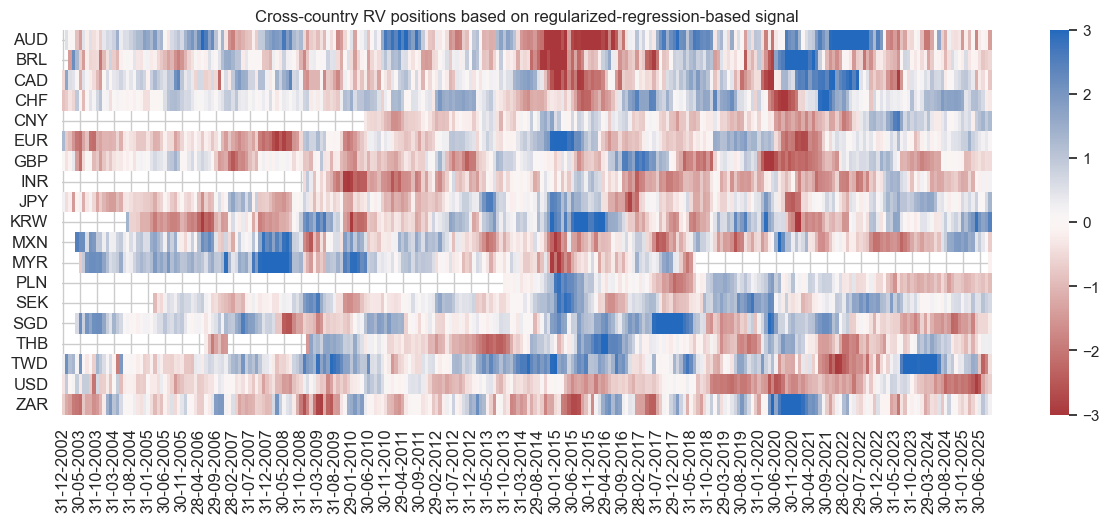
pnl.signal_heatmap(
pnl_name="PNL_RIDGE_REL_ZN_PZN",
title="Cross-country RV positions based on regularized-regression-based signal",
figsize=(15, 5),
)
dix = dict_eq_rel
pnl = dix["pnls"]
sigx = sorted(list(set(dix["sigs"]) - {"MACRO_REL_ZN", "OLS-TWLS_REL_ZN", "RIDGE_REL_ZN", "RF_REL_ZN"}))
pns = [f"PNL_{sig}_PZN" for sig in sigx]
pnl.plot_pnls(
pnl_cats=pns,
title="Cross-country equity PnLs based on single-concept macro signals",
title_fontsize=18,
xcat_labels={f"PNL_{k}_PZN": v for k, v in rcfs_names.items()},
facet=True
)
display(
pnl.evaluate_pnls(pnl_cats=pns).transpose().drop(columns="St. Dev. %").rename(index={f"PNL_{k}_PZN": v for k, v in rcfs_names.items()}).astype("float").round(2)
)
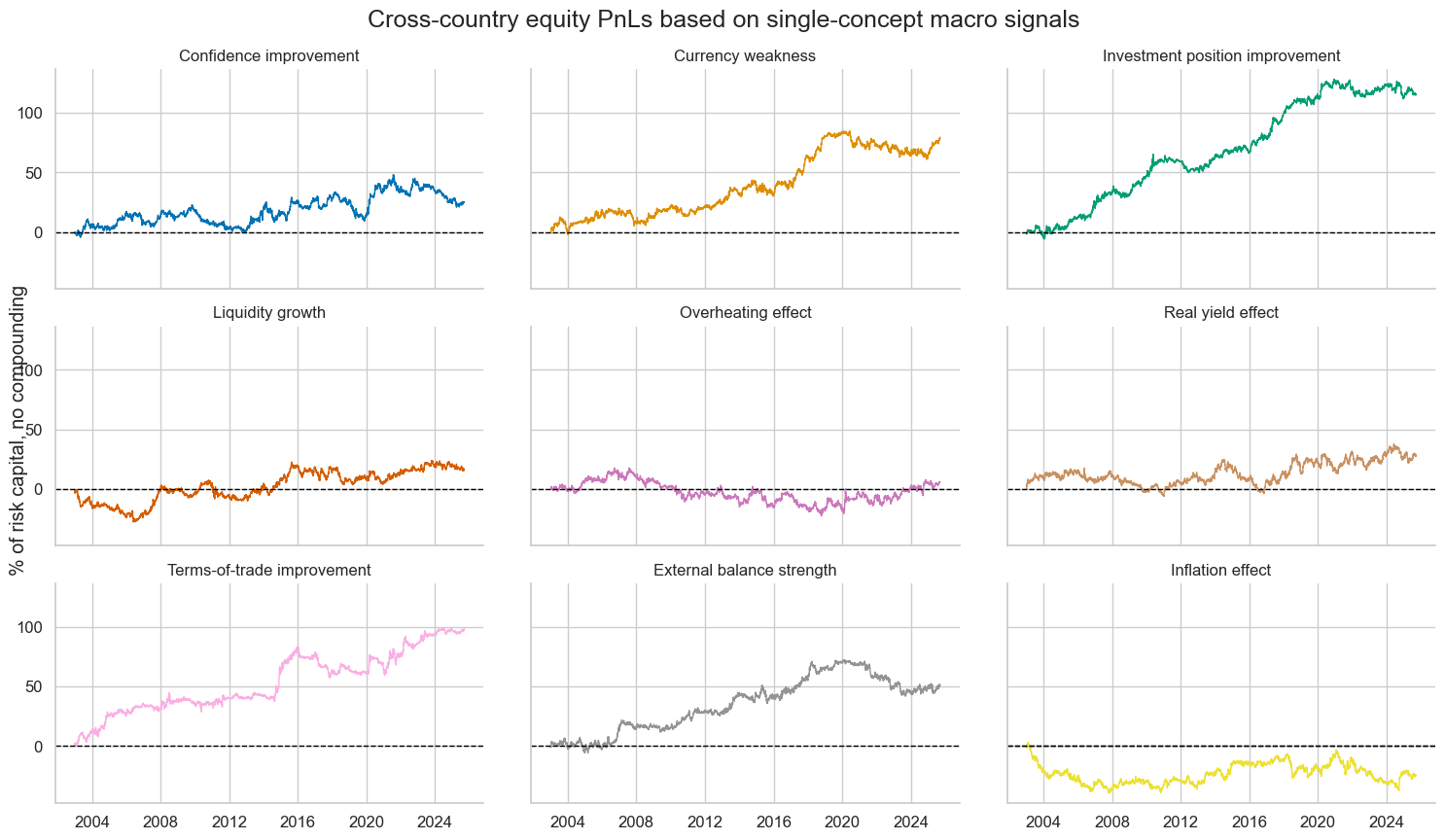
| Return % | Sharpe Ratio | Sortino Ratio | Max 21-Day Draw % | Max 6-Month Draw % | Peak to Trough Draw % | Top 5% Monthly PnL Share | USD_EQXRUSD_VT10 correl | USD_DU05YXR_NSA correl | GLD_COXR_NSA correl | Traded Months | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| xcat | |||||||||||
| Confidence improvement | 1.10 | 0.11 | 0.16 | -9.29 | -16.48 | -27.28 | 3.24 | 0.03 | 0.01 | 0.02 | 274.0 |
| Inflation effect | -1.09 | -0.11 | -0.15 | -11.69 | -19.61 | -42.41 | -2.86 | -0.20 | 0.03 | -0.02 | 274.0 |
| External balance strength | 2.25 | 0.23 | 0.32 | -9.36 | -13.07 | -30.68 | 1.35 | -0.32 | 0.06 | -0.04 | 274.0 |
| Liquidity growth | 0.70 | 0.07 | 0.10 | -8.79 | -13.86 | -27.21 | 4.76 | -0.22 | 0.05 | -0.03 | 274.0 |
| Terms-of-trade improvement | 4.37 | 0.44 | 0.63 | -11.68 | -13.68 | -25.93 | 1.01 | 0.07 | 0.02 | 0.04 | 274.0 |
| Investment position improvement | 5.08 | 0.51 | 0.72 | -8.55 | -11.07 | -16.45 | 0.61 | -0.13 | 0.03 | -0.02 | 274.0 |
| Real yield effect | 1.22 | 0.12 | 0.17 | -10.36 | -13.17 | -28.81 | 2.91 | -0.08 | 0.00 | 0.01 | 274.0 |
| Overheating effect | 0.26 | 0.03 | 0.04 | -9.24 | -13.78 | -40.40 | 11.16 | -0.27 | 0.04 | -0.04 | 274.0 |
| Currency weakness | 3.50 | 0.35 | 0.51 | -8.16 | -14.39 | -24.15 | 0.98 | -0.00 | -0.02 | -0.02 | 274.0 |
dix = dict_eq_rel
sigx = dix["sigs"]
targx = "EQXRUSD_NSAvGLB" # Simplification for trading
cidx = dix["cidx"]
start = dix["start"]
blax = dix["black"]
pnl = msn.NaivePnL(
df=dfx,
ret=targx,
sigs=sigx,
cids=cidx,
start=start,
blacklist=blax,
bms=["USD_EQXRUSD_VT10", "USD_DU05YXR_NSA", "GLD_COXR_NSA"],
)
for sig in sigx:
pnl.make_pnl(
sig=sig,
sig_op="zn_score_pan",
rebal_freq="monthly",
neutral="zero",
rebal_slip=1,
vol_scale=10,
thresh=3,
pnl_name=f"PNL_{sig}_PZN",
)
pnl.make_long_pnl(vol_scale=10, label="Long only")
dix["pnls_nsa"] = pnl
dix = dict_eq_rel
pnl = dix["pnls_nsa"]
sigx = [
"OLS-TWLS_REL_ZN",
"RIDGE_REL_ZN",
]
pns = [f"PNL_{sig}_PZN" for sig in sigx]
pnl.plot_pnls(
pnl_cats=pns,
title="Naive PnL of cross-country relative notional USD equity positions based on relative macro signals",
xcat_labels={
"PNL_OLS-TWLS_REL_ZN_PZN": "Non regularized regression-based sequential learning",
"PNL_RIDGE_REL_ZN_PZN": "Regularized regression-based sequential learning",
},
title_fontsize=14,
)
display(pnl.evaluate_pnls(pnl_cats=pns).astype("float").round(3))
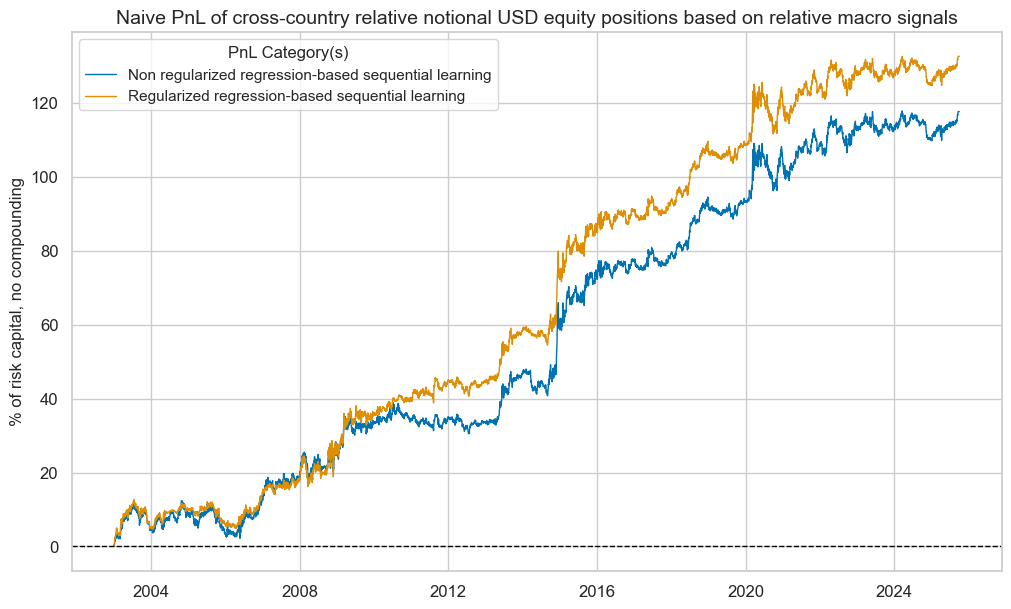
| xcat | PNL_OLS-TWLS_REL_ZN_PZN | PNL_RIDGE_REL_ZN_PZN |
|---|---|---|
| Return % | 5.172 | 5.830 |
| St. Dev. % | 10.000 | 10.000 |
| Sharpe Ratio | 0.517 | 0.583 |
| Sortino Ratio | 0.753 | 0.850 |
| Max 21-Day Draw % | -7.681 | -7.312 |
| Max 6-Month Draw % | -11.172 | -11.658 |
| Peak to Trough Draw % | -12.831 | -13.941 |
| Top 5% Monthly PnL Share | 0.705 | 0.642 |
| USD_EQXRUSD_VT10 correl | -0.134 | -0.146 |
| USD_DU05YXR_NSA correl | 0.045 | 0.047 |
| GLD_COXR_NSA correl | -0.007 | -0.021 |
| Traded Months | 274.000 | 274.000 |
Global equities cash proxy and relative value modification #
Equal weighted global cash equity portfolio #
xcatx = ["EQCALLRUSD_NSA"]
msm.check_availability(df=dfx, xcats=xcatx, cids=cids_eq, missing_recent=False)

cidx = cids_eq
# Simple weight in the global equity basket for each country when the equity futures start being traded
calcs = [
"GEQPWGT = 0 * EQXRUSD_NSA + 1",
]
dfa = msp.panel_calculator(dfx, calcs=calcs, cids=cidx)
dfa["tot_cids"] = dfa.groupby(["real_date", "xcat"])["value"].transform("count")
dfa["value"] = dfa["value"] / dfa["tot_cids"]
dfx = msm.update_df(dfx, dfa.drop(columns=["tot_cids"]))
JPMaQS macro-aware global cash equity modification #
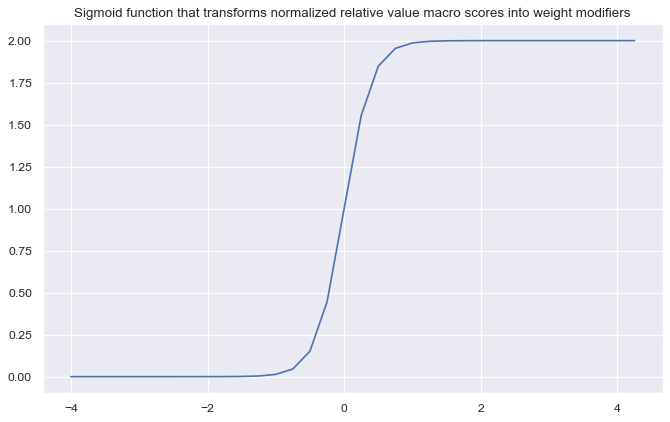
# Define appropriate sigmoid function for adjusting weights
amplitude = 2
steepness = 5
midpoint = 0
def sigmoid(x, a=amplitude, b=steepness, c=midpoint):
return a / (1 + np.exp(-b * (x - c)))
ar = np.array([i / 4 for i in range(-16, 18)])
plt.figure(figsize=(10, 6), dpi=80)
plt.plot(ar, sigmoid(ar))
plt.title("Sigmoid function that transforms normalized relative value macro scores into weight modifiers")
plt.show()
# Calculate adjusted weights
cidx = cids_eq
dfj = adjust_weights(
dfx,
weights_xcat="GEQPWGT",
adj_zns_xcat="RIDGE_REL_ZN",
method="generic",
adj_func=sigmoid,
blacklist=equsdblack,
cids=cidx,
adj_name="GEQPWGT_MOD",
)
dfx = msm.update_df(dfx, dfj)
# Visualize weights
cidx = cids_eq
xcatx = ["GEQPWGT", "GEQPWGT_MOD"]
# Reduce frequency to monthly in accordance with PnL simulation
for xc in xcatx:
dfa = dfx.loc[dfx["xcat"] == xc]
dfa["last_period_bd"] = pd.to_datetime(dfa["real_date"]) + pd.tseries.offsets.BQuarterEnd(0)
mask = pd.to_datetime(dfa["last_period_bd"]) == pd.to_datetime(dfa["real_date"])
dfa.loc[~mask, "value"] = np.nan
dfa["value"] = dfa.groupby("cid")["value"].ffill(limit=75) # max 25 business days
dfa = dfa.drop(columns="xcat").assign(xcat=f"{xc}_M")
dfx = msm.update_df(dfx, dfa)
xcatxx =[xc + "_M" for xc in xcatx]
msp.view_timelines(
dfx,
xcats=xcatxx,
cids=cidx,
ncol=4,
start="2003-01-01",
same_y=False,
cumsum=False,
title="Equal and macro signal-based weights of countries in a global USD-based equity portfolio",
title_fontsize=22,
xcat_labels=["Equal weighting allocation", "Macro signal-based allocation"],
height=1.5,
aspect=2.2,
legend_fontsize=16,
)

Long-only US Equity portfolio #
cidx = ["USD"]
calcs = [
# Always long one unit of US equity
"USEQPWGT = 0 * EQCALLRUSD_NSA + 1",
]
dfa = msp.panel_calculator(dfx, calcs=calcs, cids=cidx)
dfx = msm.update_df(dfx, dfa)
Evaluation #
dict_mod = {
"sigs": ["GEQPWGT", "GEQPWGT_MOD", "USEQPWGT"],
"targ": "EQCALLRUSD_NSA",
"cidx": cids_eq,
"start": default_start_date,
"black": equsdblack,
"srr": None,
"pnls": None,
}
dix = dict_mod
sigs = dix["sigs"]
ret = dix["targ"]
cidx = dix["cidx"]
start = dix["start"]
black = dix["black"]
pnls = msn.NaivePnL(
df=dfx,
ret=ret,
sigs=sigs,
cids=cidx,
start=start,
blacklist=black,
bms=["USD_EQXRUSD_NSA", "USD_DU05YXR_NSA", "GLD_COXR_NSA"],
)
for sig in sigs:
pnls.make_pnl(
sig=sig,
sig_op="raw",
rebal_freq="quarterly",
neutral="zero",
rebal_slip=1,
vol_scale=10,
)
dix["pnls"] = pnls
dix = dict_mod
pnls = dix["pnls"]
sigs = dix["sigs"]
pnl_cats = ["PNL_" + sig for sig in sigs[:3]]
pnls.plot_pnls(
pnl_cats=pnl_cats,
title="Long-only naive PnLs, equalized for volatility",
title_fontsize=14,
compounding=False,
xcat_labels={
"PNL_GEQPWGT": "Equal weights for all tradable currency areas",
"PNL_GEQPWGT_MOD": "Macro signal-based weights for all tradable currency areas",
"PNL_USEQPWGT": "Long-only US equity",
},
)
pnls.evaluate_pnls(pnl_cats=pnl_cats)
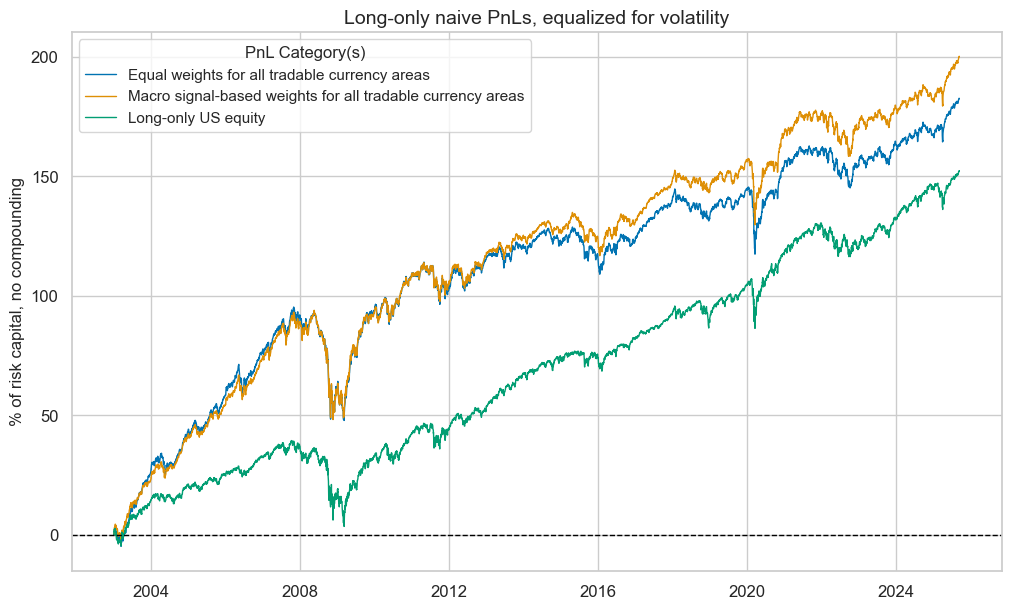
| xcat | PNL_GEQPWGT | PNL_GEQPWGT_MOD | PNL_USEQPWGT |
|---|---|---|---|
| Return % | 8.034343 | 8.810116 | 6.709842 |
| St. Dev. % | 10.0 | 10.0 | 10.0 |
| Sharpe Ratio | 0.803434 | 0.881012 | 0.670984 |
| Sortino Ratio | 1.119107 | 1.239666 | 0.943701 |
| Max 21-Day Draw % | -27.8237 | -27.027875 | -20.054564 |
| Max 6-Month Draw % | -43.639174 | -44.046311 | -29.277215 |
| Peak to Trough Draw % | -47.499061 | -45.752625 | -35.975968 |
| Top 5% Monthly PnL Share | 0.523126 | 0.492656 | 0.449502 |
| USD_EQXRUSD_NSA correl | 0.586539 | 0.552719 | 0.983719 |
| USD_DU05YXR_NSA correl | -0.131953 | -0.121444 | -0.234115 |
| GLD_COXR_NSA correl | 0.223277 | 0.211727 | 0.020789 |
| Traded Months | 274 | 274 | 274 |
dix = dict_mod
sigs = dix["sigs"]
ret = dix["targ"]
cidx = dix["cidx"]
start = dix["start"]
black = dix["black"]
pnls = msn.NaivePnL(
df=dfx,
ret=ret,
sigs=sigs,
cids=cidx,
start=start,
blacklist=black,
bms=["USD_EQXRUSD_NSA", "USD_DU05YXR_NSA", "GLD_COXR_NSA"],
)
for sig in sigs:
pnls.make_pnl(
sig=sig,
sig_op="raw",
rebal_freq="quarterly",
neutral="zero",
rebal_slip=1,
vol_scale=None,
)
dix["pnls_cash"] = pnls
dix = dict_mod
pnls = dix["pnls_cash"]
sigs = dix["sigs"]
pnl_cats = ["PNL_" + sig for sig in sigs]
pnls.plot_pnls(
pnl_cats=pnl_cats,
title="Long-only approximate USD cash PnLs with compounding",
title_fontsize=14,
compounding=True,
xcat_labels={
"PNL_GEQPWGT": "Equal weights for all tradable currency areas",
"PNL_GEQPWGT_MOD": "Macro signal-based weights for all tradable currency areas",
"PNL_USEQPWGT": "Long-only US equity",
},
)
pnls.evaluate_pnls(pnl_cats=pnl_cats)
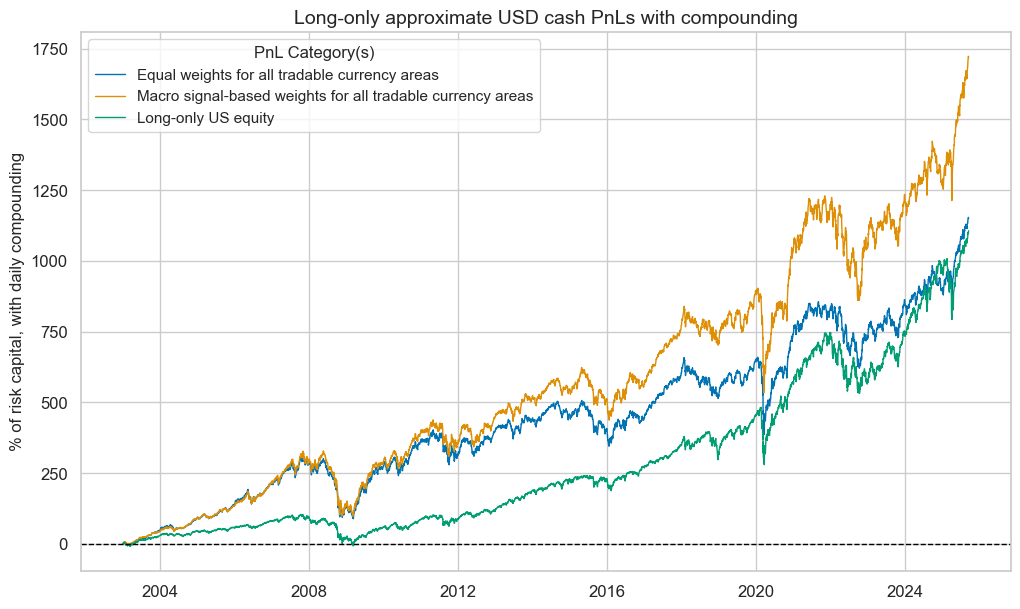
| xcat | PNL_GEQPWGT | PNL_GEQPWGT_MOD | PNL_USEQPWGT |
|---|---|---|---|
| Return % | 12.295792 | 14.0472 | 12.787229 |
| St. Dev. % | 15.304042 | 15.944399 | 19.057422 |
| Sharpe Ratio | 0.803434 | 0.881012 | 0.670984 |
| Sortino Ratio | 1.119107 | 1.239666 | 0.943701 |
| Max 21-Day Draw % | -42.581507 | -43.094323 | -38.21883 |
| Max 6-Month Draw % | -66.785574 | -70.229196 | -55.794825 |
| Peak to Trough Draw % | -72.692761 | -72.949812 | -68.560921 |
| Top 5% Monthly PnL Share | 0.523126 | 0.492656 | 0.449502 |
| USD_EQXRUSD_NSA correl | 0.586539 | 0.552719 | 0.983719 |
| USD_DU05YXR_NSA correl | -0.131953 | -0.121444 | -0.234115 |
| GLD_COXR_NSA correl | 0.223277 | 0.211727 | 0.020789 |
| Traded Months | 274 | 274 | 274 |