Merchandise import as predictor of duration returns #
This notebook offers the necessary code to replicate the research findings discussed in Macrosynergy’s post “Merchandise import as predictor of duration returns”. Its primary objective is to inspire readers to explore and conduct additional investigations while also providing a foundation for testing their own unique ideas.
Get packages and JPMaQS data #
This notebook primarily relies on the standard packages available in the Python data science stack. However, there is an additional package
macrosynergy
that is required for two purposes:
-
Downloading JPMaQS data: The
macrosynergypackage facilitates the retrieval of JPMaQS data, which is used in the notebook. -
For the analysis of quantamental data and value propositions: The
macrosynergypackage provides functionality for performing quick analyses of quantamental data and exploring value propositions.
For detailed information and a comprehensive understanding of the
macrosynergy
package and its functionalities, please refer to the
“Introduction to Macrosynergy package”
on the Macrosynergy Academy or visit the following link on
Kaggle
.
"""!pip install macrosynergy --upgrade"""
'!pip install macrosynergy --upgrade'
import numpy as np
import pandas as pd
from pandas import Timestamp
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
import os
from datetime import date
import macrosynergy.management as msm
import macrosynergy.panel as msp
import macrosynergy.signal as mss
import macrosynergy.pnl as msn
from macrosynergy.download import JPMaQSDownload
warnings.simplefilter("ignore")
First, we specify the cross-sections to download, which are used in the notebook. The cross-sections are grouped in lists for further analysis:
cids_g3 = ["EUR", "JPY", "USD"] # DM large currency areas
# IRS cross-section lists
cids_dmsc_du = ["AUD", "CAD", "CHF", "GBP", "NOK", "NZD", "SEK"]
cids_latm_du = ["CLP", "COP", "MXN"]
cids_emea_du = [
"CZK",
"HUF",
"ILS",
"PLN",
"TRY",
"ZAR",
]
cids_emas_du = ["CNY", "IDR", "INR", "KRW", "MYR", "SGD", "THB", "TWD"]
cids_dmdu = cids_g3 + cids_dmsc_du
cids_emdu = cids_latm_du + cids_emea_du + cids_emas_du
cids_du = cids_dmdu + cids_emdu
cids_dodgy = ["MYR", "TRY"] # missing or compromised data
cids_dux = list(set(cids_du) - set(cids_dodgy))
cids = cids_dux # widest set required for this notebook
JPMaQS indicators are conveniently grouped into 6 main categories: Economic Trends, Macroeconomic balance sheets, Financial conditions, Shocks and risk measures, Stylized trading factors, and Generic returns. Each indicator has a separate page with notes, description, availability, statistical measures, and timelines for main currencies. The description of each JPMaQS category is available either under Macro Quantamental Academy , JPMorgan Markets (password protected). In particular, the indicators used in this notebook could be found under Foreign trade trends , Real interest rates , Inflation expectations (Macrosynergy method) , Equity index future returns , and Duration returns .
# Category tickers
main = [
"IMPORTS_SA_P3M3ML3AR",
"IMPORTS_SA_P6M6ML6AR",
"IMPORTS_SA_P1M1ML12",
"IMPORTS_SA_P1M1ML12_3MMA",
]
xtra = [
"RYLDIRS02Y_NSA",
"RYLDIRS05Y_NSA",
"INFE1Y_JA",
"INFE2Y_JA",
"INFE5Y_JA",
]
rets = [
"EQXR_NSA",
"DU02YXR_VT10",
"DU05YXR_VT10",
]
xcats = main + rets + xtra
# Resultant tickers
tickers = [cid + "_" + xcat for cid in cids for xcat in xcats]
print(f"Maximum number of tickers is {len(tickers)}")
Maximum number of tickers is 300
# Download series from J.P. Morgan DataQuery by tickers
client_id: str = os.getenv("DQ_CLIENT_ID")
client_secret: str = os.getenv("DQ_CLIENT_SECRET")
with JPMaQSDownload(oauth=True, client_id=client_id, client_secret=client_secret) as dq:
assert dq.check_connection()
df = dq.download(
tickers=tickers,
start_date="2000-01-01",
suppress_warning=True,
metrics=["value"],
)
assert isinstance(df, pd.DataFrame) and not df.empty
print("Last updated:", date.today())
Downloading data from JPMaQS.
Timestamp UTC: 2025-06-25 12:05:43
Connection successful!
Some expressions are missing from the downloaded data. Check logger output for complete list.
8 out of 300 expressions are missing. To download the catalogue of all available expressions and filter the unavailable expressions, set `get_catalogue=True` in the call to `JPMaQSDownload.download()`.
Last updated: 2025-06-25
dfx = df.copy().sort_values(["cid", "xcat", "real_date"])
dfx.info()
<class 'pandas.core.frame.DataFrame'>
Index: 1830912 entries, 32843 to 1778141
Data columns (total 4 columns):
# Column Dtype
--- ------ -----
0 real_date datetime64[ns]
1 cid object
2 xcat object
3 value float64
dtypes: datetime64[ns](1), float64(1), object(2)
memory usage: 69.8+ MB
Availability #
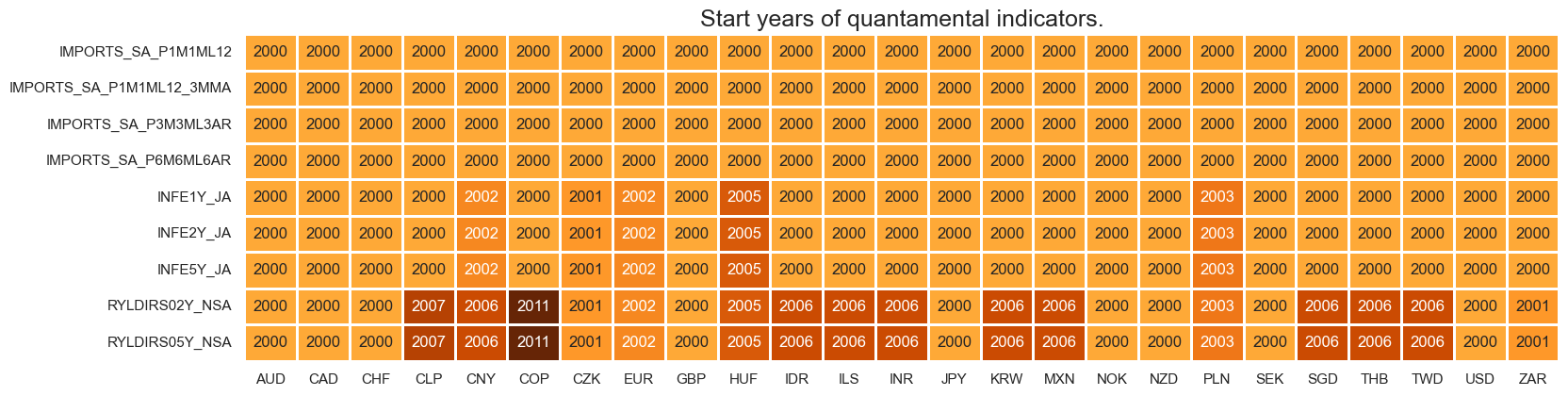
It is important to assess data availability before conducting any analysis. It allows to identify any potential gaps or limitations in the dataset, which can impact the validity and reliability of analysis and ensure that a sufficient number of observations for each selected category and cross-section is available as well as determining the appropriate time periods for analysis.
msm.missing_in_df(df, xcats=xcats, cids=cids)
No missing XCATs across DataFrame.
Missing cids for DU02YXR_VT10: []
Missing cids for DU05YXR_VT10: []
Missing cids for EQXR_NSA: ['CLP', 'COP', 'CZK', 'HUF', 'IDR', 'ILS', 'NOK', 'NZD']
Missing cids for IMPORTS_SA_P1M1ML12: []
Missing cids for IMPORTS_SA_P1M1ML12_3MMA: []
Missing cids for IMPORTS_SA_P3M3ML3AR: []
Missing cids for IMPORTS_SA_P6M6ML6AR: []
Missing cids for INFE1Y_JA: []
Missing cids for INFE2Y_JA: []
Missing cids for INFE5Y_JA: []
Missing cids for RYLDIRS02Y_NSA: []
Missing cids for RYLDIRS05Y_NSA: []
msm.check_availability(df, xcats=main + xtra, cids=cids)
Transformations and checks #
Features #
Excess import growth #
Here we create new categories to measure the excess import growth over 2-year and 5-year nominal yields. These categories will be denoted by the postfixes
v2YLD
or
v5YLD
.
First, we approximate nominal IRS yields as the sum of real yields and inflation expectations, creating new categories
NYLDIRS02Y_NSA
and
NYLDIRS05Y_NSA
. Then, these categories are subtracted from corresponding import trends.
By following this process, you can create new categories to represent the excess import growth over the 2-year and 5-year nominal yields in your dataset.
imps = [
"IMPORTS_SA_P3M3ML3AR",
"IMPORTS_SA_P6M6ML6AR",
"IMPORTS_SA_P1M1ML12_3MMA",
]
calcs = [
"NYLDIRS02Y_NSA = RYLDIRS02Y_NSA + INFE2Y_JA", # 2Y nominal yield proxy
"NYLDIRS05Y_NSA = RYLDIRS05Y_NSA + INFE5Y_JA", # 5Y nominal yield proxy
]
for m in imps:
calcs += (
f"{m}v2YLD = {m} - NYLDIRS02Y_NSA",
) # excess import growth over 2-year nominal yield
calcs += (
f"{m}v5YLD = {m} - NYLDIRS05Y_NSA",
) # excess import growth over 5-year nominal yield
dfa = msp.panel_calculator(dfx, calcs=calcs, cids=cids)
dfx = msm.update_df(dfx, dfa)
The
macrosynergy
package provides two useful functions,
view_ranges()
and
view_timelines()
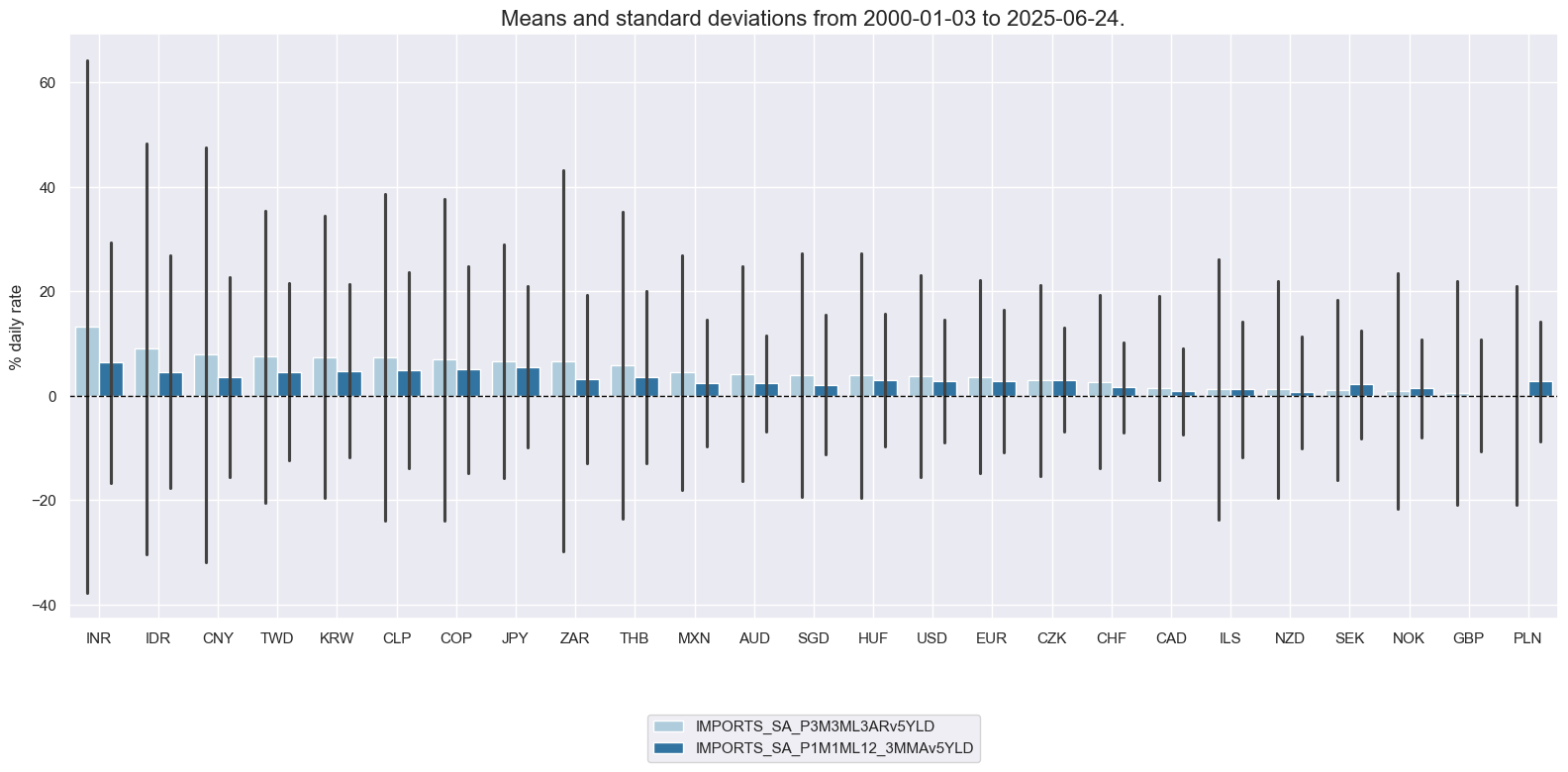
, which facilitate the convenient visualization of data for selected indicators and cross-sections. These functions assist in plotting means, standard deviations, and time series of the chosen indicators. In the cell below we plot the newly created excess import growth over 2-year and 5-year nominal yield:
xcatx = [
"IMPORTS_SA_P3M3ML3ARv5YLD", # Excess import growth, seasonally and calendar adjusted: % 3m/3m
"IMPORTS_SA_P1M1ML12_3MMAv5YLD", # Excess import growth, seasonally and calendar adjusted: % over a year ago, 3-month moving average
]
cidx = cids_dux
msp.view_ranges(
dfx,
cids=cidx,
xcats=xcatx,
kind="bar",
sort_cids_by="mean",
ylab="% daily rate",
start="2000-01-01",
)
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=4,
cumsum=False,
start="2000-01-01",
same_y=False,
size=(12, 12),
all_xticks=True,
)
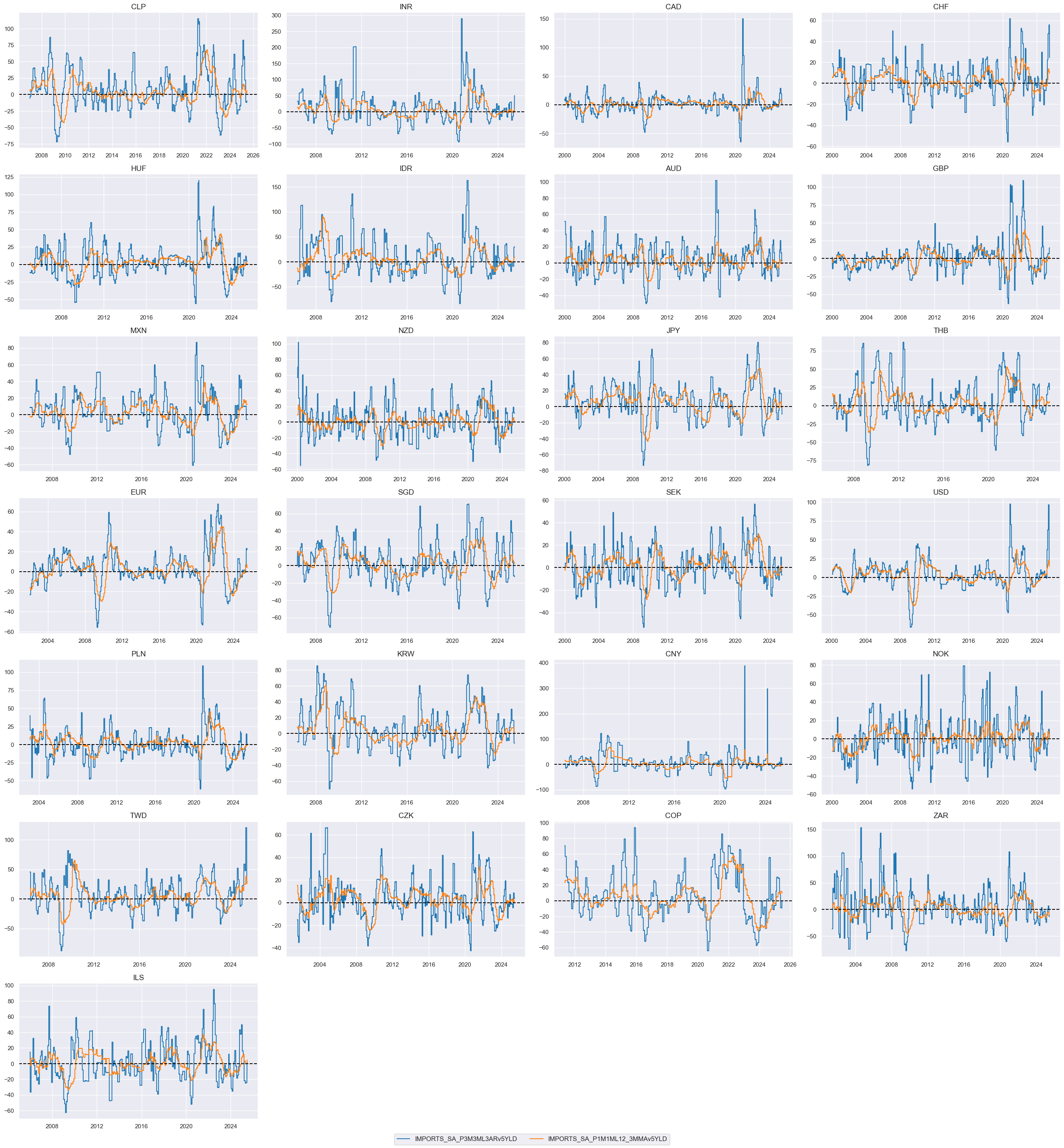
xcatx = [
"IMPORTS_SA_P6M6ML6ARv2YLD",
"IMPORTS_SA_P6M6ML6ARv5YLD",
]
cidx = cids_dux
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=4,
cumsum=False,
start="2000-01-01",
same_y=False,
size=(12, 12),
all_xticks=True,
)
Import scores #
Scoring by normalization of excess import growth is necessary for two reasons:
-
Import growth typically exceeds nominal GDP growth and interest rates. This means that the “neutral” import growth rate relative to nominal yields is not exactly zero and should be estimated based on rolling samples, i.e. considering past experiences at any point in time.
-
Like other economic data, import growth is prone to occasional data distortions that are not indicative of the economic trend. Therefore, one should de-emphasize outliers through winsorization.
Here we z-score excess import growth by using the whole panel set up to every point in time. This means that median and standard deviation are estimated based on all countries, rather than just the experience of an individual country. Thus, we create panel-based z-scores based on expanding windows, capping absolute values at three standard deviations. This normalization is helpful because it provides statistical information on the indicator’s “neutral” value. Using z-scores also makes it easier to calculate a composite import growth score later on as an average of the individual growth metrics.
The new categories will get postfix
_ZMP
to indicate that they have been z-scored, on a monthly frequency, based on the whole panel.
cidx = cids_dux
xbms = ["v2YLD", "v5YLD"]
xcatx = [m + xbm for m in imps for xbm in xbms]
dfa = pd.DataFrame(columns=list(dfx.columns))
for xm in xcatx:
dfaa = msp.make_zn_scores(
dfx,
xcat=xm,
cids=cidx,
sequential=True,
min_obs=261 * 5, # minimum requirement is 5 years of daily data
neutral="median",
pan_weight=1,
thresh=3,
postfix="_ZMP",
est_freq="m",
)
dfa = msm.update_df(dfa, dfaa)
dfx = msm.update_df(dfx, dfa)
ximps_zs = dfa["xcat"].unique().tolist()
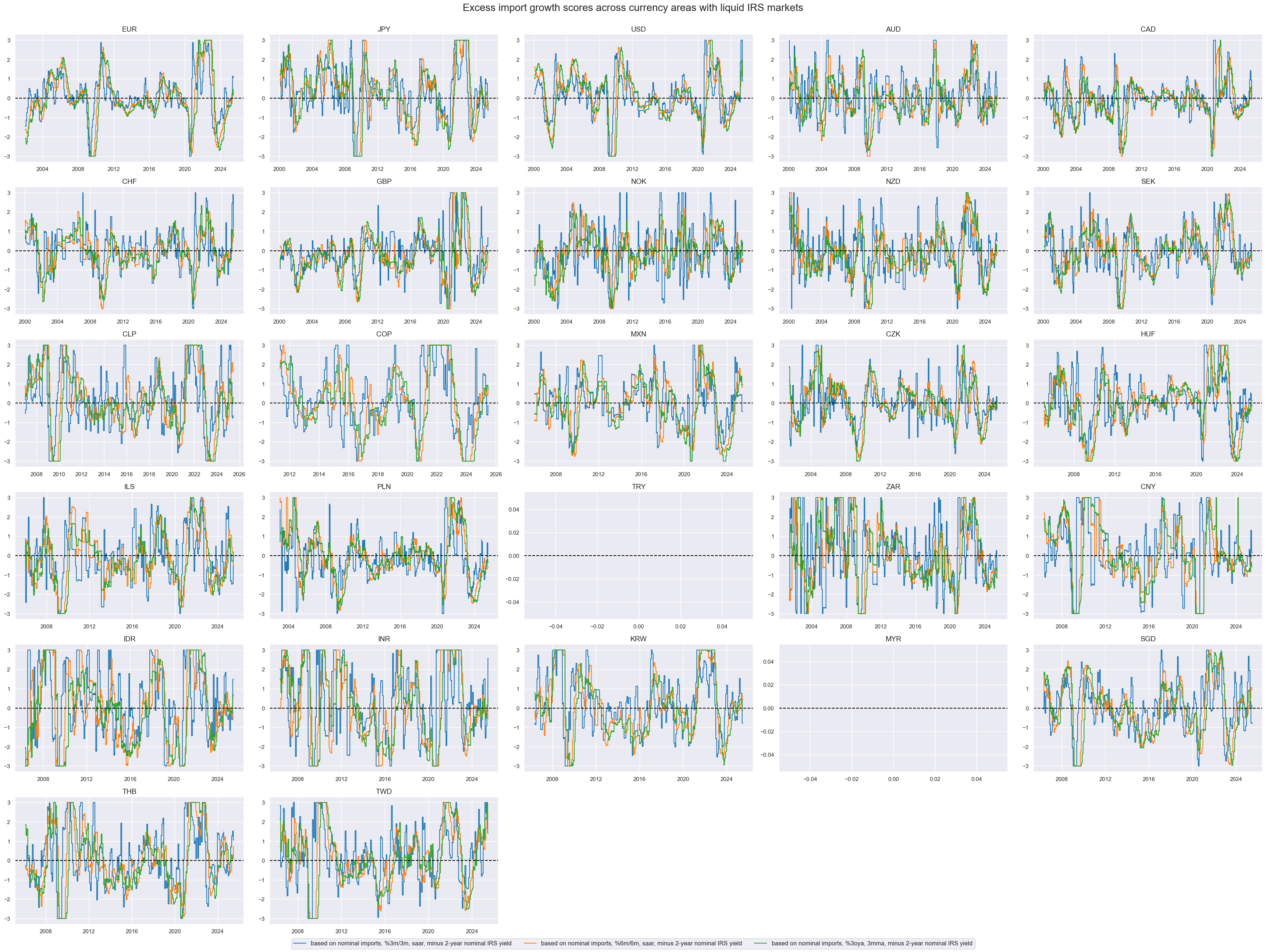
We display the z-scores of the excess import 3 categories of excess growth rates over the 2-year nominal yields on a timeline
xcatx = [
"IMPORTS_SA_P3M3ML3ARv2YLD_ZMP",
"IMPORTS_SA_P6M6ML6ARv2YLD_ZMP",
"IMPORTS_SA_P1M1ML12_3MMAv2YLD_ZMP",
]
cidx = cids_du
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=5,
cumsum=False,
start="2000-01-01",
same_y=False,
size=(12, 12),
all_xticks=True,
title="Excess import growth scores across currency areas with liquid IRS markets",
title_fontsize=20,
xcat_labels=[
"based on nominal imports, %3m/3m, saar, minus 2-year nominal IRS yield",
"based on nominal imports, %6m/6m, saar, minus 2-year nominal IRS yield",
"based on nominal imports, %3oya, 3mma, minus 2-year nominal IRS yield",
],
)
With the help of the
linear_composite``()
function from the
macrosynergy
package we create a simple average of corresponding import z-scores over 2 and 5 years and name them
IMPORTSv2YLD_ZMP
and
IMPORTSv5YLD_ZMP
cidx = cids_dux
ximps_zmp = [m + xbm + "_ZMP" for m in imps for xbm in xbms]
ximps_zmp_v2yld = [x for x in ximps_zmp if "v2YLD" in x]
ximps_zmi_v5yld = [x for x in ximps_zmp if "v5YLD" in x]
dict_zms = {
"IMPORTSv2YLD_ZMP": ximps_zmp_v2yld,
"IMPORTSv5YLD_ZMP": ximps_zmi_v5yld,
}
dfa = pd.DataFrame(columns=list(dfx.columns))
for key, value in dict_zms.items():
dfaa = msp.linear_composite(
df=dfx,
xcats=value,
cids=cidx,
complete_xcats=False,
weights=[1 / len(value)] * len(value),
signs=[1] * len(value),
new_xcat=key,
)
dfa = msm.update_df(dfa, dfaa)
dfx = msm.update_df(dfx, dfa)
ximps_czms = dfa["xcat"].unique().tolist()
Displaying both import z-scores on a timeline shows that they are almost identical:
xcatx = ximps_czms
cidx = cids_du
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=4,
cumsum=False,
start="2000-01-01",
same_y=False,
size=(12, 12),
all_xticks=True,
)
Relative import scores #
Here we create relative values for import scores. The relative values are calculated by subtracting the mean of the score from the score itself. This is done to ensure that the model is not biased towards any particular value of the score. The name of the indicator will include
_vGLB
postfix for “versus Global Benchmark” indicating that the average of the whole basket is taken for basis.
xcatx = ximps_zs + ximps_czms
cidx = cids_dux
dfa = msp.make_relative_value(
dfx,
xcats=xcatx,
cids=cidx,
start="2000-01-01",
rel_meth="subtract",
postfix="vGLB",
)
dfx = msm.update_df(dfx, dfa)
ximps_zsr = dfa["xcat"].unique().tolist()
and here we display both 2 and 5 year excess relative import growth scores on a timeline
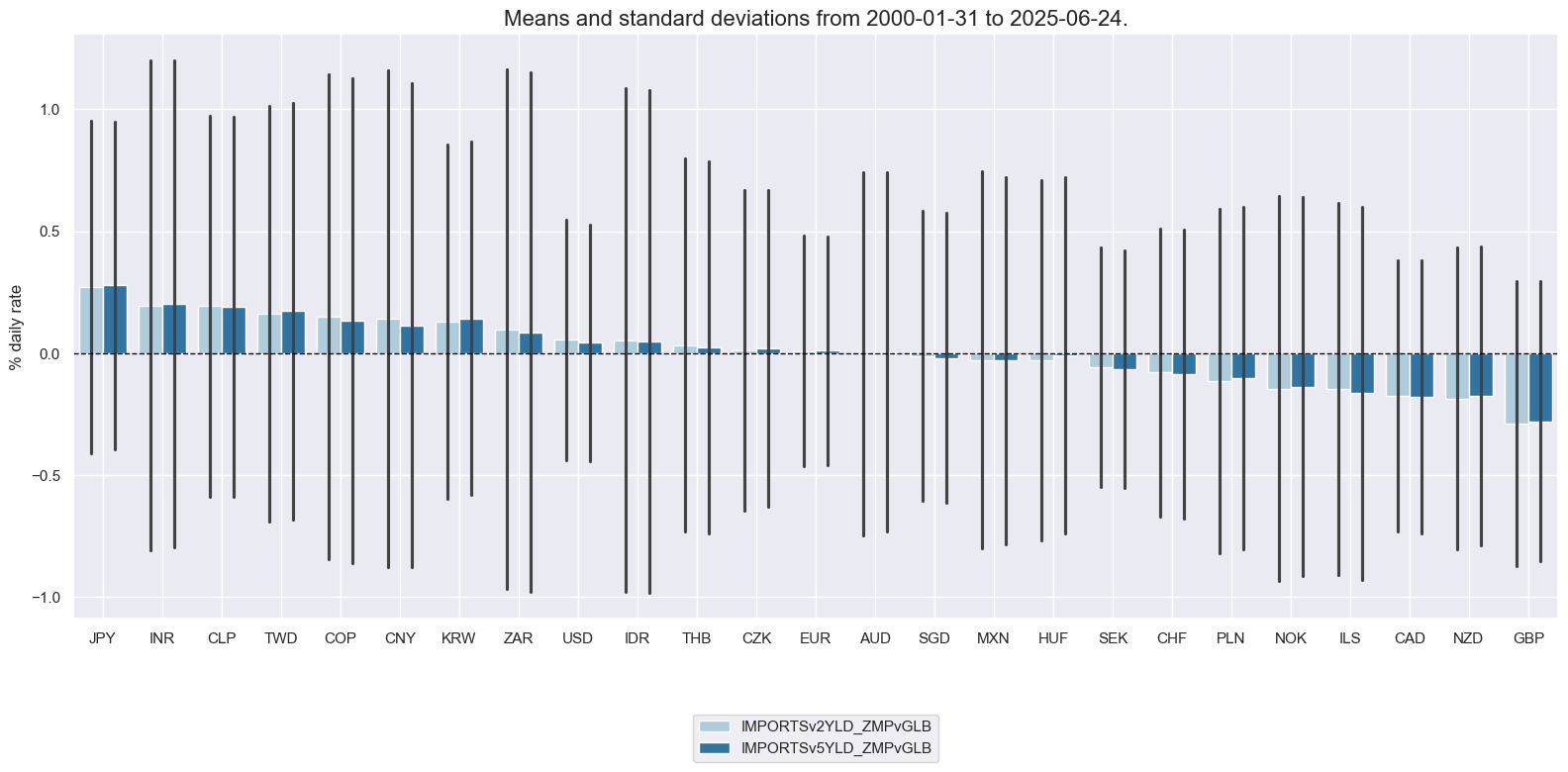
xcatx = [xc + "vGLB" for xc in ximps_czms]
cidx = cids_dux
msp.view_ranges(
dfx,
cids=cidx,
xcats=xcatx,
kind="bar",
sort_cids_by="mean",
ylab="% daily rate",
start="2000-01-01",
)
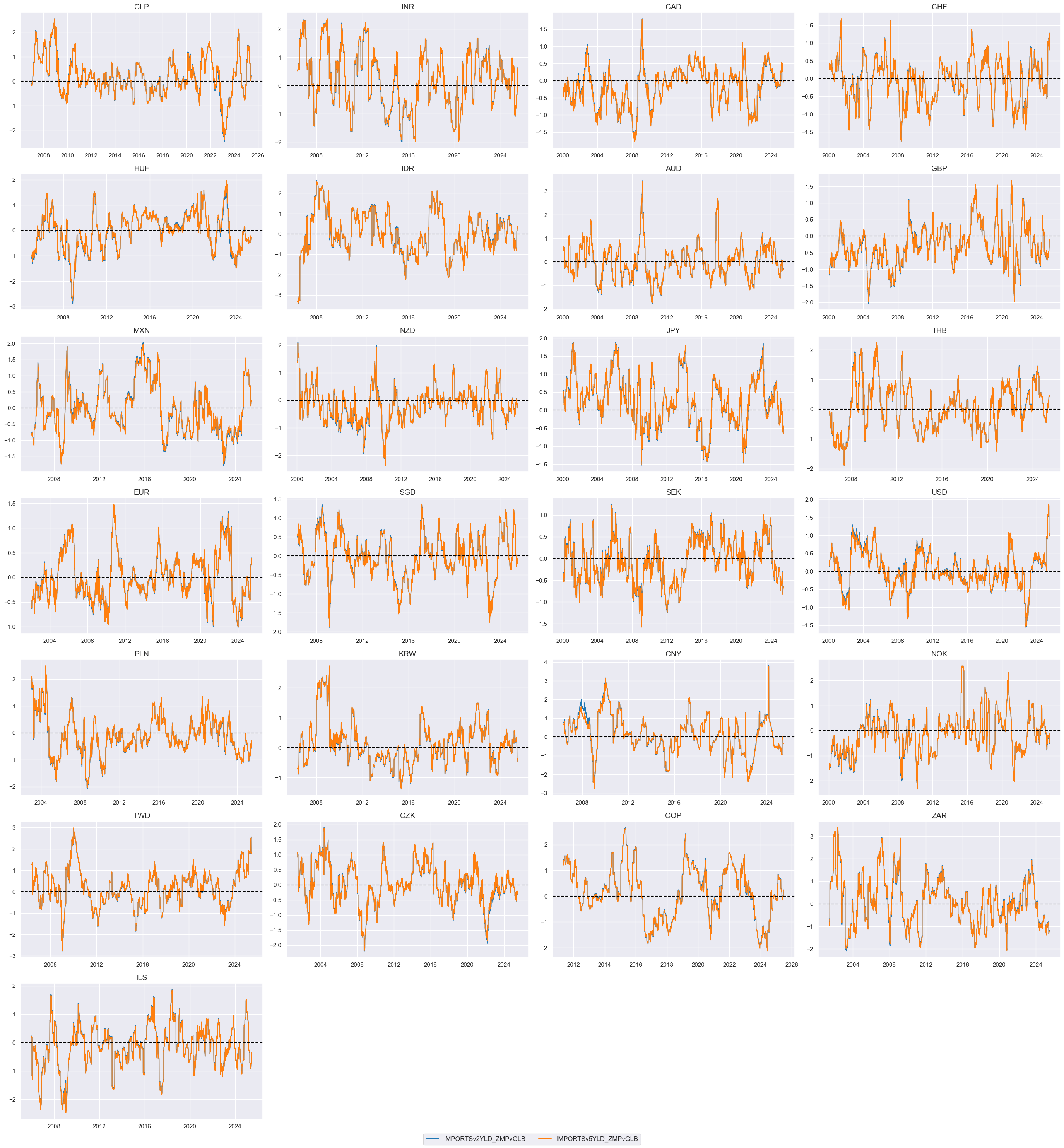
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=4,
cumsum=False,
start="2000-01-01",
same_y=False,
size=(12, 12),
all_xticks=True,
)
Targets #
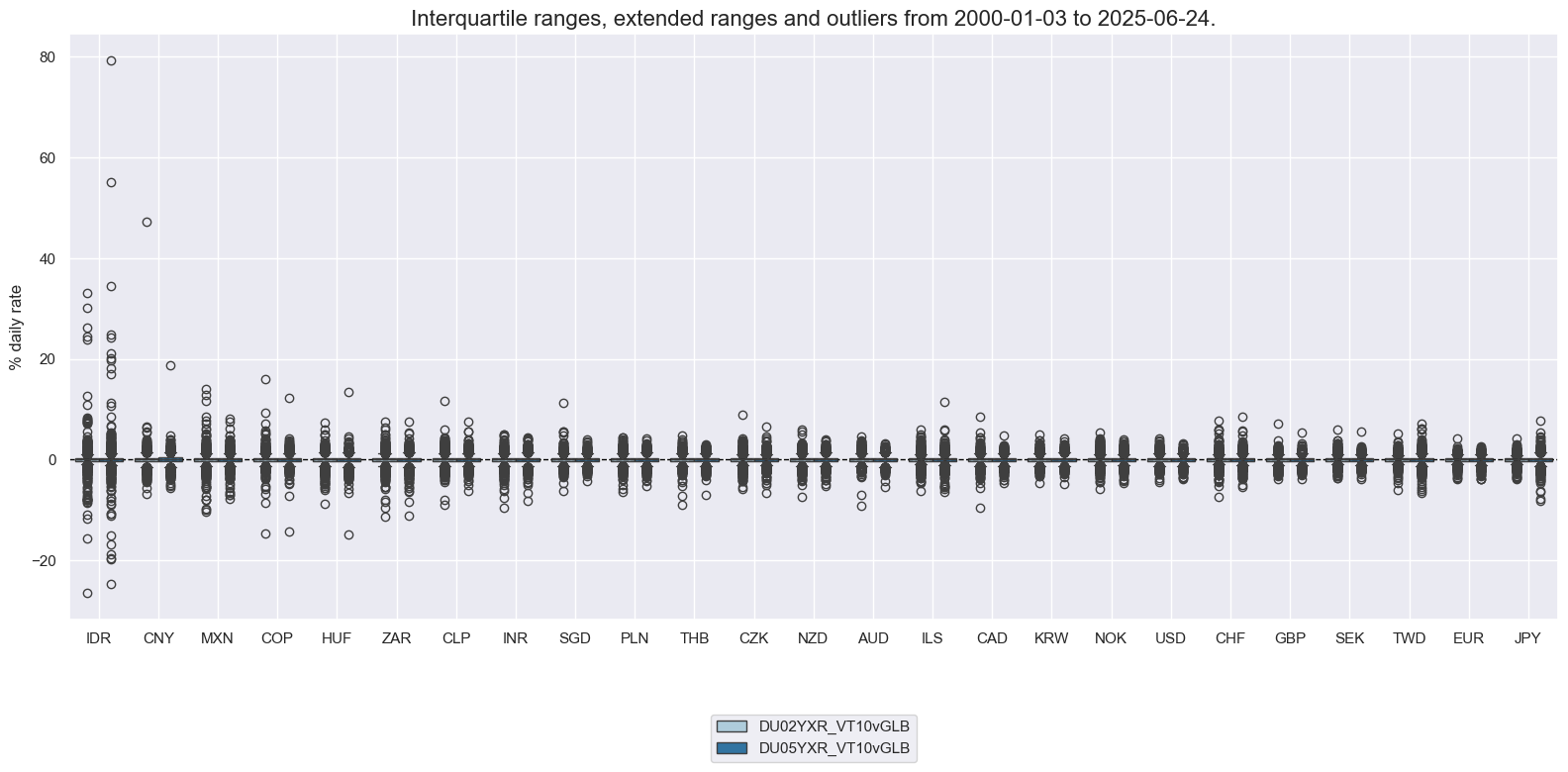
Directional #
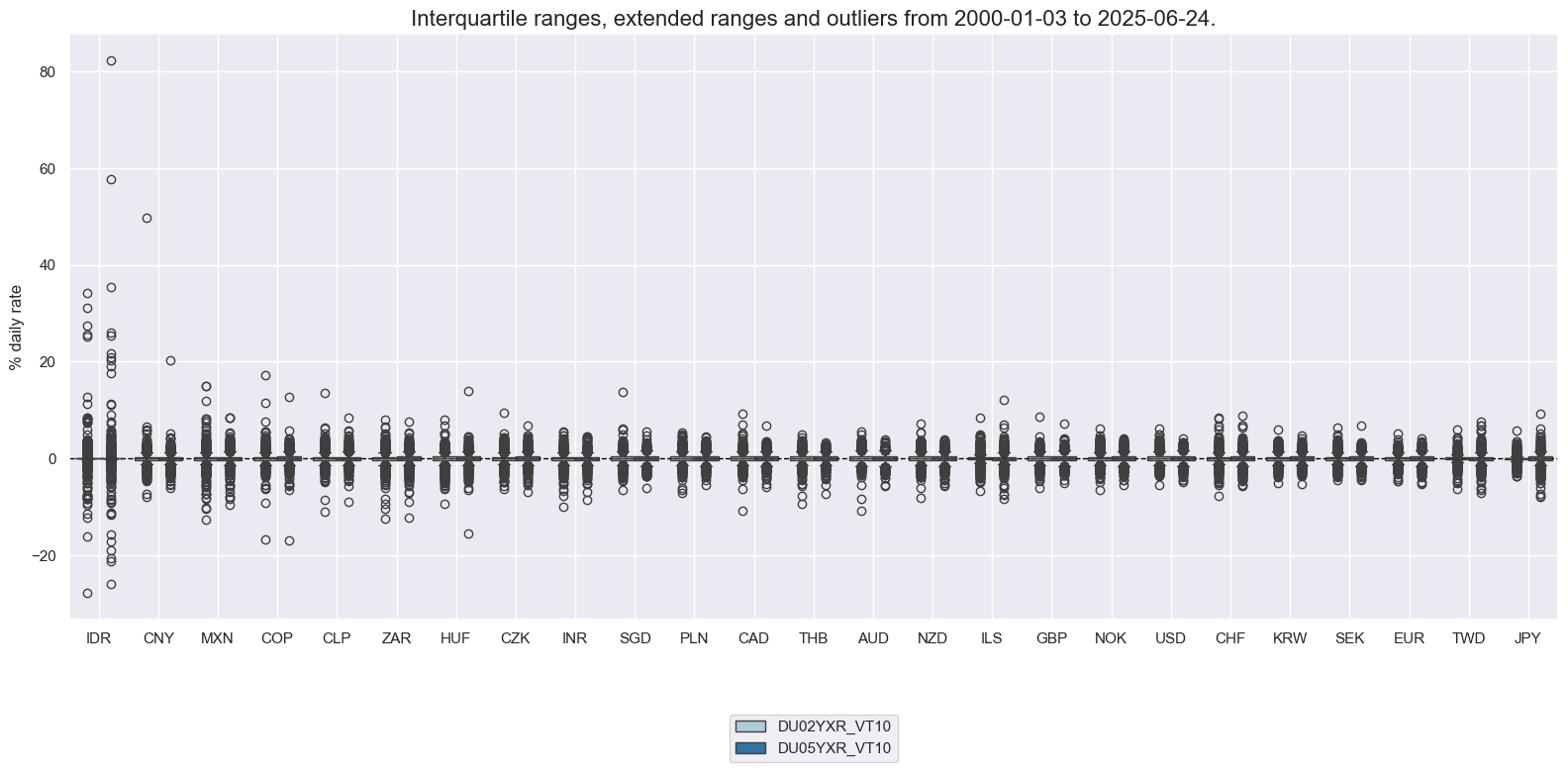
The targets of the present analysis are 2-year and 5-year interest rate swap receiver returns for 25 countries with reasonably liquid markets, in particular return on fixed receiver position, % of risk capital on position scaled to 10% (annualized) volatility target, assuming monthly roll: 2-year maturity / 5-year maturity. More on calculation, definition, and conventions see the downloadable indicator notebook here.
xcatx = ["DU02YXR_VT10", "DU05YXR_VT10"]
cidx = cids_dux
msp.view_ranges(
dfx,
cids=cidx,
xcats=xcatx,
kind="box",
sort_cids_by="std",
ylab="% daily rate",
start="2000-01-01",
)
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=4,
cumsum=True,
start="2000-01-01",
same_y=True,
size=(12, 12),
all_xticks=True,
)
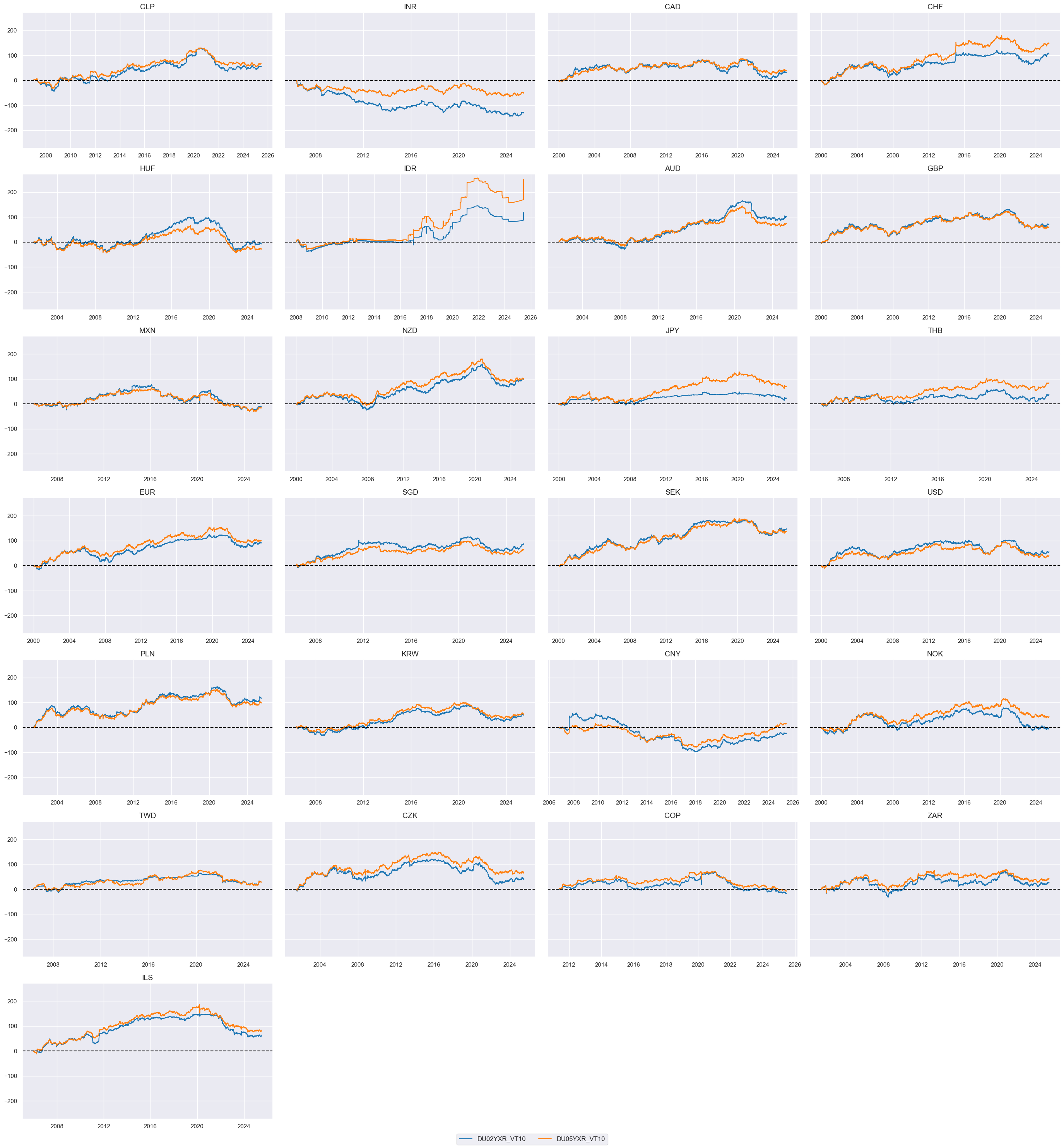
Curve (2s-5s flattening returns) #
The “2s-5s flattening returns” refer to the returns generated from the flattening of the yield curve between the 2-year and 5-year maturities. Here we define a curve flattening return as the difference between the returns of 5-year and 2-year IRS vol-targeted receiver positions. The resulting value gets a new name
DU05v02XR
.
cidx = cids_dux
calcs = ["DU05v02XR = DU05YXR_VT10 - DU02YXR_VT10 "]
dfa = msp.panel_calculator(dfx, calcs=calcs, cids=cidx)
dfx = msm.update_df(dfx, dfa)
xcatx = ["DU05v02XR"]
cidx = cids_du
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=4,
cumsum=True,
start="2000-01-01",
same_y=True,
size=(12, 12),
all_xticks=True,
)
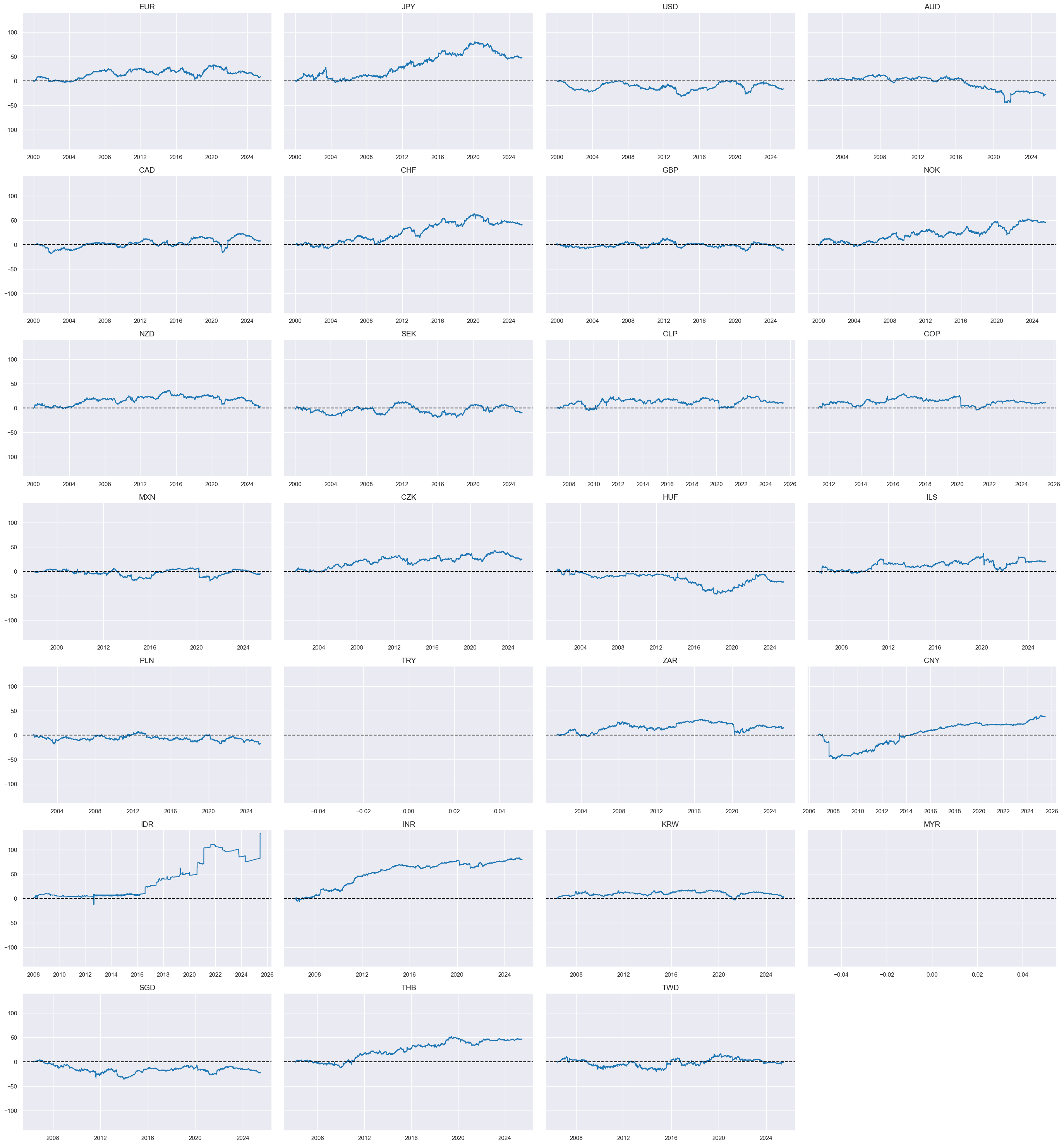
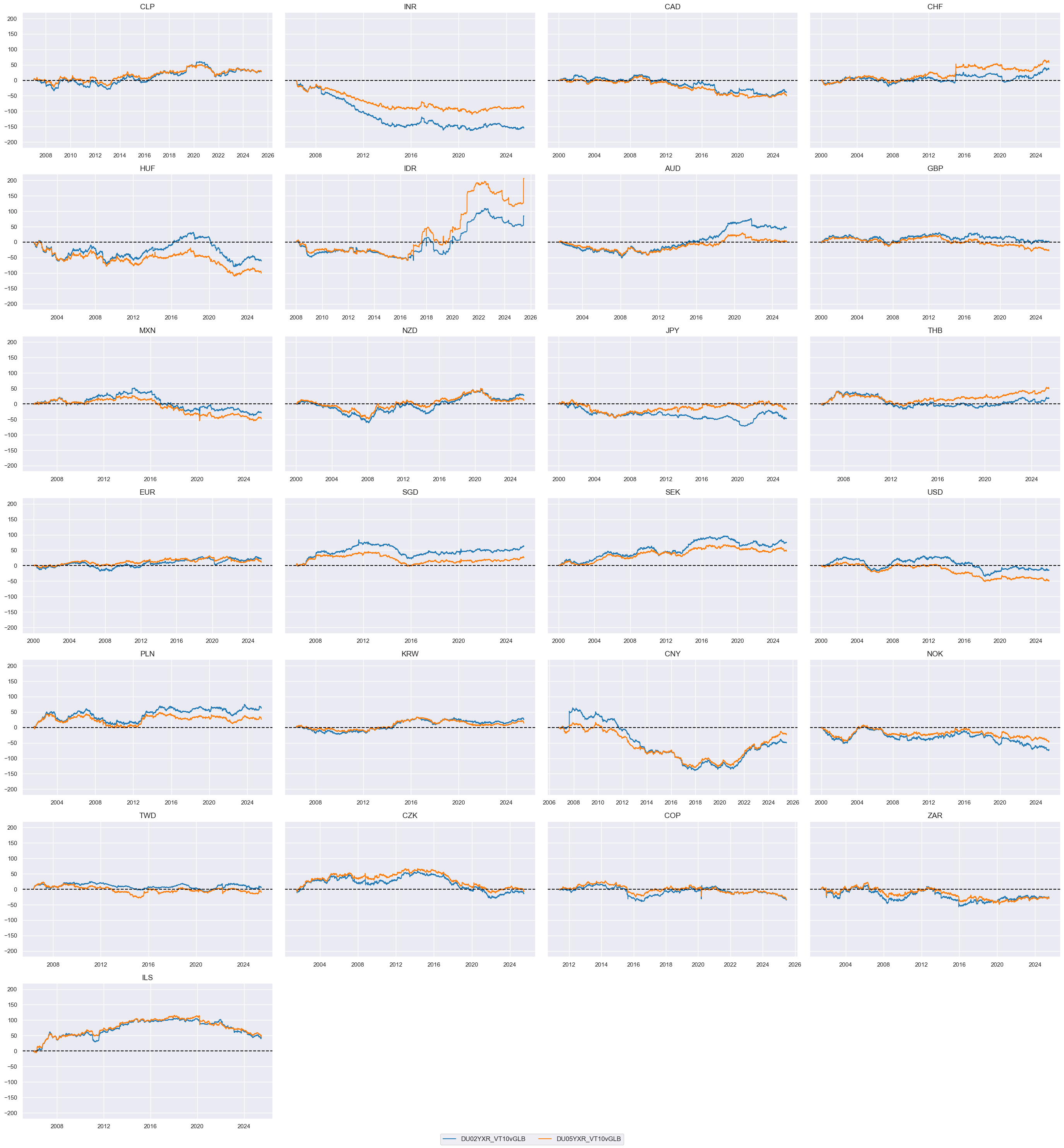
Relative #
Here we calculate the relative value of duration returns and give them postfix
vGLB
to indicate “versus Global Benchmark”
xcatx = ["DU02YXR_VT10", "DU05YXR_VT10"]
cidx = cids_dux
dfa = msp.make_relative_value(
dfx,
xcats=xcatx,
cids=cidx,
start="2000-01-01",
rel_meth="subtract",
postfix="vGLB",
)
dfx = msm.update_df(dfx, dfa)
xcatx = ["DU02YXR_VT10vGLB", "DU05YXR_VT10vGLB"]
cidx = cids_dux
msp.view_ranges(
dfx,
cids=cidx,
xcats=xcatx,
kind="box",
sort_cids_by="std",
ylab="% daily rate",
start="2000-01-01",
)
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=4,
cumsum=True,
start="2000-01-01",
same_y=True,
size=(12, 12),
all_xticks=True,
)
Value checks #
Import growth #
Directional (2Y) #
Specs and panel test #
We investigate the relationship between the main signal, the composite z-score, with the return on fixed receiver position, % of risk capital on position scaled to 10% (annualized) volatility target. As usual, we lag the explanatory variable by one period and display them on a scatter chart to get the initial impression of the relationship.
ximps_d2 = [x for x in ximps_zmp if "2YLD" in x]
sigs = ximps_d2
ms = "IMPORTSv2YLD_ZMP" # main signal
oths = list(set(sigs) - set([ms])) # other signals
targ = "DU02YXR_VT10"
cidx = cids_dux
start = "2002-01-01"
dict_xmd2 = {
"sig": ms,
"rivs": oths,
"targ": targ,
"cidx": cidx,
"black": None,
"start": start,
"srr": None,
"pnls": None,
}
dix = dict_xmd2
sig = dix["sig"]
targ = dix["targ"]
cidx = dix["cidx"]
blax = dix["black"]
start = dix["start"]
crx = msp.CategoryRelations(
dfx,
xcats=[sig, targ],
cids=cidx,
freq="Q",
lag=1,
xcat_aggs=["last", "sum"],
start="2000-01-01",
blacklist=blax,
xcat_trims=[200, 40],
)
crx.reg_scatter(
labels=False,
coef_box="lower left",
xlab="Import growth minus 2-year IRS yield, composite measure, out-of-sample panel z-score",
ylab="2-year IRS receiver returns (10% vol target), next quarter",
title=f"Excess import growth and subsequent 2-year IRS returns, {len(cids_dux)} countries",
size=(10, 6),
prob_est="map",
)
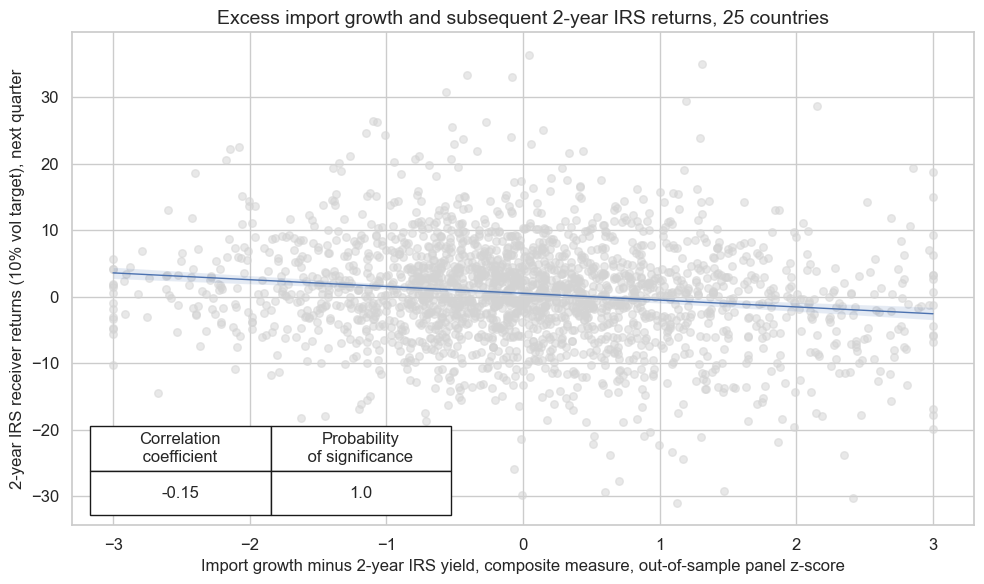
The hypothesis we are checking first is that excess import growth predicts duration returns negatively. Plausibly, this should be relevant for the whole curve. However, concurrent import trends inform more on the monetary policy outlook than long-term growth and inflation and, hence, should be a better predictor for two years than for five years. The relationship between excess import growth and subsequent IRS return is indeed negative as can be seen above, and the probability of significance is near 100%
Accuracy and correlation check #
With the help of another useful function
SignalReturnRelations
from the
macrosynergy
package we can easily display useful statistics, such as accuracy, balanced accuracy, positive and negative precision. For a description of the output table please refer to the
Introduction to Macrosynergy package
. Since the relationship between the signal and the target is negative, we put the signal in negative terms for all analyses by specifying
sig_neg=True
as an option.
dix = dict_xmd2
sig = dix["sig"]
rivs = dix["rivs"]
targ = dix["targ"]
cidx = dix["cidx"]
blax = dix["black"]
start = dix["start"]
srr = mss.SignalReturnRelations(
dfx,
cids=cidx,
sigs=[sig] + rivs,
sig_neg=[True] + [True] * len(rivs),
rets=targ,
freqs="M",
start=start,
blacklist=blax,
)
dix["srr"] = srr
dix = dict_xmd2
srrx = dix["srr"]
display(srrx.summary_table().astype("float").round(3))
| accuracy | bal_accuracy | pos_sigr | pos_retr | pos_prec | neg_prec | pearson | pearson_pval | kendall | kendall_pval | auc | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| M: IMPORTSv2YLD_ZMP_NEG/last => DU02YXR_VT10 | 0.537 | 0.536 | 0.514 | 0.534 | 0.568 | 0.503 | 0.107 | 0.000 | 0.067 | 0.000 | 0.536 |
| Mean years | 0.537 | 0.513 | 0.513 | 0.538 | 0.556 | 0.470 | 0.028 | 0.307 | 0.010 | 0.430 | 0.510 |
| Positive ratio | 0.708 | 0.667 | 0.583 | 0.708 | 0.792 | 0.292 | 0.708 | 0.500 | 0.542 | 0.375 | 0.667 |
| Mean cids | 0.537 | 0.537 | 0.511 | 0.533 | 0.569 | 0.505 | 0.106 | 0.239 | 0.067 | 0.280 | 0.537 |
| Positive ratio | 0.880 | 0.920 | 0.520 | 0.920 | 0.920 | 0.520 | 0.960 | 0.840 | 0.880 | 0.720 | 0.920 |
The Summary table below gives a short high-level snapshot of the strength and stability of the main signal and alternative signal relation. As the post states, the balanced accuracy of monthly 2-year IRS return predictions (the average ratio of correct positive and negative return predictions) has been 53.9%. Indeed, positive precision (57.2%) and negative precision (50.5%) have been above par, meaning that positive and negative return predictions have been correct more than half the time.
dix = dict_xmd2
srrx = dix["srr"]
display(srrx.signals_table().sort_index().astype("float").round(3))
| accuracy | bal_accuracy | pos_sigr | pos_retr | pos_prec | neg_prec | pearson | pearson_pval | kendall | kendall_pval | auc | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Return | Signal | Frequency | Aggregation | |||||||||||
| DU02YXR_VT10 | IMPORTS_SA_P1M1ML12_3MMAv2YLD_ZMP_NEG | M | last | 0.540 | 0.538 | 0.524 | 0.534 | 0.570 | 0.507 | 0.115 | 0.0 | 0.069 | 0.0 | 0.538 |
| IMPORTS_SA_P3M3ML3ARv2YLD_ZMP_NEG | M | last | 0.526 | 0.526 | 0.502 | 0.534 | 0.560 | 0.493 | 0.067 | 0.0 | 0.040 | 0.0 | 0.526 | |
| IMPORTS_SA_P6M6ML6ARv2YLD_ZMP_NEG | M | last | 0.534 | 0.533 | 0.520 | 0.534 | 0.565 | 0.500 | 0.094 | 0.0 | 0.058 | 0.0 | 0.533 | |
| IMPORTSv2YLD_ZMP_NEG | M | last | 0.537 | 0.536 | 0.514 | 0.534 | 0.568 | 0.503 | 0.107 | 0.0 | 0.067 | 0.0 | 0.536 |
Another useful way to visualize positive correlation probabilities based on parametric (Pearson) and non-parametric (Kendall) correlation statistics, and compare signals between each other, across counties, or years is to use
correlation_bars()
method from the
macrosynergy
package.
dix = dict_xmd2
srrx = dix["srr"]
srrx.correlation_bars(
type="years",
title=None,
size=(14, 6),
)
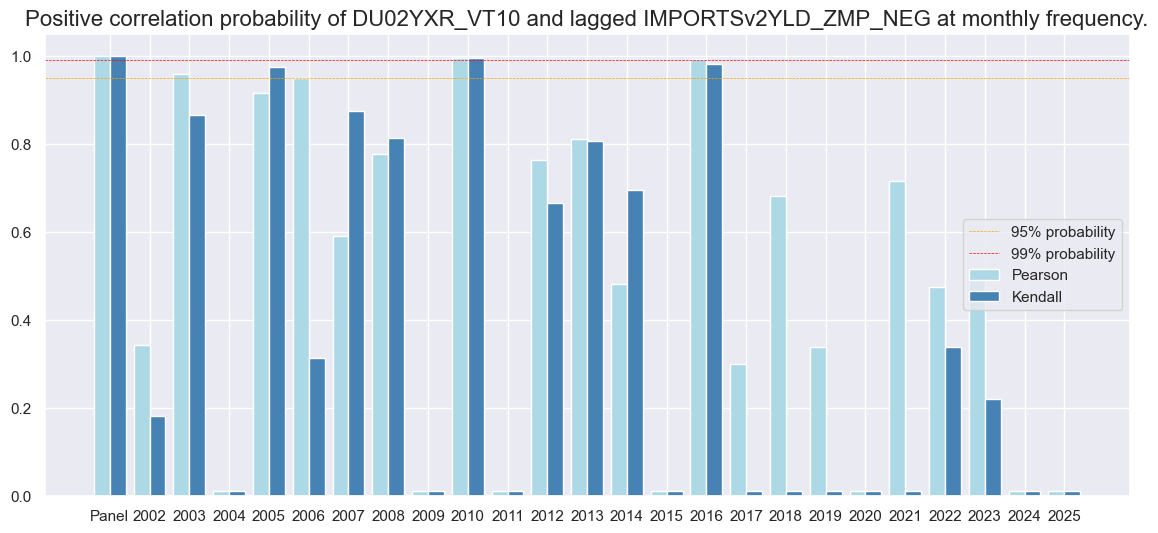
dix = dict_xmd2
srrx = dix["srr"]
srrx.correlation_bars(
type="cross_section",
title=None,
size=(14, 6),
)
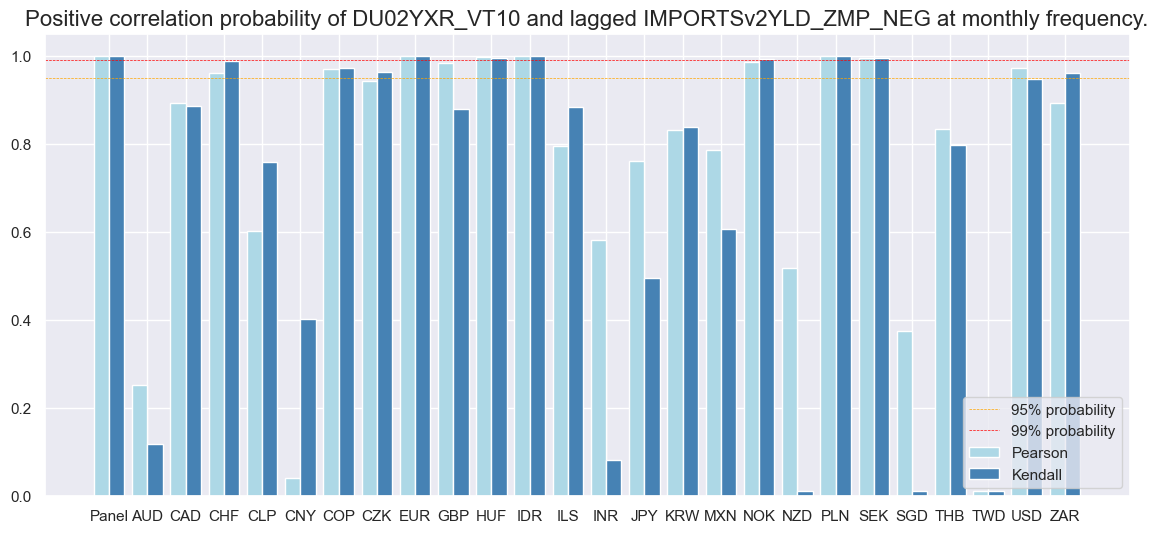
Naive PnL #
Here we calculate a daily PnL for selected composite z-score (signal)
IMPORTSv2YLD_ZMP
and its parts as alternative signals. We create a new PnL series with postfix
_PZN
to indicate that the raw signal has been transformed into z-scores. In the cell below 5 PnLs series are created: for the main signal
IMPORTSv2YLD_ZMP
, for 3 parts of this signal, and Long only PnL.
dix = dict_xmd2
sigx = [dix["sig"]] + dix["rivs"]
targ = dix["targ"]
cidx = dix["cidx"]
blax = dix["black"]
start = dix["start"]
naive_pnl = msn.NaivePnL(
dfx,
ret=targ,
sigs=sigx,
cids=cidx,
start=start,
blacklist=blax,
bms=["USD_DU05YXR_NSA", "USD_EQXR_NSA"],
)
for sig in sigx:
naive_pnl.make_pnl(
sig,
sig_neg=True,
sig_op="zn_score_pan",
thresh=3,
rebal_freq="monthly",
vol_scale=10,
rebal_slip=1,
pnl_name=sig + "_PZN",
)
naive_pnl.make_long_pnl(vol_scale=10, label="Long only")
dix["pnls"] = naive_pnl
USD_DU05YXR_NSA has no observations in the DataFrame.
dix = dict_xmd2
start = dix["start"]
cidx = dix["cidx"]
sigx = [dix["sig"]]
naive_pnl = dix["pnls"]
pnls = [s + "_PZN" for s in sigx] + ["Long only"]
dict_labels = {"IMPORTSv2YLD_ZMP_PZN": "based on composite import growth signal",
"Long only": "always long duration (risk parity)"
}
naive_pnl.plot_pnls(
pnl_cats=pnls,
pnl_cids=["ALL"],
start=start,
title=f"Naive PnL of 2-year IRS positions, {len(cidx)} countries (10% ar vol scale)",
xcat_labels=dict_labels,
figsize=(16, 8),
)
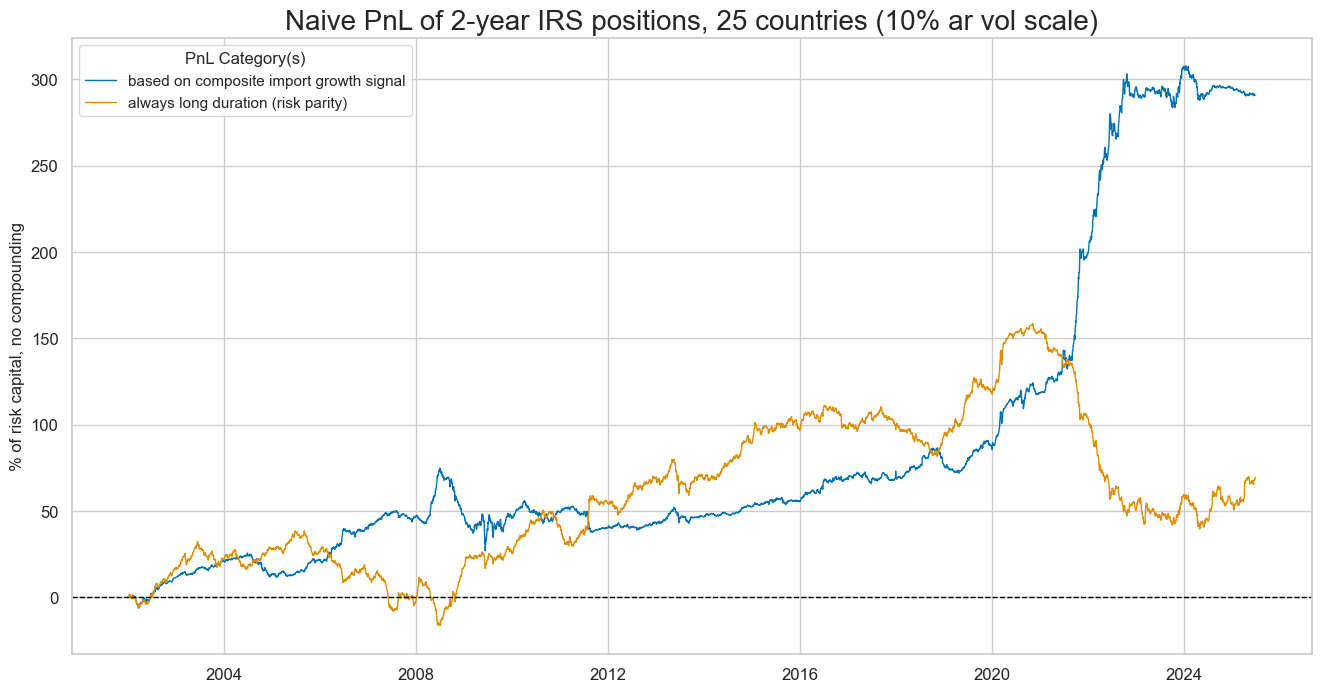
The performance has been seasonal, with the most value generated in recent years, benefiting from the economic fluctuations related to the pandemic.
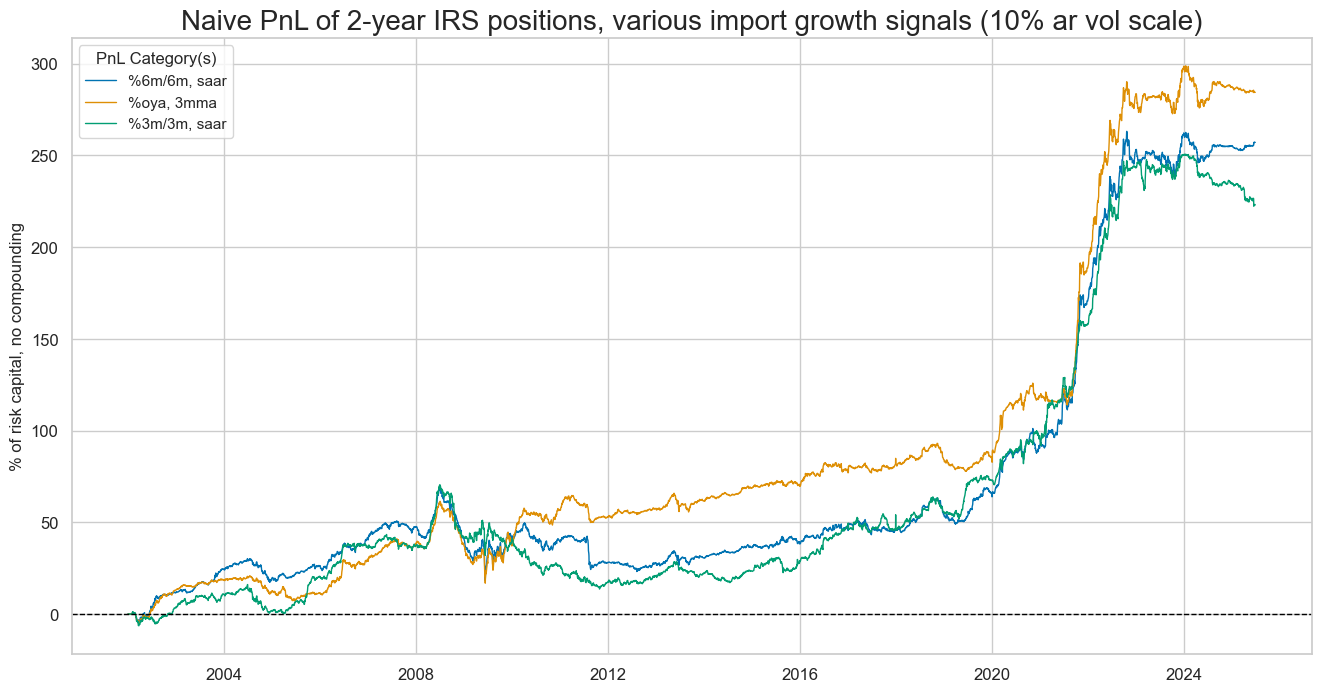
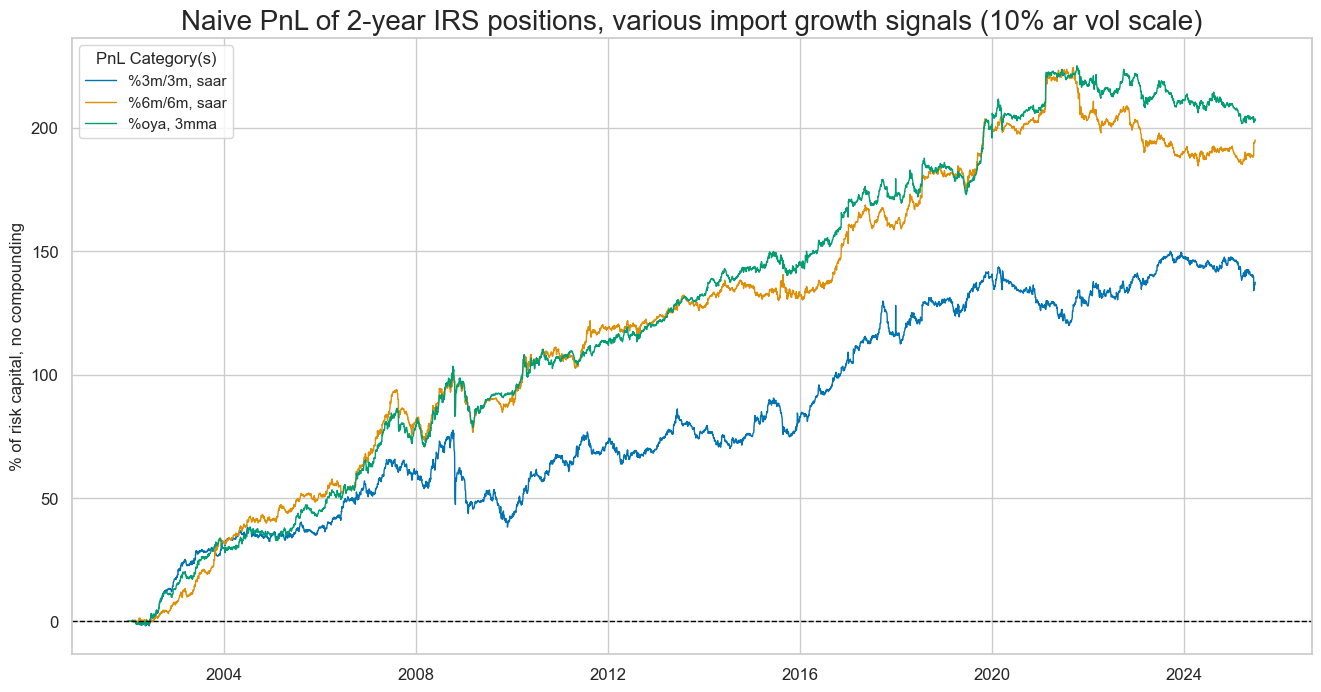
Here is the same naive PnL for the composite parts of the main signal:
IMPORTS_SA_P6M6ML6ARv2YLD_ZMP
,
IMPORTS_SA_P3M3ML3ARv2YLD_ZMP
, and
IMPORTS_SA_P1M1ML12_3MMAv2YLD_ZMP
dix = dict_xmd2
start = dix["start"]
sigx = dix["rivs"]
naive_pnl = dix["pnls"]
pnls = [s + "_PZN" for s in sigx]
dict_labels = {"IMPORTS_SA_P3M3ML3ARv2YLD_ZMP_PZN": "%3m/3m, saar",
"IMPORTS_SA_P6M6ML6ARv2YLD_ZMP_PZN": "%6m/6m, saar",
"IMPORTS_SA_P1M1ML12_3MMAv2YLD_ZMP_PZN": "%oya, 3mma"
}
naive_pnl.plot_pnls(
pnl_cats=pnls,
pnl_cids=["ALL"],
start=start,
title="Naive PnL of 2-year IRS positions, various import growth signals (10% ar vol scale)",
xcat_labels=dict_labels,
figsize=(16, 8),
)
dix = dict_xmd2
start = dix["start"]
sigx = [dix["sig"]] + dix["rivs"]
naive_pnl = dix["pnls"]
pnls = [sig + "_PZN" for sig in sigx]
df_eval = naive_pnl.evaluate_pnls(
pnl_cats=pnls,
pnl_cids=["ALL"],
start=start,
)
display(df_eval.transpose())
| Return % | St. Dev. % | Sharpe Ratio | Sortino Ratio | Max 21-Day Draw % | Max 6-Month Draw % | Peak to Trough Draw % | Top 5% Monthly PnL Share | USD_EQXR_NSA correl | Traded Months | |
|---|---|---|---|---|---|---|---|---|---|---|
| xcat | ||||||||||
| IMPORTSv2YLD_ZMP_PZN | 12.393342 | 10.0 | 1.239334 | 1.97891 | -17.232922 | -30.375639 | -47.850171 | 0.774551 | 0.002156 | 282 |
| IMPORTS_SA_P6M6ML6ARv2YLD_ZMP_PZN | 10.953108 | 10.0 | 1.095311 | 1.712372 | -18.32485 | -30.633944 | -50.997482 | 0.804391 | -0.011729 | 282 |
| IMPORTS_SA_P1M1ML12_3MMAv2YLD_ZMP_PZN | 12.115267 | 10.0 | 1.211527 | 1.978056 | -15.768551 | -29.391492 | -44.605073 | 0.807919 | -0.006027 | 282 |
| IMPORTS_SA_P3M3ML3ARv2YLD_ZMP_PZN | 9.501654 | 10.0 | 0.950165 | 1.45793 | -19.259472 | -28.064685 | -56.849619 | 0.871775 | 0.024761 | 282 |
The 22-year Sharpe ratio of a strategy based on the composite import score has been very high at 1.4, with no correlation to the S&P500 returns. Looking across different import growth signals, the least volatile annual growth rates produced the highest prediction accuracy and PnL value.
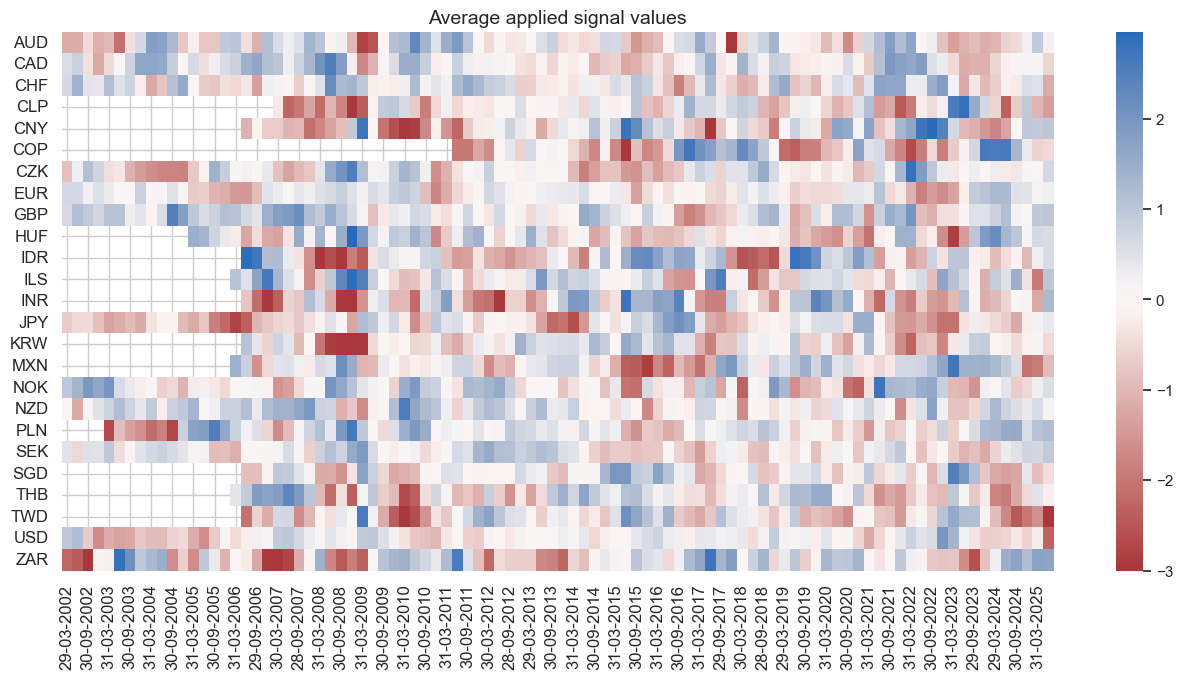
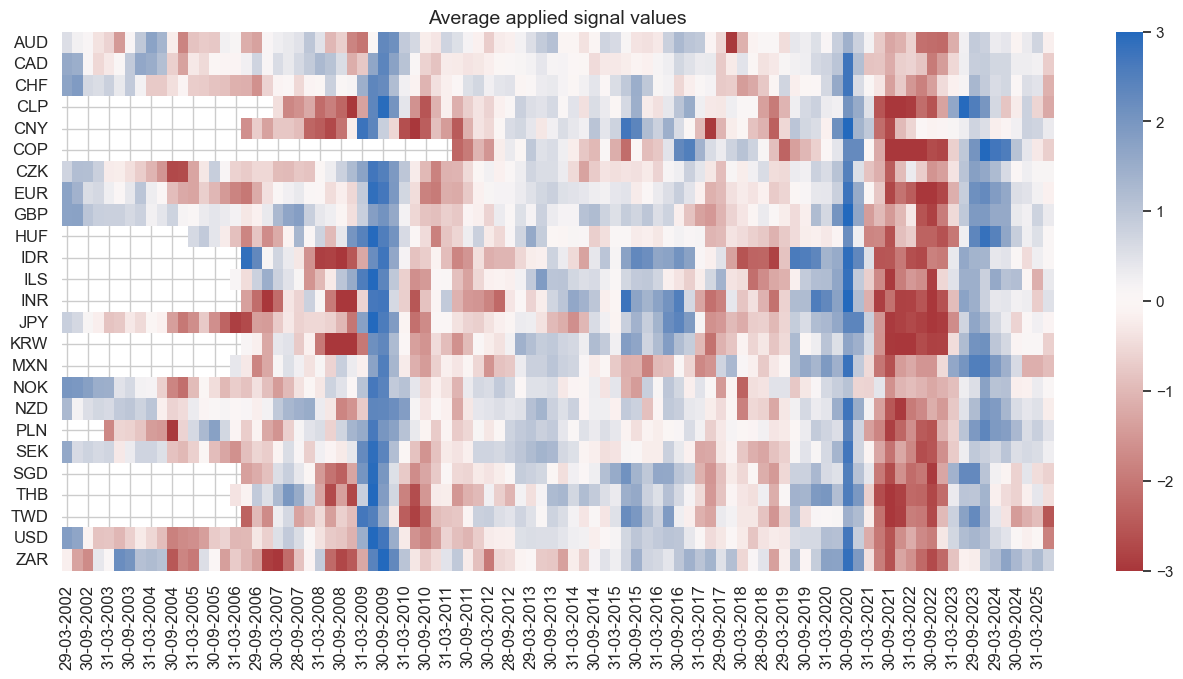
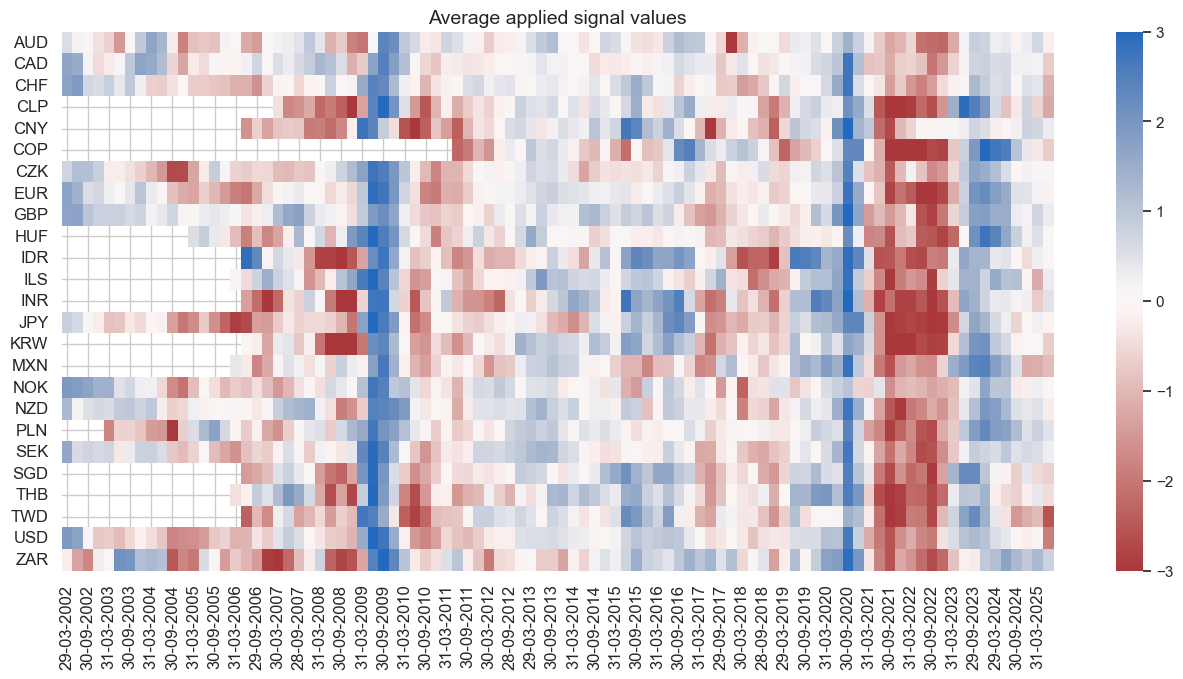
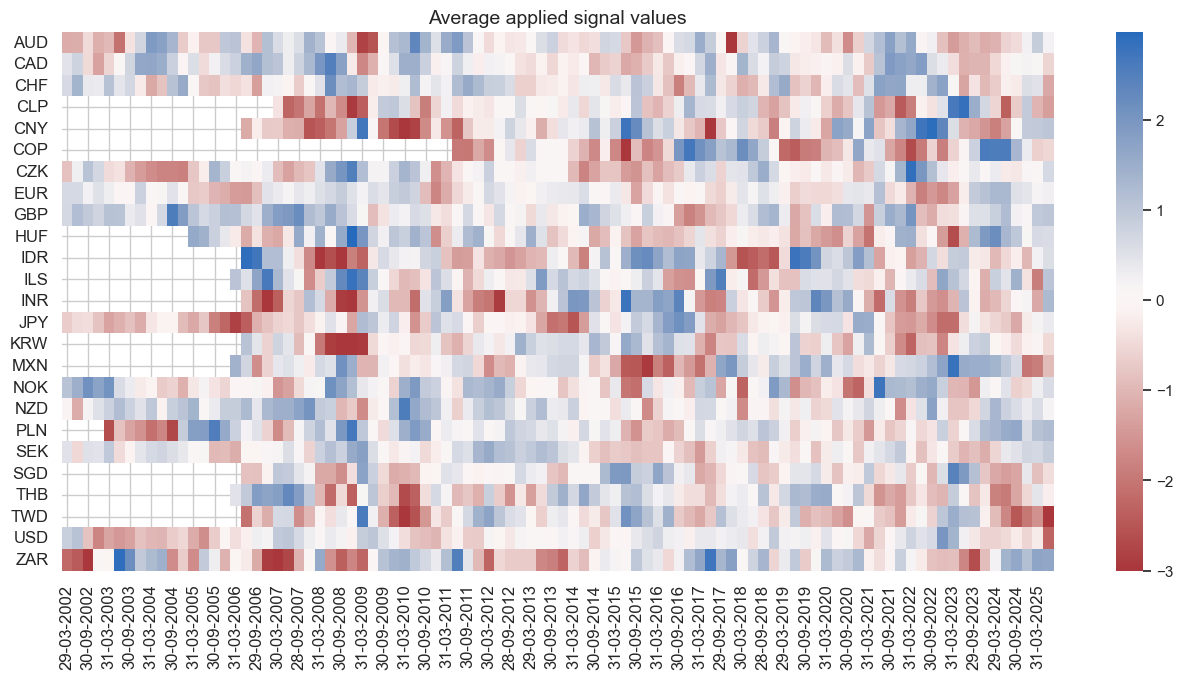
The heatmap below shows that the average applied signal values are strongest in times of economic turbulence, such as the pandemic. This fosters the seasonality of the strategy.
dix = dict_xmd2
start = dix["start"]
sig = dix["sig"]
naive_pnl = dix["pnls"]
naive_pnl.signal_heatmap(pnl_name=sig + "_PZN", freq="q", start=start, figsize=(16, 7))
Directional (5Y) #
Specs and panel test #
Here we perform the same analysis for imports-based duration strategy for 5-year maturity contracts. It would have only produced half the value and did so predominantly in the 2020s. Longer-date maturity receivers carry higher risk premia and displayed a greater ratio of positive return months (54.6%), making it harder for a short-biased strategy to create value. However, like the 2-year maturity, the imports-based signal would have highly complemented a long-only strategy.
ximps_d5 = [x for x in ximps_zmp if "5YLD" in x]
sigs = ximps_d5
ms = "IMPORTSv5YLD_ZMP" # main signal
oths = list(set(sigs) - set([ms])) # other signals
targ = "DU05YXR_VT10"
cidx = cids_dux
start = "2002-01-01"
dict_xmd5 = {
"sig": ms,
"rivs": oths,
"targ": targ,
"cidx": cidx,
"start": start,
"srr": None,
"pnls": None,
}
dix = dict_xmd5
sig = dix["sig"]
targ = dix["targ"]
cidx = dix["cidx"]
crx = msp.CategoryRelations(
dfx,
xcats=[sig, targ],
cids=cidx,
freq="Q",
lag=1,
xcat_aggs=["last", "sum"],
start="2000-01-01",
xcat_trims=[200, 40],
)
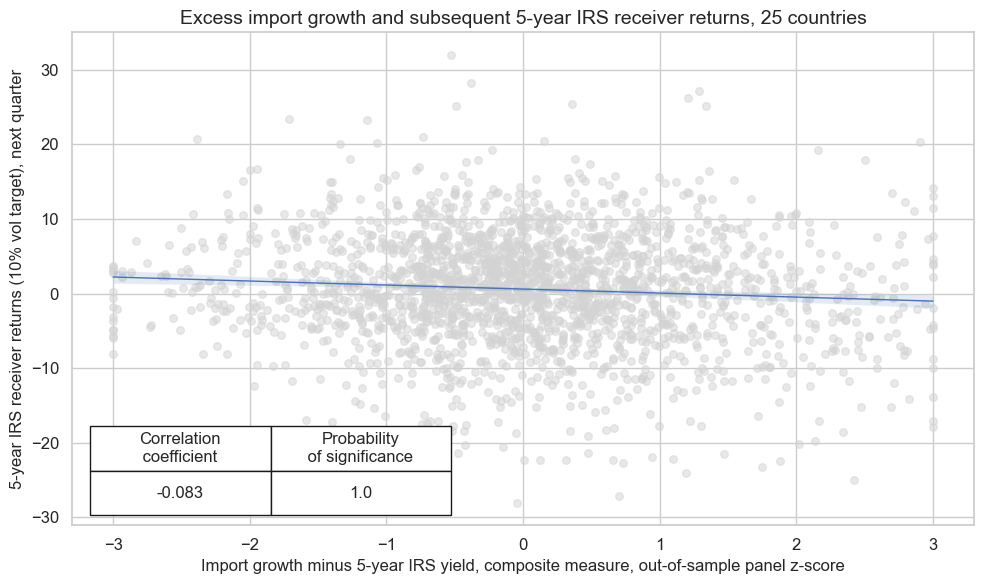
crx.reg_scatter(
labels=False,
coef_box="lower left",
xlab="Import growth minus 5-year IRS yield, composite measure, out-of-sample panel z-score",
ylab="5-year IRS receiver returns (10% vol target), next quarter",
title=f"Excess import growth and subsequent 5-year IRS receiver returns, {len(cids_dux)} countries",
size=(10, 6),
prob_est="map",
)
Accuracy and correlation check #
dix = dict_xmd5
sig = dix["sig"]
rivs = dix["rivs"]
targ = dix["targ"]
cidx = dix["cidx"]
start = dix["start"]
srr = mss.SignalReturnRelations(
dfx,
cids=cidx,
sigs=[sig] + rivs,
sig_neg=[True] + [True] * len(rivs),
rets=targ,
freqs="M",
start=start,
)
dix["srr"] = srr
dix = dict_xmd5
srrx = dix["srr"]
display(srrx.summary_table().astype("float").round(3))
| accuracy | bal_accuracy | pos_sigr | pos_retr | pos_prec | neg_prec | pearson | pearson_pval | kendall | kendall_pval | auc | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| M: IMPORTSv5YLD_ZMP_NEG/last => DU05YXR_VT10 | 0.521 | 0.520 | 0.510 | 0.543 | 0.562 | 0.478 | 0.061 | 0.000 | 0.035 | 0.000 | 0.520 |
| Mean years | 0.521 | 0.503 | 0.509 | 0.548 | 0.548 | 0.457 | 0.009 | 0.401 | -0.005 | 0.370 | 0.501 |
| Positive ratio | 0.625 | 0.625 | 0.583 | 0.708 | 0.750 | 0.292 | 0.625 | 0.333 | 0.542 | 0.333 | 0.625 |
| Mean cids | 0.521 | 0.519 | 0.508 | 0.542 | 0.561 | 0.478 | 0.056 | 0.459 | 0.034 | 0.413 | 0.520 |
| Positive ratio | 0.680 | 0.680 | 0.480 | 0.920 | 0.880 | 0.320 | 0.800 | 0.480 | 0.760 | 0.520 | 0.680 |
dix = dict_xmd5
srrx = dix["srr"]
display(srrx.signals_table().sort_index().astype("float").round(3))
| accuracy | bal_accuracy | pos_sigr | pos_retr | pos_prec | neg_prec | pearson | pearson_pval | kendall | kendall_pval | auc | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Return | Signal | Frequency | Aggregation | |||||||||||
| DU05YXR_VT10 | IMPORTS_SA_P1M1ML12_3MMAv5YLD_ZMP_NEG | M | last | 0.525 | 0.523 | 0.520 | 0.543 | 0.565 | 0.482 | 0.069 | 0.000 | 0.036 | 0.000 | 0.524 |
| IMPORTS_SA_P3M3ML3ARv5YLD_ZMP_NEG | M | last | 0.514 | 0.514 | 0.500 | 0.543 | 0.557 | 0.472 | 0.039 | 0.002 | 0.020 | 0.017 | 0.515 | |
| IMPORTS_SA_P6M6ML6ARv5YLD_ZMP_NEG | M | last | 0.519 | 0.518 | 0.517 | 0.543 | 0.560 | 0.476 | 0.051 | 0.000 | 0.025 | 0.003 | 0.518 | |
| IMPORTSv5YLD_ZMP_NEG | M | last | 0.521 | 0.520 | 0.510 | 0.543 | 0.562 | 0.478 | 0.061 | 0.000 | 0.035 | 0.000 | 0.520 |
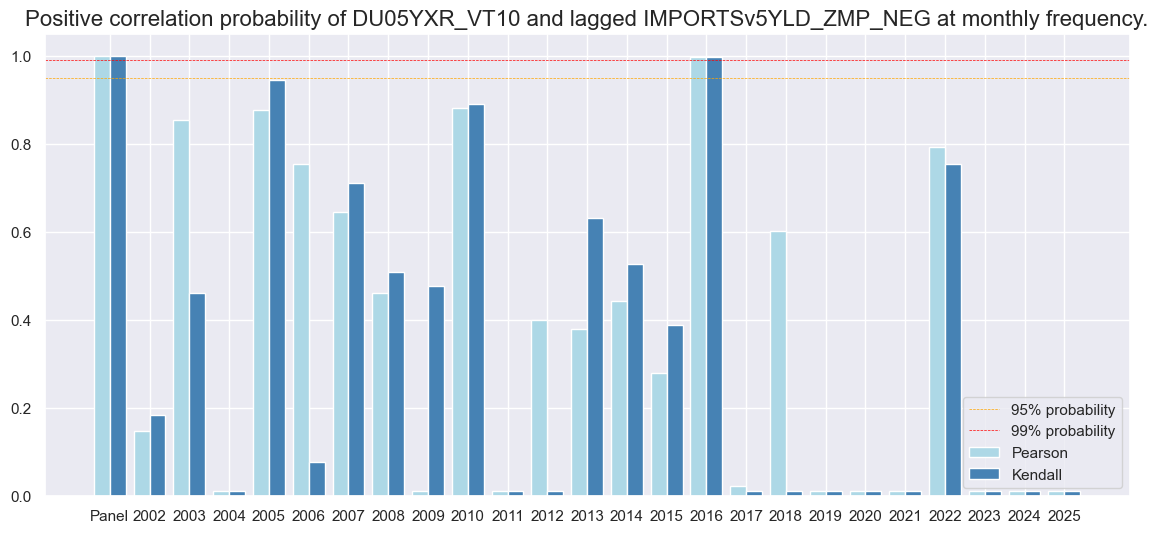
dix = dict_xmd5
srrx = dix["srr"]
srrx.correlation_bars(
type="years",
title=None,
size=(14, 6),
)
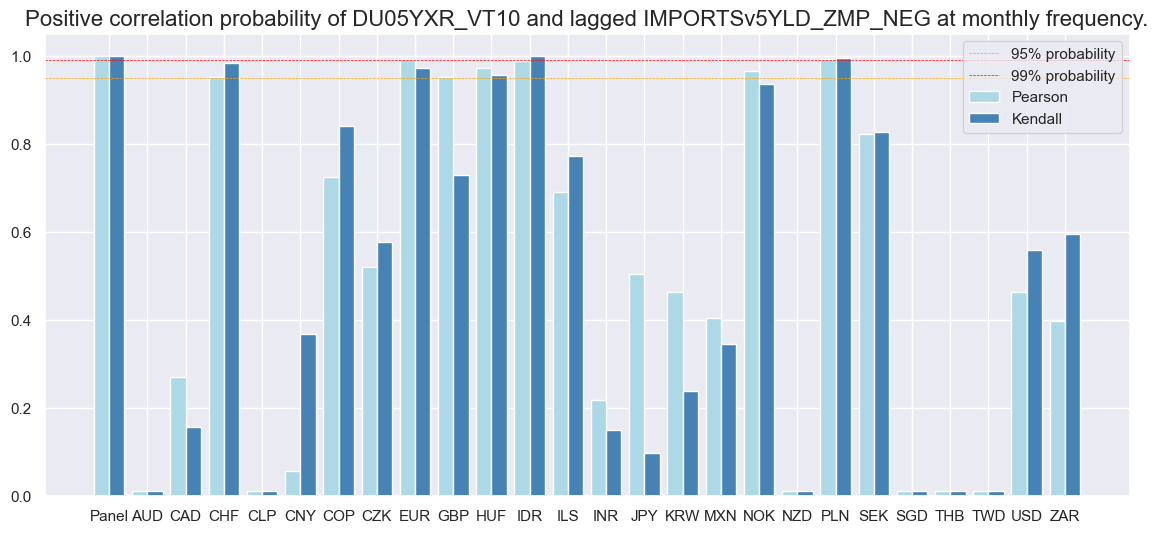
dix = dict_xmd5
srrx = dix["srr"]
srrx.correlation_bars(
type="cross_section",
title=None,
size=(14, 6),
)
Naive PnL #
dix = dict_xmd5
sigx = [dix["sig"]] + dix["rivs"]
targ = dix["targ"]
cidx = dix["cidx"]
start = dix["start"]
naive_pnl = msn.NaivePnL(
dfx,
ret=targ,
sigs=sigx,
cids=cidx,
start=start,
bms=["USD_DU05YXR_NSA", "USD_EQXR_NSA"],
)
for sig in sigx:
naive_pnl.make_pnl(
sig,
sig_neg=True,
sig_op="zn_score_pan",
thresh=3,
rebal_freq="monthly",
vol_scale=10,
rebal_slip=1,
pnl_name=sig + "_PZN",
)
naive_pnl.make_long_pnl(vol_scale=10, label="Long only")
dix["pnls"] = naive_pnl
USD_DU05YXR_NSA has no observations in the DataFrame.
dix = dict_xmd5
start = dix["start"]
cidx = dix["cidx"]
sigx = [dix["sig"]]
naive_pnl = dix["pnls"]
pnls = [s + "_PZN" for s in sigx] + ["Long only"]
dict_labels = {"IMPORTSv5YLD_ZMP_PZN": "based on composite import growth signal",
"Long only": "always long duration (risk parity)"
}
naive_pnl.plot_pnls(
pnl_cats=pnls,
pnl_cids=["ALL"],
start=start,
title=f"Naive PnL of 5-year IRS positions, {len(cidx)} countries (10% ar vol scale)",
xcat_labels=dict_labels,
figsize=(16, 8),
)
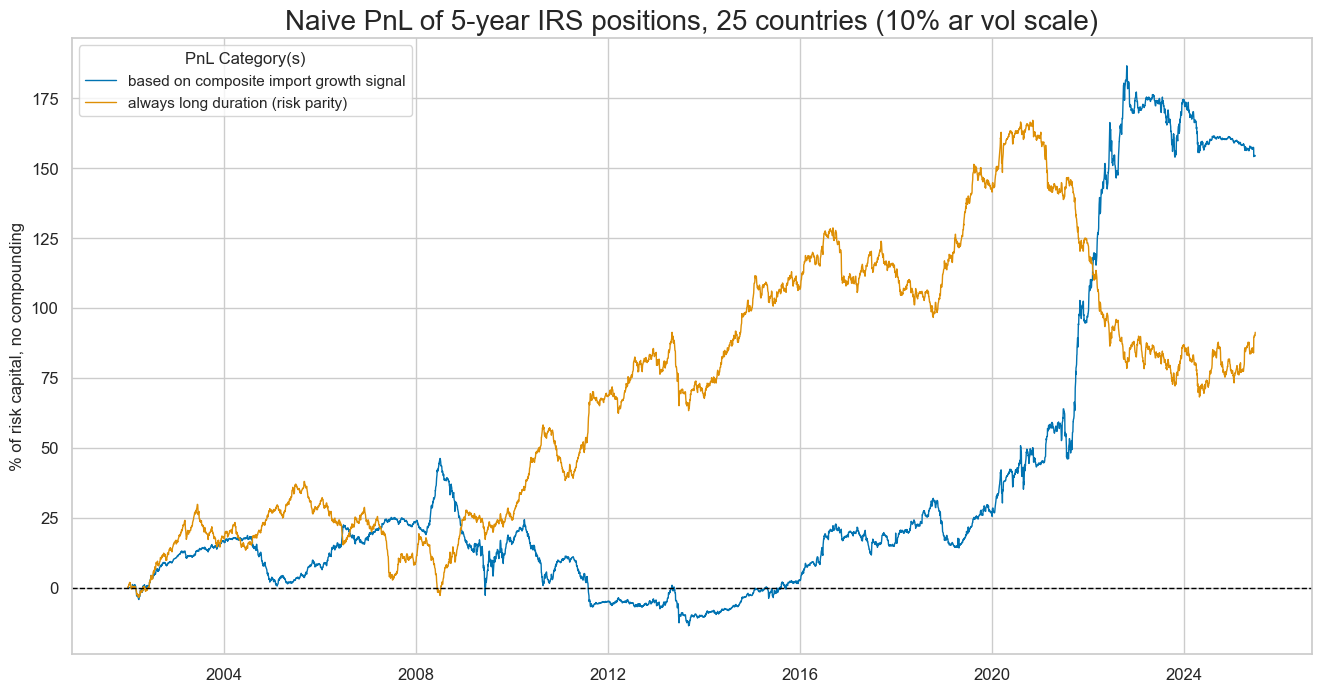
dix = dict_xmd5
start = dix["start"]
sigx = dix["rivs"]
naive_pnl = dix["pnls"]
pnls = [s + "_PZN" for s in sigx]
dict_labels = {"IMPORTS_SA_P3M3ML3ARv5YLD_ZMP_PZN": "%3m/3m, saar",
"IMPORTS_SA_P6M6ML6ARv5YLD_ZMP_PZN": "%6m/6m, saar",
"IMPORTS_SA_P1M1ML12_3MMAv5YLD_ZMP_PZN": "%oya, 3mma"
}
naive_pnl.plot_pnls(
pnl_cats=pnls,
pnl_cids=["ALL"],
start=start,
title="Naive PnL of 5-year IRS positions, various import growth signals (10% ar vol scale)",
xcat_labels=dict_labels,
figsize=(16, 8),
)
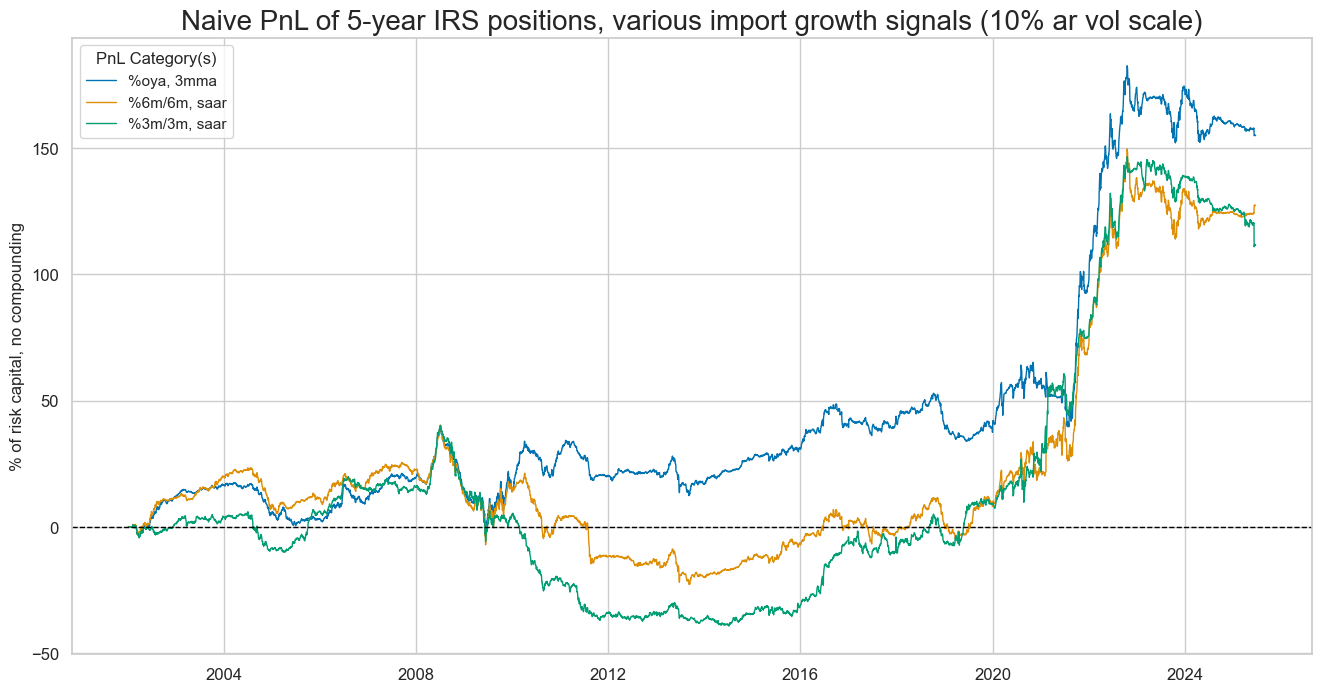
dix = dict_xmd5
start = dix["start"]
sigx = [dix["sig"]] + dix["rivs"]
naive_pnl = dix["pnls"]
pnls = [sig + "_PZN" for sig in sigx]
df_eval = naive_pnl.evaluate_pnls(
pnl_cats=pnls,
pnl_cids=["ALL"],
start=start,
)
display(df_eval.transpose())
| Return % | St. Dev. % | Sharpe Ratio | Sortino Ratio | Max 21-Day Draw % | Max 6-Month Draw % | Peak to Trough Draw % | Top 5% Monthly PnL Share | USD_EQXR_NSA correl | Traded Months | |
|---|---|---|---|---|---|---|---|---|---|---|
| xcat | ||||||||||
| IMPORTSv5YLD_ZMP_PZN | 6.572924 | 10.0 | 0.657292 | 0.983337 | -17.930911 | -26.980173 | -59.8117 | 1.301381 | -0.002865 | 282 |
| IMPORTS_SA_P1M1ML12_3MMAv5YLD_ZMP_PZN | 6.603406 | 10.0 | 0.660341 | 1.011712 | -14.546221 | -24.521487 | -42.438309 | 1.281978 | -0.006922 | 282 |
| IMPORTS_SA_P6M6ML6ARv5YLD_ZMP_PZN | 5.422929 | 10.0 | 0.542293 | 0.807552 | -17.115081 | -27.241933 | -63.024822 | 1.429139 | -0.012065 | 282 |
| IMPORTS_SA_P3M3ML3ARv5YLD_ZMP_PZN | 4.753404 | 10.0 | 0.47534 | 0.689797 | -16.165099 | -25.168802 | -79.280957 | 1.531968 | 0.010624 | 282 |
dix = dict_xmd5
start = dix["start"]
sig = dix["sig"]
naive_pnl = dix["pnls"]
naive_pnl.signal_heatmap(pnl_name=sig + "_PZN", freq="q", start=start, figsize=(16, 7))
Curve (5y versus 2y flattening) #
Specs and panel test #
The hypothesis is that strong import growth predicts swap curve-flattening through a more hawkish monetary policy stance in the near term. This hypothesis relies on the transitory nature of import growth information and the expectations that central banks defend their inflation targets in the long run. Here we define a curve flattening return as the difference between the returns of 5-year and 2-year IRS vol-targeted receiver positions.
ximps_d2 = [x for x in ximps_zmp if "2YLD" in x]
sigs = ximps_d2
ms = "IMPORTSv2YLD_ZMP" # main signal
oths = list(set(sigs) - set([ms])) # other signals
targ = "DU05v02XR"
cidx = cids_dux
start = "2002-01-01"
dict_xm52 = {
"sig": ms,
"rivs": oths,
"targ": targ,
"cidx": cidx,
"start": start,
"srr": None,
"pnls": None,
}
dix = dict_xm52
sig = dix["sig"]
targ = dix["targ"]
cidx = dix["cidx"]
start = dix["start"]
crx = msp.CategoryRelations(
dfx,
xcats=[sig, targ],
cids=cidx,
freq="Q",
lag=1,
xcat_aggs=["last", "sum"],
start=start,
xcat_trims=[200, 40],
)
crx.reg_scatter(
labels=False,
coef_box="lower right",
xlab="Import growth versus nominal GDP growth, composite measure, out-of-sample panel z-score",
ylab="IRS flattening returns (10% vol target), next quarter",
title=f"Excess import growth and subsequent IRS curve flattening returns, {len(cids_dux)} countries",
size=(10, 6),
prob_est="map",
)
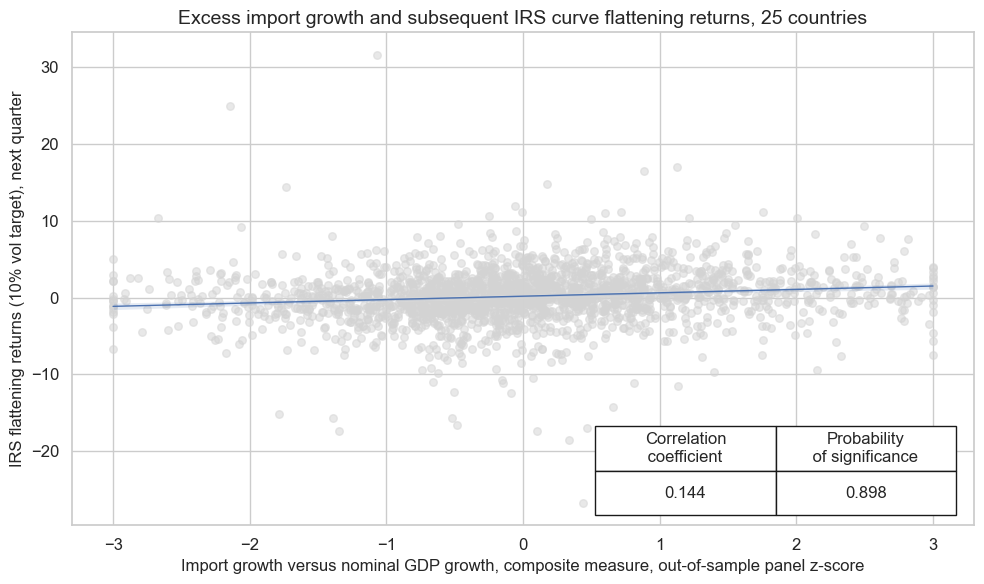
Empirical panel analysis confirms a positive relationship between the composite import growth score and subsequent monthly or quarterly curve flattening returns. The forward correlation coefficient is comparable in size to outright duration return predictions. However, the Macrosynergy panel test only assigns 83% significance to the quarterly relation, reflecting the high cross-country correlation of curve-based returns.
Accuracy and correlation check #
dix = dict_xm52
sig = dix["sig"]
rivs = dix["rivs"]
targ = dix["targ"]
cidx = dix["cidx"]
start = dix["start"]
srr = mss.SignalReturnRelations(
dfx,
cids=cidx,
sigs=[sig] + rivs,
rets=targ,
freqs="M",
start=start,
)
dix["srr"] = srr
dix = dict_xm52
srrx = dix["srr"]
display(srrx.summary_table().astype("float").round(3))
| accuracy | bal_accuracy | pos_sigr | pos_retr | pos_prec | neg_prec | pearson | pearson_pval | kendall | kendall_pval | auc | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| M: IMPORTSv2YLD_ZMP/last => DU05v02XR | 0.541 | 0.542 | 0.486 | 0.531 | 0.574 | 0.510 | 0.089 | 0.000 | 0.081 | 0.000 | 0.542 |
| Mean years | 0.542 | 0.528 | 0.487 | 0.532 | 0.547 | 0.509 | 0.047 | 0.275 | 0.043 | 0.259 | 0.519 |
| Positive ratio | 0.750 | 0.750 | 0.417 | 0.667 | 0.708 | 0.500 | 0.792 | 0.625 | 0.792 | 0.667 | 0.750 |
| Mean cids | 0.540 | 0.541 | 0.489 | 0.533 | 0.574 | 0.507 | 0.106 | 0.241 | 0.082 | 0.202 | 0.541 |
| Positive ratio | 0.840 | 0.880 | 0.480 | 0.680 | 1.000 | 0.600 | 0.840 | 0.800 | 0.960 | 0.800 | 0.880 |
dix = dict_xm52
srrx = dix["srr"]
display(srrx.signals_table().sort_index().astype("float").round(3))
| accuracy | bal_accuracy | pos_sigr | pos_retr | pos_prec | neg_prec | pearson | pearson_pval | kendall | kendall_pval | auc | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Return | Signal | Frequency | Aggregation | |||||||||||
| DU05v02XR | IMPORTS_SA_P1M1ML12_3MMAv2YLD_ZMP | M | last | 0.543 | 0.545 | 0.476 | 0.531 | 0.578 | 0.511 | 0.090 | 0.0 | 0.086 | 0.0 | 0.545 |
| IMPORTS_SA_P3M3ML3ARv2YLD_ZMP | M | last | 0.518 | 0.518 | 0.498 | 0.531 | 0.549 | 0.486 | 0.055 | 0.0 | 0.045 | 0.0 | 0.518 | |
| IMPORTS_SA_P6M6ML6ARv2YLD_ZMP | M | last | 0.542 | 0.543 | 0.480 | 0.531 | 0.576 | 0.510 | 0.085 | 0.0 | 0.079 | 0.0 | 0.544 | |
| IMPORTSv2YLD_ZMP | M | last | 0.541 | 0.542 | 0.486 | 0.531 | 0.574 | 0.510 | 0.089 | 0.0 | 0.081 | 0.0 | 0.542 |
Predictive accuracy for curve flattening returns has been similar in value to directional 2-year returns, with balanced accuracy at 53.9%.
dix = dict_xm52
srrx = dix["srr"]
srrx.correlation_bars(
type="years",
title=None,
size=(14, 6),
)
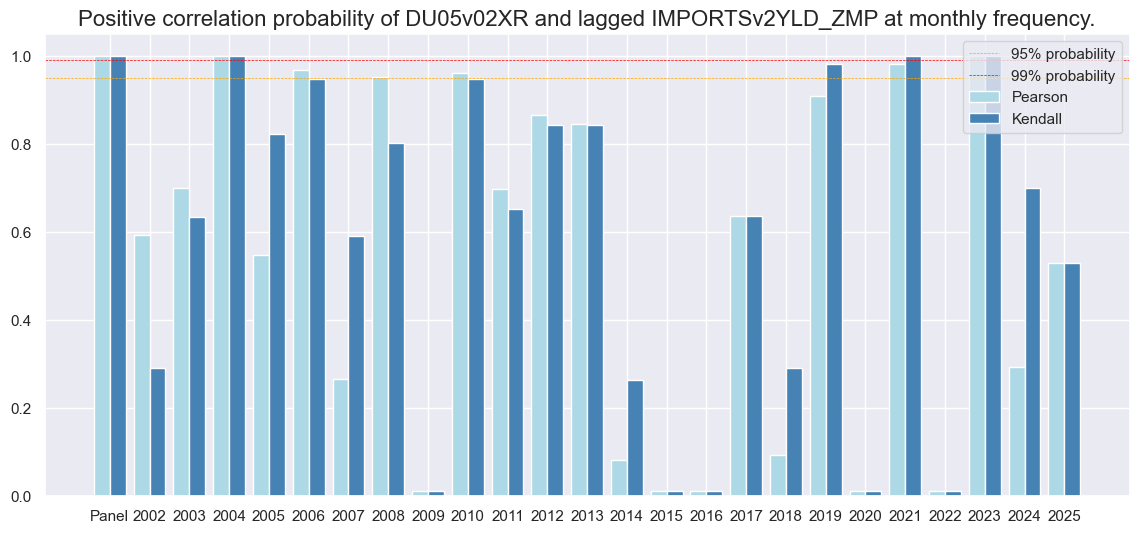
dix = dict_xm52
srrx = dix["srr"]
srrx.correlation_bars(
type="cross_section",
title=None,
size=(14, 6),
)
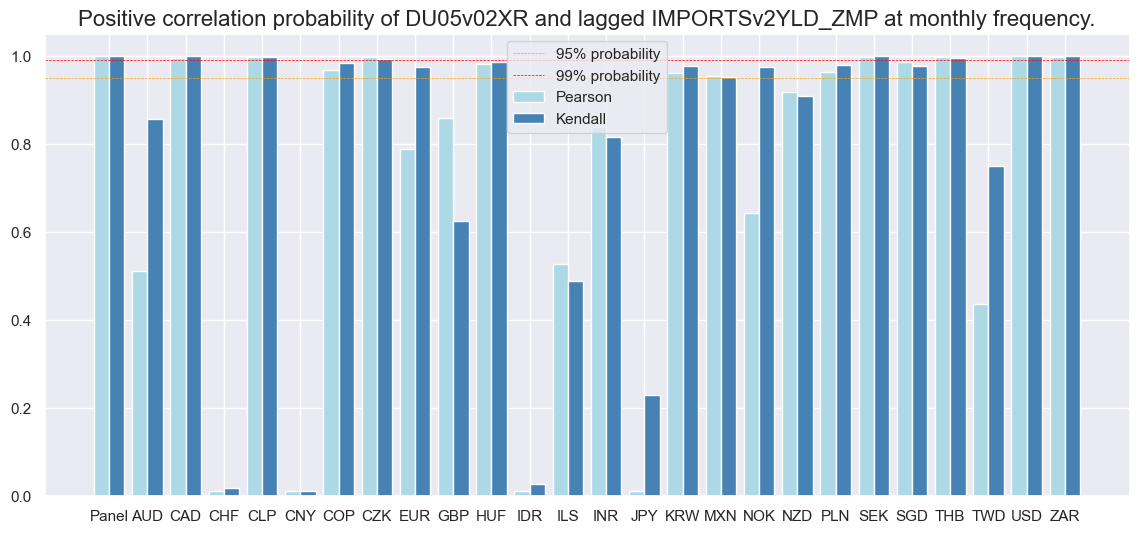
Naive PnL #
dix = dict_xm52
sigx = [dix["sig"]] + dix["rivs"]
targ = dix["targ"]
cidx = dix["cidx"]
start = dix["start"]
naive_pnl = msn.NaivePnL(
dfx,
ret=targ,
sigs=sigx,
cids=cidx,
start=start,
bms=["USD_DU05YXR_NSA", "USD_EQXR_NSA"],
)
for sig in sigx:
naive_pnl.make_pnl(
sig,
sig_neg=False,
sig_op="zn_score_pan",
thresh=3,
rebal_freq="monthly",
vol_scale=10,
rebal_slip=1,
pnl_name=sig + "_PZN",
)
naive_pnl.make_long_pnl(vol_scale=10, label="Long only")
dix["pnls"] = naive_pnl
USD_DU05YXR_NSA has no observations in the DataFrame.
dix = dict_xm52
start = dix["start"]
cidx = dix["cidx"]
sigx = [dix["sig"]]
naive_pnl = dix["pnls"]
pnls = [s + "_PZN" for s in sigx] + ["Long only"]
dict_labels = {"IMPORTSv2YLD_ZMP_PZN": "based on composite import growth signal",
"Long only": "always receive 5s and pay 2s (risk parity)"
}
naive_pnl.plot_pnls(
pnl_cats=pnls,
pnl_cids=["ALL"],
start=start,
title=f"Naive PnL of IRS 5s-2s flattening positions, {len(cidx)} countries (10% ar vol scale)",
xcat_labels=dict_labels,
figsize=(16, 8),
)
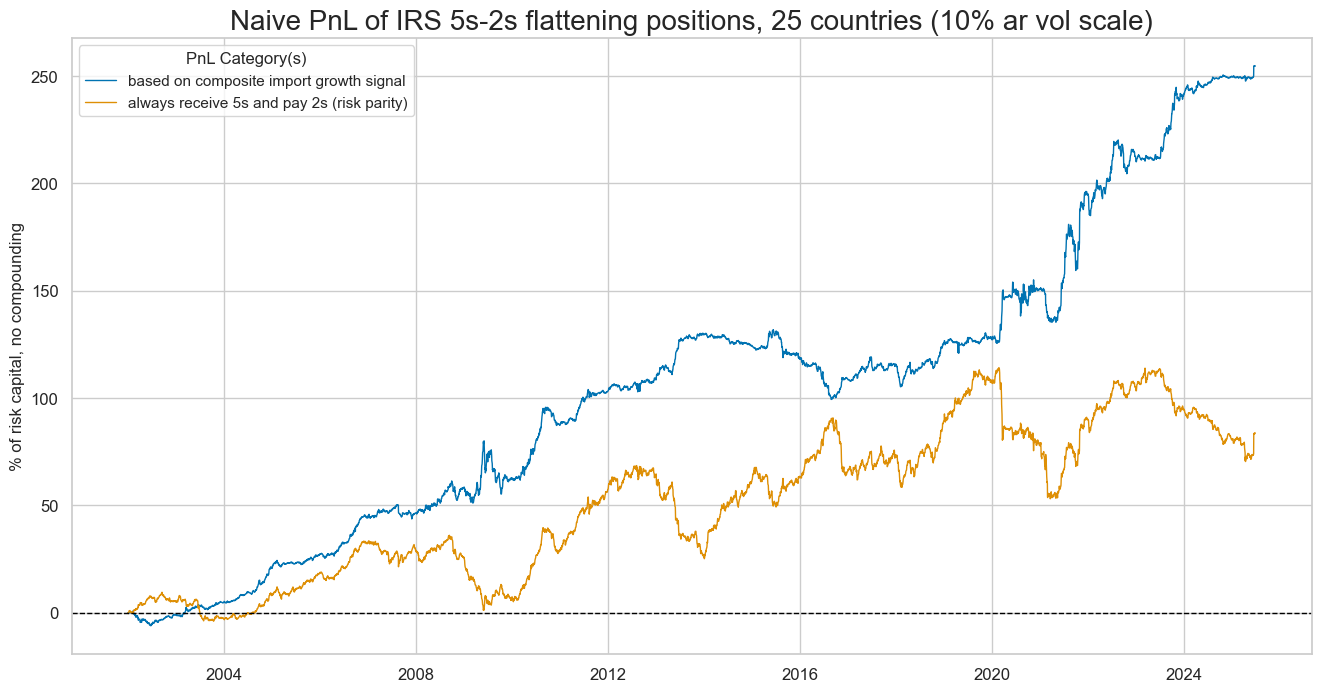
Like the directional strategy, the imports-based curve strategy has performed well in economic turbulences.
pnls
['IMPORTSv2YLD_ZMP_PZN', 'Long only']
dix = dict_xm52
start = dix["start"]
sigx = dix["rivs"]
naive_pnl = dix["pnls"]
pnls = [s + "_PZN" for s in sigx]
dict_labels = {"IMPORTS_SA_P3M3ML3ARv2YLD_ZMP_PZN": "%oya, 3mma",
"IMPORTS_SA_P6M6ML6ARv2YLD_ZMP_PZN": "%6m/6m, saar",
"IMPORTS_SA_P1M1ML12_3MMAv2YLD_ZMP_PZN": "%oya, 3mma"
}
naive_pnl.plot_pnls(
pnl_cats=pnls,
pnl_cids=["ALL"],
start=start,
title="Naive PnL of 5-year IRS positions, various import growth signals (10% ar vol scale)",
xcat_labels=dict_labels,
figsize=(16, 8),
)
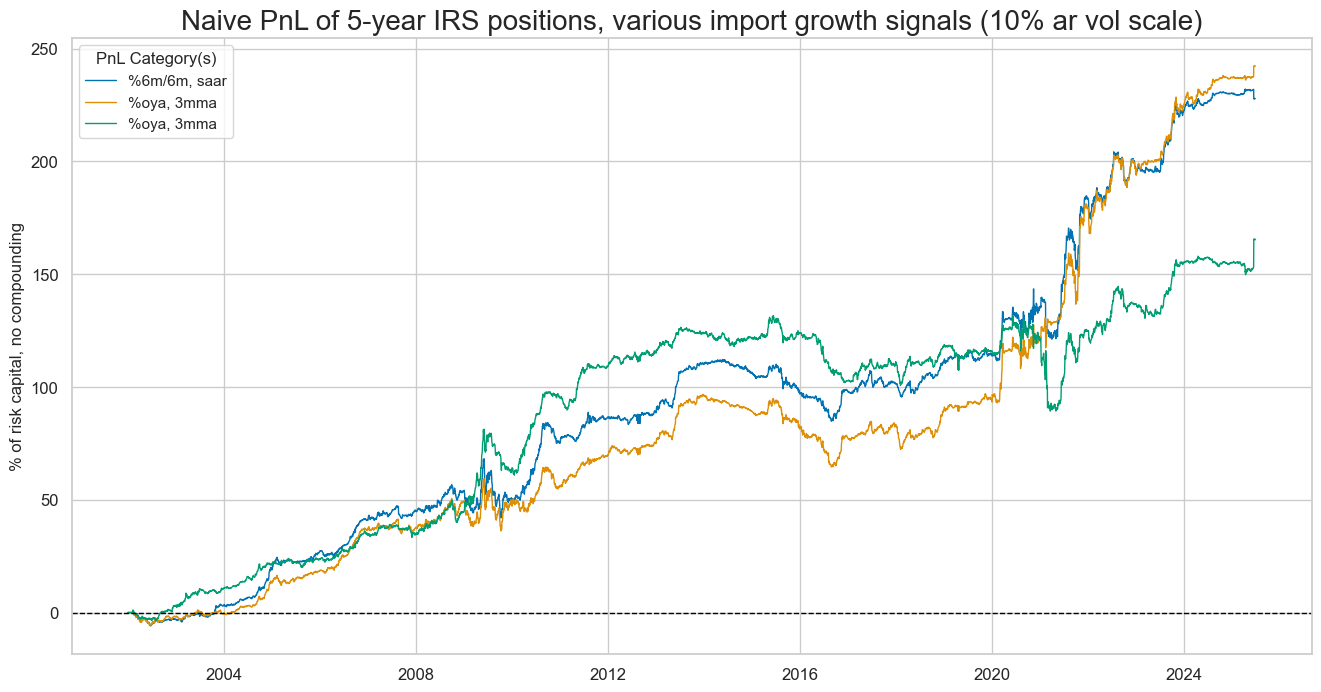
All import growth rates would have produced significant and roughly similar economic value as a scored trading signal for curve positions.
dix = dict_xm52
start = dix["start"]
sigx = [dix["sig"]] + dix["rivs"]
naive_pnl = dix["pnls"]
pnls = [sig + "_PZN" for sig in sigx]
df_eval = naive_pnl.evaluate_pnls(
pnl_cats=pnls,
pnl_cids=["ALL"],
start=start,
)
display(df_eval.transpose())
| Return % | St. Dev. % | Sharpe Ratio | Sortino Ratio | Max 21-Day Draw % | Max 6-Month Draw % | Peak to Trough Draw % | Top 5% Monthly PnL Share | USD_EQXR_NSA correl | Traded Months | |
|---|---|---|---|---|---|---|---|---|---|---|
| xcat | ||||||||||
| IMPORTSv2YLD_ZMP_PZN | 10.848906 | 10.0 | 1.084891 | 1.647826 | -18.780165 | -18.189621 | -32.481942 | 0.73105 | 0.00737 | 282 |
| IMPORTS_SA_P6M6ML6ARv2YLD_ZMP_PZN | 9.708573 | 10.0 | 0.970857 | 1.419109 | -16.72209 | -19.116753 | -27.314103 | 0.768393 | 0.000801 | 282 |
| IMPORTS_SA_P1M1ML12_3MMAv2YLD_ZMP_PZN | 10.323987 | 10.0 | 1.032399 | 1.527301 | -19.851622 | -13.82832 | -32.144933 | 0.700122 | -0.001017 | 282 |
| IMPORTS_SA_P3M3ML3ARv2YLD_ZMP_PZN | 7.051329 | 10.0 | 0.705133 | 1.059505 | -25.528627 | -38.491035 | -42.313686 | 0.878696 | 0.019334 | 282 |
Relative (2y) #
Specs and panel test #
The hypothesis is that countries with stronger imports will subsequently experience lower duration returns than those with weaker import growth. Differentials in local-currency import growth are seen as indicative of differences in growth and inflation and, hence, for resultant differences in changes in monetary policy. The monetary policy links suggest that predictive power should be stronger for relative 2-year IRS receiver returns than for relative 5-year IRS receiver returns. The term “relative” here refers to the value of the local currency area minus the average value for all tradable currency areas at the given time period.
ximps_d2 = [x for x in ximps_zmp if "2YLD" in x]
for_sigs = ximps_d2
sigs = [s + "vGLB" for s in for_sigs]
ms = "IMPORTSv2YLD_ZMPvGLB" # main signal
oths = list(set(sigs) - set([ms])) # other signals
targ = "DU02YXR_VT10vGLB"
cidx = cids_dux
start = "2002-01-01"
dict_imr2 = {
"sig": ms,
"rivs": oths,
"targ": targ,
"cidx": cidx,
"start": start,
"srr": None,
"pnls": None,
}
dix = dict_imr2
sig = dix["sig"]
targ = dix["targ"]
cidx = dix["cidx"]
crx = msp.CategoryRelations(
dfx,
xcats=[sig, targ],
cids=cidx,
freq="Q",
lag=1,
xcat_aggs=["last", "sum"],
start="2000-01-01",
xcat_trims=[200, 40], # extreme value distorts scatter
)
crx.reg_scatter(
labels=False,
coef_box="upper right",
xlab="Excess import growth relative to the global average, composite measure, out-of-sample panel z-score",
ylab="2-year IRS returns versus global (10% vol target), next quarter",
title=f"Relative import growth and subsequent relative 2-year IRS returns, {len(cidx)} countries",
size=(10, 6),
prob_est="map",
)
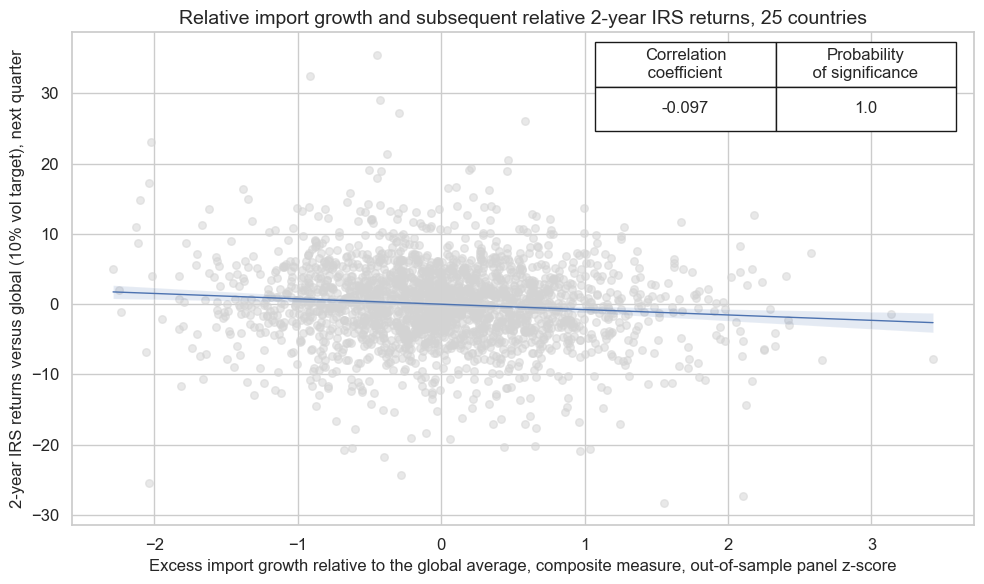
The Macrosynergy panel tests suggest that the relationship is negative and highly significant with a probability of nearly 100% for either monthly or quarterly frequency.
Accuracy and correlation check #
dix = dict_imr2
sig = dix["sig"]
rivs = dix["rivs"]
targ = dix["targ"]
cidx = dix["cidx"]
start = dix["start"]
srr = mss.SignalReturnRelations(
dfx,
cids=cidx,
sigs=[sig] + rivs,
sig_neg=[True] + [True] * len(rivs),
rets=targ,
freqs="M",
start=start,
)
dix["srr"] = srr
dix = dict_imr2
srrx = dix["srr"]
display(srrx.summary_table().astype("float").round(3))
| accuracy | bal_accuracy | pos_sigr | pos_retr | pos_prec | neg_prec | pearson | pearson_pval | kendall | kendall_pval | auc | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| M: IMPORTSv2YLD_ZMPvGLB_NEG/last => DU02YXR_VT10vGLB | 0.518 | 0.517 | 0.521 | 0.512 | 0.528 | 0.506 | 0.062 | 0.000 | 0.036 | 0.000 | 0.517 |
| Mean years | 0.522 | 0.521 | 0.522 | 0.511 | 0.532 | 0.511 | 0.073 | 0.344 | 0.041 | 0.393 | 0.521 |
| Positive ratio | 0.583 | 0.583 | 0.583 | 0.625 | 0.667 | 0.500 | 0.833 | 0.583 | 0.667 | 0.542 | 0.583 |
| Mean cids | 0.517 | 0.516 | 0.518 | 0.512 | 0.526 | 0.505 | 0.055 | 0.364 | 0.036 | 0.345 | 0.516 |
| Positive ratio | 0.680 | 0.640 | 0.680 | 0.560 | 0.680 | 0.520 | 0.760 | 0.520 | 0.760 | 0.560 | 0.640 |
dix = dict_imr2
srrx = dix["srr"]
display(srrx.signals_table().sort_index().astype("float").round(3))
| accuracy | bal_accuracy | pos_sigr | pos_retr | pos_prec | neg_prec | pearson | pearson_pval | kendall | kendall_pval | auc | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Return | Signal | Frequency | Aggregation | |||||||||||
| DU02YXR_VT10vGLB | IMPORTS_SA_P1M1ML12_3MMAv2YLD_ZMPvGLB_NEG | M | last | 0.512 | 0.512 | 0.511 | 0.512 | 0.524 | 0.500 | 0.062 | 0.000 | 0.031 | 0.000 | 0.512 |
| IMPORTS_SA_P3M3ML3ARv2YLD_ZMPvGLB_NEG | M | last | 0.516 | 0.515 | 0.523 | 0.512 | 0.527 | 0.504 | 0.034 | 0.007 | 0.025 | 0.003 | 0.515 | |
| IMPORTS_SA_P6M6ML6ARv2YLD_ZMPvGLB_NEG | M | last | 0.518 | 0.518 | 0.520 | 0.512 | 0.529 | 0.506 | 0.060 | 0.000 | 0.032 | 0.000 | 0.518 | |
| IMPORTSv2YLD_ZMPvGLB_NEG | M | last | 0.518 | 0.517 | 0.521 | 0.512 | 0.529 | 0.506 | 0.062 | 0.000 | 0.036 | 0.000 | 0.517 |
The balanced accuracy of the prediction of monthly return directions has been lower than in the case of directional signals. For the 2-year relative IRS receiver returns it has been at 51.4%. Lower precision is a common feature of relative economic signals because data are not fully comparable across countries and a part of the signal reflects irrelevant differences in data conventions and economic structure.
dix = dict_imr2
srrx = dix["srr"]
srrx.correlation_bars(
type="years",
title=None,
size=(14, 6),
)
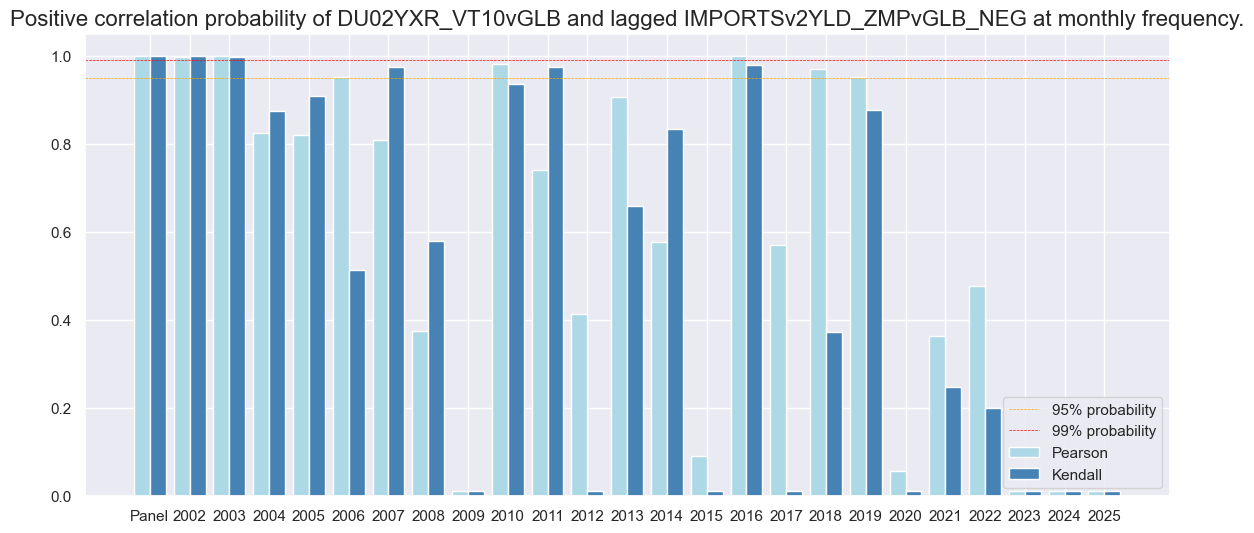
dix = dict_imr2
srrx = dix["srr"]
srrx.correlation_bars(
type="cross_section",
title=None,
size=(14, 6),
)
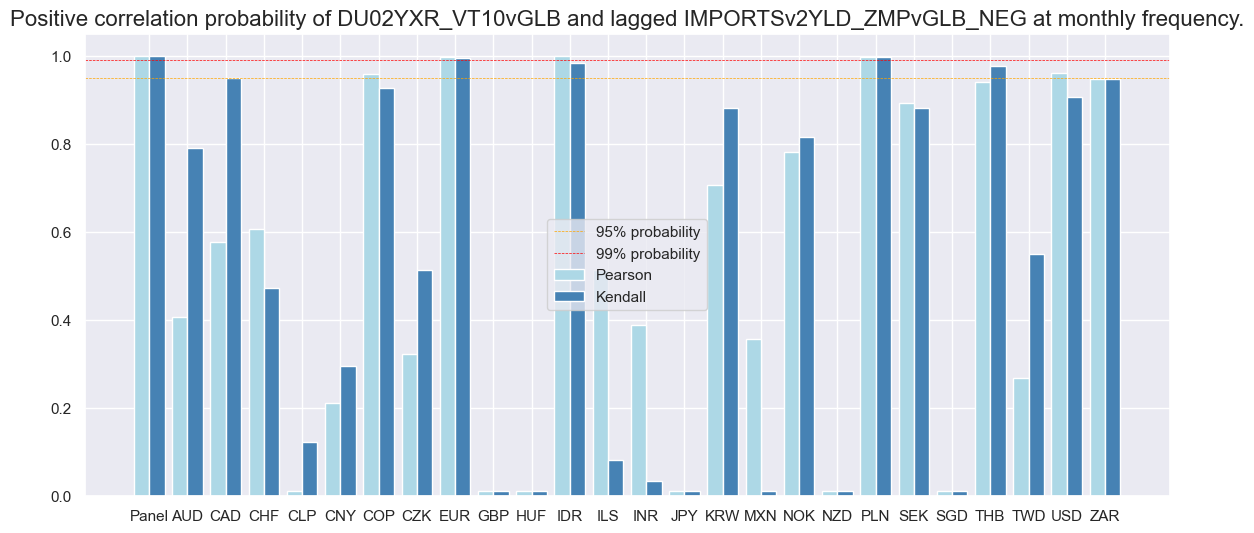
Naive PnL #
dix = dict_imr2
sigx = [dix["sig"]] + dix["rivs"]
targ = dix["targ"]
cidx = dix["cidx"]
start = dix["start"]
naive_pnl = msn.NaivePnL(
dfx,
ret=targ,
sigs=sigx,
cids=cidx,
start=start,
bms=["USD_DU05YXR_NSA", "USD_EQXR_NSA"],
)
for sig in sigx:
naive_pnl.make_pnl(
sig,
sig_neg=True,
sig_op="zn_score_pan",
thresh=3,
rebal_freq="monthly",
vol_scale=10,
rebal_slip=1,
pnl_name=sig + "_PZN",
)
dix["pnls"] = naive_pnl
USD_DU05YXR_NSA has no observations in the DataFrame.
dix = dict_imr2
start = dix["start"]
cidx = dix["cidx"]
sigx = [dix["sig"]]
naive_pnl = dix["pnls"]
pnls = [s + "_PZN" for s in sigx]
dict_labels = {"IMPORTSv2YLD_ZMPvGLB_PZN": "based on relative composite import growth signal"}
naive_pnl.plot_pnls(
pnl_cats=pnls,
pnl_cids=["ALL"],
start=start,
title=f"Naive PnL of relative 2-year IRS positions, {len(cidx)} countries (10% ar vol scale)",
xcat_labels=dict_labels,
figsize=(16, 8),
)
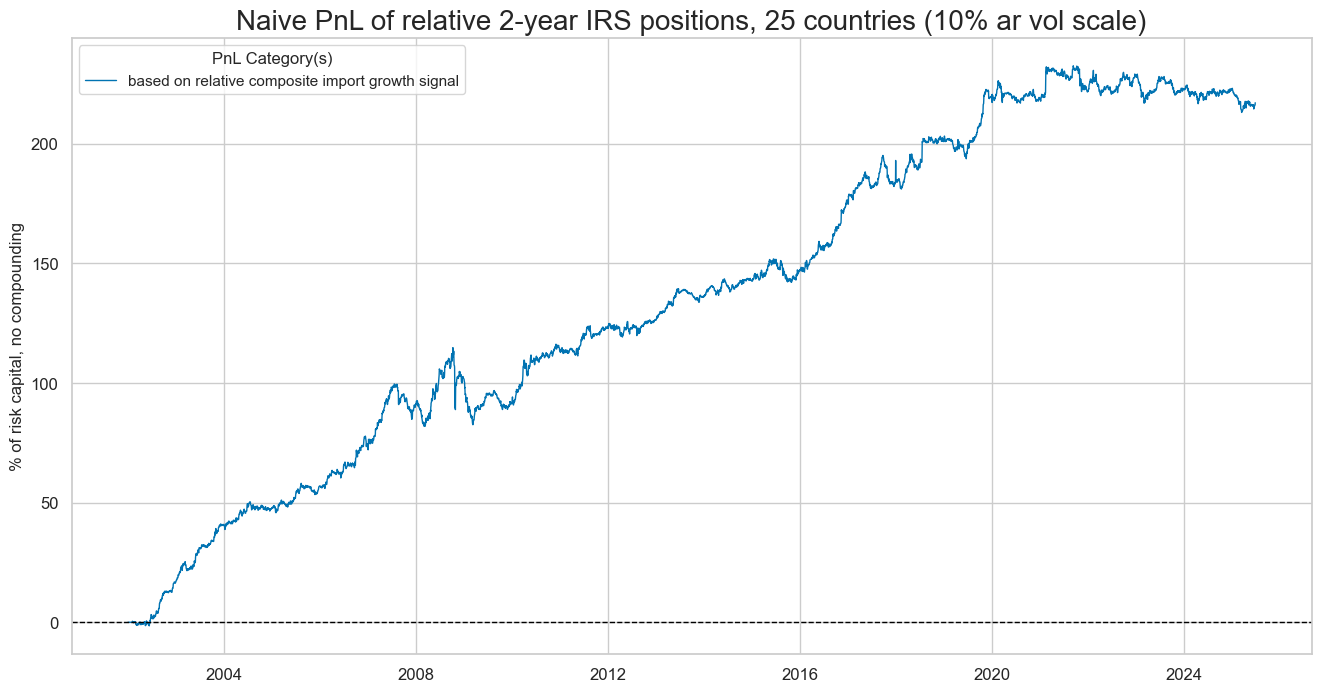
The economic value of the relative import growth score trading signal has been less seasonal than those based on directional signals. The consistent and robust performance of relative import growth as a trading signal reflects the diversification benefits of relative versus directional positions. The flip side is that this strategy requires higher leverage than a directional portfolio for the same return target, translating into higher transaction costs (not considered in this analysis).
dix = dict_imr2
start = dix["start"]
sigx = dix["rivs"]
naive_pnl = dix["pnls"]
pnls = [s + "_PZN" for s in sigx]
dict_labels = {"IMPORTS_SA_P3M3ML3ARv2YLD_ZMPvGLB_PZN": "%3m/3m, saar",
"IMPORTS_SA_P6M6ML6ARv2YLD_ZMPvGLB_PZN": "%6m/6m, saar",
"IMPORTS_SA_P1M1ML12_3MMAv2YLD_ZMPvGLB_PZN": "%oya, 3mma"
}
naive_pnl.plot_pnls(
pnl_cats=pnls,
pnl_cids=["ALL"],
start=start,
title="Naive PnL of 2-year IRS positions, various import growth signals (10% ar vol scale)",
xcat_labels=dict_labels,
figsize=(16, 8),
)
dix = dict_imr2
start = dix["start"]
sigx = [dix["sig"]] + dix["rivs"]
naive_pnl = dix["pnls"]
pnls = [sig + "_PZN" for sig in sigx]
df_eval = naive_pnl.evaluate_pnls(
pnl_cats=pnls,
pnl_cids=["ALL"],
start=start,
)
display(df_eval.transpose())
| Return % | St. Dev. % | Sharpe Ratio | Sortino Ratio | Max 21-Day Draw % | Max 6-Month Draw % | Peak to Trough Draw % | Top 5% Monthly PnL Share | USD_EQXR_NSA correl | Traded Months | |
|---|---|---|---|---|---|---|---|---|---|---|
| xcat | ||||||||||
| IMPORTSv2YLD_ZMPvGLB_PZN | 9.251873 | 10.0 | 0.925187 | 1.339818 | -21.256292 | -26.318217 | -32.207383 | 0.507486 | 0.037473 | 282 |
| IMPORTS_SA_P3M3ML3ARv2YLD_ZMPvGLB_PZN | 5.855281 | 10.0 | 0.585528 | 0.83475 | -28.271295 | -29.635003 | -39.289195 | 0.712792 | 0.058267 | 282 |
| IMPORTS_SA_P6M6ML6ARv2YLD_ZMPvGLB_PZN | 8.3122 | 10.0 | 0.83122 | 1.237015 | -12.751704 | -20.429788 | -39.944784 | 0.643587 | 0.004653 | 282 |
| IMPORTS_SA_P1M1ML12_3MMAv2YLD_ZMPvGLB_PZN | 8.675352 | 10.0 | 0.867535 | 1.287167 | -13.956558 | -19.081038 | -24.845868 | 0.577342 | 0.029545 | 282 |
The table above shows impressive strategy ratios: long-term Sharpe ratio of 1 and no equity market correlation.
dix = dict_imr2
start = dix["start"]
sig = dix["sig"]
naive_pnl = dix["pnls"]
naive_pnl.signal_heatmap(pnl_name=sig + "_PZN", freq="q", start=start, figsize=(16, 7))
Relative (5y) #
Specs and panel test #
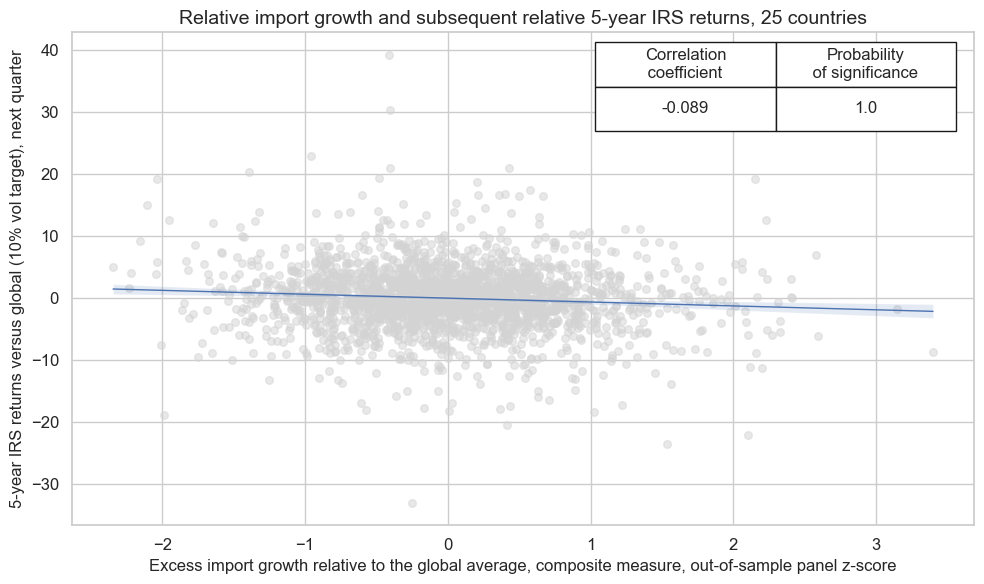
A very similar analysis based on the 5-year maturities would have produced a little less value, with Sharpe 0.9, and with greater seasonality:
ximps_d5 = [x for x in ximps_zmp if "5YLD" in x]
for_sigs = ximps_d5
sigs = [s + "vGLB" for s in for_sigs]
ms = "IMPORTSv5YLD_ZMPvGLB" # main signal
oths = list(set(sigs) - set([ms])) # other signals
targ = "DU05YXR_VT10vGLB"
cidx = cids_dux
start = "2002-01-01"
dict_imr5 = {
"sig": ms,
"rivs": oths,
"targ": targ,
"cidx": cidx,
"start": start,
"srr": None,
"pnls": None,
}
dix = dict_imr5
sig = dix["sig"]
targ = dix["targ"]
cidx = dix["cidx"]
crx = msp.CategoryRelations(
dfx,
xcats=[sig, targ],
cids=cidx,
freq="Q",
lag=1,
xcat_aggs=["last", "sum"],
start="2000-01-01",
xcat_trims=[200, 40], # extreme value distorts scatter
)
crx.reg_scatter(
labels=False,
coef_box="upper right",
xlab="Excess import growth relative to the global average, composite measure, out-of-sample panel z-score",
ylab="5-year IRS returns versus global (10% vol target), next quarter",
title=f"Relative import growth and subsequent relative 5-year IRS returns, {len(cidx)} countries",
size=(10, 6),
prob_est="map",
)
Accuracy and correlation check #
dix = dict_imr5
sig = dix["sig"]
rivs = dix["rivs"]
targ = dix["targ"]
cidx = dix["cidx"]
start = dix["start"]
srr = mss.SignalReturnRelations(
dfx,
cids=cidx,
sigs=[sig] + rivs,
sig_neg=[True] + [True] * len(rivs),
rets=targ,
freqs="M",
start=start,
)
dix["srr"] = srr
dix = dict_imr5
srrx = dix["srr"]
display(srrx.summary_table().astype("float").round(3))
| accuracy | bal_accuracy | pos_sigr | pos_retr | pos_prec | neg_prec | pearson | pearson_pval | kendall | kendall_pval | auc | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| M: IMPORTSv5YLD_ZMPvGLB_NEG/last => DU05YXR_VT10vGLB | 0.513 | 0.513 | 0.524 | 0.507 | 0.519 | 0.506 | 0.056 | 0.000 | 0.031 | 0.000 | 0.513 |
| Mean years | 0.513 | 0.513 | 0.525 | 0.506 | 0.519 | 0.507 | 0.067 | 0.353 | 0.034 | 0.367 | 0.513 |
| Positive ratio | 0.625 | 0.625 | 0.583 | 0.667 | 0.667 | 0.500 | 0.833 | 0.583 | 0.750 | 0.542 | 0.625 |
| Mean cids | 0.512 | 0.513 | 0.520 | 0.507 | 0.518 | 0.508 | 0.051 | 0.372 | 0.032 | 0.399 | 0.512 |
| Positive ratio | 0.680 | 0.640 | 0.680 | 0.560 | 0.760 | 0.600 | 0.840 | 0.480 | 0.720 | 0.480 | 0.640 |
dix = dict_imr5
srrx = dix["srr"]
display(srrx.signals_table().sort_index().astype("float").round(3))
| accuracy | bal_accuracy | pos_sigr | pos_retr | pos_prec | neg_prec | pearson | pearson_pval | kendall | kendall_pval | auc | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Return | Signal | Frequency | Aggregation | |||||||||||
| DU05YXR_VT10vGLB | IMPORTS_SA_P1M1ML12_3MMAv5YLD_ZMPvGLB_NEG | M | last | 0.505 | 0.505 | 0.510 | 0.507 | 0.512 | 0.498 | 0.054 | 0.000 | 0.023 | 0.007 | 0.505 |
| IMPORTS_SA_P3M3ML3ARv5YLD_ZMPvGLB_NEG | M | last | 0.518 | 0.518 | 0.524 | 0.507 | 0.524 | 0.512 | 0.026 | 0.036 | 0.026 | 0.002 | 0.518 | |
| IMPORTS_SA_P6M6ML6ARv5YLD_ZMPvGLB_NEG | M | last | 0.511 | 0.510 | 0.521 | 0.507 | 0.517 | 0.504 | 0.062 | 0.000 | 0.025 | 0.003 | 0.510 | |
| IMPORTSv5YLD_ZMPvGLB_NEG | M | last | 0.513 | 0.513 | 0.524 | 0.507 | 0.519 | 0.506 | 0.056 | 0.000 | 0.031 | 0.000 | 0.513 |
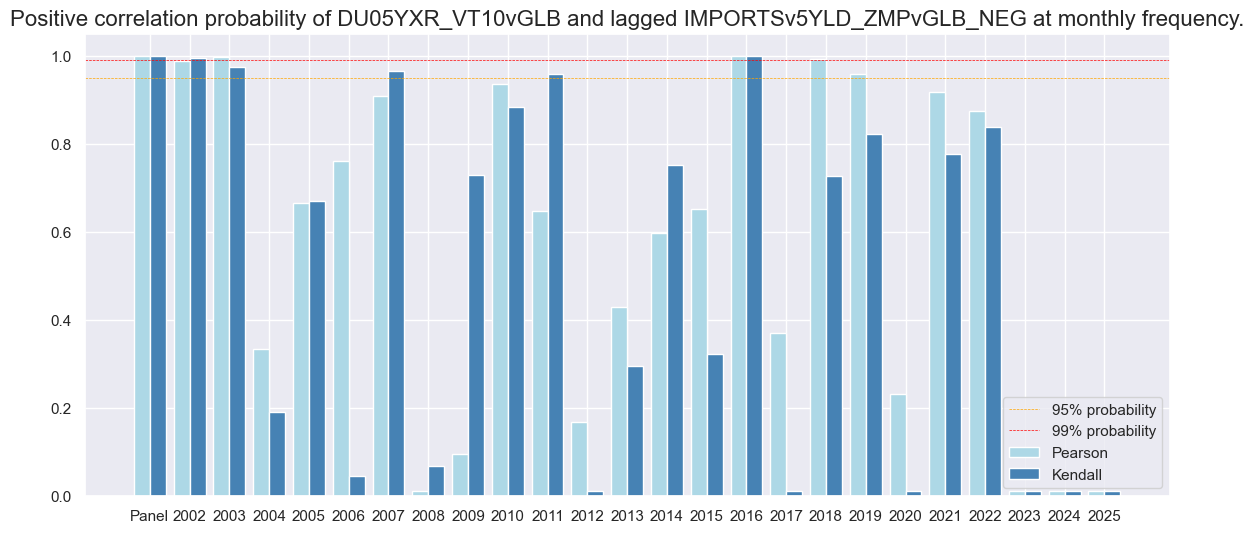
dix = dict_imr5
srrx = dix["srr"]
srrx.correlation_bars(
type="years",
title=None,
size=(14, 6),
)
dix = dict_imr5
srrx = dix["srr"]
srrx.correlation_bars(
type="cross_section",
title=None,
size=(14, 6),
)
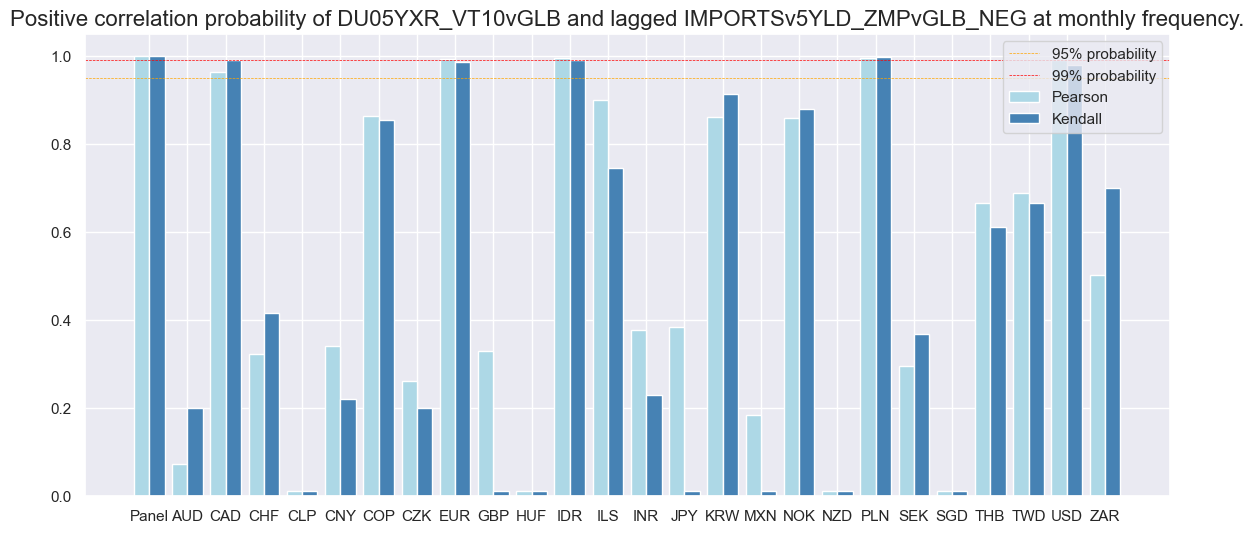
Naive PnL #
dix = dict_imr5
sigx = [dix["sig"]] + dix["rivs"]
targ = dix["targ"]
cidx = dix["cidx"]
start = dix["start"]
naive_pnl = msn.NaivePnL(
dfx,
ret=targ,
sigs=sigx,
cids=cidx,
start=start,
bms=["USD_DU05YXR_NSA", "USD_EQXR_NSA"],
)
for sig in sigx:
naive_pnl.make_pnl(
sig,
sig_neg=True,
sig_op="zn_score_pan",
thresh=3,
rebal_freq="monthly",
vol_scale=10,
rebal_slip=1,
pnl_name=sig + "_PZN",
)
dix["pnls"] = naive_pnl
USD_DU05YXR_NSA has no observations in the DataFrame.
dix = dict_imr5
start = dix["start"]
cidx = dix["cidx"]
sigx = [dix["sig"]]
naive_pnl = dix["pnls"]
pnls = [s + "_PZN" for s in sigx]
dict_labels = {"IMPORTSv5YLD_ZMPvGLB_PZN": "based on composite import growth signal",
}
naive_pnl.plot_pnls(
pnl_cats=pnls,
pnl_cids=["ALL"],
start=start,
title=f"Naive PnL of relative 5-year IRS positions, {len(cidx)} countries (10% ar vol scale)",
xcat_labels=dict_labels,
figsize=(16, 8),
)
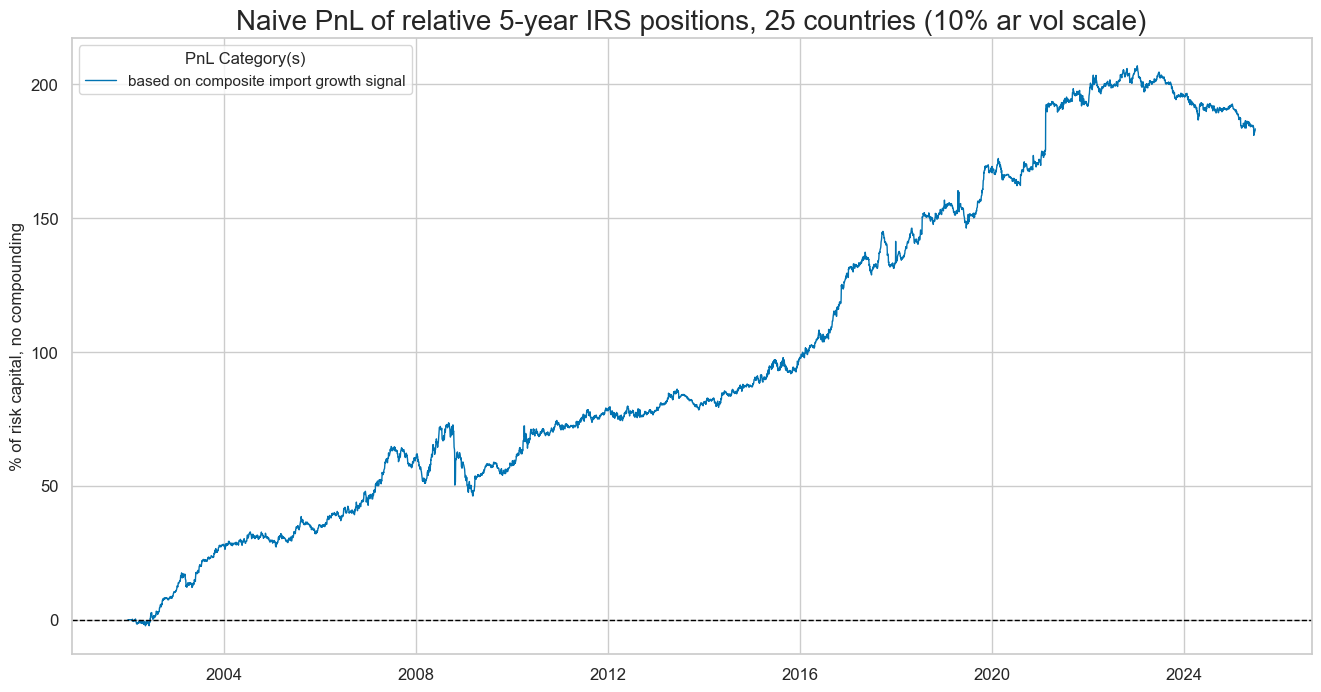
dix = dict_imr5
start = dix["start"]
sigx = dix["rivs"]
naive_pnl = dix["pnls"]
pnls = [s + "_PZN" for s in sigx]
dict_labels = {"IMPORTS_SA_P3M3ML3ARv5YLD_ZMPvGLB_PZN": "%oya, 3mma",
"IMPORTS_SA_P6M6ML6ARv5YLD_ZMPvGLB_PZN": "%6m/6m, saar",
"IMPORTS_SA_P1M1ML12_3MMAv5YLD_ZMPvGLB_PZN": "%oya, 3mma"
}
naive_pnl.plot_pnls(
pnl_cats=pnls,
pnl_cids=["ALL"],
start=start,
title="Naive PnL of 2-year IRS positions, various import growth signals (10% ar vol scale)",
xcat_labels=dict_labels,
figsize=(16, 8),
)
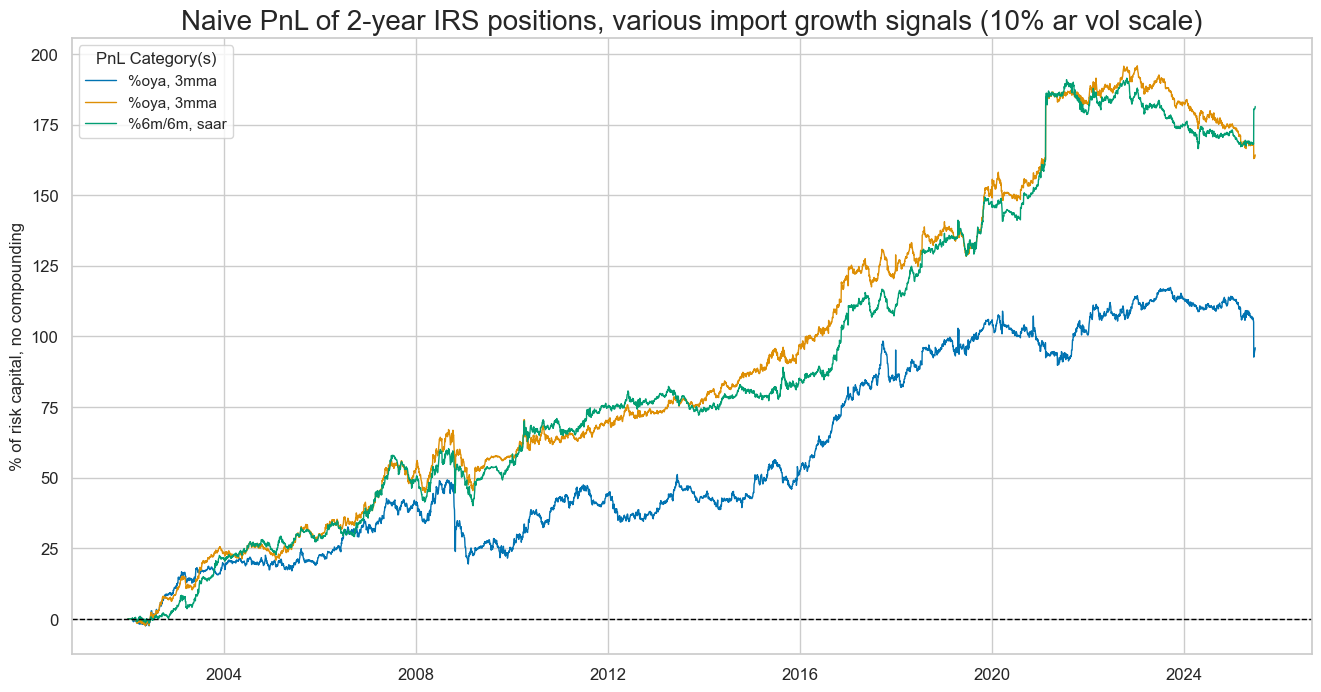
dix = dict_imr5
start = dix["start"]
sigx = [dix["sig"]] + dix["rivs"]
naive_pnl = dix["pnls"]
pnls = [sig + "_PZN" for sig in sigx]
df_eval = naive_pnl.evaluate_pnls(
pnl_cats=pnls,
pnl_cids=["ALL"],
start=start,
)
display(df_eval.transpose())
| Return % | St. Dev. % | Sharpe Ratio | Sortino Ratio | Max 21-Day Draw % | Max 6-Month Draw % | Peak to Trough Draw % | Top 5% Monthly PnL Share | USD_EQXR_NSA correl | Traded Months | |
|---|---|---|---|---|---|---|---|---|---|---|
| xcat | ||||||||||
| IMPORTSv5YLD_ZMPvGLB_PZN | 7.80845 | 10.0 | 0.780845 | 1.196914 | -20.478667 | -25.901286 | -27.350701 | 0.5828 | 0.026047 | 282 |
| IMPORTS_SA_P3M3ML3ARv5YLD_ZMPvGLB_PZN | 4.089405 | 10.0 | 0.408941 | 0.565543 | -24.111746 | -27.585788 | -29.75733 | 0.872472 | 0.038491 | 282 |
| IMPORTS_SA_P1M1ML12_3MMAv5YLD_ZMPvGLB_PZN | 6.997865 | 10.0 | 0.699786 | 1.123686 | -15.114439 | -20.326093 | -32.833135 | 0.689735 | 0.023586 | 282 |
| IMPORTS_SA_P6M6ML6ARv5YLD_ZMPvGLB_PZN | 7.72802 | 10.0 | 0.772802 | 1.318317 | -12.628883 | -18.442718 | -24.92287 | 0.704613 | 0.003197 | 282 |
dix = dict_imr5
start = dix["start"]
sig = dix["sig"]
naive_pnl = dix["pnls"]
naive_pnl.signal_heatmap(pnl_name=sig + "_PZN", freq="q", start=start, figsize=(16, 7))