Equity country allocation scorecard #
Get packages and JPMaQS data #
import tqdm
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import warnings
import os
import gc
from datetime import date, datetime
import macrosynergy.management as msm
import macrosynergy.panel as msp
import macrosynergy.signal as mss
import macrosynergy.pnl as msn
import macrosynergy.learning as msl
import macrosynergy.visuals as msv
from macrosynergy.panel.panel_imputer import MeanPanelImputer
from macrosynergy.panel.adjust_weights import adjust_weights
from macrosynergy.download import JPMaQSDownload
from macrosynergy.visuals import ScoreVisualisers
pd.set_option('display.width', 400)
import warnings
warnings.simplefilter("ignore")
# Cross-sections of interest
cids_dmeq = ["AUD", "CAD", "CHF", "EUR", "GBP", "JPY", "SEK", "USD"]
cids_eueq = ["DEM", "ESP", "FRF", "ITL", "NLG"]
cids_aseq = ["CNY", "HKD", "INR", "KRW", "MYR", "SGD", "THB", "TWD"]
cids_exeq = ["BRL", "TRY", "ZAR"]
cids_nueq = ["MXN", "PLN"]
cids_no_jpmaqs = ["HKD", "TRY"]
cids_eq = sorted(list(set(cids_dmeq + cids_eueq + cids_aseq + cids_exeq + cids_nueq) - set(cids_no_jpmaqs + cids_eueq)))
cids = cids_eq
# Category tickers
inf = (
[
f"{cat}_{at}"
for cat in [
"CPIC",
"CPIH",
]
for at in [
"SA_P1M1ML12",
"SA_P1Q1QL4",
]
] + ["PPIH_NSA_P1M1ML12"]
)
surveys = [
f"{cat}_{at}"
for cat in ["CCSCORE", "MBCSCORE"]
for at in [
"SA_D3M3ML3",
"SA_D1Q1QL1",
"SA_D1M1ML12",
"SA_D1Q1QL4",
]
]
flows = [
f"{flow}_NSA_D1M1ML12" for flow in ["NIIPGDP", "IIPLIABGDP"]
]
trade = (
[
f"{cat}_{at}"
for cat in ["CABGDPRATIO", "MTBGDPRATIO"]
for at in [
"SA_3MMAv60MMA", "SA_1QMAv20QMA",
"SA_6MMA_D1M1ML6", "NSA_12MMA_D1M1ML3"
]
]
)
fxrel = [
f"{cat}_NSA_{t}"
for cat in ["REEROADJ", "CTOT"]
for t in ["P1W4WL1", "P1M1ML12", "P1M12ML1"]
] + ["PPPFXOVERVALUE_NSA_P1M12ML1"]
eq = ["EQCRR_VT10", "EQCRY_VT10", "EQCRR_NSA", "EQCRY_NSA"]
add = [
"INFTEFF_NSA",
]
eco = (
inf
+ surveys
+ flows
+ trade
+ fxrel
+ eq
+ add
)
mkt = [
"EQXR_NSA",
"EQCALLRUSD_NSA",
"FXTARGETED_NSA",
"FXUNTRADABLE_NSA",
]
xcats = eco + mkt
# Tickers for download
single_tix = ["USD_GB10YXR_NSA", "EUR_FXXR_NSA"]
tickers = [cid + "_" + xcat for cid in cids for xcat in xcats] + single_tix
# Download series from J.P. Morgan DataQuery by tickers
start_date = "1990-12-31"
end_date = (pd.Timestamp.today() - pd.offsets.BDay(1)).strftime('%Y-%m-%d')
# Retrieve credentials
oauth_id = os.getenv("DQ_CLIENT_ID") # Replace with own client ID
oauth_secret = os.getenv("DQ_CLIENT_SECRET") # Replace with own secret
# Download from DataQuery
downloader = JPMaQSDownload(client_id=oauth_id, client_secret=oauth_secret)
df = downloader.download(
tickers=tickers,
start_date=start_date,
end_date=end_date,
metrics=["value"],
suppress_warning=True,
show_progress=True,
)
dfx = df.copy()
dfx.info()
Downloading data from JPMaQS.
Timestamp UTC: 2025-09-24 09:40:10
Connection successful!
Requesting data: 100%|██████████| 38/38 [00:07<00:00, 4.93it/s]
Downloading data: 100%|██████████| 38/38 [00:24<00:00, 1.56it/s]
Some expressions are missing from the downloaded data. Check logger output for complete list.
189 out of 743 expressions are missing. To download the catalogue of all available expressions and filter the unavailable expressions, set `get_catalogue=True` in the call to `JPMaQSDownload.download()`.
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3994576 entries, 0 to 3994575
Data columns (total 4 columns):
# Column Dtype
--- ------ -----
0 real_date datetime64[ns]
1 cid object
2 xcat object
3 value float64
dtypes: datetime64[ns](1), float64(1), object(2)
memory usage: 121.9+ MB
Renaming, availability and blacklisting #
# Removing Australia and New Zealand CPI multiple transformation frequencies - maintaining monthly version now
dfx = dfx.loc[
~(
(dfx["cid"].isin(["AUD", "NZD"])) & (dfx["xcat"].isin(inf)) & (dfx["xcat"].str.contains("Q"))
)
]
Renaming quarterly categories #
dict_repl = {
"CPIC_SJA_P1Q1QL1AR": "CPIC_SJA_P3M3ML3AR",
"CPIC_SJA_P2Q2QL2AR": "CPIC_SJA_P6M6ML6AR",
"CPIC_SA_P1Q1QL4": "CPIC_SA_P1M1ML12",
"CPIH_SJA_P1Q1QL1AR": "CPIH_SJA_P3M3ML3AR",
"CPIH_SJA_P2Q2QL2AR": "CPIH_SJA_P6M6ML6AR",
"CPIH_SA_P1Q1QL4": "CPIH_SA_P1M1ML12",
"CCSCORE_SA_D1Q1QL1": "CCSCORE_SA_D3M3ML3",
"MBCSCORE_SA_D1Q1QL1": "MBCSCORE_SA_D3M3ML3",
"CCSCORE_SA_D1Q1QL4": "CCSCORE_SA_D1M1ML12",
"MBCSCORE_SA_D1Q1QL4": "MBCSCORE_SA_D1M1ML12",
"CABGDPRATIO_SA_1QMAv20QMA": "CABGDPRATIO_SA_3MMAv60MMA",
"MTBGDPRATIO_SA_1QMAv20QMA": "MTBGDPRATIO_SA_3MMAv60MMA",
}
dfx["xcat2"] = dfx["xcat"].map(dict_repl).fillna(dfx["xcat"])
dfx = dfx.drop(columns="xcat").rename(columns={"xcat2": "xcat"})
Check availability #
xcatx = sorted(list(set(inf) - set(dict_repl.keys())))
msm.check_availability(df=dfx, xcats=xcatx, cids=cids_eq, missing_recent=False)

xcatx = sorted(list(set(surveys) - set(dict_repl.keys())))
msm.check_availability(df=dfx, xcats=xcatx, cids=cids_eq, missing_recent=False)

xcatx = sorted(list(set(trade) - set(dict_repl.keys())))
msm.check_availability(df=dfx, xcats=xcatx, cids=cids_eq, missing_recent=False)

xcatx = sorted(list(set(eq) - set(dict_repl.keys())))
msm.check_availability(df=dfx, xcats=xcatx, cids=cids_eq, missing_recent=False)

xcatx = sorted(list(set(mkt) - set(dict_repl.keys())))
msm.check_availability(df=dfx, xcats=xcatx, cids=cids_eq, missing_recent=False)

Blacklisting dictionary for empirical research #
# At present no blacklisting for cash equity
equsdblack={}
Equity returns #
cidx = cids_eq
xcatx = ["EQCALLRUSD_NSA"]
start_date = "1995-01-01"
dfa = msp.make_relative_value(
dfx,
xcats=xcatx,
cids=cidx,
start=start_date,
blacklist=equsdblack, # Using the FX Blacklisting for returns in USD
rel_meth="subtract",
complete_cross=False,
postfix="vGLB",
)
dfx = msm.update_df(dfx, dfa)
Factor construction and checks #
# Initiate category dictionary for thematic factors
dict_facts = {}
# Initiate labeling dictionary
dict_lab = {}
Auxiliary categories #
# Stitching for India and China: extending core with corresponding headline
cidx = ["INR", "CNY"]
merging_xcatx = {
"CPIC_SA_P1M1ML12": ["CPIC_SA_P1M1ML12", "CPIH_SA_P1M1ML12"],
}
for new_cat, xcatx in merging_xcatx.items():
dfa = msm.merge_categories(df=dfx, xcats=xcatx, new_xcat=new_cat, cids=cidx)
dfx = msm.update_df(dfx, dfa)
Relative real equity carry #
# Real index carry versions
xcatx = ["CPIH_SA_P1M1ML12", "CPIC_SA_P1M1ML12", "PPIH_NSA_P1M1ML12"]
cidx = cids_eq
calcs = [
"EQCRR_CPIH = EQCRY_NSA + CPIH_SA_P1M1ML12",
"EQCRR_CPIC = EQCRY_NSA + CPIC_SA_P1M1ML12",
"EQCRR_PPIH = EQCRY_NSA + PPIH_NSA_P1M1ML12",
]
dfa = msp.panel_calculator(dfx, calcs=calcs, cids=cidx)
dfx = msm.update_df(dfx, dfa)
ecrr = ["EQCRR_NSA", "EQCRR_CPIH", "EQCRR_CPIC", "EQCRR_PPIH"]
# Relative value scores
xcatx = ecrr
cidx = cids_eq
start_date = "1995-01-01"
dfa = msp.make_relative_value(
dfx,
xcats=xcatx,
cids=cidx,
start=start_date,
blacklist=equsdblack,
rel_meth="subtract",
complete_cross=False,
postfix="vGLB",
)
dfx = msm.update_df(dfx, dfa)
for xcat in xcatx:
dfa = msp.make_zn_scores(
dfx,
xcat=xcat+"vGLB",
cids=cidx,
sequential=True,
min_obs=261 * 3,
neutral="zero",
pan_weight=1,
thresh=3,
postfix="_ZN",
est_freq="m",
)
dfx = msm.update_df(dfx, dfa)
# Conceptual relative factor score
xcatx = [xc + "vGLB_ZN" for xc in ecrr]
cidx = cids_eq
cfs = "EQCRRvGLB"
dfa = msp.linear_composite(
df=dfx,
xcats=xcatx,
cids=cids_eq,
new_xcat=cfs,
complete_xcats=False,
)
dfx= msm.update_df(dfx, dfa)
# Re-score
dfa = msp.make_zn_scores(
dfx,
xcat=cfs,
cids=cidx,
sequential=True,
min_obs=261 * 3,
neutral="zero",
pan_weight=1,
thresh=3,
postfix="_ZN",
est_freq="m",
)
dfx = msm.update_df(dfx, dfa)
dict_facts[cfs] = "Relative real equity carry"
Relative real currency weakness #
# Imputing PPP for USD. # TWD unavailable for this indicator (will only use REERs)
cidx = list(set(cids_eq) - {"USD"})
dfu = msp.linear_composite(
dfx,
xcats="PPPFXOVERVALUE_NSA_P1M12ML1",
cids=cidx,
weights=None,
complete_cids=False,
complete_xcats=False,
new_cid='USD'
)
dfx = msm.update_df(dfx, dfu)
# Define negative categories
xcatx = [
"PPPFXOVERVALUE_NSA_P1M12ML1",
"REEROADJ_NSA_P1M12ML1",
"REEROADJ_NSA_P1M1ML12",
"REEROADJ_NSA_P1W4WL1",
]
calcs = []
for xc in xcatx:
calcs.append(f"{xc}N = - {xc}")
dfa = msp.panel_calculator(dfx, calcs=calcs, cids=cids_eq)
dfx = msm.update_df(dfx, dfa)
# All constituents
fxweak = [
'PPPFXOVERVALUE_NSA_P1M12ML1N',
'REEROADJ_NSA_P1M12ML1N',
'REEROADJ_NSA_P1M1ML12N',
'REEROADJ_NSA_P1W4WL1N'
]
# Relative value scores
xcatx = fxweak
cidx = cids_eq
start_date = "1995-01-01"
dfa = msp.make_relative_value(
dfx,
xcats=xcatx,
cids=cidx,
start=start_date,
blacklist=equsdblack,
rel_meth="subtract",
complete_cross=False,
postfix="vGLB",
)
dfx = msm.update_df(dfx, dfa)
for xcat in xcatx:
dfa = msp.make_zn_scores(
dfx,
xcat=xcat+"vGLB",
cids=cidx,
sequential=True,
min_obs=261 * 3,
neutral="zero",
pan_weight=1,
thresh=3,
postfix="_ZN",
est_freq="m",
)
dfx = msm.update_df(dfx, dfa)
# Conceptual relative factor score
xcatx = [xc + "vGLB_ZN" for xc in fxweak]
cidx = cids_eq
cfs = "FXWEAKvGLB"
dfa = msp.linear_composite(
df=dfx,
xcats=xcatx,
cids=cids_eq,
new_xcat=cfs,
complete_xcats=False,
)
dfx= msm.update_df(dfx, dfa)
# Re-score
dfa = msp.make_zn_scores(
dfx,
xcat=cfs,
cids=cidx,
sequential=True,
min_obs=261 * 3,
neutral="zero",
pan_weight=1,
thresh=3,
postfix="_ZN",
est_freq="m",
)
dfx = msm.update_df(dfx, dfa)
dict_facts[cfs] = "Relative real currency weakness"
Relative terms-of-trade improvements #
# All constituents
tot = ['CTOT_NSA_P1M12ML1', 'CTOT_NSA_P1M1ML12', 'CTOT_NSA_P1W4WL1']
# Relative value scores
xcatx = tot
cidx = cids_eq
start_date = "1995-01-01"
dfa = msp.make_relative_value(
dfx,
xcats=xcatx,
cids=cidx,
start=start_date,
blacklist=equsdblack,
rel_meth="subtract",
complete_cross=False,
postfix="vGLB",
)
dfx = msm.update_df(dfx, dfa)
for xcat in xcatx:
dfa = msp.make_zn_scores(
dfx,
xcat=xcat+"vGLB",
cids=cidx,
sequential=True,
min_obs=261 * 3,
neutral="zero",
pan_weight=1,
thresh=3,
postfix="_ZN",
est_freq="m",
)
dfx = msm.update_df(dfx, dfa)
# Conceptual relative factor score
xcatx = [xc + "vGLB_ZN" for xc in tot]
cidx = cids_eq
cfs = "TOTDvGLB"
dfa = msp.linear_composite(
df=dfx,
xcats=xcatx,
cids=cids_eq,
new_xcat=cfs,
complete_xcats=False,
)
dfx= msm.update_df(dfx, dfa)
# Re-score
dfa = msp.make_zn_scores(
dfx,
xcat=cfs,
cids=cidx,
sequential=True,
min_obs=261 * 3,
neutral="zero",
pan_weight=1,
thresh=3,
postfix="_ZN",
est_freq="m",
)
dfx = msm.update_df(dfx, dfa)
dict_facts[cfs] = "Relative terms-of-trade improvement"
Relative external balances strength #
# All constituents
xbal = [
'MTBGDPRATIO_SA_3MMAv60MMA',
'CABGDPRATIO_SA_3MMAv60MMA',
'MTBGDPRATIO_NSA_12MMA_D1M1ML3',
'MTBGDPRATIO_SA_6MMA_D1M1ML6'
]
# Relative value scores
xcatx = xbal
cidx = cids_eq
start_date = "1995-01-01"
dfa = msp.make_relative_value(
dfx,
xcats=xcatx,
cids=cidx,
start=start_date,
blacklist=equsdblack,
rel_meth="subtract",
complete_cross=False,
postfix="vGLB",
)
dfx = msm.update_df(dfx, dfa)
for xcat in xcatx:
dfa = msp.make_zn_scores(
dfx,
xcat=xcat+"vGLB",
cids=cidx,
sequential=True,
min_obs=261 * 3,
neutral="zero",
pan_weight=1,
thresh=3,
postfix="_ZN",
est_freq="m",
)
dfx = msm.update_df(dfx, dfa)
# Conceptual relative factor score
xcatx = [xc + "vGLB_ZN" for xc in xbal]
cidx = cids_eq
cfs = "XBSvGLB"
dfa = msp.linear_composite(
df=dfx,
xcats=xcatx,
cids=cids_eq,
new_xcat=cfs,
complete_xcats=False,
)
dfx= msm.update_df(dfx, dfa)
# Re-score
dfa = msp.make_zn_scores(
dfx,
xcat=cfs,
cids=cidx,
sequential=True,
min_obs=261 * 3,
neutral="zero",
pan_weight=1,
thresh=3,
postfix="_ZN",
est_freq="m",
)
dfx = msm.update_df(dfx, dfa)
dict_facts[cfs] = "Relative external balances strength"
Relative investment position improvements #
# Change a sign
calcs = ["IIPLIABGDP_NSA_D1M1ML12N = - IIPLIABGDP_NSA_D1M1ML12"]
dfa = msp.panel_calculator(dfx, calcs=calcs, cids=cids_eq)
dfx = msm.update_df(dfx, dfa)
# All constituents
iip = [
'IIPLIABGDP_NSA_D1M1ML12N',
'NIIPGDP_NSA_D1M1ML12',
]
# Relative value scores
xcatx = iip
cidx = cids_eq
start_date = "1995-01-01"
dfa = msp.make_relative_value(
dfx,
xcats=xcatx,
cids=cidx,
start=start_date,
blacklist=equsdblack,
rel_meth="subtract",
complete_cross=False,
postfix="vGLB",
)
dfx = msm.update_df(dfx, dfa)
for xcat in xcatx:
dfa = msp.make_zn_scores(
dfx,
xcat=xcat+"vGLB",
cids=cidx,
sequential=True,
min_obs=261 * 3,
neutral="zero",
pan_weight=1,
thresh=3,
postfix="_ZN",
est_freq="m",
)
dfx = msm.update_df(dfx, dfa)
# Conceptual relative factor score
xcatx = [xc + "vGLB_ZN" for xc in iip]
cidx = cids_eq
cfs = "IIPDvGLB"
dfa = msp.linear_composite(
df=dfx,
xcats=xcatx,
cids=cids_eq,
new_xcat=cfs,
complete_xcats=False,
)
dfx= msm.update_df(dfx, dfa)
# Re-score
dfa = msp.make_zn_scores(
dfx,
xcat=cfs,
cids=cidx,
sequential=True,
min_obs=261 * 3,
neutral="zero",
pan_weight=1,
thresh=3,
postfix="_ZN",
est_freq="m",
)
dfx = msm.update_df(dfx, dfa)
dict_facts[cfs] = "Relative investment position improvement"
Relative confidence improvement #
# All constituents
conf = [
'MBCSCORE_SA_D3M3ML3', 'MBCSCORE_SA_D1M1ML12',
'CCSCORE_SA_D3M3ML3', 'CCSCORE_SA_D1M1ML12',
]
# Relative value scores
xcatx = conf
cidx = cids_eq
start_date = "1995-01-01"
dfa = msp.make_relative_value(
dfx,
xcats=xcatx,
cids=cidx,
start=start_date,
blacklist=equsdblack,
rel_meth="subtract",
complete_cross=False,
postfix="vGLB",
)
dfx = msm.update_df(dfx, dfa)
for xcat in xcatx:
dfa = msp.make_zn_scores(
dfx,
xcat=xcat+"vGLB",
cids=cidx,
sequential=True,
min_obs=261 * 3,
neutral="zero",
pan_weight=1,
thresh=3,
postfix="_ZN",
est_freq="m",
)
dfx = msm.update_df(dfx, dfa)
# Conceptual relative factor score
xcatx = [xc + "vGLB_ZN" for xc in conf]
cidx = cids_eq
cfs = "CONDvGLB"
dfa = msp.linear_composite(
df=dfx,
xcats=xcatx,
cids=cids_eq,
new_xcat=cfs,
complete_xcats=False,
)
dfx= msm.update_df(dfx, dfa)
# Re-score
dfa = msp.make_zn_scores(
dfx,
xcat=cfs,
cids=cidx,
sequential=True,
min_obs=261 * 3,
neutral="zero",
pan_weight=1,
thresh=3,
postfix="_ZN",
est_freq="m",
)
dfx = msm.update_df(dfx, dfa)
dict_facts[cfs] = "Relative confidence improvement"
Overview visuals of all relative factors #
dict_factz = {k+"_ZN": v for k, v in dict_facts.items()}
xcatx = list(dict_factz.keys())
msm.check_availability(
df=dfx,
xcats=xcatx,
cids=cids_eq,
missing_recent=False,
start="1995-01-01",
xcat_labels=dict_factz,
)

cidx = cids_eq
xcatx = list(dict_factz.keys())
start = "1995-01-01"
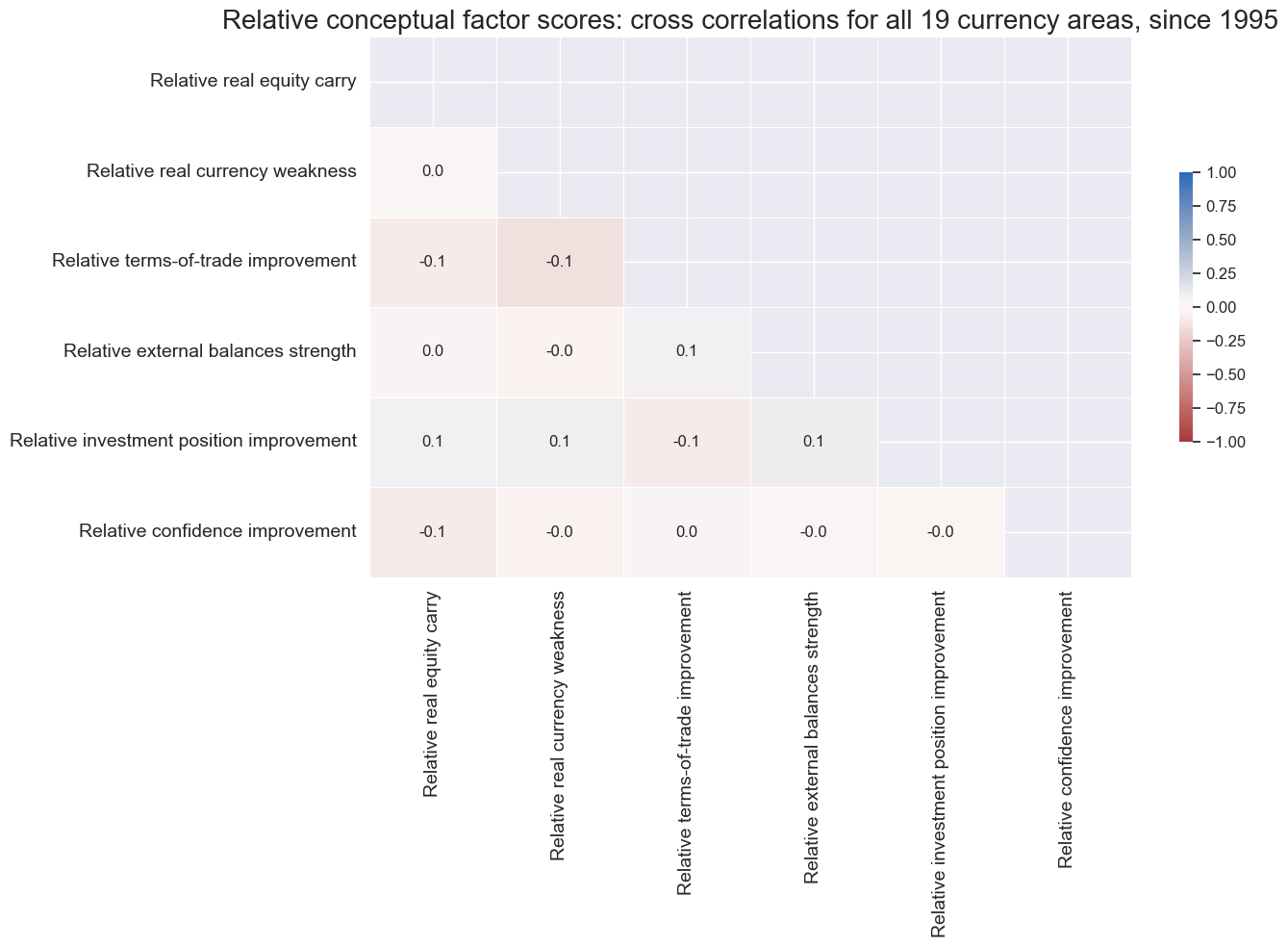
msp.correl_matrix(
dfx,
cids=cidx,
xcats=xcatx,
max_color=1.0,
annot=True,
fmt=".1f",
freq="M",
cluster=False,
title=f"Relative conceptual factor scores: cross correlations for all {str(len(cids_eq))} currency areas, since 1995",
title_fontsize=20,
xcat_labels=dict_factz,
start=start,
size=(14, 10),
)
Global condensed scorecard #
Snapshot #
xcatx = list(dict_factz.keys())
cidx = cids_eq
# Set data of snapshot
backdate = datetime.strptime("2018-09-01", "%Y-%m-%d")
lastdate = datetime.strptime(end_date, "%Y-%m-%d")
snapdate = lastdate # lastdate or backdate
sv = ScoreVisualisers(
df=dfx,
cids=cidx,
xcats = xcatx,
xcat_labels=dict_factz,
xcat_comp="Composite",
no_zn_scores=True,
rescore_composite=True,
blacklist=equsdblack,
)
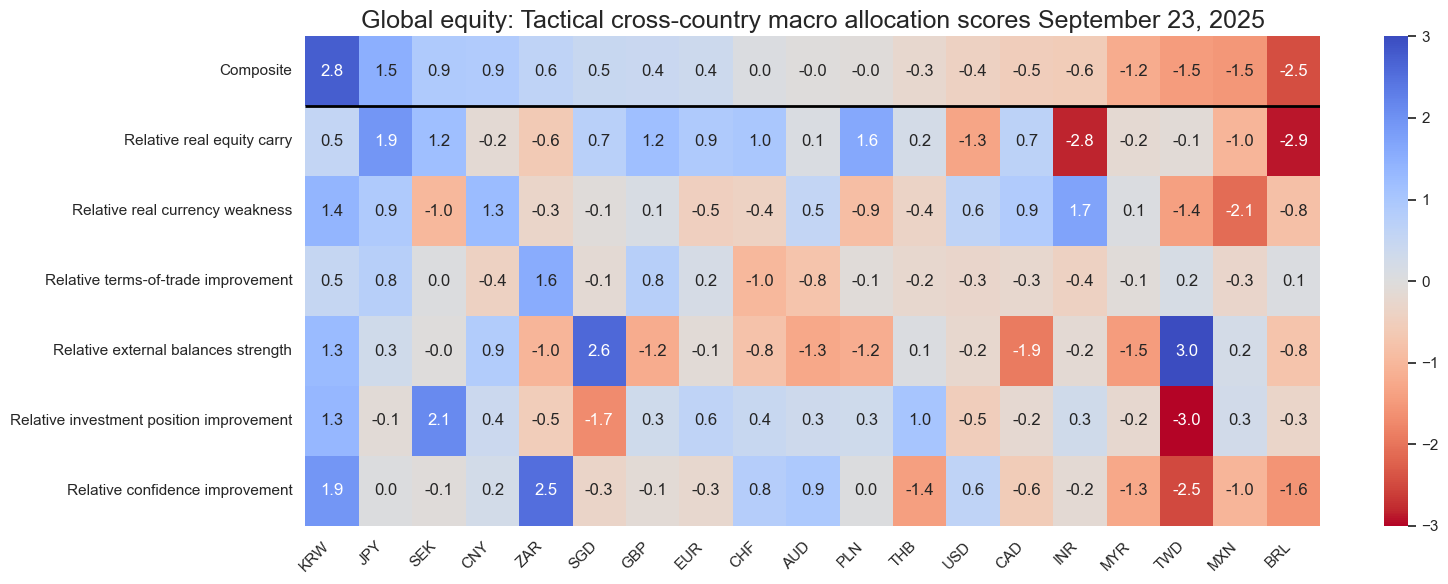
sv.view_snapshot(
cids=cidx,
date=snapdate,
transpose=True,
sort_by_composite = True,
title=f"Global equity: Tactical cross-country macro allocation scores {snapdate.strftime("%B %d, %Y")}",
title_fontsize=18,
figsize=(16, 6),
xcats=xcatx + ["Composite"],
xcat_labels=dict_factz,
round_decimals=1,
)
Global history #
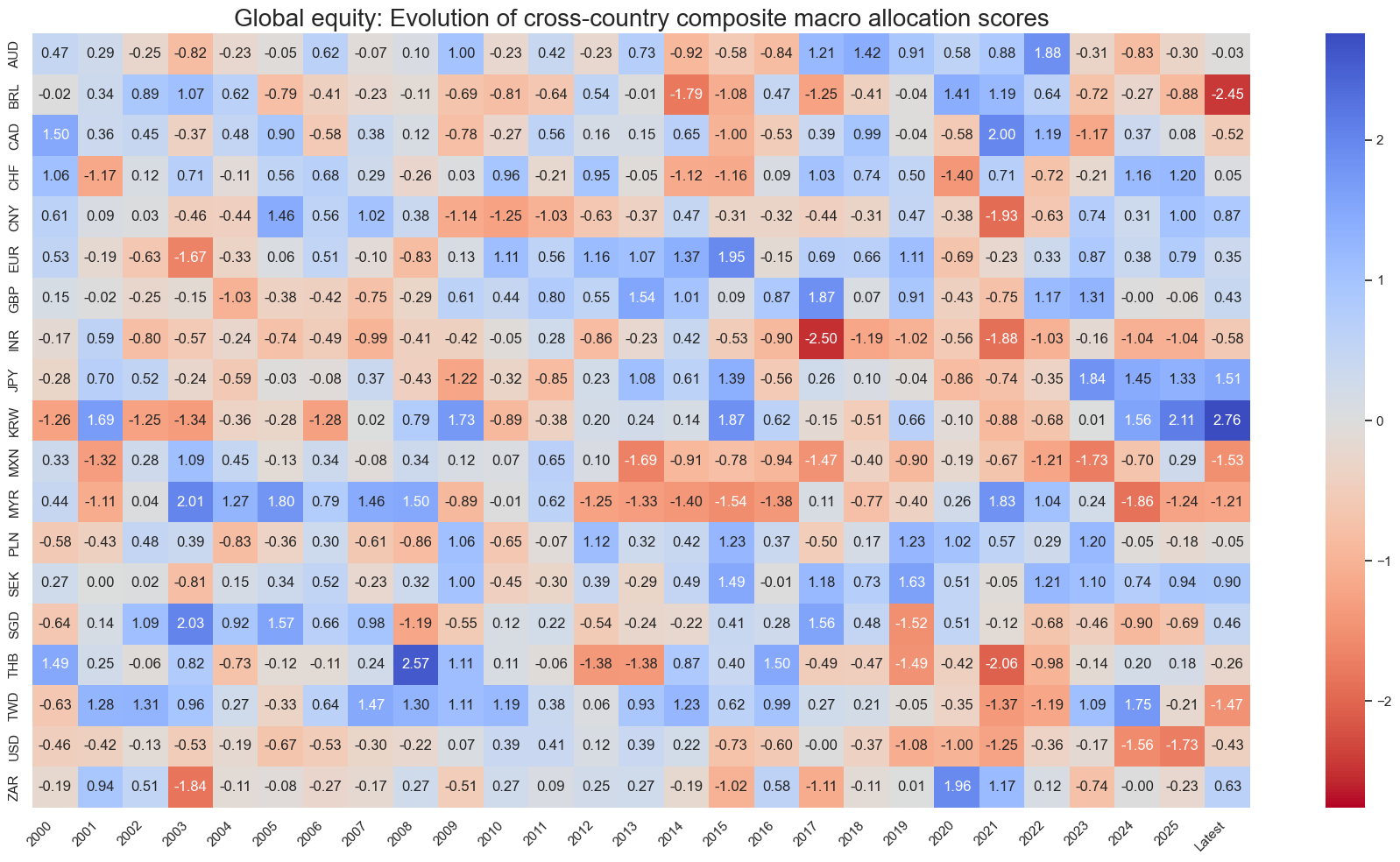
sv.view_score_evolution(
xcat="Composite",
cids=cidx,
freq="A",
include_latest_day=True,
transpose=False,
title="Global equity: Evolution of cross-country composite macro allocation scores",
start="2000-01-01",
figsize=(18, 10),
)
Latest day: 2025-09-23 00:00:00
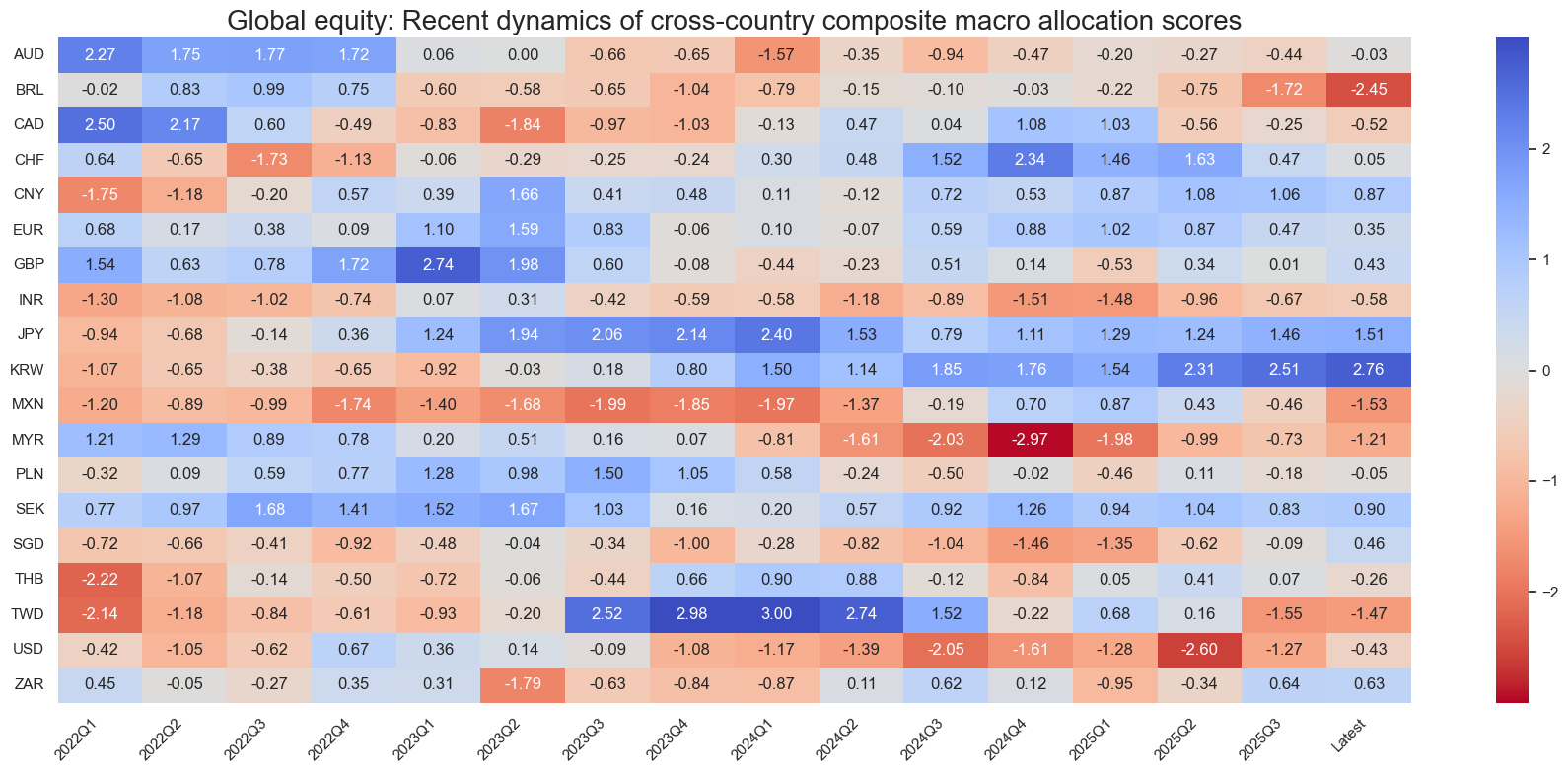
sv.view_score_evolution(
xcat="Composite",
cids=cidx,
freq="Q",
include_latest_day=True,
transpose=False,
title="Global equity: Recent dynamics of cross-country composite macro allocation scores",
start="2022-01-01",
figsize=(18, 8),
)
Latest day: 2025-09-23 00:00:00
Country history #
xcatx = list(dict_factz.keys()) + ["Composite"]
cidx = cids_eq
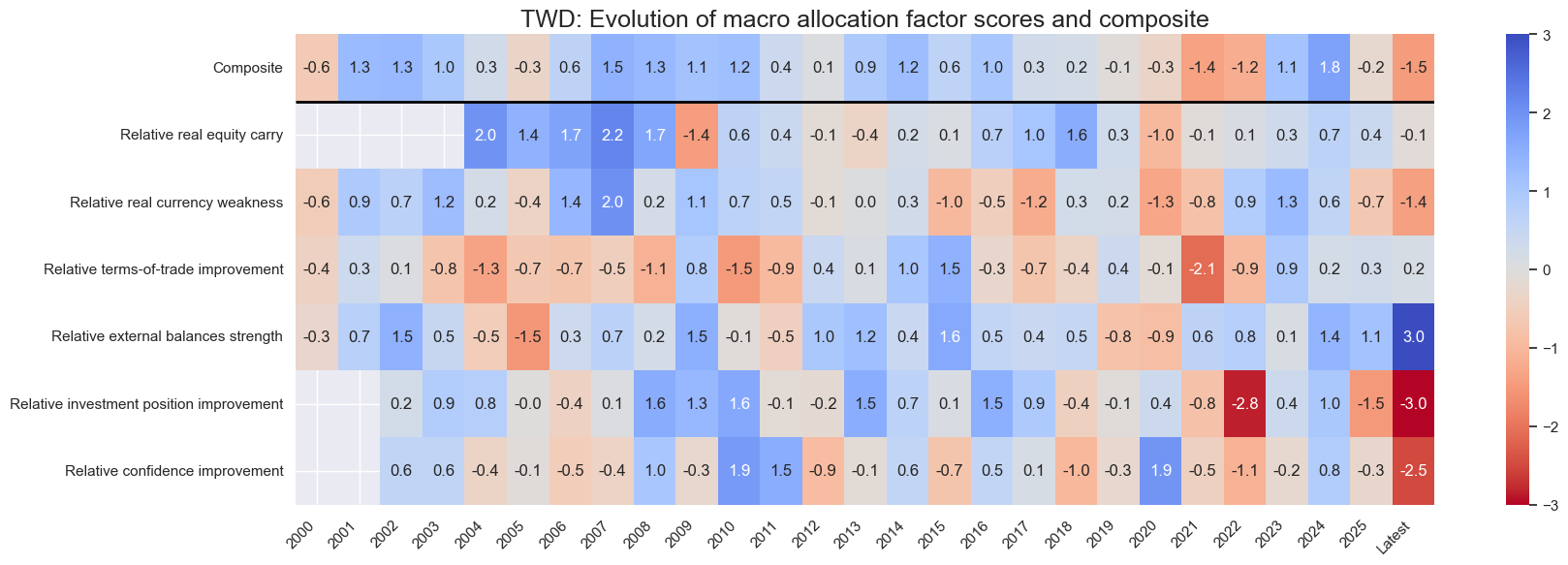
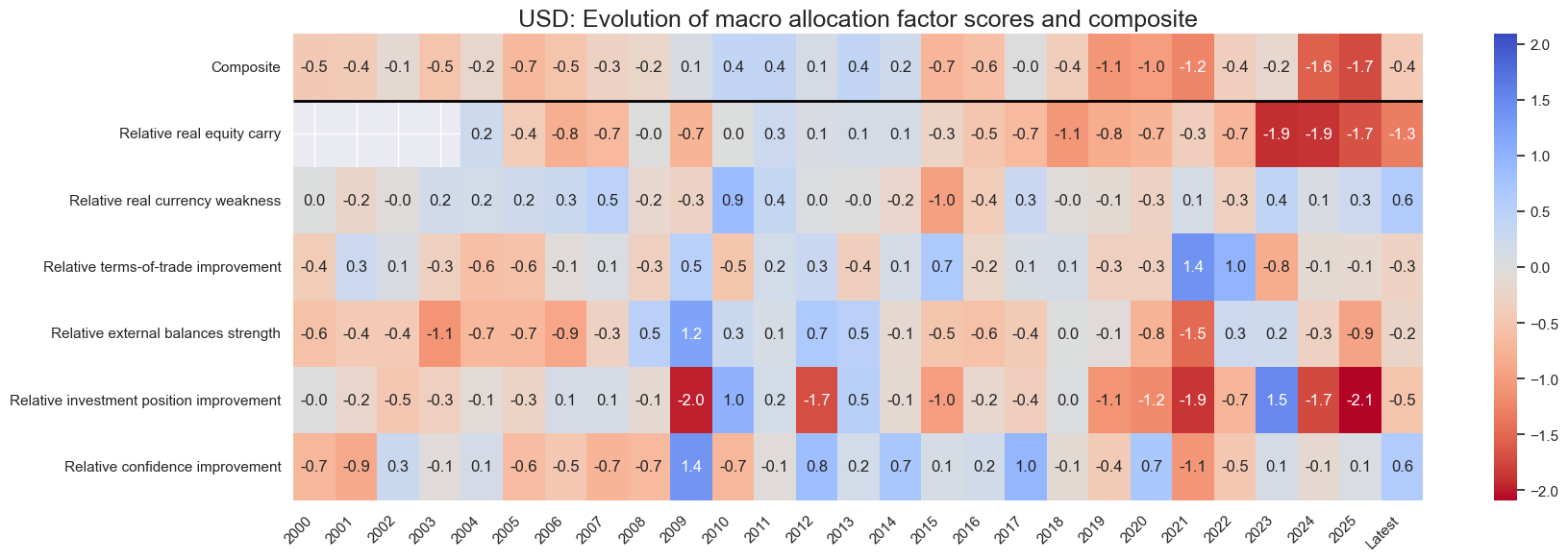
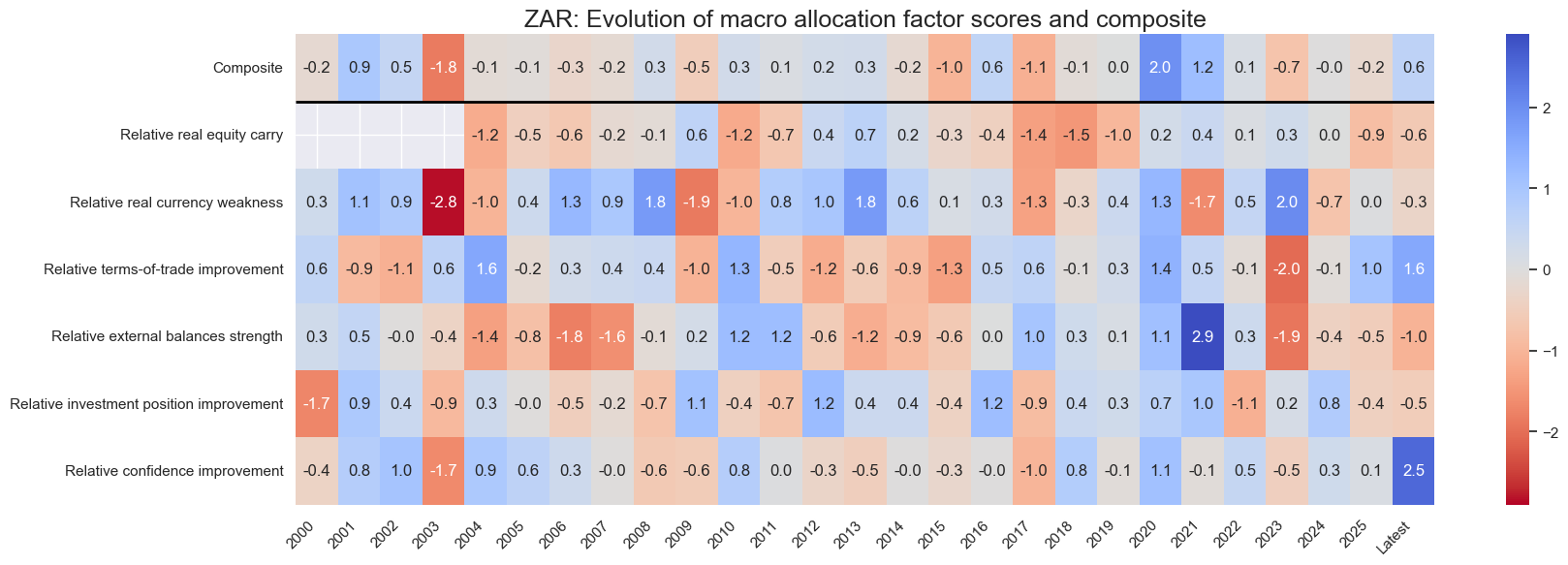
for cid in cids_eq:
sv.view_cid_evolution(
cid=cid,
xcats=xcatx,
xcat_labels=dict_lab,
freq="A",
transpose=False,
title=f"{cid}: Evolution of macro allocation factor scores and composite",
title_fontsize=18,
figsize=(18, 6),
round_decimals=1,
start="2000-01-01",
)
Latest day: 2025-09-23 00:00:00
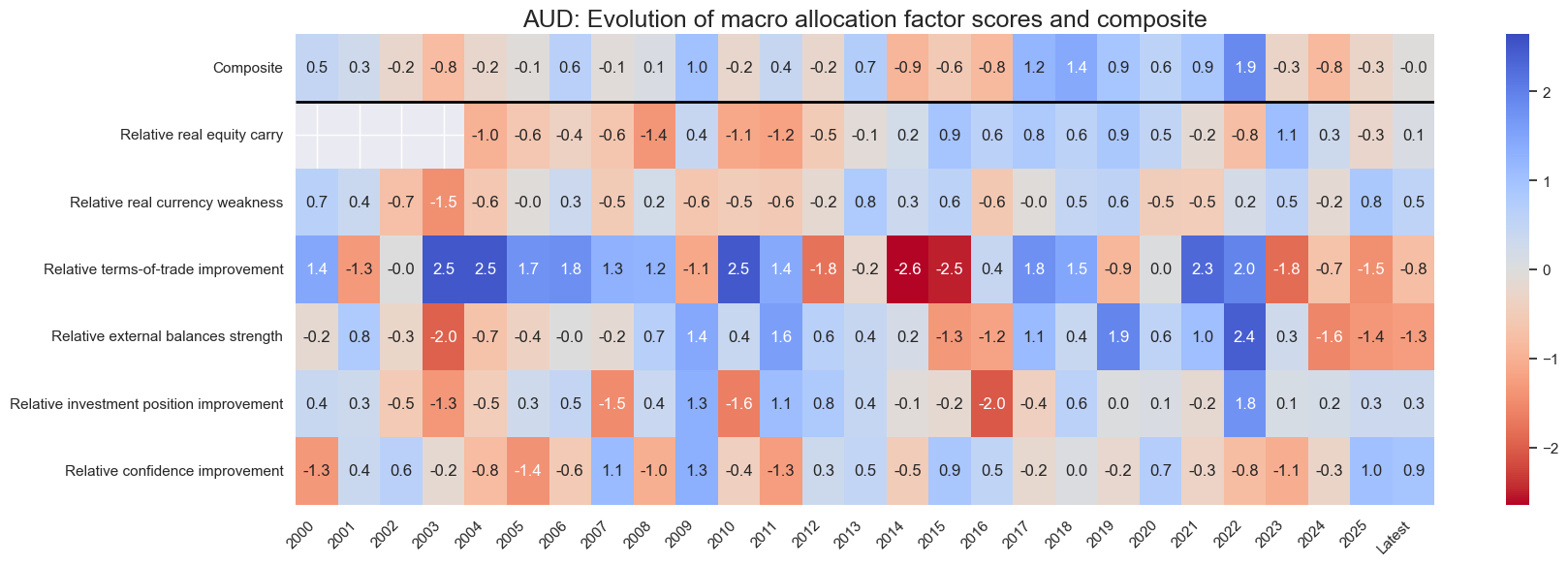
Latest day: 2025-09-23 00:00:00
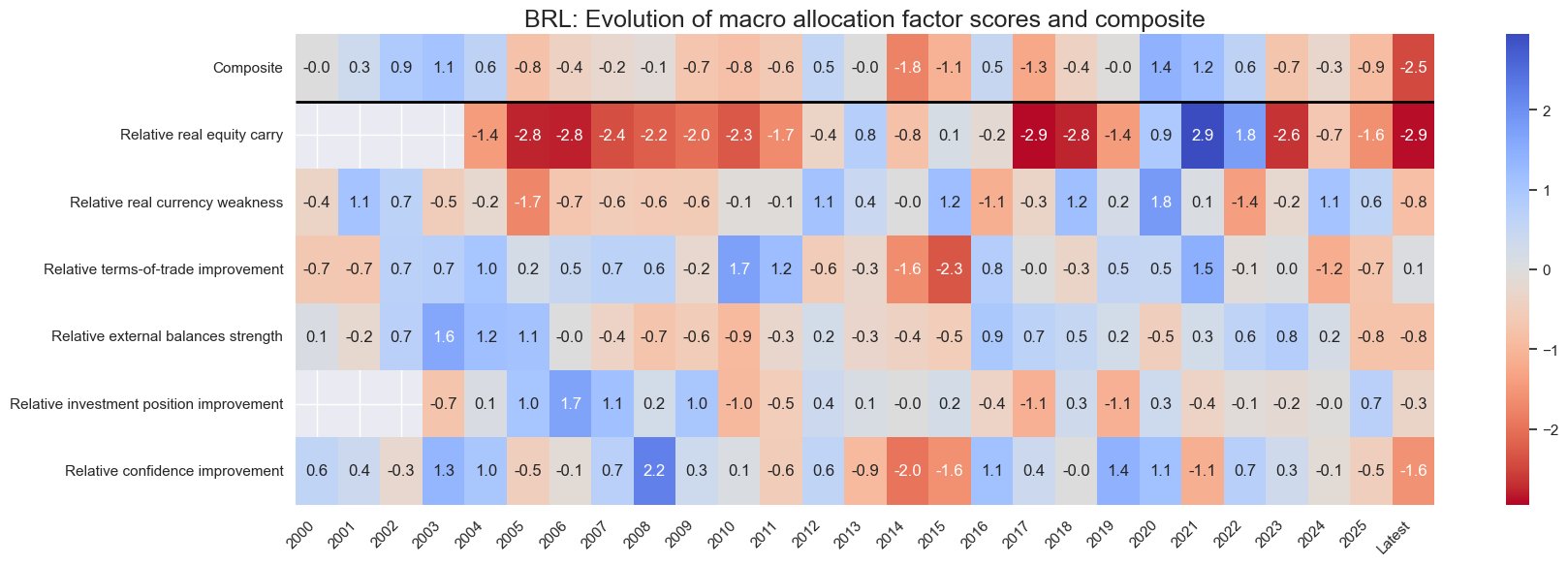
Latest day: 2025-09-23 00:00:00
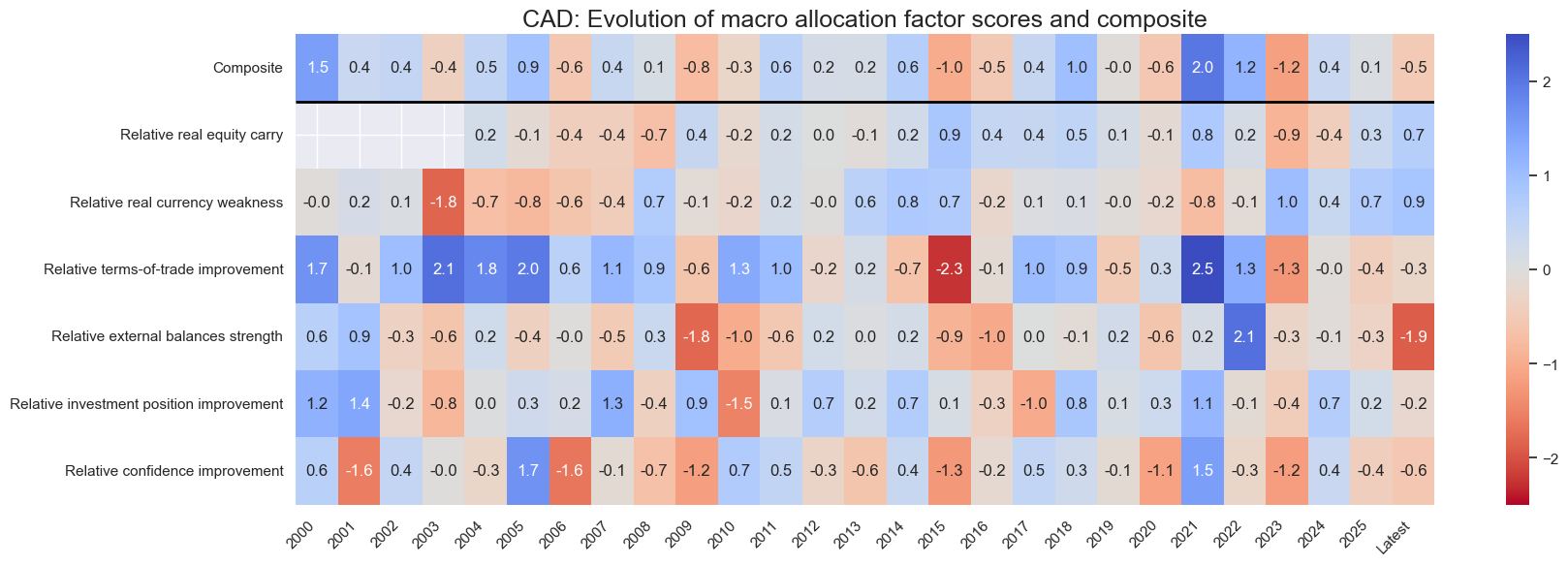
Latest day: 2025-09-23 00:00:00
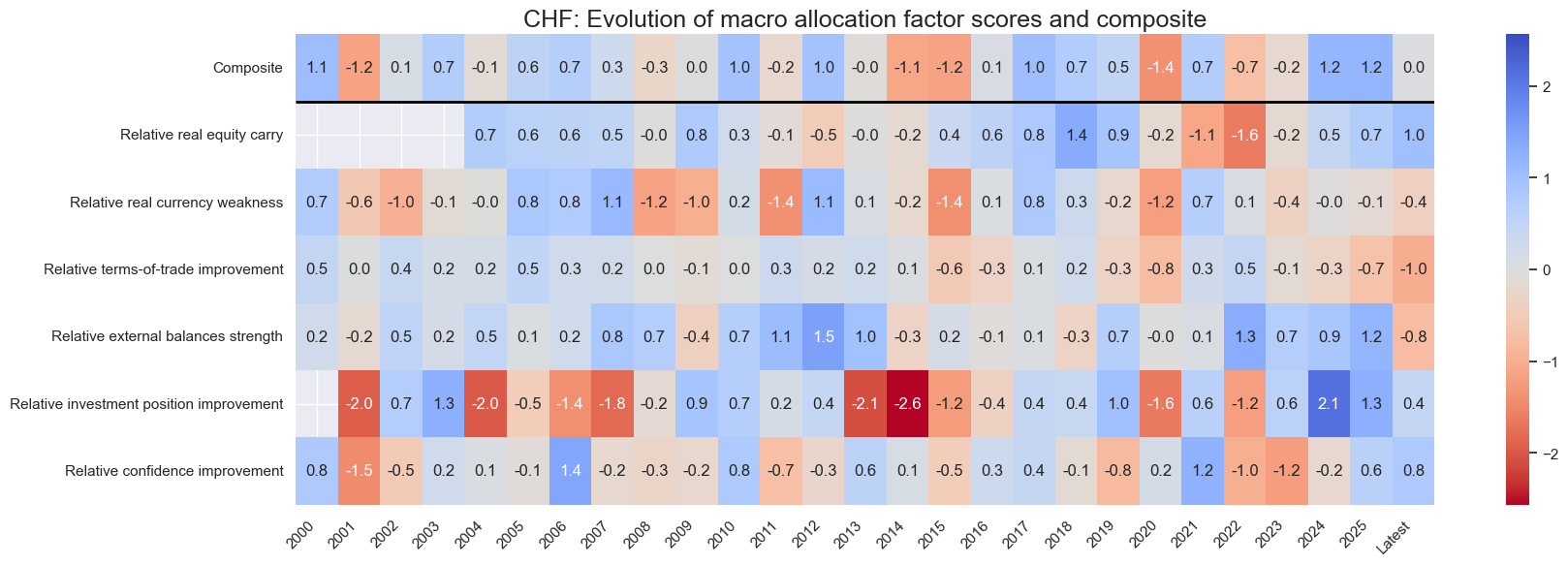
Latest day: 2025-09-23 00:00:00
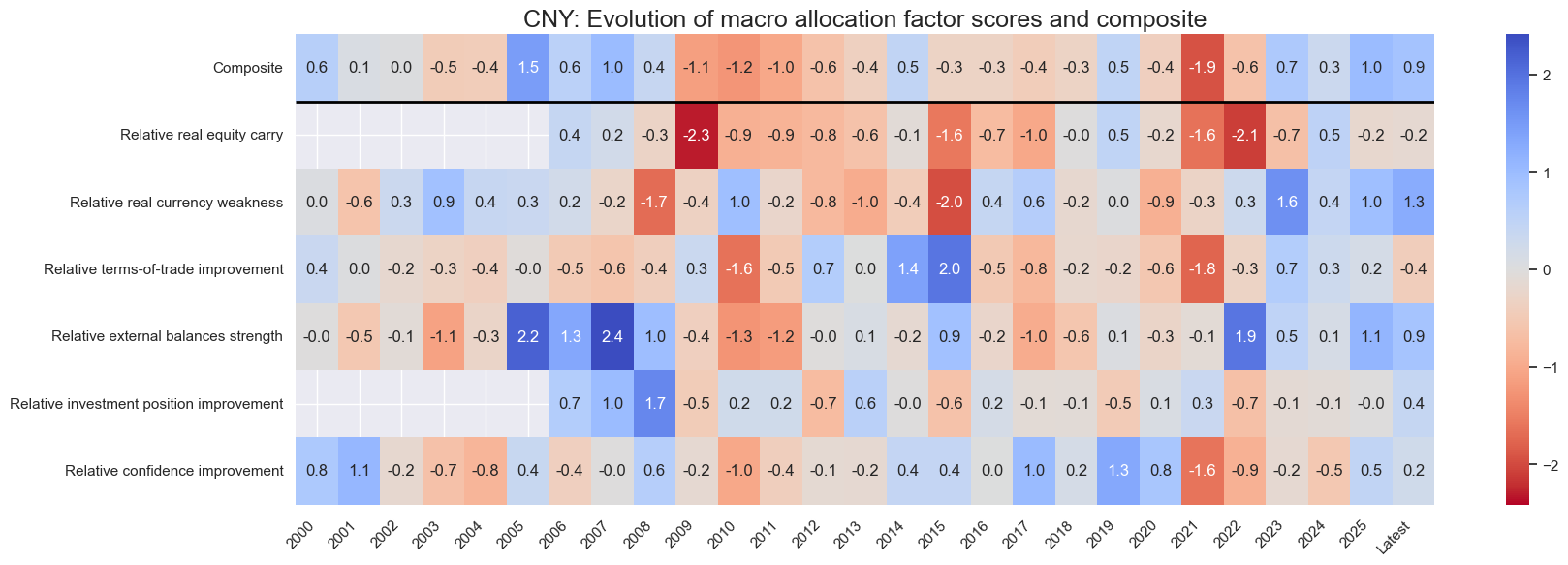
Latest day: 2025-09-23 00:00:00
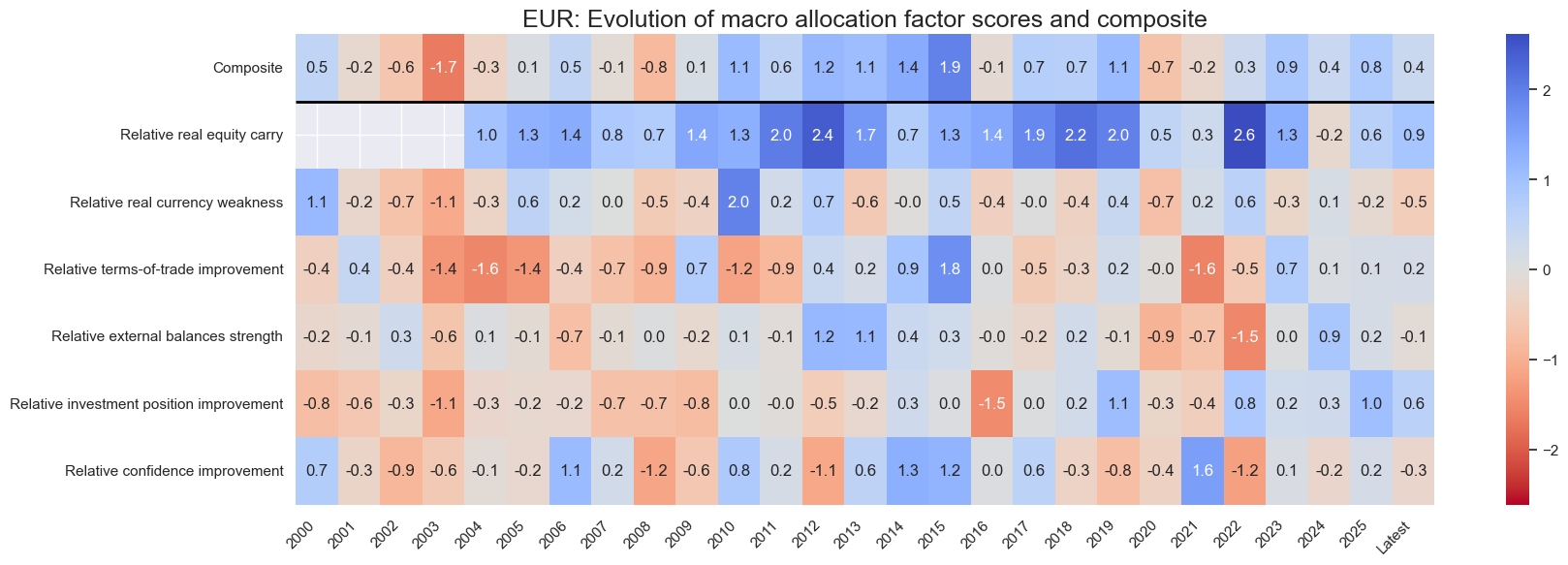
Latest day: 2025-09-23 00:00:00
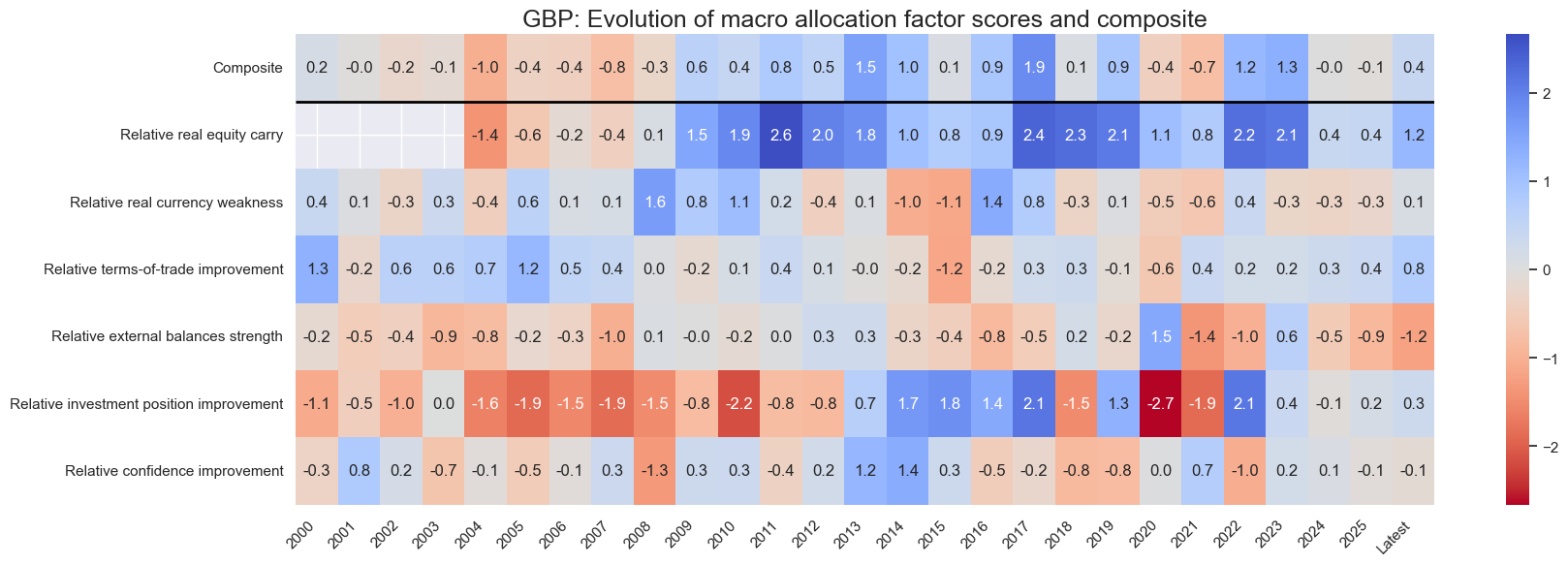
Latest day: 2025-09-23 00:00:00
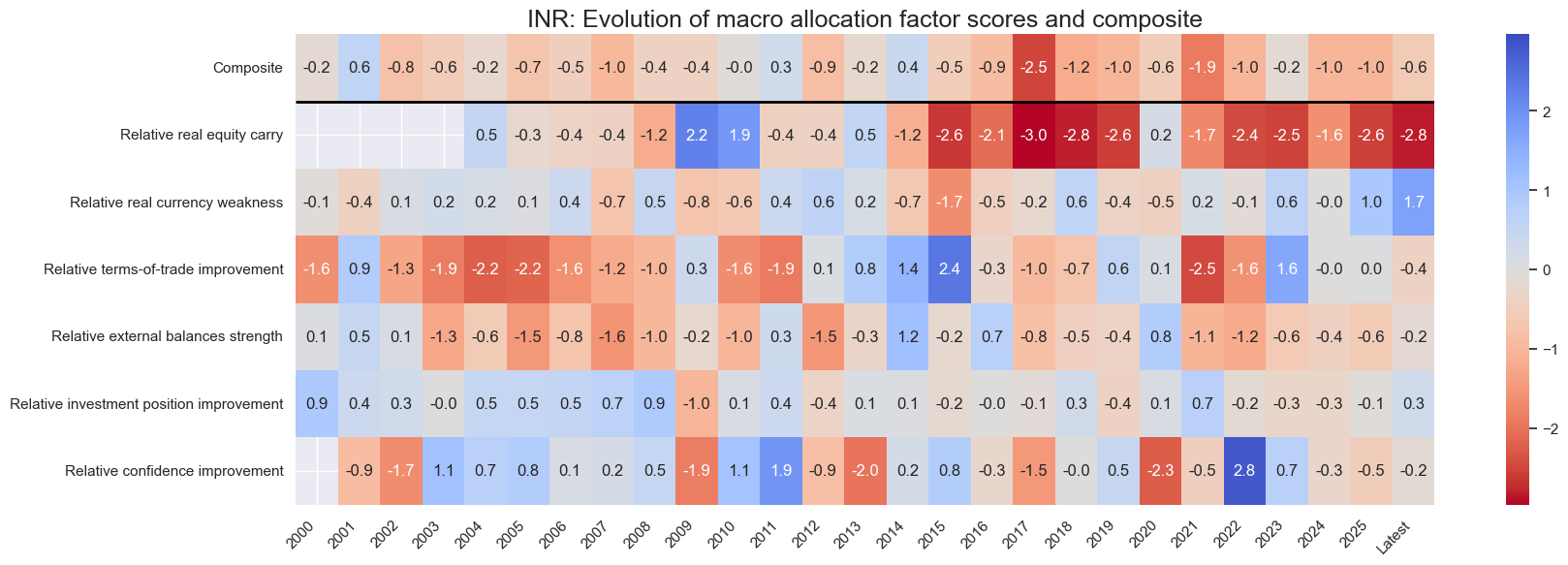
Latest day: 2025-09-23 00:00:00
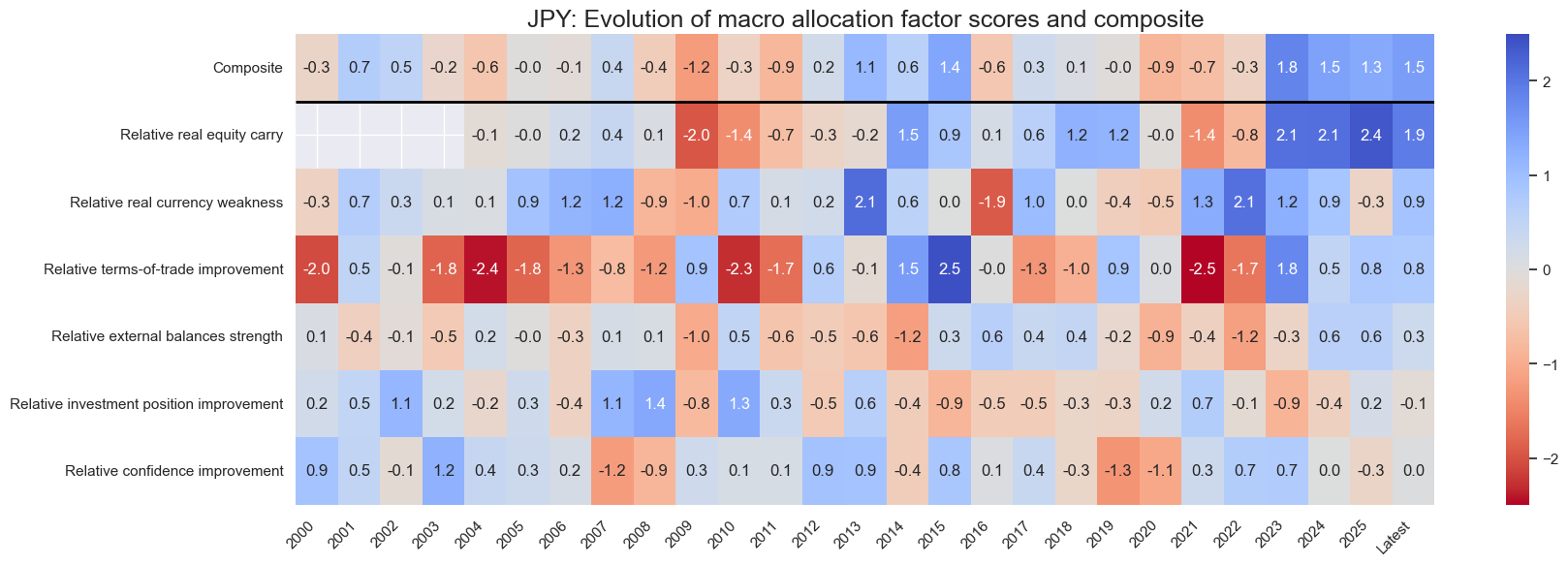
Latest day: 2025-09-23 00:00:00
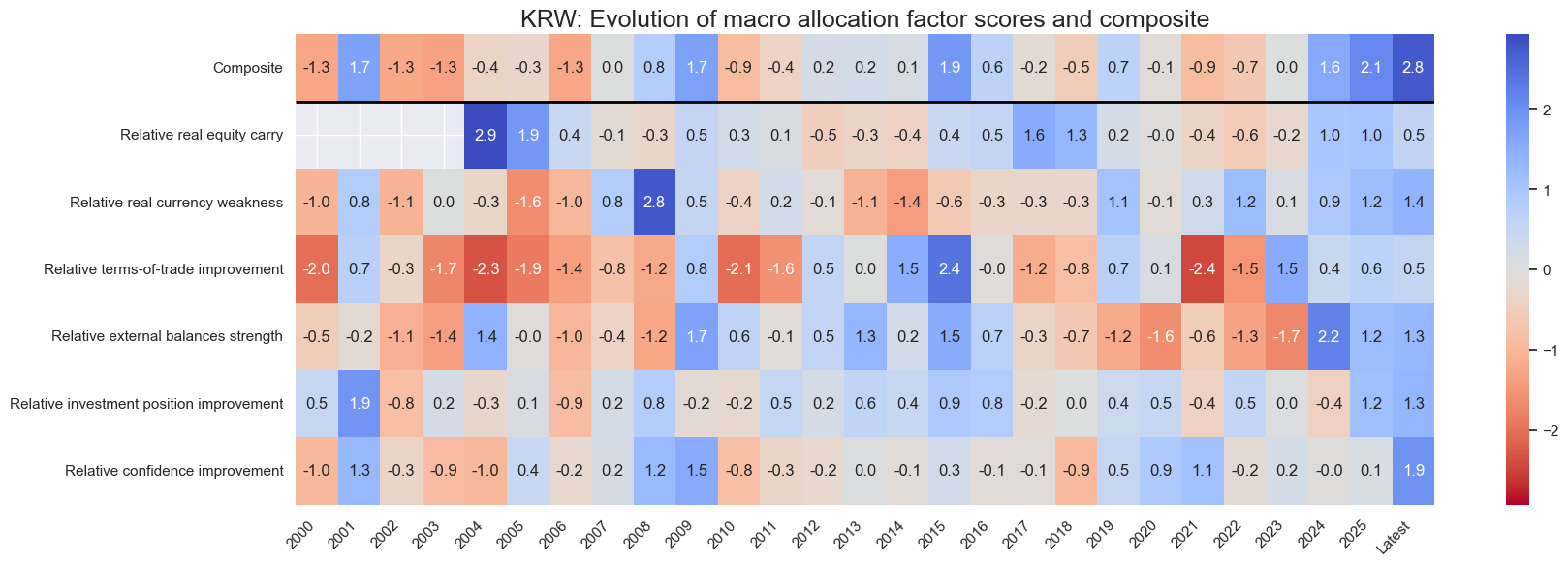
Latest day: 2025-09-23 00:00:00
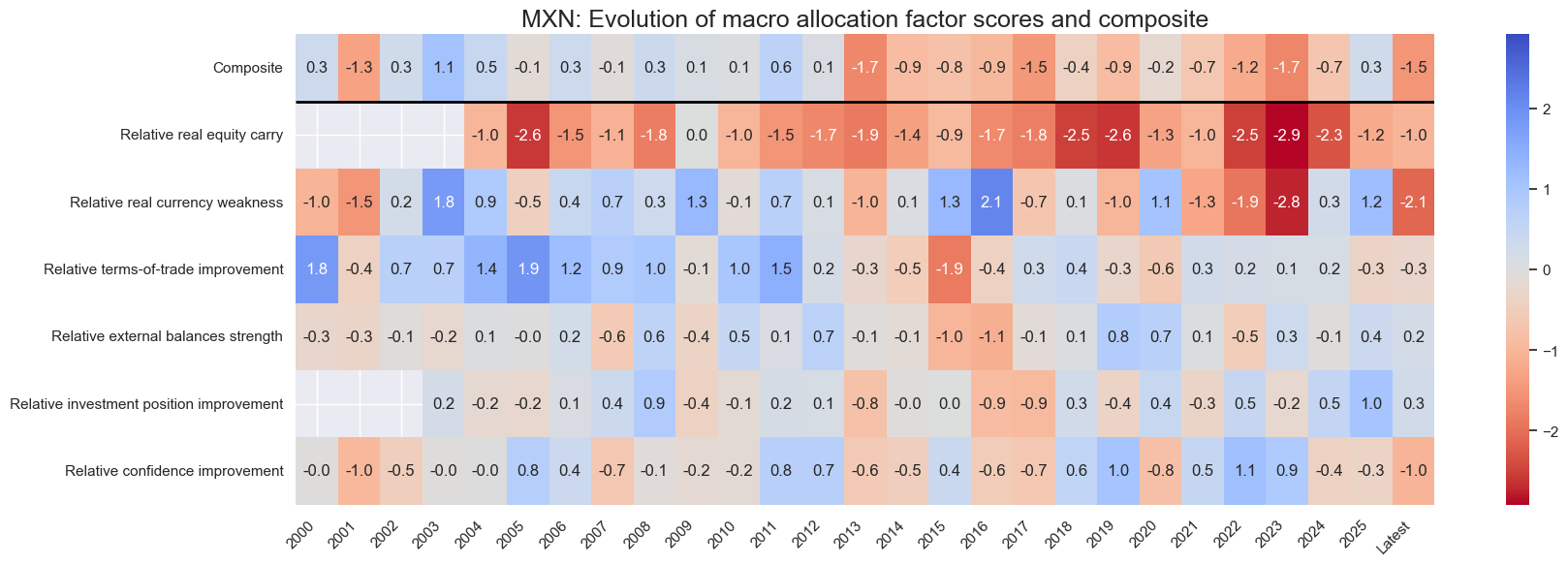
Latest day: 2025-09-23 00:00:00
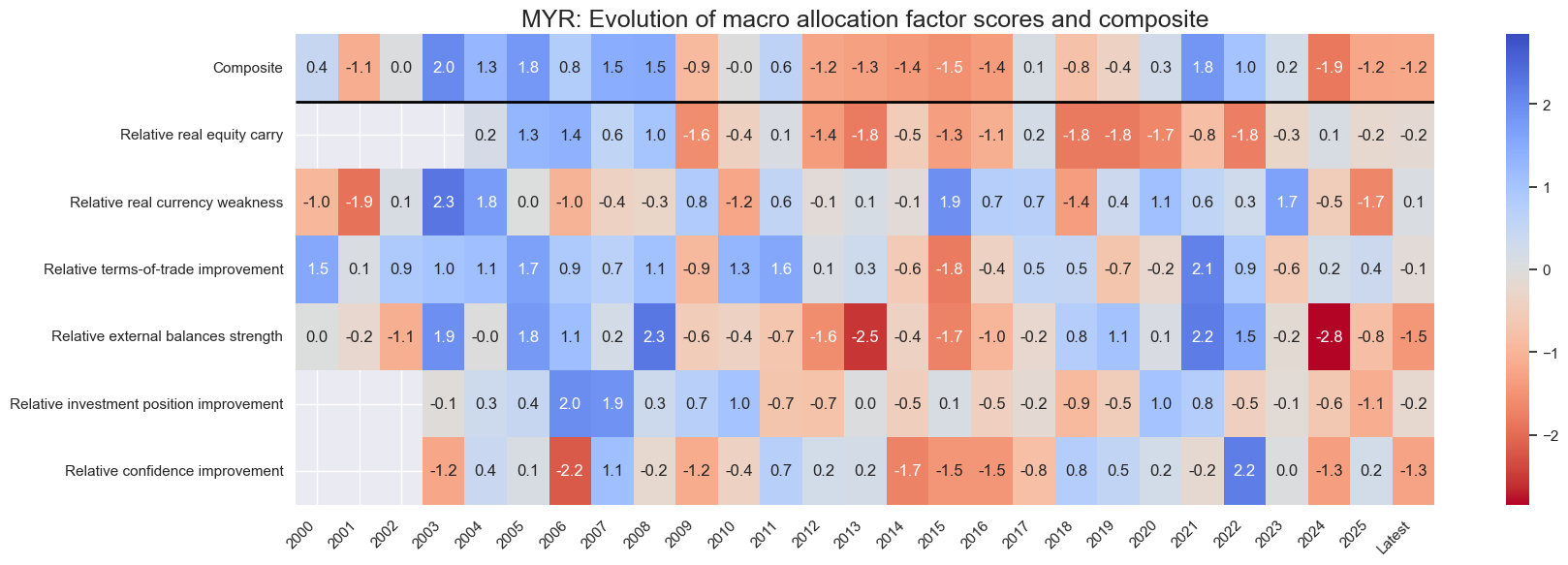
Latest day: 2025-09-23 00:00:00
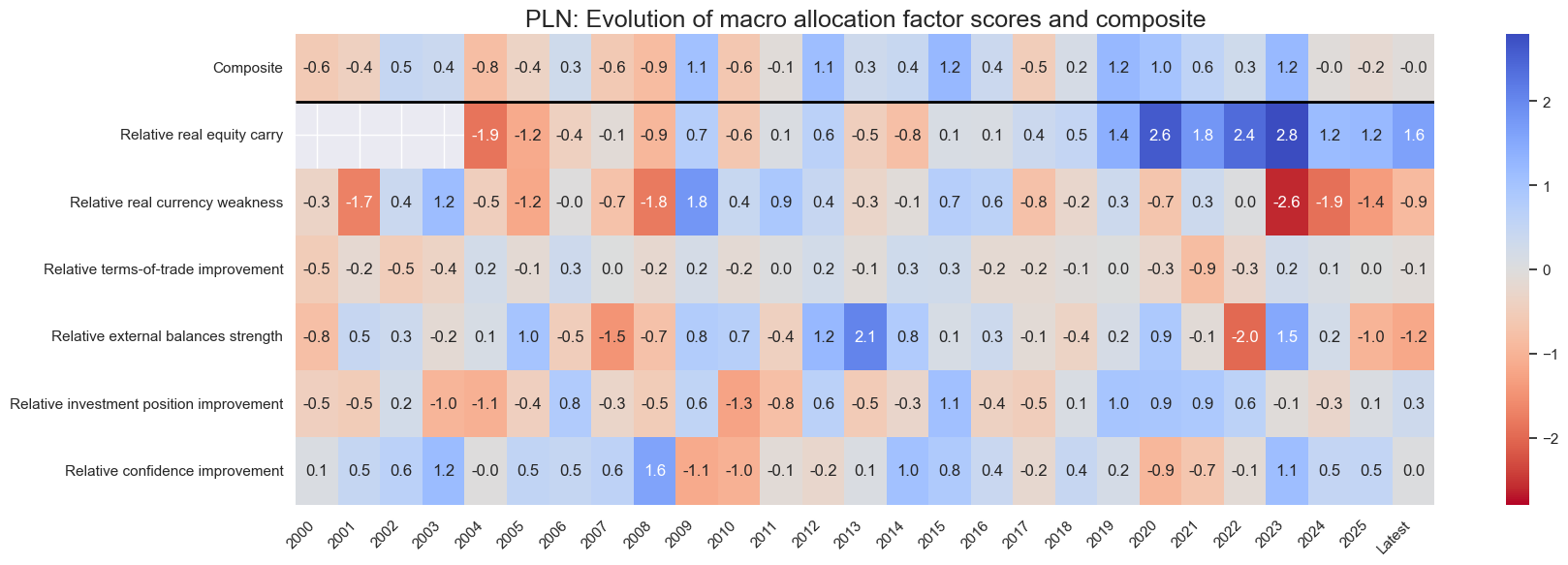
Latest day: 2025-09-23 00:00:00
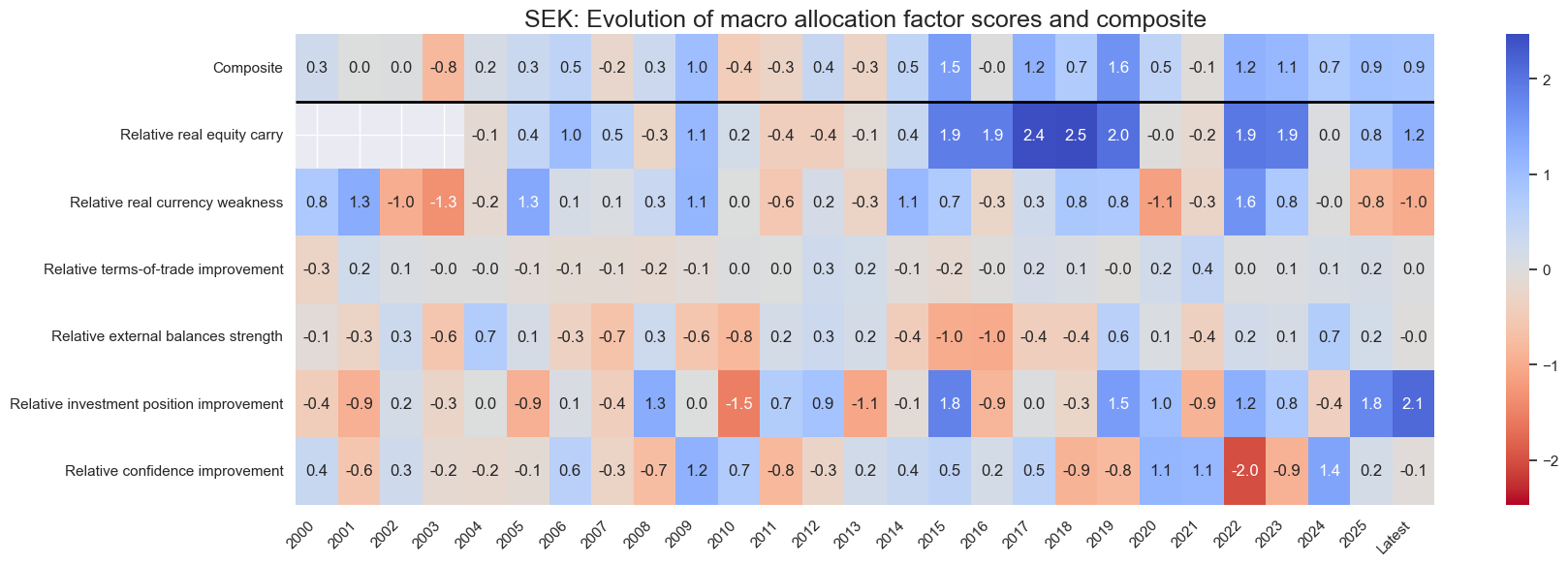
Latest day: 2025-09-23 00:00:00
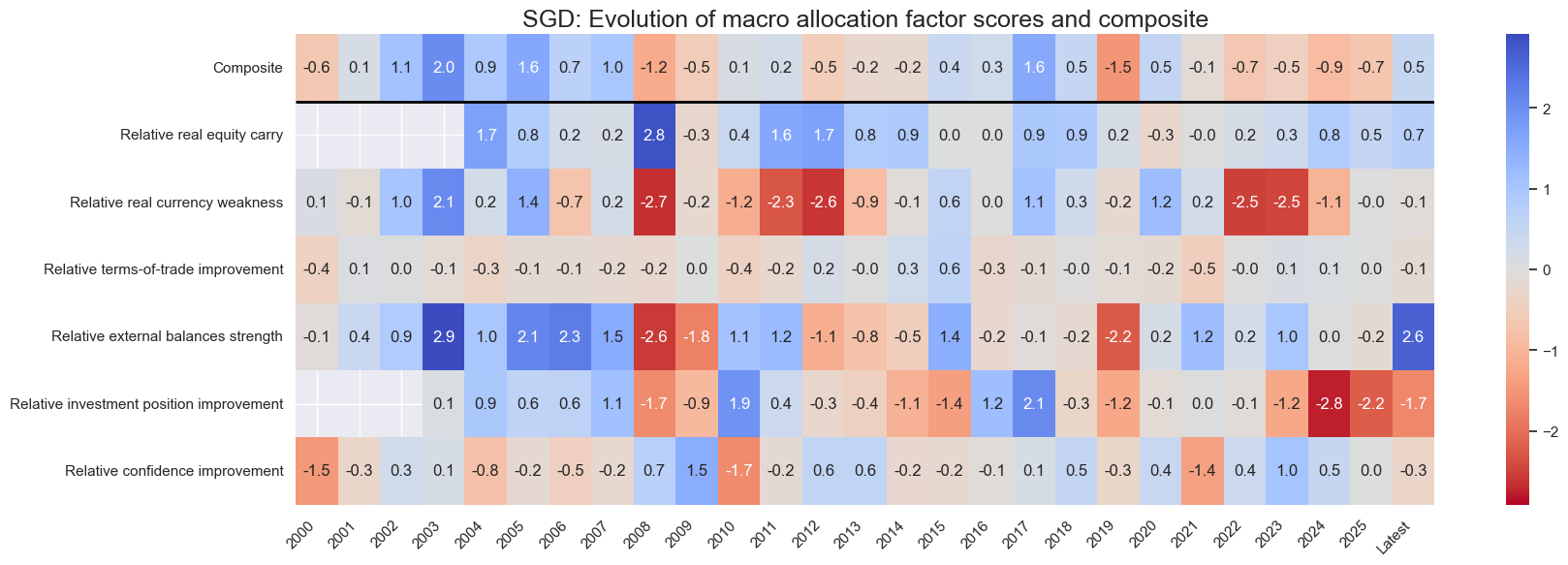
Latest day: 2025-09-23 00:00:00
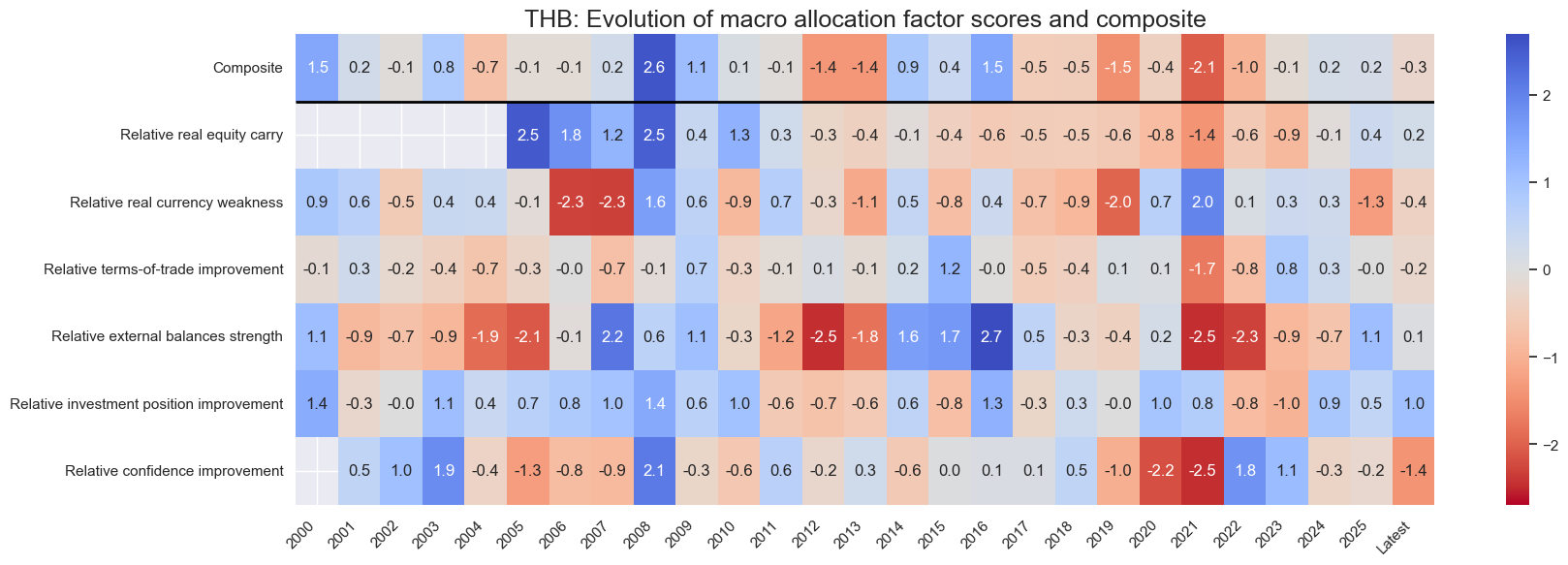
Latest day: 2025-09-23 00:00:00
Latest day: 2025-09-23 00:00:00
Latest day: 2025-09-23 00:00:00
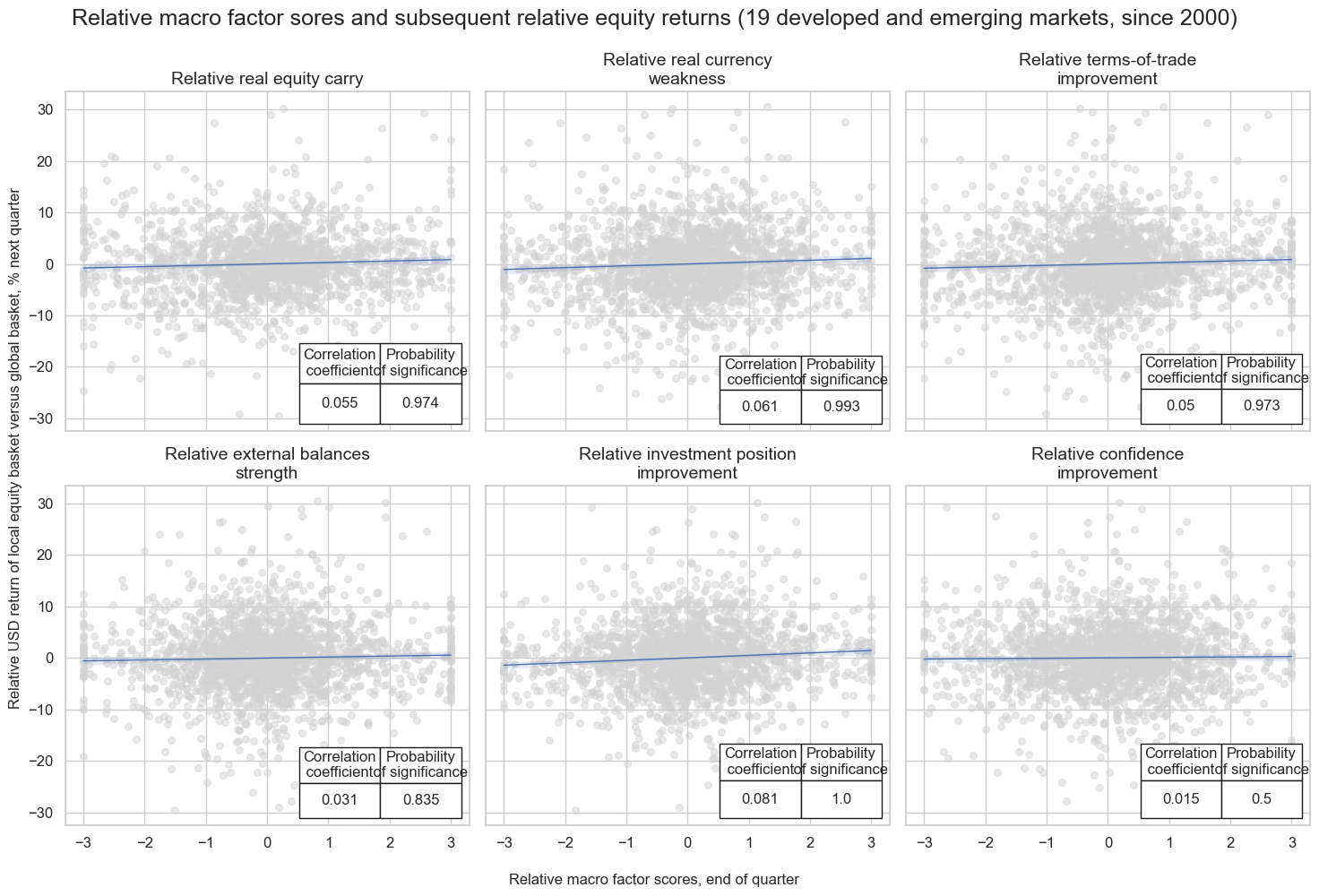
Predictive power and economic value #
Predictive power of factors #
xcatx = list(dict_factz.keys())
cidx = cids_eq
start = "2000-01-01"
catregs = {
sig : msp.CategoryRelations(
dfx,
xcats=[sig, "EQCALLRUSD_NSAvGLB"],
cids=cidx,
freq="Q",
lag=1,
slip=1,
blacklist=equsdblack,
xcat_aggs=["last", "sum"],
start=start,
)
for sig in xcatx
}
msv.multiple_reg_scatter(
cat_rels=list(catregs.values()),
figsize=(15,10),
ncol=3,
nrow=2,
title="Relative macro factor sores and subsequent relative equity returns (19 developed and emerging markets, since 2000)",
title_fontsize=18,
xlab="Relative macro factor scores, end of quarter",
ylab="Relative USD return of local equity basket versus global basket, % next quarter",
coef_box="lower right",
prob_est="map",
share_axes=True,
subplot_titles=[dict_factz[x] for x in xcatx],
)
Predictive power of composite #
# Conceptual relative factor score
xcatx = list(dict_factz.keys())
cidx = cids_eq
cfs = "ALLvGLB"
dfa = msp.linear_composite(
df=dfx,
xcats=xcatx,
cids=cids_eq,
new_xcat=cfs,
complete_xcats=False,
)
dfx= msm.update_df(dfx, dfa)
# Re-score
dfa = msp.make_zn_scores(
dfx,
xcat=cfs,
cids=cidx,
sequential=True,
min_obs=261 * 3,
neutral="zero",
pan_weight=1,
thresh=3,
postfix="_ZN",
est_freq="m",
)
dfx = msm.update_df(dfx, dfa)
dict_alls = {cfs: "Relative overall factor"} | dict_facts
dict_allz = {cfs+"_ZN": "Relative overall factor"} | dict_factz
xcatx = ["ALLvGLB_ZN"]
cidx = cids_eq
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=5,
start="2000-01-01",
same_y=True,
height=1.7,
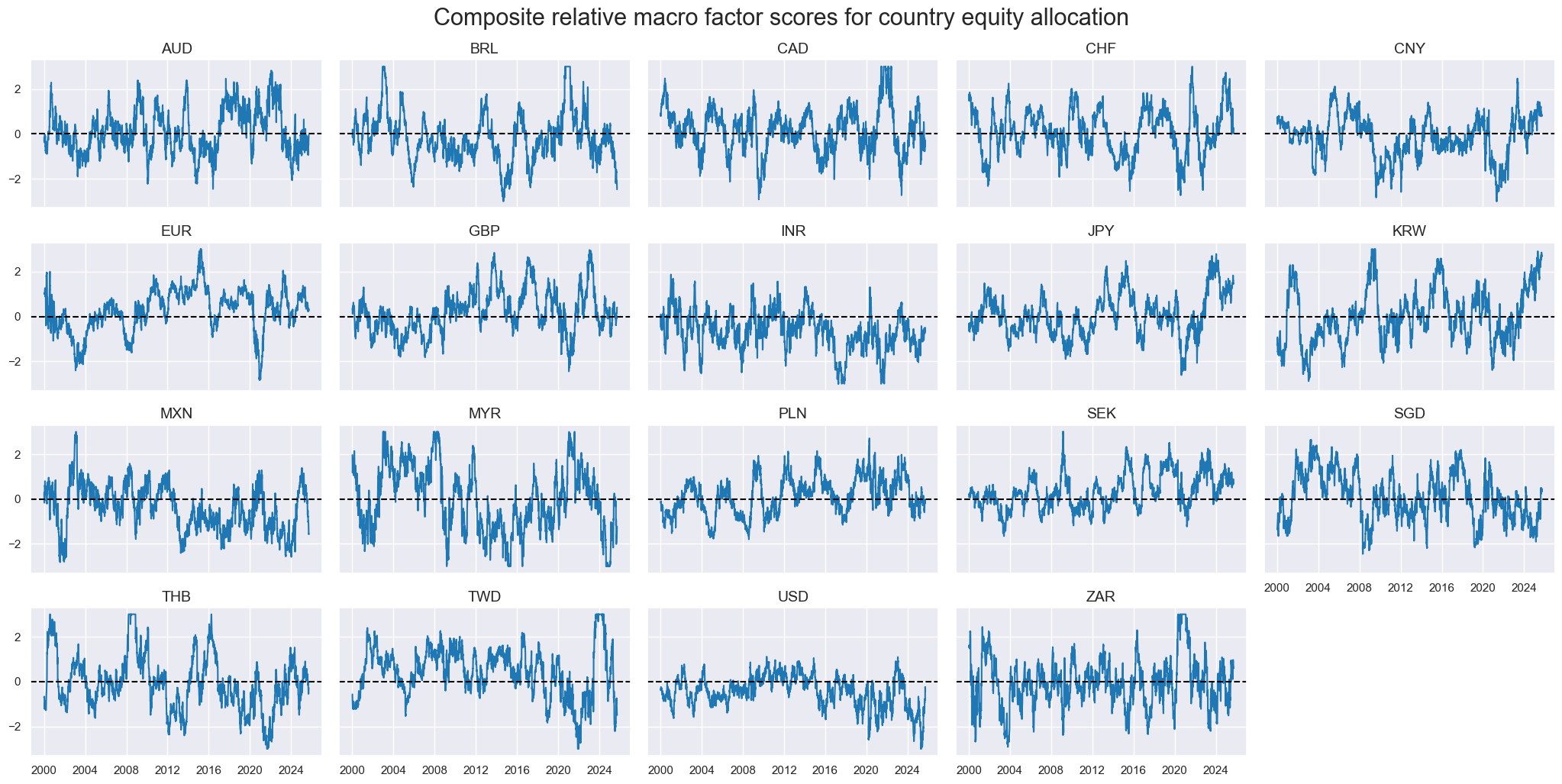
title="Composite relative macro factor scores for country equity allocation",
title_fontsize=22,
)
sig = "ALLvGLB_ZN"
ret = "EQCALLRUSD_NSAvGLB"
cidx = cids_eq
freq = "m"
start = "2000-01-01"
crx = msp.CategoryRelations(
dfx,
xcats=[sig, ret],
cids=cidx,
freq="Q",
lag=1,
slip=1,
xcat_aggs=["last", "sum"],
start=start,
blacklist=None,
)
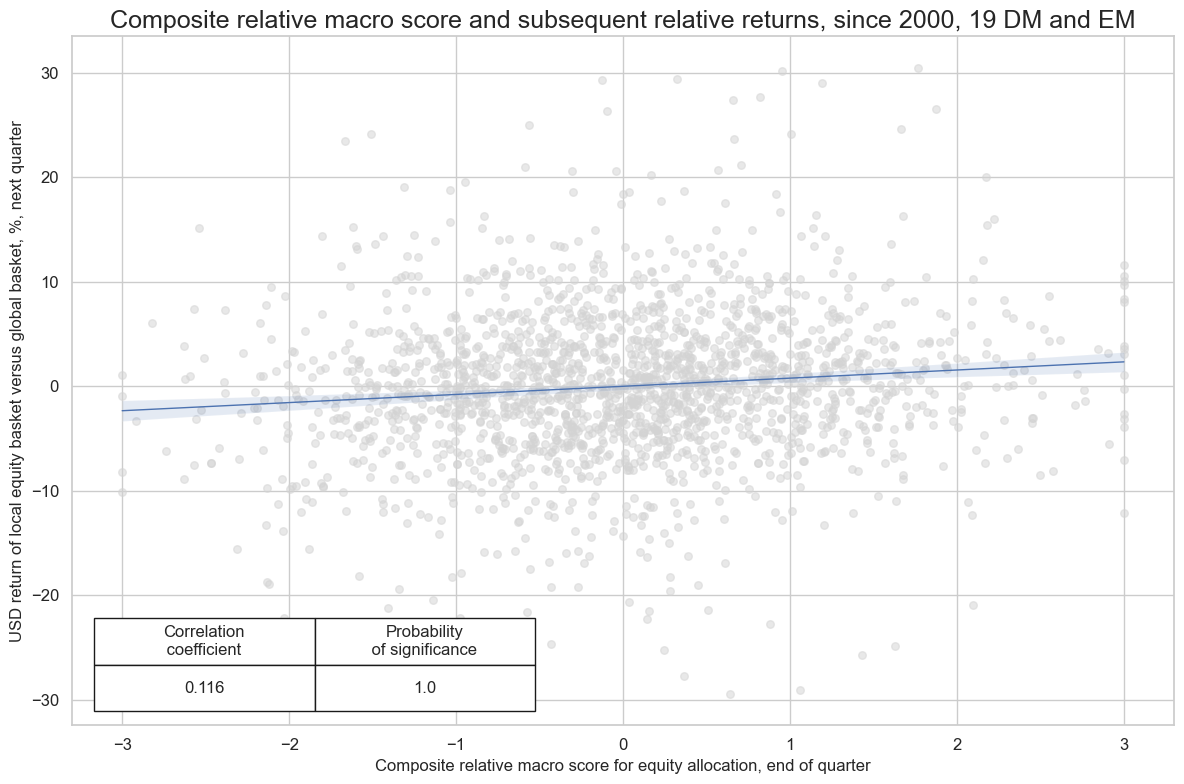
crx.reg_scatter(
labels=False,
coef_box="lower left",
xlab="Composite relative macro score for equity allocation, end of quarter",
ylab="USD return of local equity basket versus global basket, %, next quarter",
title="Composite relative macro score and subsequent relative returns, since 2000, 19 DM and EM",
title_fontsize=18,
size=(12, 8),
prob_est="map",
)
Stylized relative position PnL #
sig = "ALLvGLB_ZN"
ret = "EQCALLRUSD_NSAvGLB"
cidx = cids_eq
blax = None
sdate = "2000-01-01"
pnls = msn.NaivePnL(
df=dfx,
ret=ret,
sigs=[sig],
cids=cidx,
start=sdate,
blacklist=blax,
bms=["USD_GB10YXR_NSA", "EUR_FXXR_NSA", "USD_EQXR_NSA"],
)
pnls.make_pnl(
sig=sig,
sig_op="zn_score_pan",
rebal_freq="monthly",
neutral="zero",
thresh=3,
rebal_slip=1,
vol_scale=10,
pnl_name="PROP_PNL",
)
pnls.make_pnl(
sig=sig,
sig_op="binary",
rebal_freq="monthly",
neutral="zero",
rebal_slip=1,
vol_scale=10,
pnl_name="BIN_PNL",
)
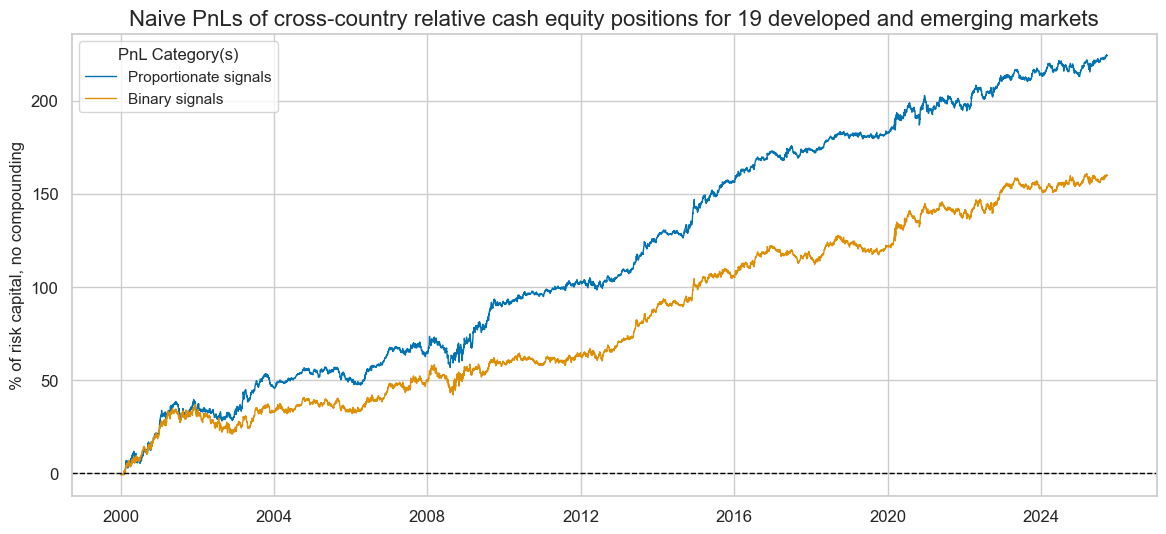
pnls.plot_pnls(
title="Naive PnLs of cross-country relative cash equity positions for 19 developed and emerging markets",
title_fontsize=16,
xcat_labels=["Proportionate signals", "Binary signals"],
figsize=(14,6)
)
display(pnls.evaluate_pnls(["PROP_PNL", "BIN_PNL"]))
| xcat | PROP_PNL | BIN_PNL |
|---|---|---|
| Return % | 8.717149 | 6.215304 |
| St. Dev. % | 10.0 | 10.0 |
| Sharpe Ratio | 0.871715 | 0.62153 |
| Sortino Ratio | 1.287248 | 0.907071 |
| Max 21-Day Draw % | -9.331289 | -7.623355 |
| Max 6-Month Draw % | -15.498525 | -14.325042 |
| Peak to Trough Draw % | -16.769772 | -16.163088 |
| Top 5% Monthly PnL Share | 0.492196 | 0.544589 |
| USD_GB10YXR_NSA correl | 0.029689 | 0.050645 |
| EUR_FXXR_NSA correl | 0.112782 | 0.125806 |
| USD_EQXR_NSA correl | -0.079334 | -0.12193 |
| Traded Months | 309 | 309 |
sigs = list(dict_factz.keys())
targ = "EQCALLRUSD_NSAvGLB"
cidx = cids_eq
blax = None
sdate = "2003-01-01"
single_pnls = msn.NaivePnL(
df=dfx,
ret=targ,
sigs=sigs,
cids=cidx,
start=sdate,
blacklist=blax,
bms=["USD_GB10YXR_NSA", "EUR_FXXR_NSA", "USD_EQXR_NSA"],
)
for sig in sigs:
single_pnls.make_pnl(
sig=sig,
sig_op="raw",
rebal_freq="monthly",
neutral="zero",
rebal_slip=1,
vol_scale=10,
)
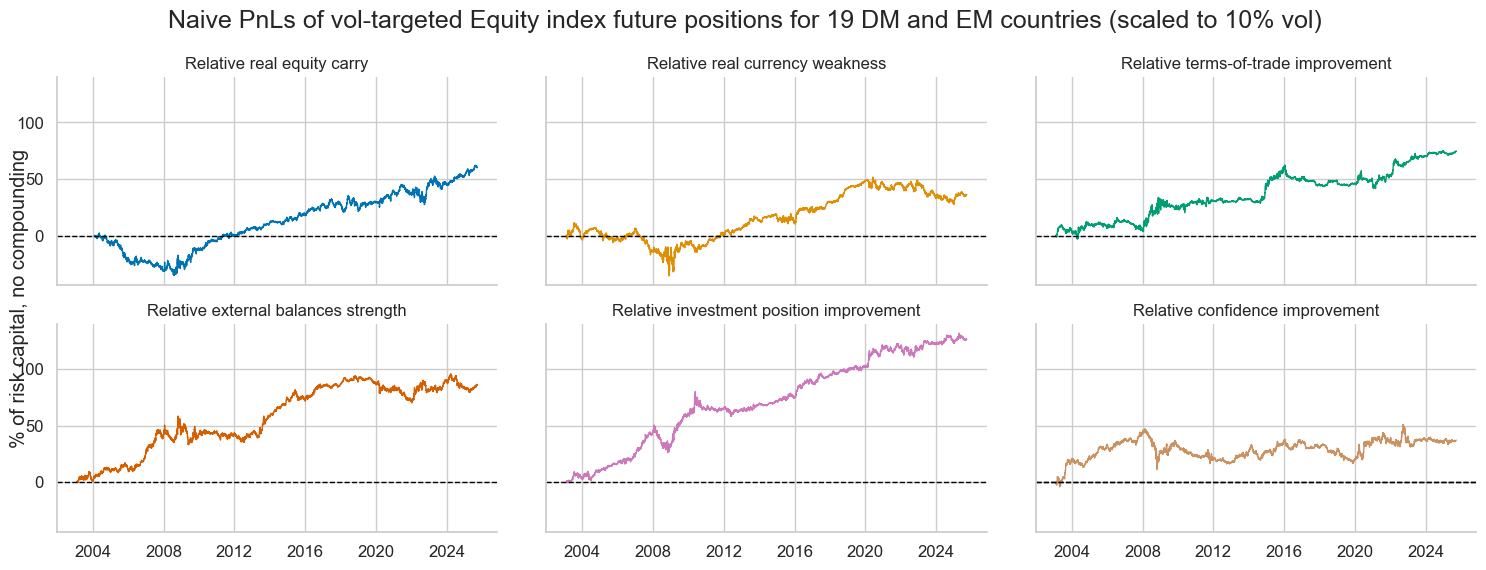
single_pnls.plot_pnls(
title="Naive PnLs of vol-targeted Equity index future positions for 19 DM and EM countries (scaled to 10% vol)",
title_fontsize=18,
xcat_labels=list(dict_factz.values()),
facet=True,
figsize=(12, 10)
)
Wealth enhancement #
Weights and pseudo-weights #
# Equal weight calculation
cidx = cids_eq
# Simple weight in the global equity basket for each country when the equity futures start being traded
calcs = [
"GEQPWGT = 0 * EQCALLRUSD_NSA + 1",
]
dfa = msp.panel_calculator(dfx, calcs=calcs, cids=cidx)
dfa["tot_cids"] = dfa.groupby(["real_date", "xcat"])["value"].transform("count")
dfa["value"] = dfa["value"] / dfa["tot_cids"]
dfx = msm.update_df(dfx, dfa.drop(columns=["tot_cids"]))
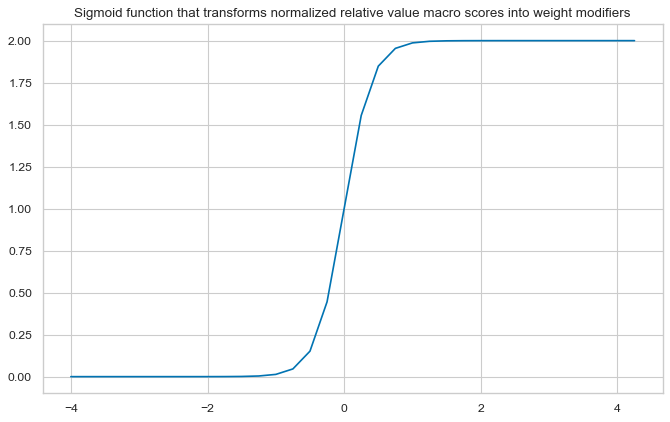
# Define appropriate sigmoid function for adjusting weights
amplitude = 2
steepness = 5
midpoint = 0
def sigmoid(x, a=amplitude, b=steepness, c=midpoint):
return a / (1 + np.exp(-b * (x - c)))
ar = np.array([i / 4 for i in range(-16, 18)])
plt.figure(figsize=(10, 6), dpi=80)
plt.plot(ar, sigmoid(ar))
plt.title("Sigmoid function that transforms normalized relative value macro scores into weight modifiers")
plt.show()
# Adjusted weights calculation
cidx = cids_eq
dfj = adjust_weights(
dfx,
weights_xcat="GEQPWGT",
adj_zns_xcat="ALLvGLB_ZN",
method="generic",
adj_func=sigmoid,
blacklist=equsdblack,
cids=cidx,
adj_name="GEQPWGT_MOD",
)
dfx = msm.update_df(dfx, dfj)
# Visualize weights
cidx = cids_eq
xcatx = ["GEQPWGT", "GEQPWGT_MOD"]
# Reduce frequency to monthly in accordance with PnL simulation
for xc in xcatx:
dfa = dfx.loc[dfx["xcat"] == xc]
dfa["last_period_bd"] = pd.to_datetime(dfa["real_date"]) + pd.tseries.offsets.BQuarterEnd(0)
mask = pd.to_datetime(dfa["last_period_bd"]) == pd.to_datetime(dfa["real_date"])
dfa.loc[~mask, "value"] = np.nan
dfa["value"] = dfa.groupby("cid")["value"].ffill(limit=75) # max 25 business days
dfa = dfa.drop(columns="xcat").assign(xcat=f"{xc}_M")
dfx = msm.update_df(dfx, dfa)
xcatxx =[xc + "_M" for xc in xcatx]
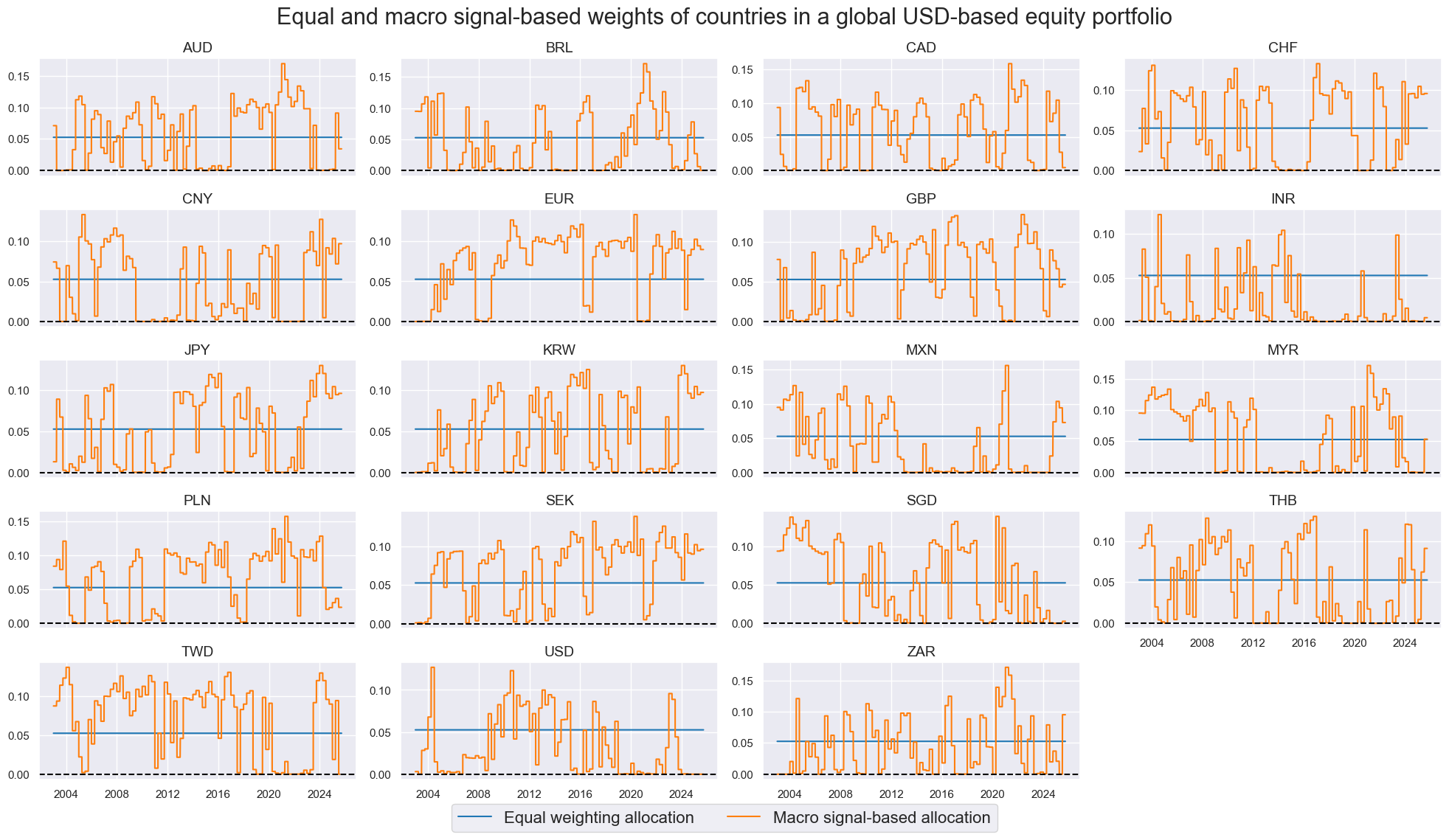
msp.view_timelines(
dfx,
xcats=xcatxx,
cids=cidx,
ncol=4,
start="2003-01-01",
same_y=False,
cumsum=False,
title="Equal and macro signal-based weights of countries in a global USD-based equity portfolio",
title_fontsize=22,
xcat_labels=["Equal weighting allocation", "Macro signal-based allocation"],
height=1.5,
aspect=2.2,
legend_fontsize=16,
)
# U.S. only "weight"
cidx = ["USD"]
calcs = [
# Always long one unit of US equity
"USEQPWGT = 0 * EQCALLRUSD_NSA + 1",
]
dfa = msp.panel_calculator(dfx, calcs=calcs, cids=cidx)
dfx = msm.update_df(dfx, dfa)
Evaluation #
dict_mod = {
"sigs": ["GEQPWGT_MOD", "GEQPWGT", "USEQPWGT"],
"targ": "EQCALLRUSD_NSA",
"cidx": cids_eq,
"start": "2000-01-01",
"black": equsdblack,
"srr": None,
"pnls": None,
}
dix = dict_mod
sigs = dix["sigs"]
ret = dix["targ"]
cidx = dix["cidx"]
start = dix["start"]
black = dix["black"]
pnls = msn.NaivePnL(
df=dfx,
ret=ret,
sigs=sigs,
cids=cidx,
start=start,
blacklist=black,
)
for sig in sigs:
pnls.make_pnl(
sig=sig,
sig_op="raw",
rebal_freq="quarterly",
neutral="zero",
rebal_slip=1,
)
dix["pnls"] = pnls
dix = dict_mod
pnls = dix["pnls"]
sigs = dix["sigs"]
pnl_cats = ["PNL_" + sig for sig in sigs]
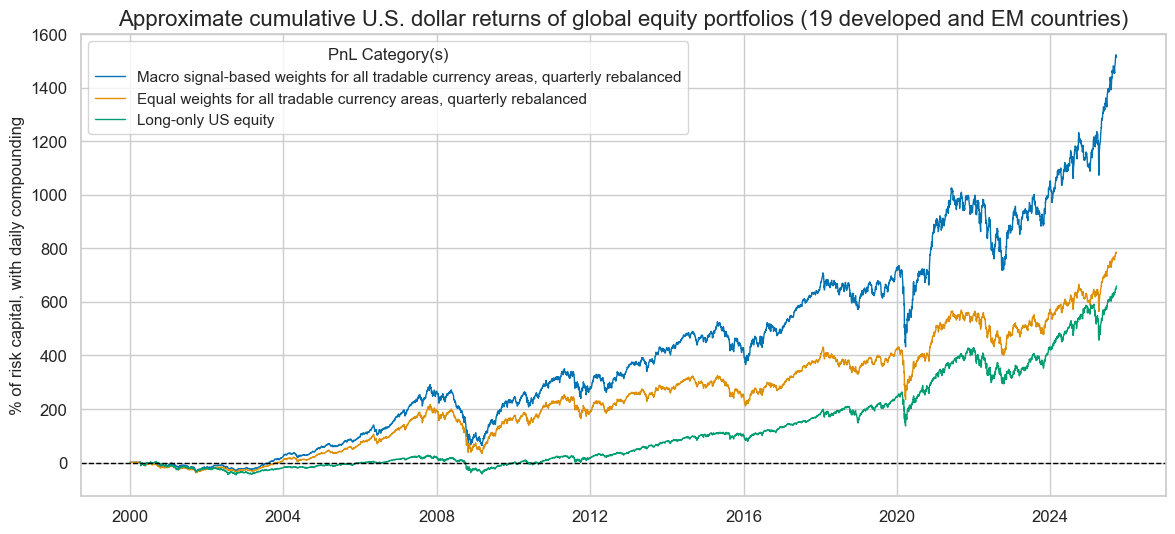
pnls.plot_pnls(
pnl_cats=pnl_cats,
title="Approximate cumulative U.S. dollar returns of global equity portfolios (19 developed and EM countries)",
title_fontsize=16,
compounding=True,
xcat_labels={
"PNL_GEQPWGT": "Equal weights for all tradable currency areas, quarterly rebalanced",
"PNL_GEQPWGT_MOD": "Macro signal-based weights for all tradable currency areas, quarterly rebalanced",
"PNL_USEQPWGT": "Long-only US equity",
},
figsize=(14,6)
)
pnls.evaluate_pnls(pnl_cats=pnl_cats)
| xcat | PNL_GEQPWGT_MOD | PNL_GEQPWGT | PNL_USEQPWGT |
|---|---|---|---|
| Return % | 12.089165 | 9.650414 | 9.902037 |
| St. Dev. % | 15.887407 | 15.31639 | 19.678504 |
| Sharpe Ratio | 0.760928 | 0.630071 | 0.503191 |
| Sortino Ratio | 1.071502 | 0.872544 | 0.712426 |
| Max 21-Day Draw % | -44.234854 | -46.065109 | -38.21883 |
| Max 6-Month Draw % | -74.633423 | -72.113718 | -55.794825 |
| Peak to Trough Draw % | -81.359015 | -79.047799 | -68.560921 |
| Top 5% Monthly PnL Share | 0.563015 | 0.662894 | 0.587019 |
| Traded Months | 309 | 309 | 309 |