EM sovereign risk premia indices with EMBI adjustment #
Get packages and JPMaQS data #
Setup and imports #
# !pip install macrosynergy --upgrade
DQ_CLIENT_ID: str = "your_client_id"
DQ_CLIENT_SECRET: str = "your_client_secret"
# Constants and credentials
import os
REQUIRED_VERSION: str = "1.2.2"
DQ_CLIENT_ID: str = os.getenv("DQ_CLIENT_ID")
DQ_CLIENT_SECRET: str = os.getenv("DQ_CLIENT_SECRET")
PROXY = {} # Configure if behind corporate firewall
START_DATE: str = "1998-01-01"
import macrosynergy as msy
msy.check_package_version(required_version=REQUIRED_VERSION)
# If version check fails: pip install macrosynergy --upgrade
if not DQ_CLIENT_ID or not DQ_CLIENT_SECRET:
raise ValueError(
"Missing DataQuery credentials." \
"Please set DQ_CLIENT_ID and DQ_CLIENT_SECRET as environment variables or insert them directly in the notebook."
)
import numpy as np
import pandas as pd
from pandas import Timestamp
import matplotlib.pyplot as plt
import os
import io
from datetime import datetime
import macrosynergy.management as msm
import macrosynergy.panel as msp
import macrosynergy.signal as mss
import macrosynergy.pnl as msn
import macrosynergy.visuals as msv
from macrosynergy.download import JPMaQSDownload
from macrosynergy.panel.adjust_weights import adjust_weights
import warnings
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
from IPython.display import display
pd.set_option('display.width', 400)
warnings.simplefilter("ignore")
Data selection and download #
cids_fc_latam = [ # Latam foreign currency debt countries
"BRL",
"CLP",
"COP",
"DOP",
"MXN",
"PEN",
"UYU",
]
cids_fc_emeu = [ # EM Europe foreign currency debt countries
"HUF",
"PLN",
"RON",
"RUB",
"RSD",
"TRY",
]
cids_fc_meaf = [ # Middle-East and Africa foreign currency debt countries
"AED",
"EGP",
"NGN",
"OMR",
"QAR",
"ZAR",
"SAR",
]
cids_fc_asia = [ # Asia foreign currency debt countries
"CNY",
"IDR",
"INR",
"PHP",
]
cids_fc = sorted(
list(
set(cids_fc_latam + cids_fc_emeu + cids_fc_meaf + cids_fc_asia)
)
)
cids_emxfc = ["CZK", "ILS", "KRW", "MYR", "SGD", "THB", "TWD"]
cids_em = sorted(cids_fc + cids_emxfc)
# Category tickers
# Features
govfin = [
"GGOBGDPRATIO_NSA",
"GGOBGDPRATIONY_NSA",
"GGDGDPRATIO_NSA",
]
xbal = [
"CABGDPRATIO_NSA_12MMA",
"MTBGDPRATIO_NSA_12MMA",
]
xliab = [
"NIIPGDP_NSA_D1Mv2YMA",
"NIIPGDP_NSA_D1Mv5YMA",
"IIPLIABGDP_NSA_D1Mv2YMA",
"IIPLIABGDP_NSA_D1Mv5YMA",
]
xdebt = [
"ALLIFCDSGDP_NSA",
"GGIFCDSGDP_NSA",
]
GOVRISK = [
"ACCOUNTABILITY_NSA",
"POLSTAB_NSA",
"CORRCONTROL_NSA",
]
growth = [
'RGDP_SA_P1Q1QL4_20QMA',
"RGDP_SA_P1Q1QL4"
]
infl = [
"CPIC_SA_P1M1ML12",
"CPIH_SA_P1M1ML12",
]
risk_metrics = [
"LTFCRATING_NSA",
"LTLCRATING_NSA",
"FCBICRY_NSA",
"FCBICRY_VT10",
"CDS05YSPRD_NSA",
"CDS05YXRxEASD_NSA",
]
# Targets
rets = ["FCBIR_NSA", "FCBIXR_NSA", "FCBIXR_VT10"]
# Benchmark returns
bms = ["USD_EQXR_NSA", "UHY_CRXR_NSA", "UIG_CRXR_NSA"]
# Create ticker list
xcats = govfin + xbal + xliab + xdebt + GOVRISK + growth + infl + risk_metrics + rets
tickers = [cid + "_" + xcat for cid in cids_em for xcat in xcats] + bms
print(f"Maximum number of tickers is {len(tickers)}")
Maximum number of tickers is 840
# Download macro-quantamental indicators from JPMaQS via the DataQuery API
with JPMaQSDownload(
client_id=DQ_CLIENT_ID,
client_secret=DQ_CLIENT_SECRET,
proxy=PROXY
) as downloader:
df: pd.DataFrame = downloader.download(
tickers=tickers,
start_date=START_DATE,
metrics=["value",],
suppress_warning=True,
show_progress=True,
report_time_taken=True,
get_catalogue=True,
)
Downloading the JPMAQS catalogue from DataQuery...
Downloaded JPMAQS catalogue with 23214 tickers.
Removed 82/840 expressions that are not in the JPMaQS catalogue.
Downloading data from JPMaQS.
Timestamp UTC: 2025-07-09 08:45:06
Connection successful!
Requesting data: 100%|███████████████████████████████████| 38/38 [00:07<00:00, 4.92it/s]
Downloading data: 100%|██████████████████████████████████| 38/38 [00:31<00:00, 1.21it/s]
Time taken to download data: 40.69 seconds.
Some expressions are missing from the downloaded data. Check logger output for complete list.
1 out of 758 expressions are missing. To download the catalogue of all available expressions and filter the unavailable expressions, set `get_catalogue=True` in the call to `JPMaQSDownload.download()`.
# Preserve original downloaded data for debugging and comparison
dfx = df.copy()
dfx.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 4678657 entries, 0 to 4678656
Data columns (total 4 columns):
# Column Dtype
--- ------ -----
0 real_date datetime64[ns]
1 cid object
2 xcat object
3 value float64
dtypes: datetime64[ns](1), float64(1), object(2)
memory usage: 142.8+ MB
Availability checks and blacklisting #
Availability #
xcatx = govfin
msm.check_availability(df=dfx, xcats=xcatx, cids=cids_em, missing_recent=False)

xcatx = xbal
msm.check_availability(df=dfx, xcats=xcatx, cids=cids_em, missing_recent=False)

xcatx = xliab
msm.check_availability(df=dfx, xcats=xcatx, cids=cids_em, missing_recent=False)

xcatx = xdebt
msm.check_availability(df=dfx, xcats=xcatx, cids=cids_em, missing_recent=False)

xcatx = risk_metrics
msm.check_availability(df=dfx, xcats=xcatx, cids=cids_em, missing_recent=False)

xcatx = rets
msm.check_availability(df=dfx, xcats=xcatx, cids=cids_em, missing_recent=False)
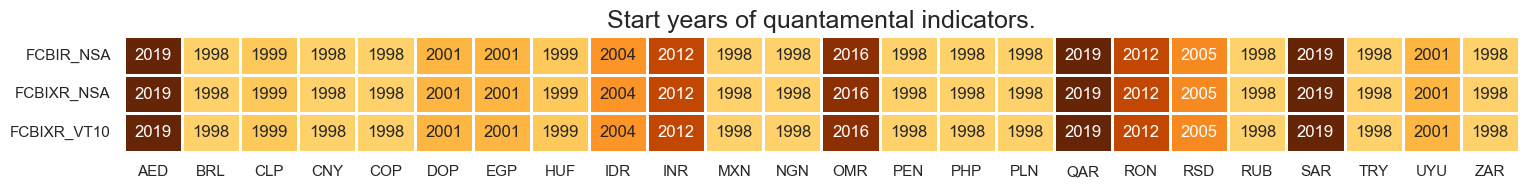
xcatx = growth
msm.check_availability(df=dfx, xcats=xcatx, cids=cids_em, missing_recent=False)

xcatx = infl
msm.check_availability(df=dfx, xcats=xcatx, cids=cids_em, missing_recent=False)
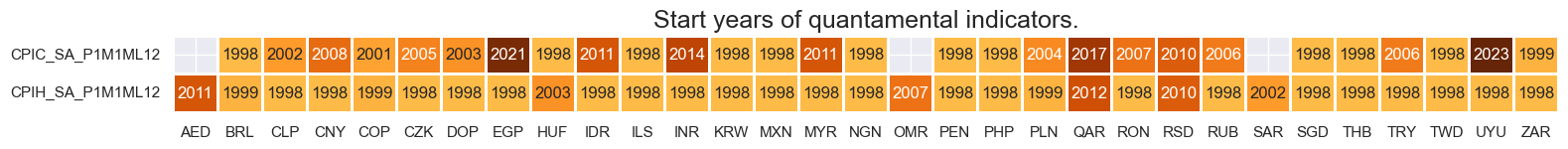
Blacklist #
black_fc = {'RUB': [Timestamp('2022-02-01 00:00:00'), Timestamp('2035-02-26 00:00:00')]}
Macro risk score construction and checks #
Preparatory transformations #
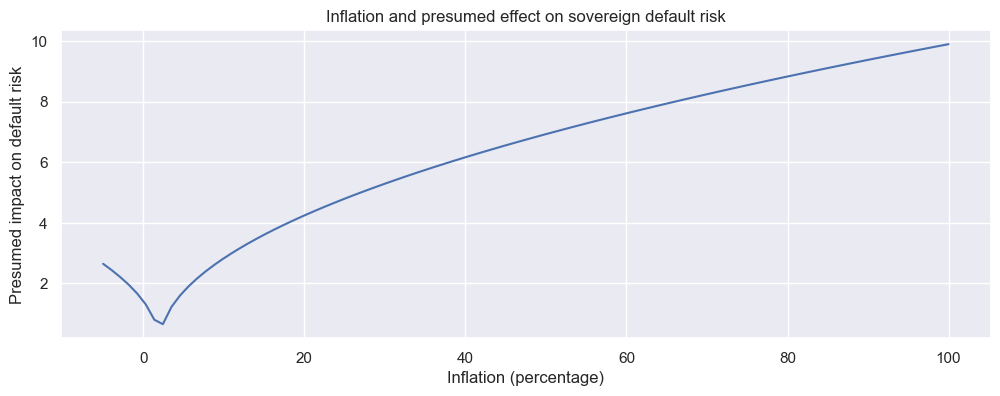
# Non-linear inflation effect theory
x = np.linspace(-5, 100, 100)
y = np.power(abs(x - 2), 1/2)
plt.figure(figsize=(12, 4))
plt.plot(x, y)
plt.title("Inflation and presumed effect on sovereign default risk")
plt.xlabel("Inflation (percentage)")
plt.ylabel("Presumed impact on default risk")
plt.grid(True)
plt.show()
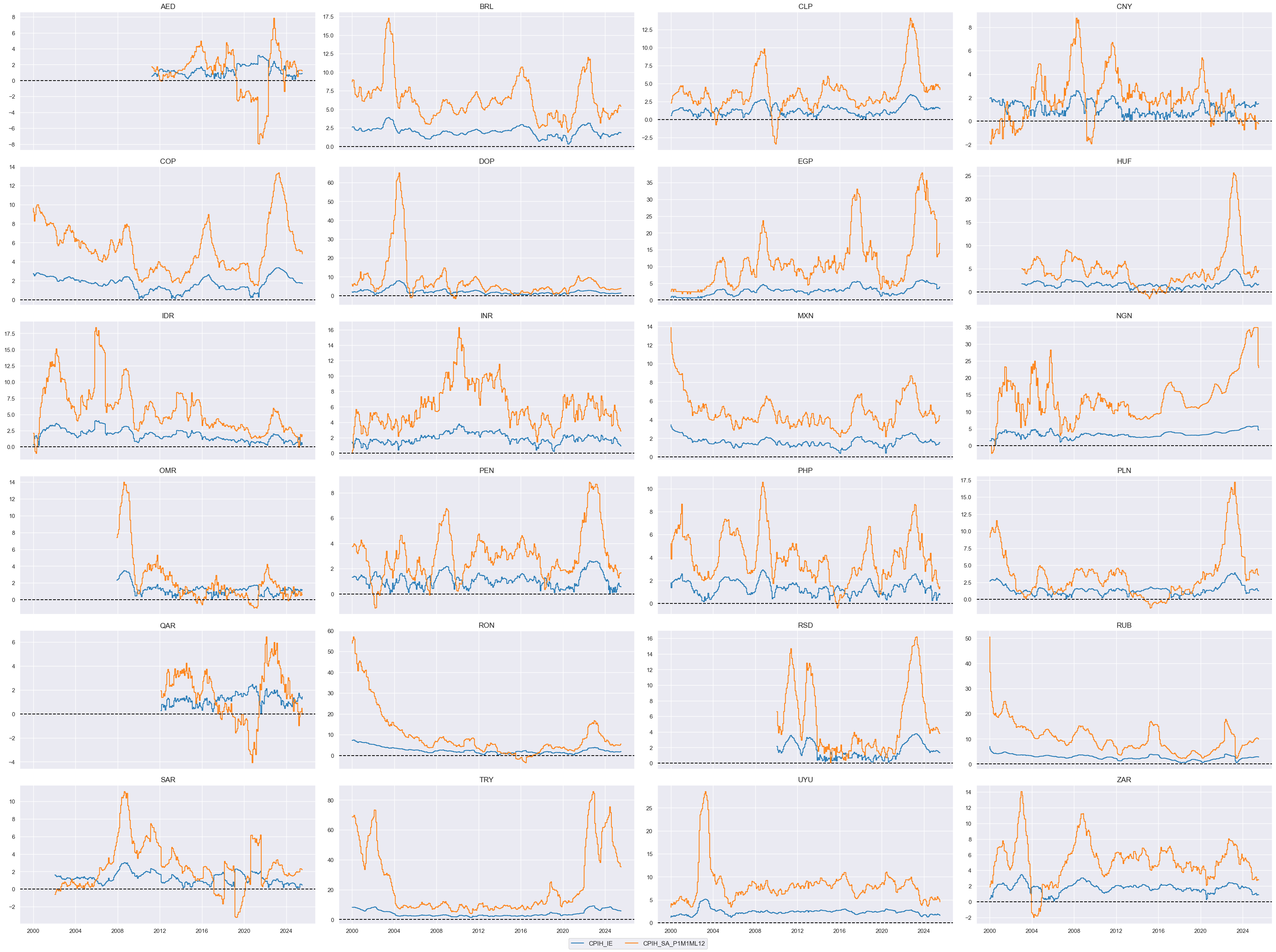
# Inflation effects
cidx = cids_fc
xcx = ["CPIH", "CPIC"]
calcs = [
f"{xc}_IE = {xc}_SA_P1M1ML12.applymap(lambda x: np.power(abs(x - 2), 1/2))"
for xc in xcx
]
dfa = msp.panel_calculator(dfx, calcs=calcs, cids=cidx)
dfx = msm.update_df(dfx, dfa)
xcatx = ["CPIH_IE", "CPIH_SA_P1M1ML12"]
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=4,
start="2000-01-01",
aspect=2,
same_y=False,
)
Macro risk scores #
Conceptual factor scores #
# Placeholder dictionaries
dict_factz = {}
dict_labels = {}
# Governing dictionary of quantamental indicators, neutral levels, and weightings
dict_macros = {
"GFINRISK":{
"GGOBGDPRATIO_NSA": ["median", "NEG", 1/3],
"GGOBGDPRATIONY_NSA": ["median", "NEG", 1/3],
"GGDGDPRATIO_NSA": ["median", "", 1/3],
},
"XBALRISK":{
"CABGDPRATIO_NSA_12MMA": ["median", "NEG", 0.5],
"MTBGDPRATIO_NSA_12MMA": ["median", "NEG", 0.5],
},
"XLIABRISK":{
"NIIPGDP_NSA_D1Mv2YMA": ["median", "NEG", 0.25],
"NIIPGDP_NSA_D1Mv5YMA": ["median", "NEG", 0.25],
"IIPLIABGDP_NSA_D1Mv2YMA": ["median", "", 0.25],
"IIPLIABGDP_NSA_D1Mv5YMA": ["median", "", 0.25],
},
"XDEBTRISK":{
"ALLIFCDSGDP_NSA": ["median", "", 0.5],
"GGIFCDSGDP_NSA": ["median", "", 0.5],
},
"GOVRISK":{
"ACCOUNTABILITY_NSA": ["median", "NEG", 1/3],
"POLSTAB_NSA": ["median", "NEG", 1/3],
"CORRCONTROL_NSA": ["median", "NEG", 1/3],
},
"GROWTHRISK":{
"RGDP_SA_P1Q1QL4_20QMA": ["median", "NEG", 0.5],
"RGDP_SA_P1Q1QL4": ["median", "NEG", 0.5],
},
"INFLRISK":{
"CPIH_IE": ["median", "", 0.5],
"CPIC_IE": ["median", "", 0.5],
}
}
# Normalize all macro-quantamental categories based on the broad EM set
cidx = cids_em
for fact in dict_macros.keys():
dict_fact = dict_macros[fact]
xcatx = list(dict_fact.keys())
dfa = pd.DataFrame(columns=list(dfx.columns))
for xc in xcatx:
postfix = dict_fact[xc][1]
neutral = dict_fact[xc][0]
dfaa = msp.make_zn_scores(
dfx,
xcat=xc,
cids=cidx,
sequential=True,
min_obs=261 * 3,
neutral=neutral,
pan_weight=1,
thresh=3,
postfix="_" + postfix + "ZN",
est_freq="m",
)
dfaa["value"] = dfaa["value"] * (1 if postfix == "" else -1)
dfa = msm.update_df(dfa, dfaa)
dict_factz[fact] = dfa["xcat"].unique()
dfx = msm.update_df(dfx, dfa)
# Combine quantamental scores to conceptual scores
cidx = cids_em
for key, value in dict_factz.items():
weights = [w[2] for w in list(dict_macros[key].values())]
dfa = msp.linear_composite(
dfx,
xcats=value,
cids=cidx,
weights=weights,
normalize_weights= True,
complete_xcats=False,
new_xcat=key,
)
dfx = msm.update_df(dfx, dfa)
for key in dict_factz.keys():
dfa = msp.make_zn_scores(
dfx,
xcat=key,
cids=cidx,
sequential=True,
min_obs=261 * 3,
neutral="zero",
pan_weight=1,
thresh=3,
postfix="_ZN",
est_freq="m",
)
dfx = msm.update_df(dfx, dfa)
macroz = [fact + "_ZN" for fact in dict_factz.keys()]
dict_labels["GGOBGDPRATIO_NSA_NEGZN"] = "Excess government balance, % of GDP, current year, negative"
dict_labels["GGOBGDPRATIONY_NSA_NEGZN"] = "Excess government balance, % of GDP, next year, negative"
dict_labels["GGDGDPRATIO_NSA_ZN"] = "Excess general government debt ratio, % of GDP"
dict_labels["GFINRISK_ZN"] = "Government finances risk score"
dict_labels["CABGDPRATIO_NSA_12MMA_NEGZN"] = "Current account balance, 12mma, % of GDP, negative"
dict_labels["MTBGDPRATIO_NSA_12MMA_NEGZN"] = "Merchandise trade balance, 12mma, % of GDP, negative"
dict_labels["XBALRISK_ZN"] = "External balances risk score"
dict_labels["IIPLIABGDP_NSA_D1Mv2YMA_ZN"] = "International liabilities, vs. 2yma, % of GDP"
dict_labels["IIPLIABGDP_NSA_D1Mv5YMA_ZN"] = "International liabilities, vs. 5yma, % of GDP"
dict_labels["NIIPGDP_NSA_D1Mv2YMA_NEGZN"] = "Net international investment position, vs. 2yma, % of GDP, negative"
dict_labels["NIIPGDP_NSA_D1Mv5YMA_NEGZN"] = "Net international investment position, vs. 5yma, % of GDP, negative"
dict_labels["XLIABRISK_ZN"] = "International position risk score"
dict_labels["ALLIFCDSGDP_NSA_NEGZN"] = "Excess foreign-currency debt securities, all, % of GDP, negative"
dict_labels["GGIFCDSGDP_NSA_NEGZN"] = "Excess foreign-currency debt securities, government, % of GDP, negative"
dict_labels["XDEBTRISK_ZN"] = "Foreign-currency debt risk score"
dict_labels["ACCOUNTABILITY_NSA_NEGZN"] = "Voice and accountability index, z-score"
dict_labels["POLSTAB_NSA_NEGZN"] = "Political stability and absence of violence/terrorism index, z-score"
dict_labels["CORRCONTROL_NSA_NEGZN"] = "Corruption control index, z-score"
dict_labels['GOVRISK_ZN'] = 'Governance risk score'
dict_labels["RGDP_SA_P1Q1QL4_20QMA_NEGZN"] = "Real GDP growth, percentage over a year ago, z-score"
dict_labels["RGDP_SA_P1Q1QL4_NEGZN"] = "Real GDP growth, percentage over a year ago, z-score"
dict_labels['GROWTHRISK_ZN'] = "Growth risk score"
dict_labels["CPIH_IE_NEGZN"] = "Headline CPI inflation effect, z-score"
dict_labels["CPIC_IE_NEGZN"] = "Core CPI inflation effect, z-score"
dict_labels["INFLRISK_ZN"] = "Inflation risk score"
# Box for quantamental score review
factor = "XBALRISK" # "GFINRISK" "XBALRISK" "XLIABRISK" "XDEBTRISK" "GOVRISK" "GROWTHRISK" "INFLRISK"
xcatx = list(dict_factz[factor])
cidx = cids_fc
sdate = "2000-01-01"
msp.view_ranges(
dfx,
xcats=xcatx,
kind="bar",
sort_cids_by="mean", # countries sorted by mean of the first category
start=sdate,
xcat_labels=dict_labels,
)
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=4,
start=sdate,
same_y=True,
aspect=2,
xcat_labels=dict_labels,
title=None,
title_fontsize=22,
legend_fontsize=16,
height=2,
)
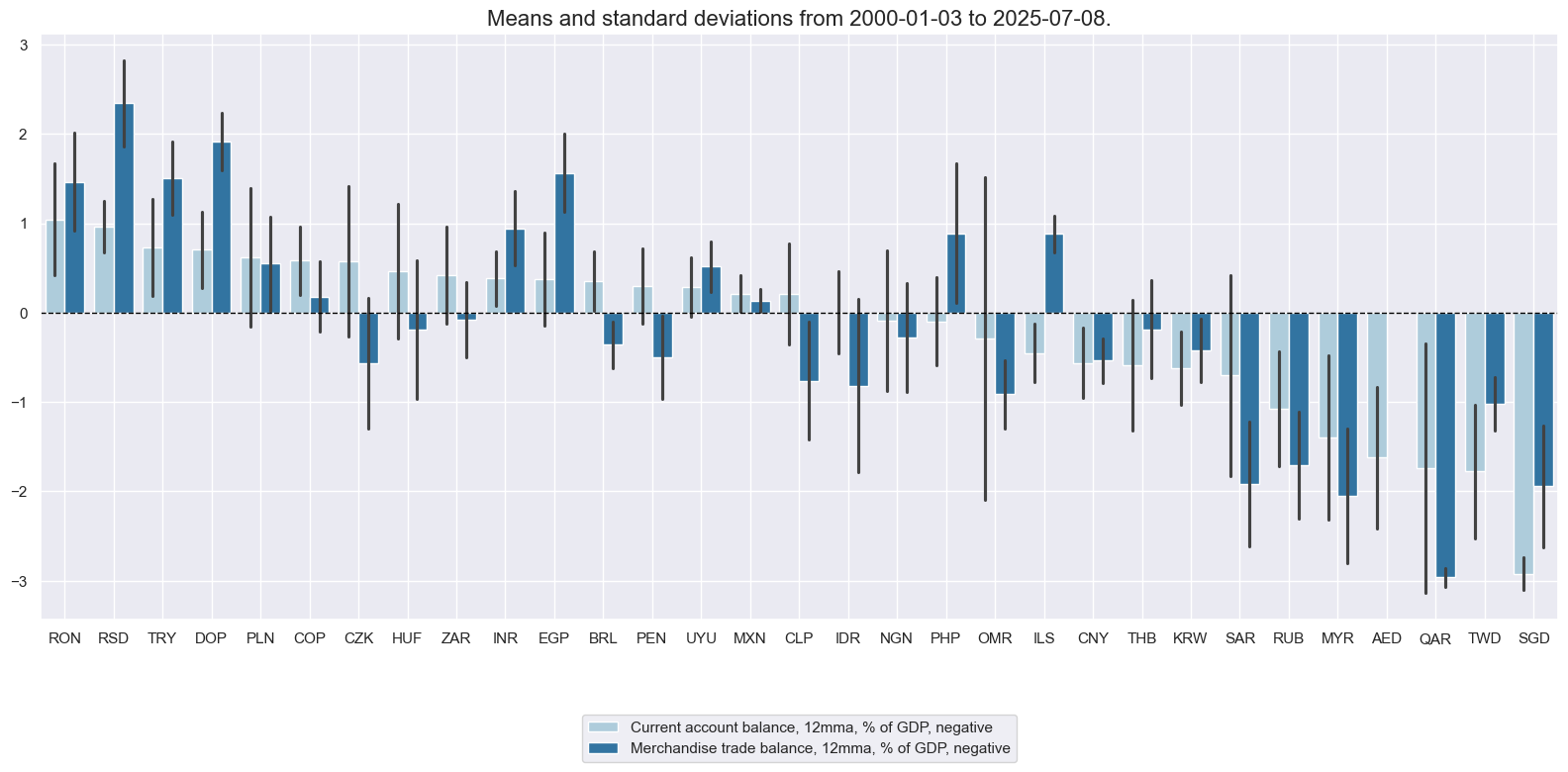
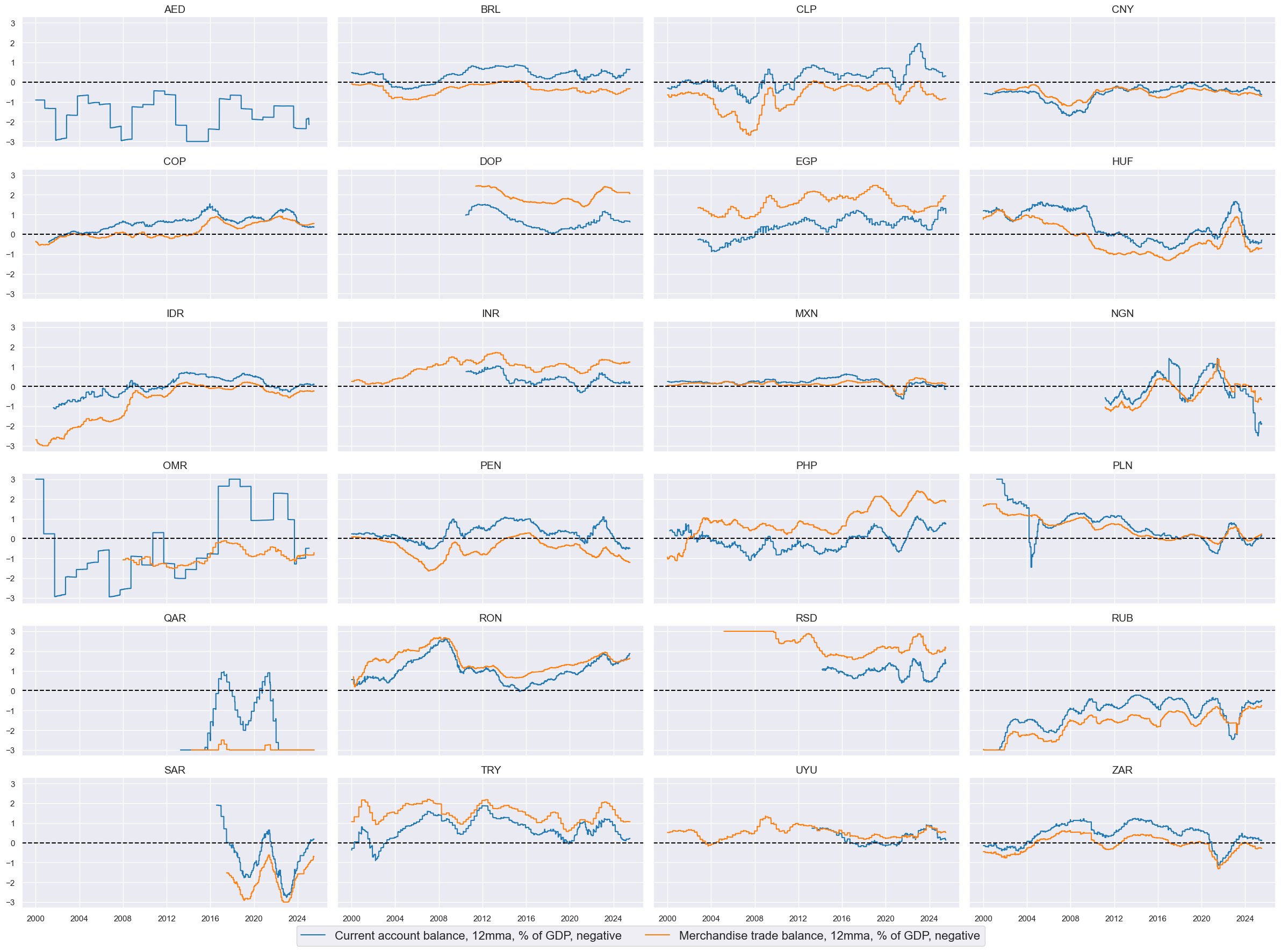
xcatx = macroz
cidx = cids_fc
sdate = "2000-01-01"
msp.view_ranges(
dfx,
xcats=xcatx,
kind="bar",
sort_cids_by=None,
start=sdate,
xcat_labels=dict_labels,
)
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=4,
start=sdate,
same_y=True,
aspect=2,
xcat_labels=dict_labels,
title="Macro scores related to sovereign debt default risk (higher score means higher risk)",
title_fontsize=25,
legend_fontsize=16,
height=2,
)
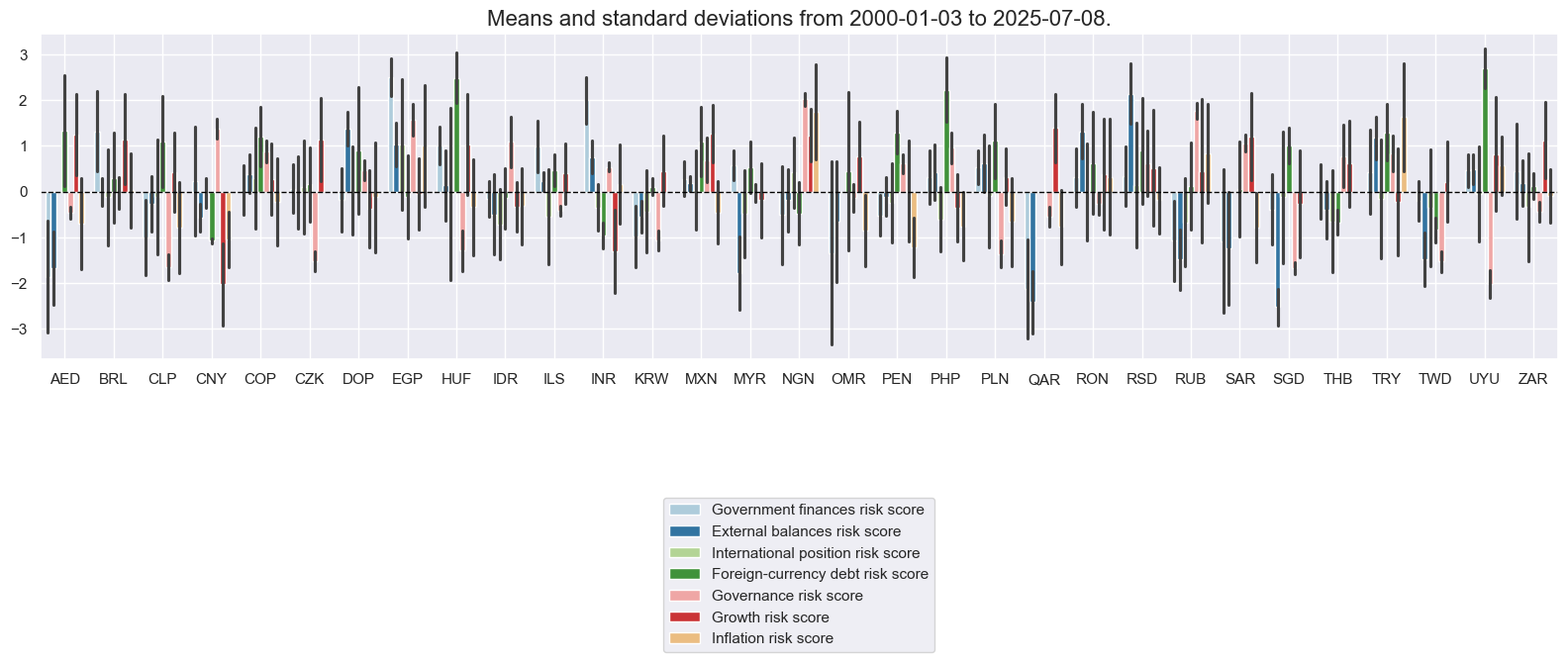
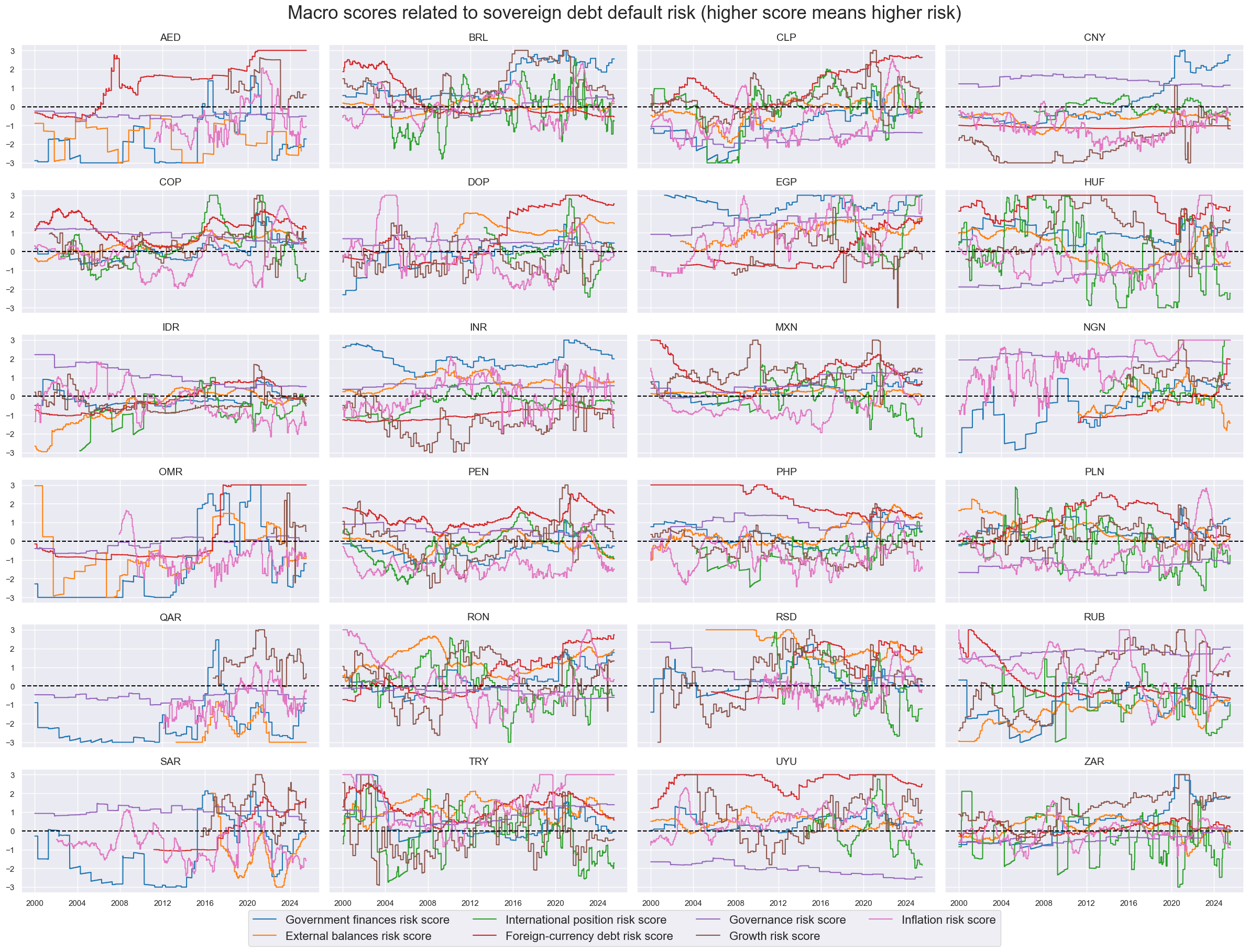
Composite macro risk scores #
# Custom weights
dict_custom_weights = {
'GFINRISK_ZN': 1,
'XBALRISK_ZN': 1,
'XLIABRISK_ZN': 1,
'XDEBTRISK_ZN': 0.001,
'GOVRISK_ZN': 1,
'GROWTHRISK_ZN': 0.001,
'INFLRISK_ZN': 0.001,
}
# Weighted composite macro risk scores
cidx = cids_fc
xcatx = macroz
equal_weights = [1/len(macroz)] * len(macroz)
custom_weights = [dict_custom_weights[m] for m in macroz]
weights = {
"EWS": equal_weights,
"CWS": custom_weights,
}
for k, w in weights.items():
dfa = msp.linear_composite(
dfx,
xcats=xcatx,
cids=cidx,
weights=w,
normalize_weights=True,
complete_xcats=False,
new_xcat="MACRORISK_" + k,
)
dfx = msm.update_df(dfx, dfa)
# Re-scoring the composites
for m in ['MACRORISK_EWS', 'MACRORISK_CWS']:
dfa = msp.make_zn_scores(
dfx,
xcat=m,
cids=cidx,
sequential=True,
min_obs=261 * 3,
neutral="zero",
pan_weight=1,
thresh=3,
postfix="_ZN",
est_freq="m",
)
dfx = msm.update_df(dfx, dfa)
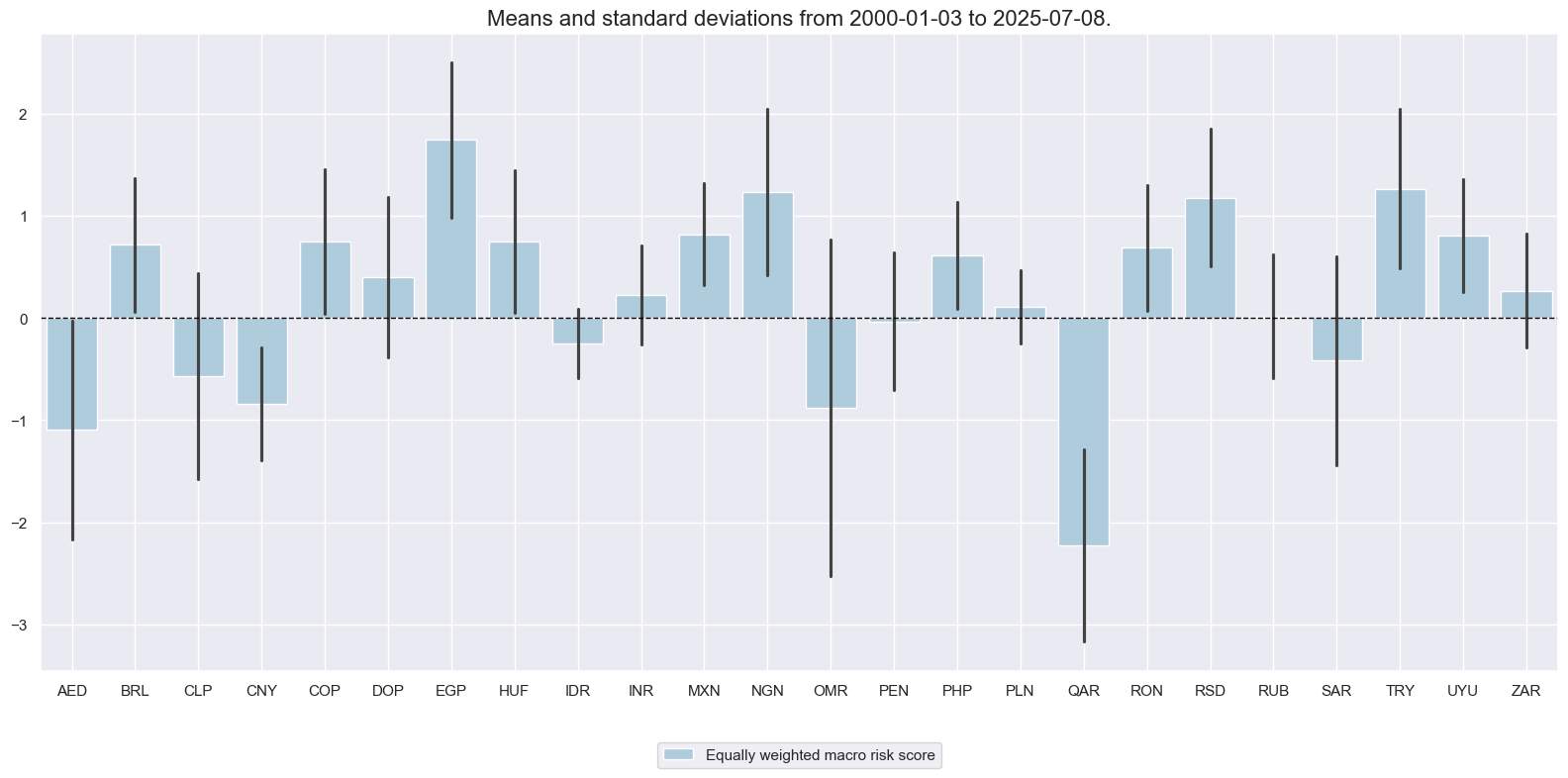
dict_labels['MACRORISK_EWS_ZN'] = 'Equally weighted macro risk score'
dict_labels['MACRORISK_CWS_ZN'] = 'Custom weighted macro risk score'
xcatx = ['MACRORISK_EWS_ZN'] # ['MACRORISK_EWS_ZN', 'MACRORISK_CWS_ZN']
cidx = cids_fc
sdate = "2000-01-01"
msp.view_ranges(
dfx,
xcats=xcatx,
kind="bar",
sort_cids_by=None,
start=sdate,
xcat_labels=dict_labels,
)
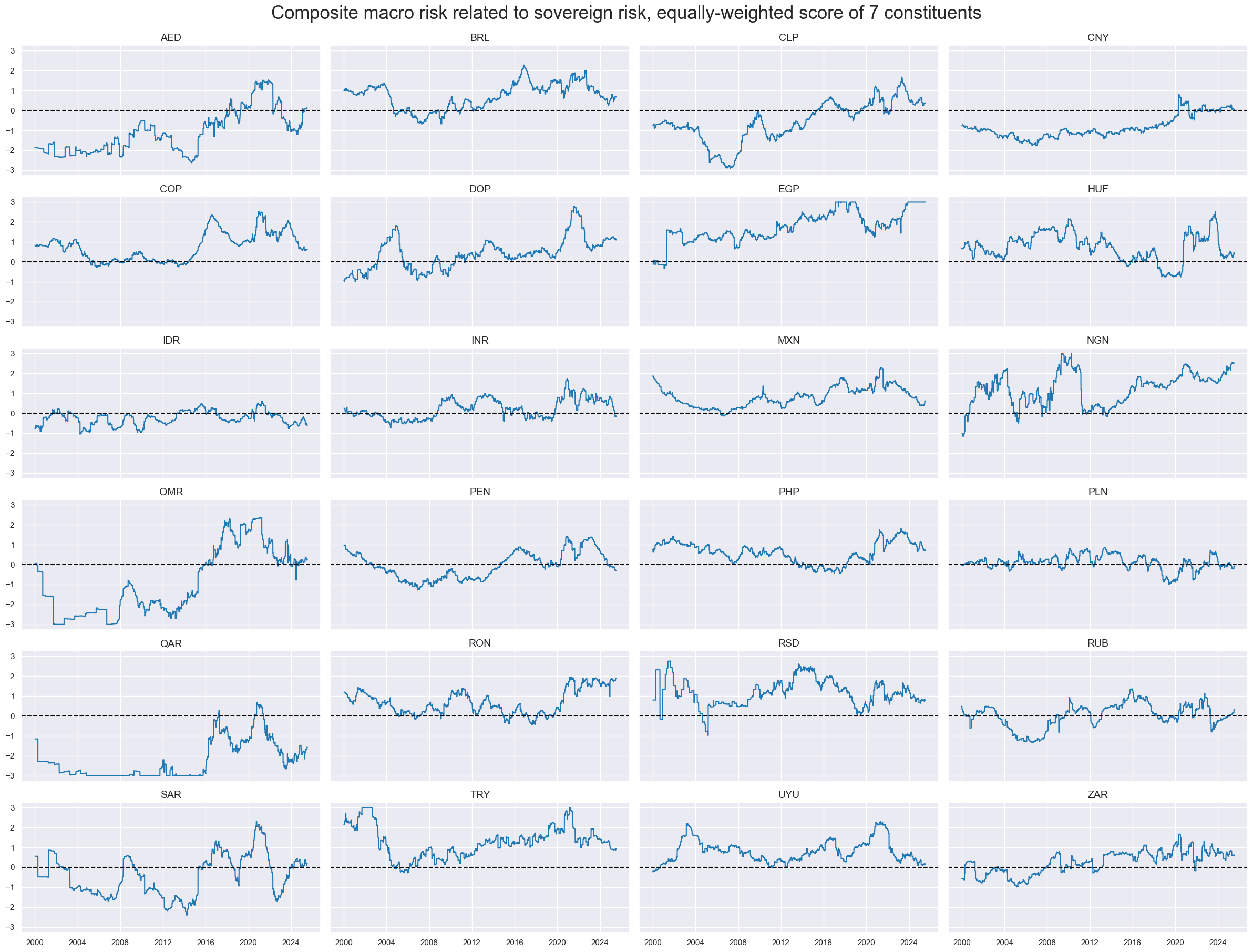
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=4,
start=sdate,
same_y=True,
aspect=2,
xcat_labels=dict_labels,
title="Composite macro risk related to sovereign risk, equally-weighted score of 7 constituents",
title_fontsize=25,
legend_fontsize=16,
height=2,
)
Market-implied risk scores #
# Use index carry where CDS spreads not available ("priced risk" score)
msm.missing_in_df(df, xcats=["CDS05YSPRD_NSA"], cids=cids_fc) # countries without CDS
cidx = ['AED', 'DOP', 'EGP', 'INR', 'NGN', 'OMR', 'QAR', 'RSD', 'SAR', 'UYU']
calcs = ["CDS05YSPRD_NSA = FCBICRY_NSA"]
dfa = msp.panel_calculator(dfx, calcs=calcs, cids=cidx)
dfx = msm.update_df(dfx, dfa)
# Use inverse rating score ("rated risk" score)
calcs = [
"LTFCRATING_ADJ = LTFCRATING_NSA + 1", # temporary fix for VEF/RUB problem
"LTFCRATING_INV = 1 / LTFCRATING_ADJ",
"CDS05YSPRD_LOG = np.log( CDS05YSPRD_NSA )" # accoount for non-linearity of spread changes
]
cidx = cids_fc
dfa = msp.panel_calculator(dfx, calcs=calcs, cids=cidx)
dfx = msm.update_df(dfx, dfa)
No missing XCATs across DataFrame.
Missing cids for CDS05YSPRD_NSA: ['AED', 'DOP', 'EGP', 'INR', 'NGN', 'OMR', 'QAR', 'RSD', 'SAR', 'UYU']
xcatx = ["LTFCRATING_INV", "MACRORISK_EWS_ZN"]
cidx = cids_fc
catregs = {}
for xc in xcatx:
catregs[xc] = msp.CategoryRelations(
dfx,
xcats=[xc, "CDS05YSPRD_NSA"],
cids=cidx,
years=1,
lag=0,
xcat_aggs=["mean", "mean"],
blacklist=black_fc,
start="2000-01-01",
)
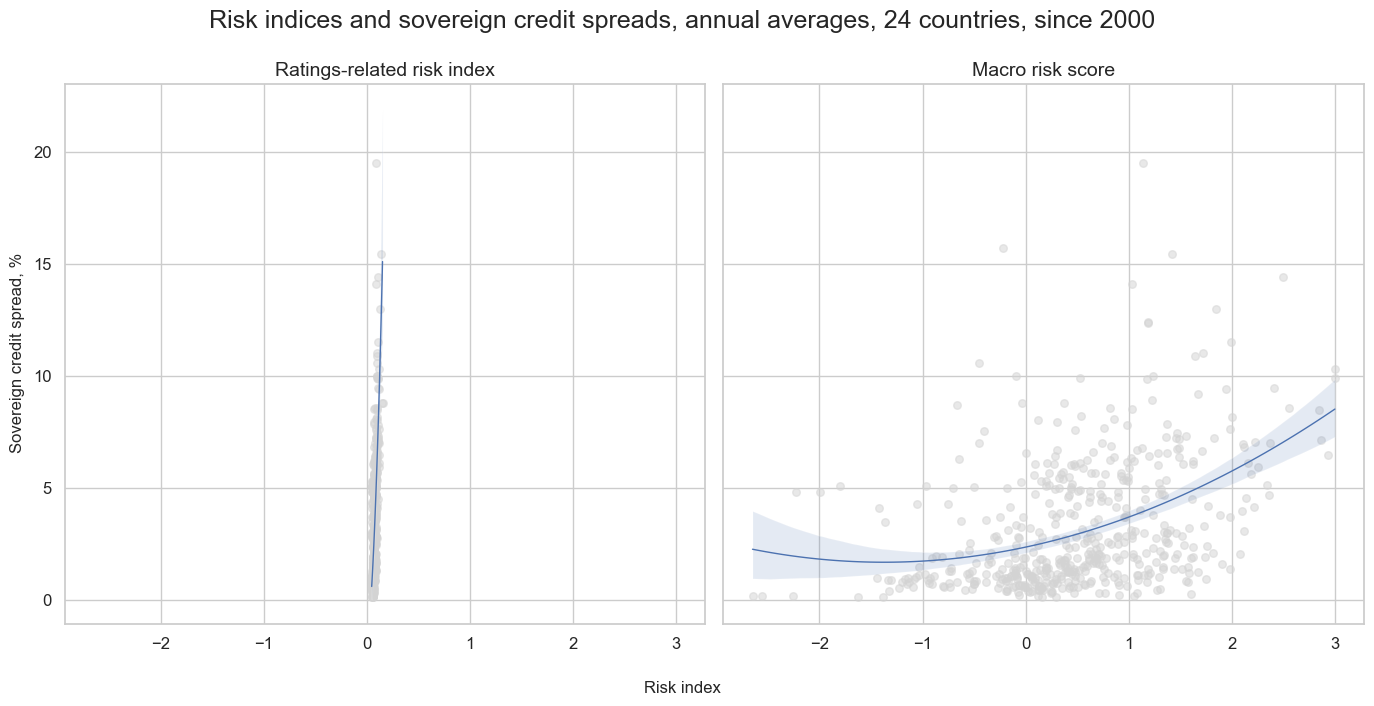
msv.multiple_reg_scatter(
cat_rels=[v for k, v in catregs.items()],
reg_order=2,
ncol=2,
nrow=1,
figsize=(14, 7),
title="Risk indices and sovereign credit spreads, annual averages, 24 countries, since 2000",
title_fontsize=18,
xlab="Risk index",
ylab="Sovereign credit spread, %",
subplot_titles=["Ratings-related risk index", "Macro risk score"],
)
# Re-score the composite
for xc in ["CDS05YSPRD_LOG", "LTFCRATING_INV"]:
dfa = msp.make_zn_scores(
dfx,
xcat=xc,
cids=cidx,
sequential=True,
min_obs=261 * 3,
neutral="median",
pan_weight=1,
thresh=3,
postfix="_ZN",
est_freq="m",
)
dfx = msm.update_df(dfx, dfa)
dict_labels["CDS05YSPRD_LOG_ZN"] = "Log spread-based market risk score"
dict_labels["LTFCRATING_INV_ZN"] = "Ratings-based market risk score"
# Composite market risk scores
cidx = cids_fc
xcatx = ["CDS05YSPRD_LOG_ZN", "LTFCRATING_INV_ZN"]
dfa = msp.linear_composite(
dfx,
xcats=xcatx,
cids=cidx,
complete_xcats=False,
new_xcat="MARKETRISK",
)
dfx = msm.update_df(dfx, dfa)
# Re-score the composite
dfa = msp.make_zn_scores(
dfx,
xcat="MARKETRISK",
cids=cidx,
sequential=True,
min_obs=261 * 3,
neutral="zero",
pan_weight=1,
thresh=3,
postfix="_ZN",
est_freq="m",
)
dfx = msm.update_df(dfx, dfa)
dict_labels["MARKETRISK_ZN"] = "Composite market risk score"
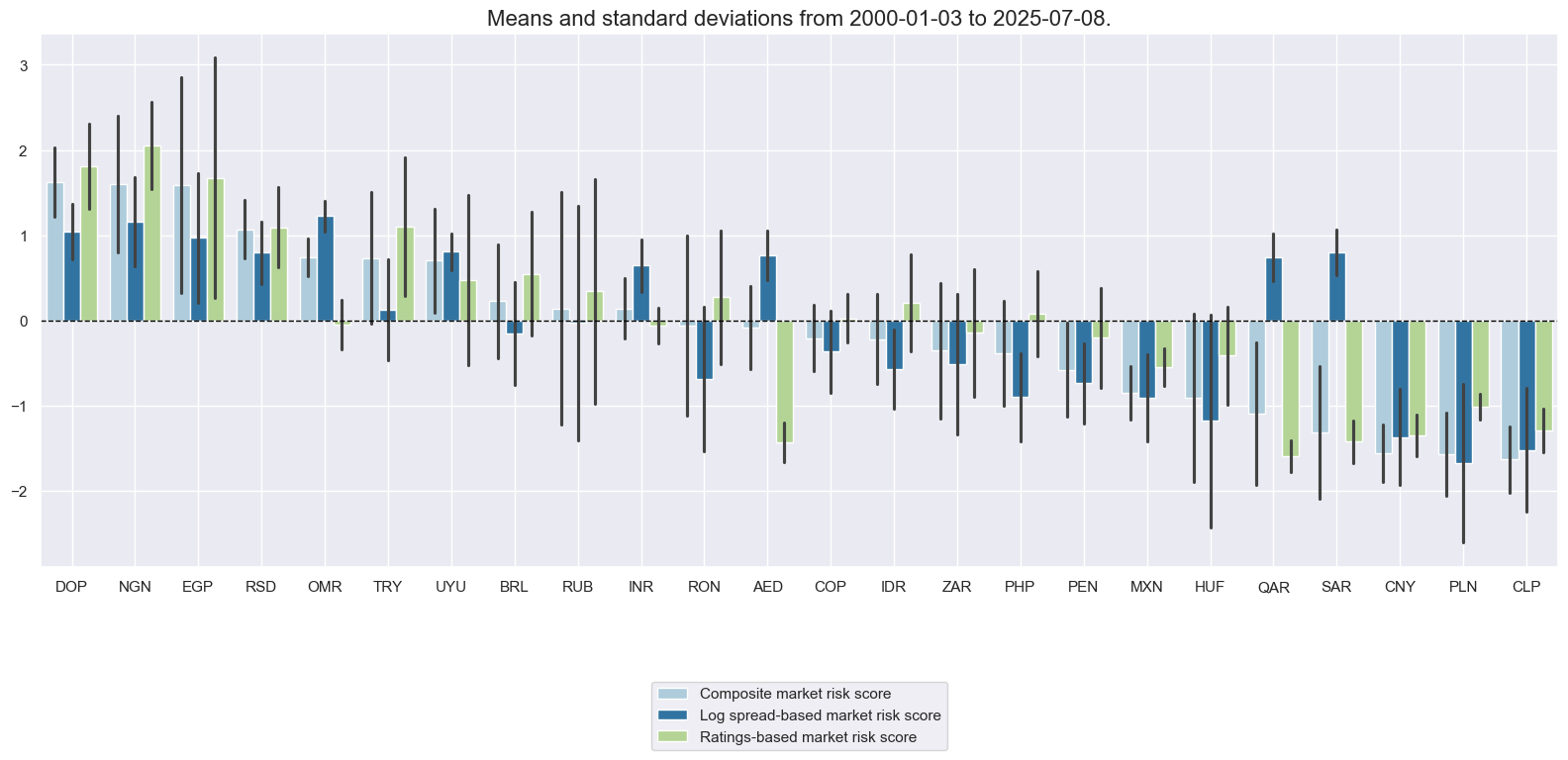
xcatx = ["MARKETRISK_ZN", "CDS05YSPRD_LOG_ZN", "LTFCRATING_INV_ZN"]
cidx = cids_fc
sdate = "2000-01-01"
msp.view_ranges(
dfx,
xcats=xcatx,
kind="bar",
sort_cids_by="mean",
start=sdate,
xcat_labels=dict_labels,
)
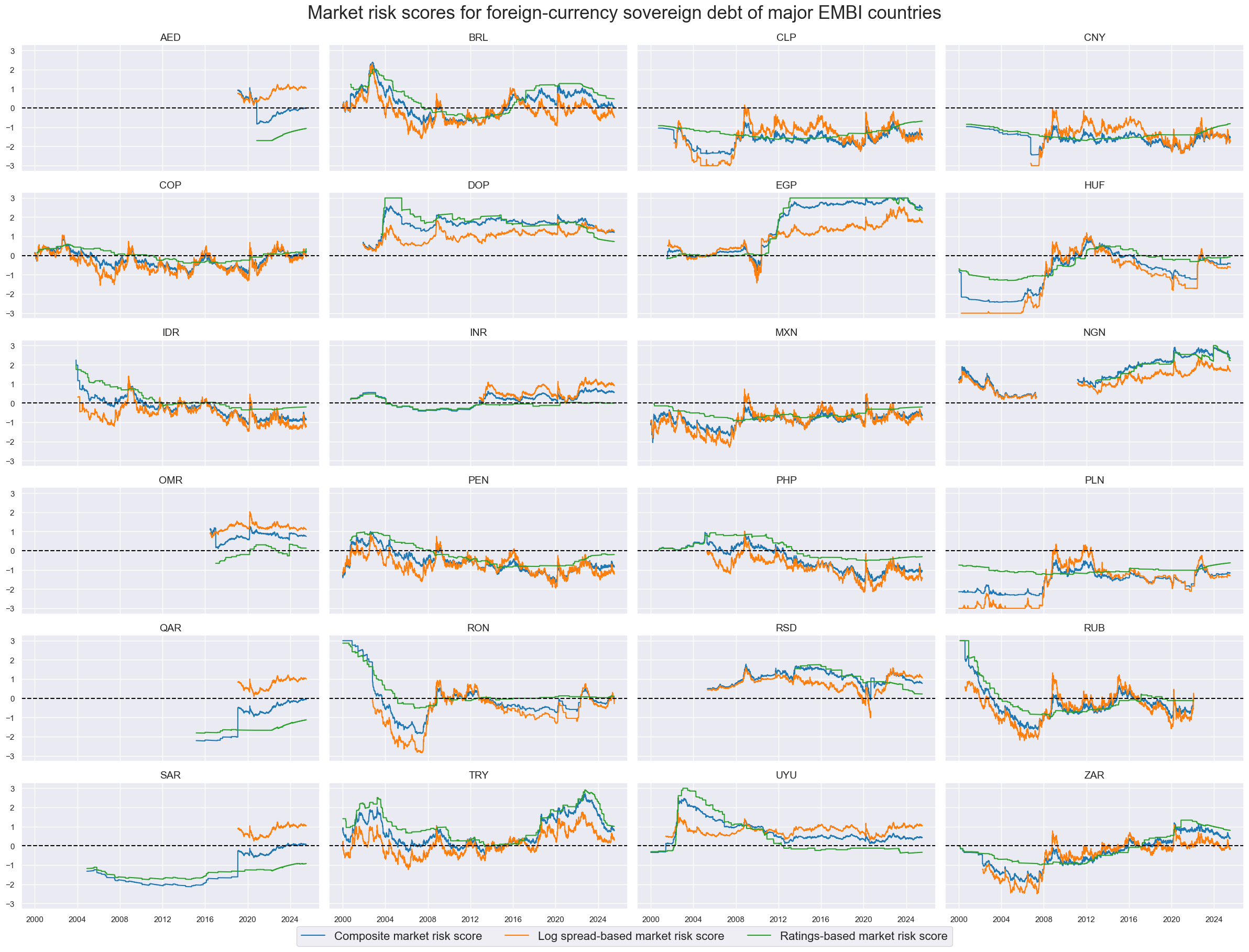
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=4,
start=sdate,
same_y=True,
xcat_labels=dict_labels,
title='Market risk scores for foreign-currency sovereign debt of major EMBI countries',
title_fontsize=25,
legend_fontsize=16,
aspect=2,
height=2,
blacklist=black_fc
)
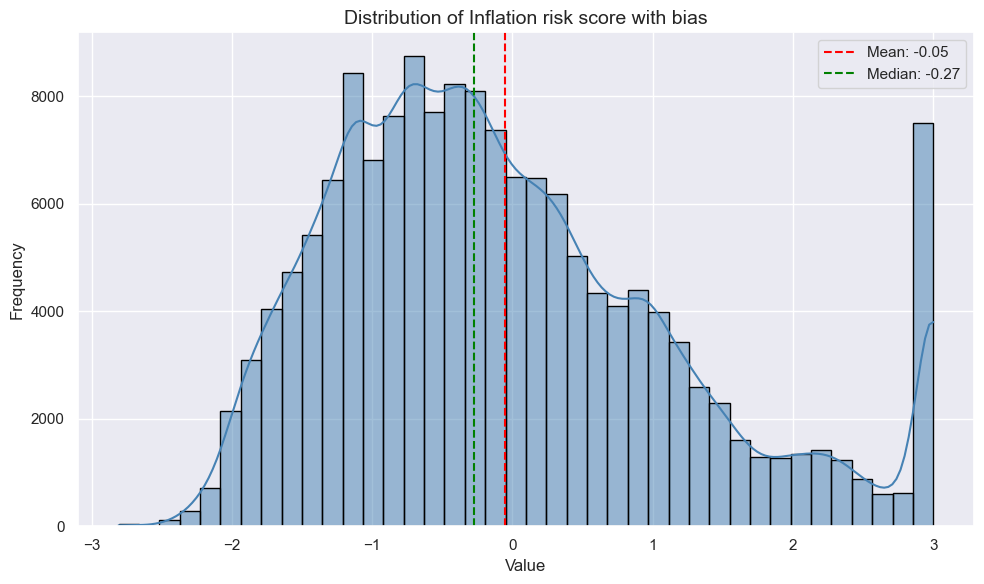
Distribution bias analysis #
Macro risk distribution #
xcat = 'INFLRISK_ZN' # 'GFINRISK_ZN', 'XBALRISK_ZN', 'XLIABRISK_ZN', 'XDEBTRISK_ZN', 'GOVRISK_ZN', 'GROWTHRISK_ZN', 'INFLRISK_ZN' # MACRORISK_EWS_ZN, MACRORISK_CWS_ZN
dfxa = dfx[(dfx['xcat'] == xcat)]
plt.figure(figsize=(10, 6))
sns.histplot(dfxa['value'], kde=True, bins=40, color='steelblue', edgecolor='black')
mean_val = dfxa['value'].mean()
median_val = dfxa['value'].median()
plt.axvline(mean_val, color='red', linestyle='--', label=f'Mean: {mean_val:.2f}')
plt.axvline(median_val, color='green', linestyle='--', label=f'Median: {median_val:.2f}')
plt.title(f"Distribution of {dict_labels[xcat]} with bias", fontsize=14)
plt.xlabel("Value")
plt.ylabel("Frequency")
plt.legend()
plt.tight_layout()
plt.show()
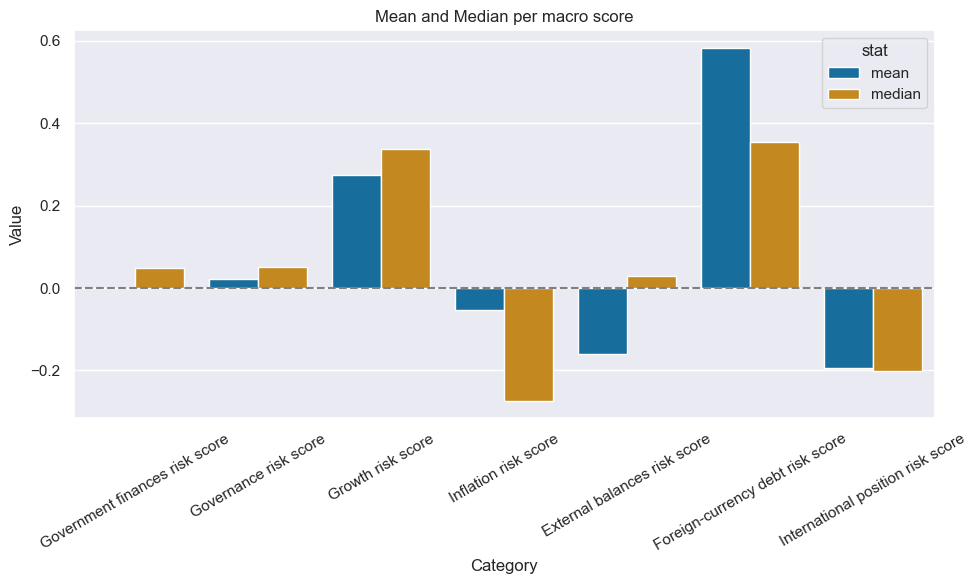
summary_stats = dfx[dfx['xcat'].isin(macroz)].groupby('xcat')['value'].agg(['mean', 'median']).reset_index()
summary_long = summary_stats.melt(id_vars='xcat', value_vars=['mean', 'median'], var_name='stat')
summary_long['xcat_lab'] = summary_long['xcat'].map(dict_labels)
# Plot using the new column
plt.figure(figsize=(10, 6))
sns.barplot(data=summary_long, x='xcat_lab', y='value', hue='stat')
plt.title("Mean and Median per macro score")
plt.ylabel("Value")
plt.xlabel("Category")
plt.axhline(0, linestyle='--', color='gray')
# Rotate x-axis labels
plt.xticks(rotation=30)
plt.tight_layout()
plt.show()
macroz_total = macroz + ['MACRORISK_EWS_ZN'] + ['MACRORISK_CWS_ZN']
dfxa = dfx[dfx['xcat'].isin(macroz_total)].copy()
dfxa['is_positive'] = dfxa['value'] > 0
dfxa['is_negative'] = dfxa['value'] < 0
category_stats = (
dfxa.groupby('xcat')
.agg(
positives=('is_positive', 'sum'),
negatives=('is_negative', 'sum'),
total=('value', 'count')
)
.reset_index()
)
category_stats['share_positive'] = (
category_stats['positives'] / category_stats['total']
).map("{:.2%}".format)
category_stats['xcat_label'] = category_stats['xcat'].map(dict_labels)
category_stats = category_stats[['xcat_label', 'positives', 'negatives', 'total', 'share_positive']]
display(category_stats.sort_values('share_positive', ascending=False))
| xcat_label | positives | negatives | total | share_positive | |
|---|---|---|---|---|---|
| 5 | Equally weighted macro risk score | 109641 | 62151 | 171792 | 63.82% |
| 7 | Foreign-currency debt risk score | 123060 | 80451 | 203511 | 60.47% |
| 2 | Growth risk score | 111166 | 76724 | 187955 | 59.15% |
| 4 | Custom weighted macro risk score | 99074 | 72718 | 171792 | 57.67% |
| 0 | Government finances risk score | 112877 | 104438 | 217315 | 51.94% |
| 6 | External balances risk score | 102714 | 97850 | 200564 | 51.21% |
| 1 | Governance risk score | 113187 | 108711 | 221898 | 51.01% |
| 3 | Inflation risk score | 64800 | 92403 | 157226 | 41.21% |
| 8 | International position risk score | 63389 | 90920 | 155237 | 40.83% |
From the above, we can conclude that the distribution is not excessively weighted in either direction - however the number of positives is higher than 50% in all categories except for the inflation and the international position scores. Therefore, we find a positive bias in the scores.
Basic relationship visualizations #
Long-term relations #
# Long-term ratings - spread relations
xcatx = ["LTFCRATING_INV_ZN", "CDS05YSPRD_LOG_ZN"]
cidx = cids_fc
cr = msp.CategoryRelations(
dfx,
xcats=xcatx,
cids=cidx,
years=10,
lag=0,
xcat_aggs=["mean", "mean"],
blacklist=black_fc,
start="2000-01-01",
)
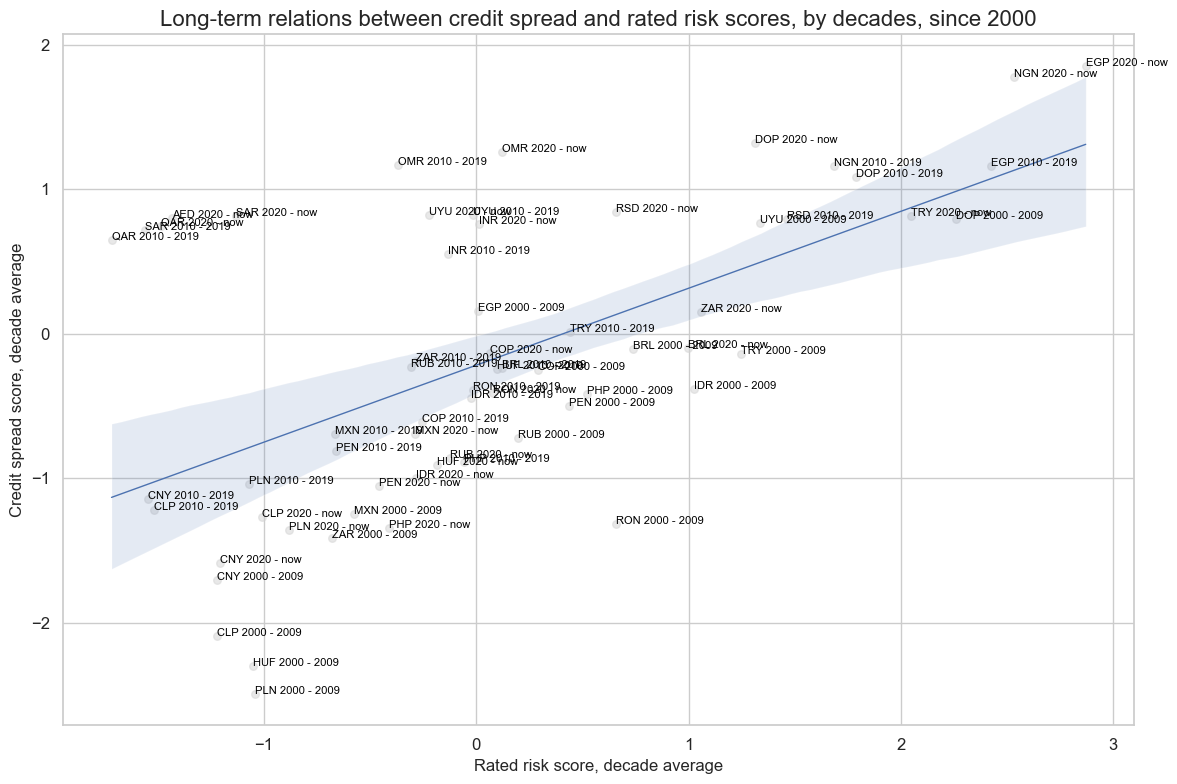
cr.reg_scatter(
labels=True,
label_fontsize=12,
title="Long-term relations between credit spread and rated risk scores, by decades, since 2000",
title_fontsize=16,
xlab="Rated risk score, decade average",
ylab="Credit spread score, decade average",
)
# Long-term macro risk - spread relations
xcatx = ["MACRORISK_EWS_ZN", "CDS05YSPRD_LOG_ZN"]
cidx = cids_fc
cr = msp.CategoryRelations(
dfx,
xcats=xcatx,
cids=cidx,
years=10,
lag=0,
xcat_aggs=["mean", "mean"],
blacklist=black_fc,
start="2000-01-01",
)
cr.reg_scatter(
labels=True,
label_fontsize=12,
title="Long-term relations between composite sovereign risk and credit spread scores, by decades, since 2000",
title_fontsize=16,
xlab=None,
ylab=None,
)
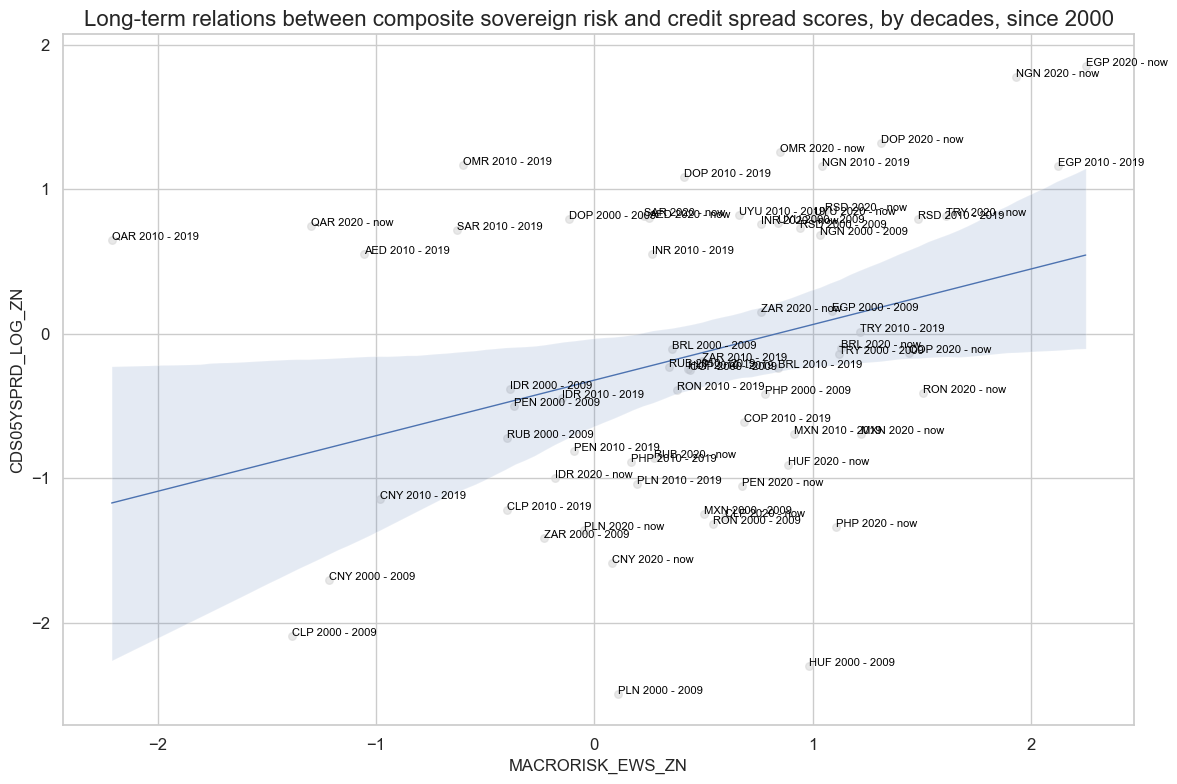
# Long-term macro risk - ratings relations
xcatx = ["MACRORISK_EWS_ZN", "LTFCRATING_INV_ZN"]
cidx = cids_fc
cr = msp.CategoryRelations(
dfx,
xcats=xcatx,
cids=cidx,
years=10,
lag=0,
xcat_aggs=["mean", "mean"],
blacklist=black_fc,
start="2000-01-01",
)
cr.reg_scatter(
labels=True,
label_fontsize=12,
title="Long-term relations between composite sovereign risk and rated risk scores, by decades, since 2000",
title_fontsize=16,
xlab=None,
ylab=None,
)
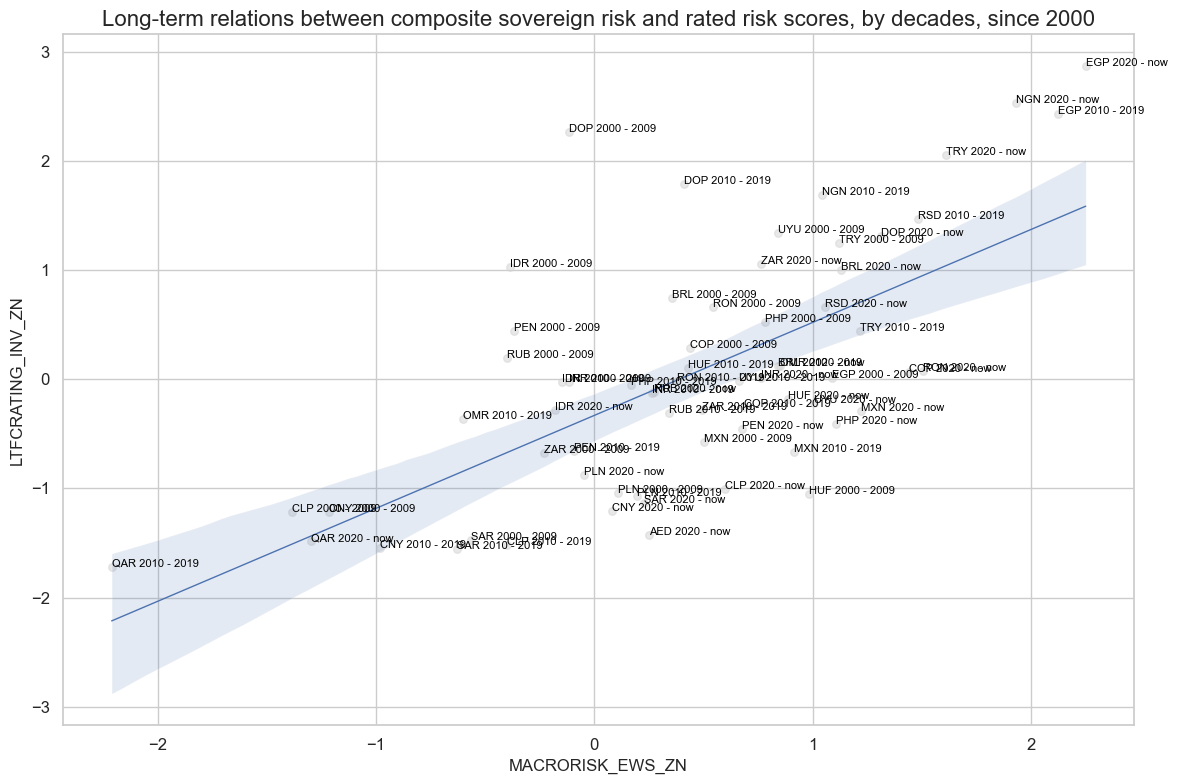
# Long-term macro risk - ratings relations
xcatx = ["MACRORISK_EWS_ZN", "MARKETRISK_ZN"]
cidx = cids_fc
cr = msp.CategoryRelations(
dfx,
xcats=xcatx,
cids=cidx,
years=10,
lag=0,
xcat_aggs=["mean", "mean"],
blacklist=black_fc,
start="2000-01-01",
)
cr.reg_scatter(
labels=True,
label_fontsize=12,
title="EM credit risk: macro risk scores and market risk scores, by decades, 24 sovereigns, since 2000",
title_fontsize=16,
xlab="Sovereign credit-related macro risk score, decade average (as far as available)",
ylab="Market risk score, decade average (as far as available)",
)
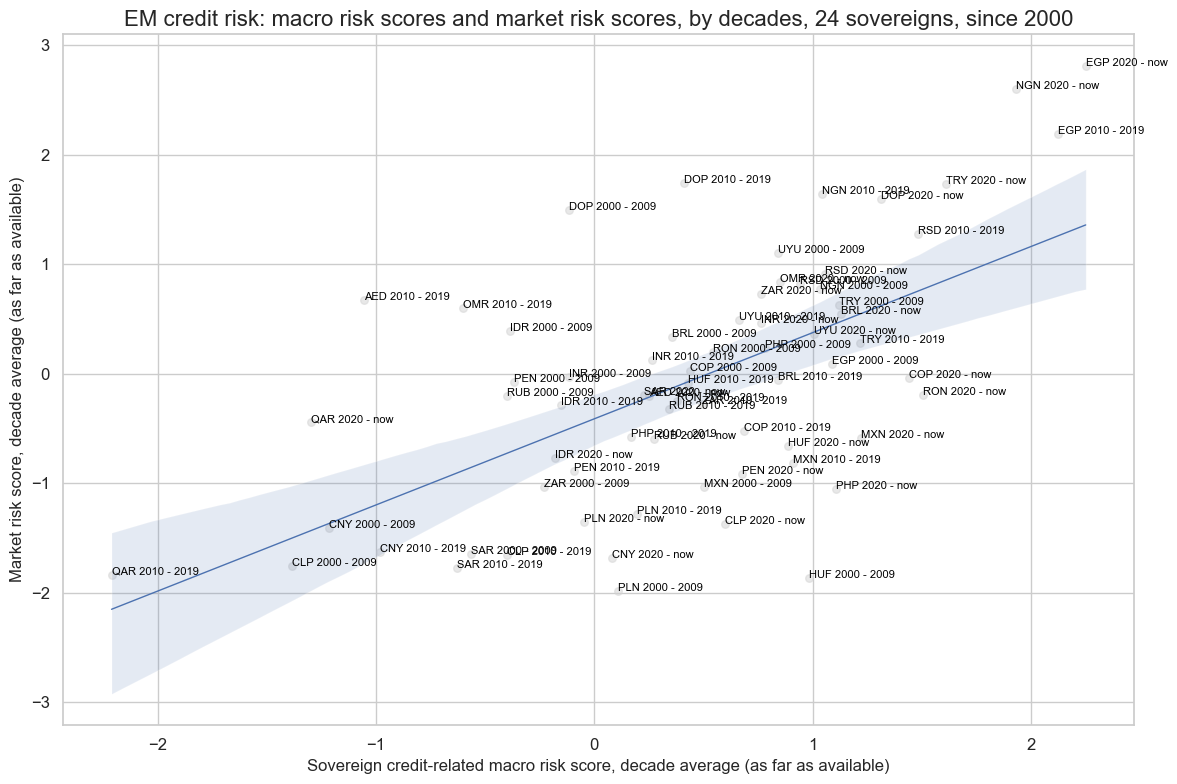
cidx = cids_fc
risks = ["MARKETRISK_ZN", "MACRORISK_EWS_ZN"]
returns = ["FCBIXR_NSA", "FCBIXR_VT10"]
dict_labels["FCBIXR_NSA"] = "Foreign-currency sovereign bond index return, %"
dict_labels["FCBIXR_VT10"] = "Vol-targeted foreign-currency sovereign bond index return, %"
all_relations = []
all_titles = []
for risk in risks:
for ret in returns:
cr = msp.CategoryRelations(
dfx,
xcats=[risk, ret],
cids=cidx,
freq="A",
# years=10,
lag=1,
xcat_aggs=["mean", "sum"],
blacklist=black_fc,
start="2000-01-01",
)
all_relations.append(cr)
risk_label = dict_labels[risk]
ret_label = dict_labels[ret].lower()
all_titles.append(risk_label + " vs. " + ret_label)
msv.multiple_reg_scatter(
cat_rels=all_relations,
title="Annual risk and subsequent return measures for foreign-currency sovereign debt, 24 countries, since 2000",
xlab="Risk score (annual average)",
ylab="Returns, %, next year",
ncol=2,
nrow=2,
figsize=(14, 12),
prob_est="map",
coef_box="lower left",
subplot_titles=all_titles
)
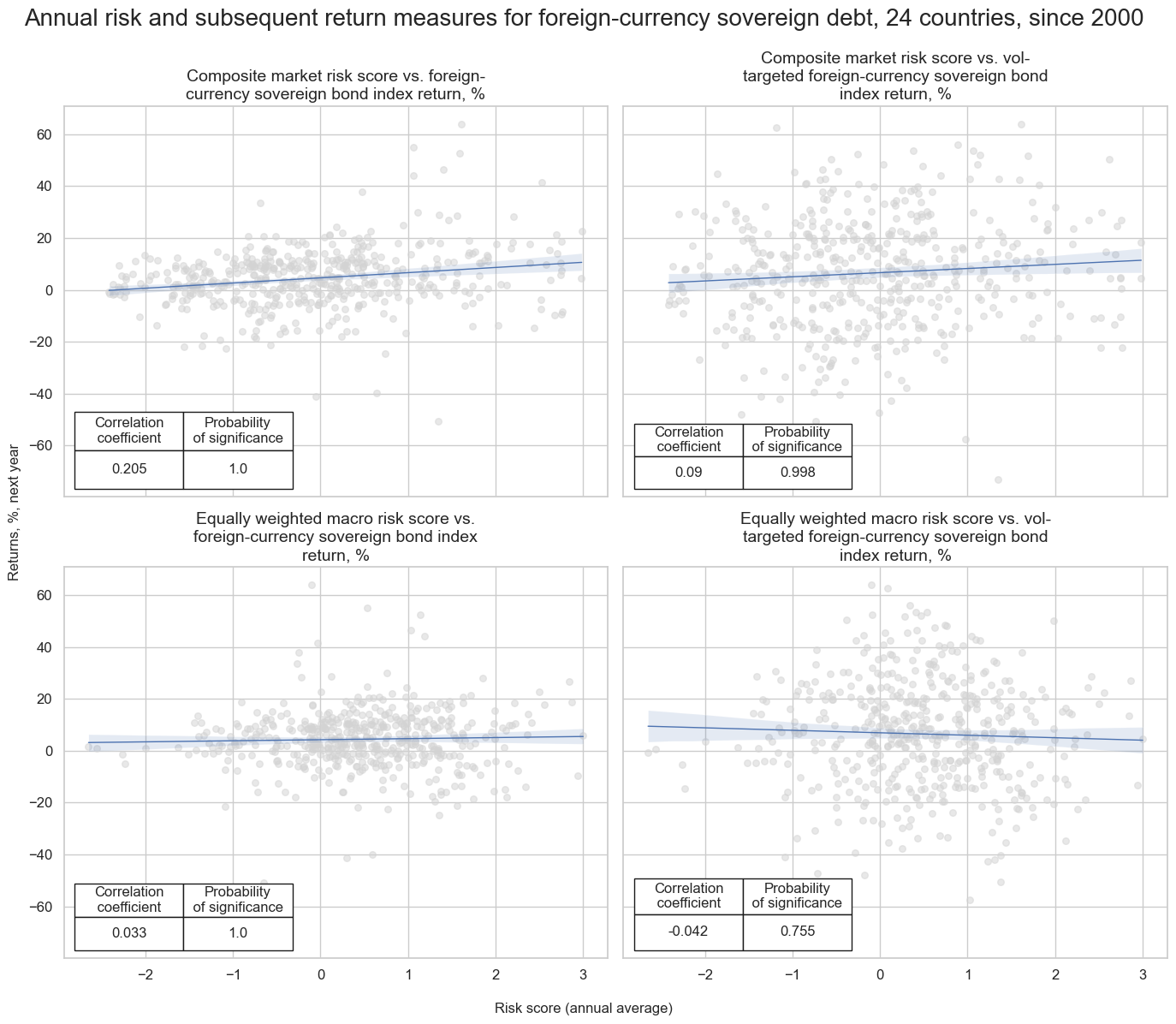
cidx = cids_fc
risks = ["CDS05YSPRD_LOG_ZN", "LTFCRATING_INV_ZN"]
returns = ["FCBIXR_NSA", "FCBIXR_VT10"]
all_relations = []
all_titles = []
for risk in risks:
for ret in returns:
cr = msp.CategoryRelations(
dfx,
xcats=[risk, ret],
cids=cidx,
freq="A",
# years=10,
lag=1,
xcat_aggs=["mean", "sum"],
blacklist=black_fc,
start="2000-01-01",
)
all_relations.append(cr)
all_titles.append(risk + " vs. " + ret)
msv.multiple_reg_scatter(
cat_rels=all_relations,
title=None,
xlab=None,
ylab=None,
ncol=2,
nrow=2,
figsize=(16, 10),
prob_est="map",
coef_box="lower left",
subplot_titles=all_titles
)
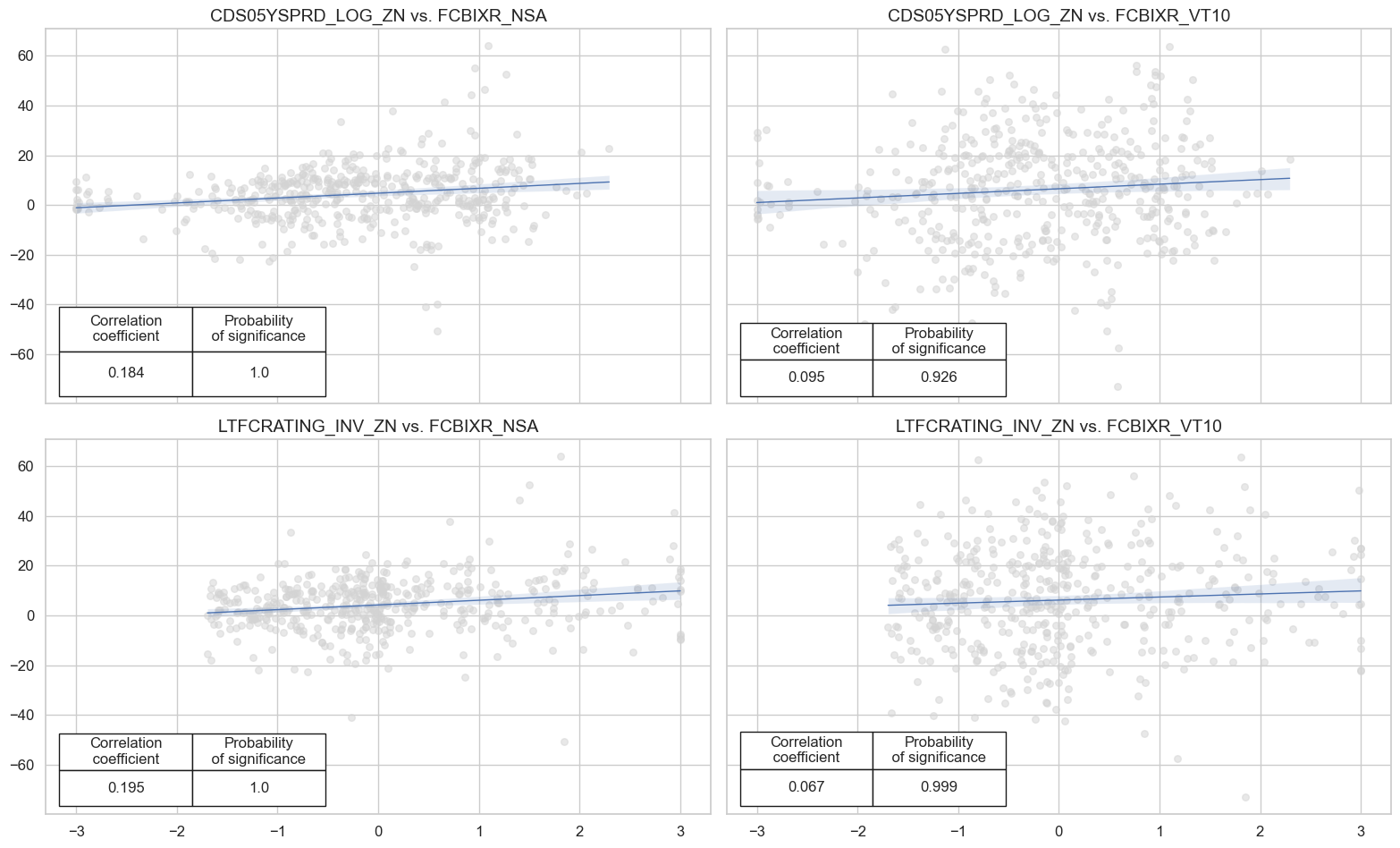
Macro risk premium scores #
Aggregate macro risk premium scores #
# Score differences
cidx = cids_fc
calcs = [
"MACROSPREAD_RPS = CDS05YSPRD_LOG_ZN - MACRORISK_EWS_ZN",
"MACRORATING_RPS = LTFCRATING_INV_ZN - MACRORISK_EWS_ZN",
"MACROALL_RPS = MARKETRISK_ZN - MACRORISK_EWS_ZN",
"MACROSPREAD_RPS_CWS = CDS05YSPRD_LOG_ZN - MACRORISK_CWS_ZN",
"MACRORATING_RPS_CWS = LTFCRATING_INV_ZN - MACRORISK_CWS_ZN",
"MACROALL_RPS_CWS = MARKETRISK_ZN - MACRORISK_CWS_ZN",
]
dfa = msp.panel_calculator(dfx, calcs=calcs, cids=cidx)
dfx = msm.update_df(dfx, dfa)
rps = list(dfa['xcat'].unique())
# Re-z-scoring the risk premium scores
for rp in rps:
dfa = msp.make_zn_scores(
dfx,
xcat=rp,
cids=cidx,
sequential=True,
min_obs=261 * 3,
neutral="zero",
pan_weight=1,
thresh=3,
postfix="_ZN",
est_freq="m",
)
dfx = msm.update_df(dfx, dfa)
dict_labels["MACROSPREAD_RPS_ZN"] = "Spread-based macro risk premium score"
dict_labels["MACRORATING_RPS_ZN"] = "Ratings-based macro risk premium score"
dict_labels["MACROALL_RPS_ZN"] = "Broad macro risk premium score"
dict_labels["MACROSPREAD_RPS_CWS_ZN"] = "Spread-based macro risk premium score, custom weights"
dict_labels["MACRORATING_RPS_CWS_ZN"] = "Ratings-based macro risk premium score, custom weights"
dict_labels["MACROALL_RPS_CWS_ZN"] = "Broad macro risk premium score, custom weights"
rpz = ["MACROSPREAD_RPS_ZN", "MACRORATING_RPS_ZN", "MACROALL_RPS_ZN"]
xrpz = rpz + [rp[:-3] + "_CWS_ZN" for rp in rpz]
xcatx = rpz
cidx = cids_fc
sdate = "2000-01-01"
msp.view_ranges(
dfx,
xcats=xcatx,
kind="bar",
sort_cids_by=None,
start=sdate,
xcat_labels=dict_labels,
)
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=4,
start=sdate,
same_y=True,
aspect=2,
xcat_labels=dict_labels,
title="Sovereign-credit-related macro risk premium scores (higher score means higher premium)",
title_fontsize=25,
legend_fontsize=16,
height=2,
)
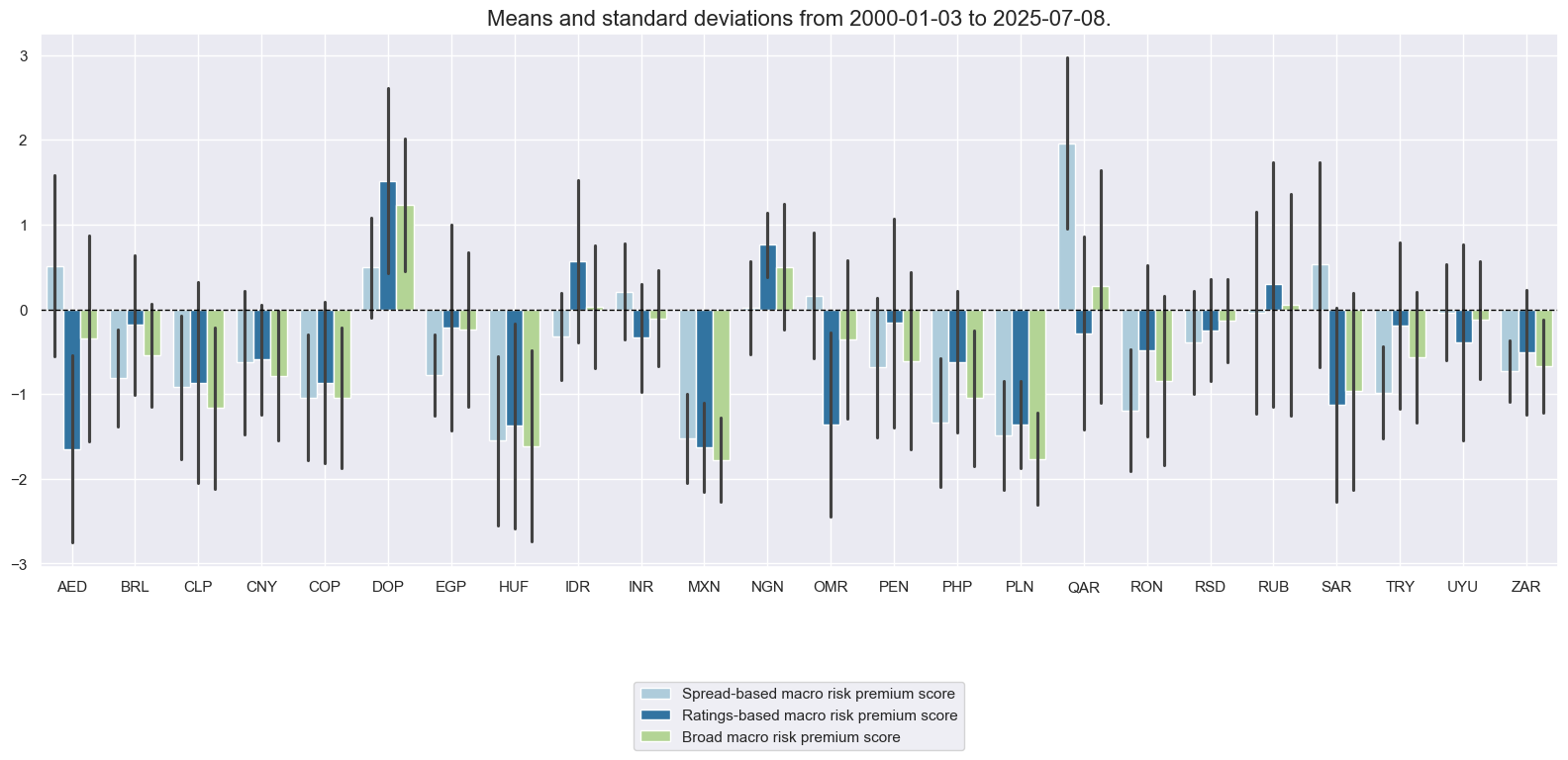
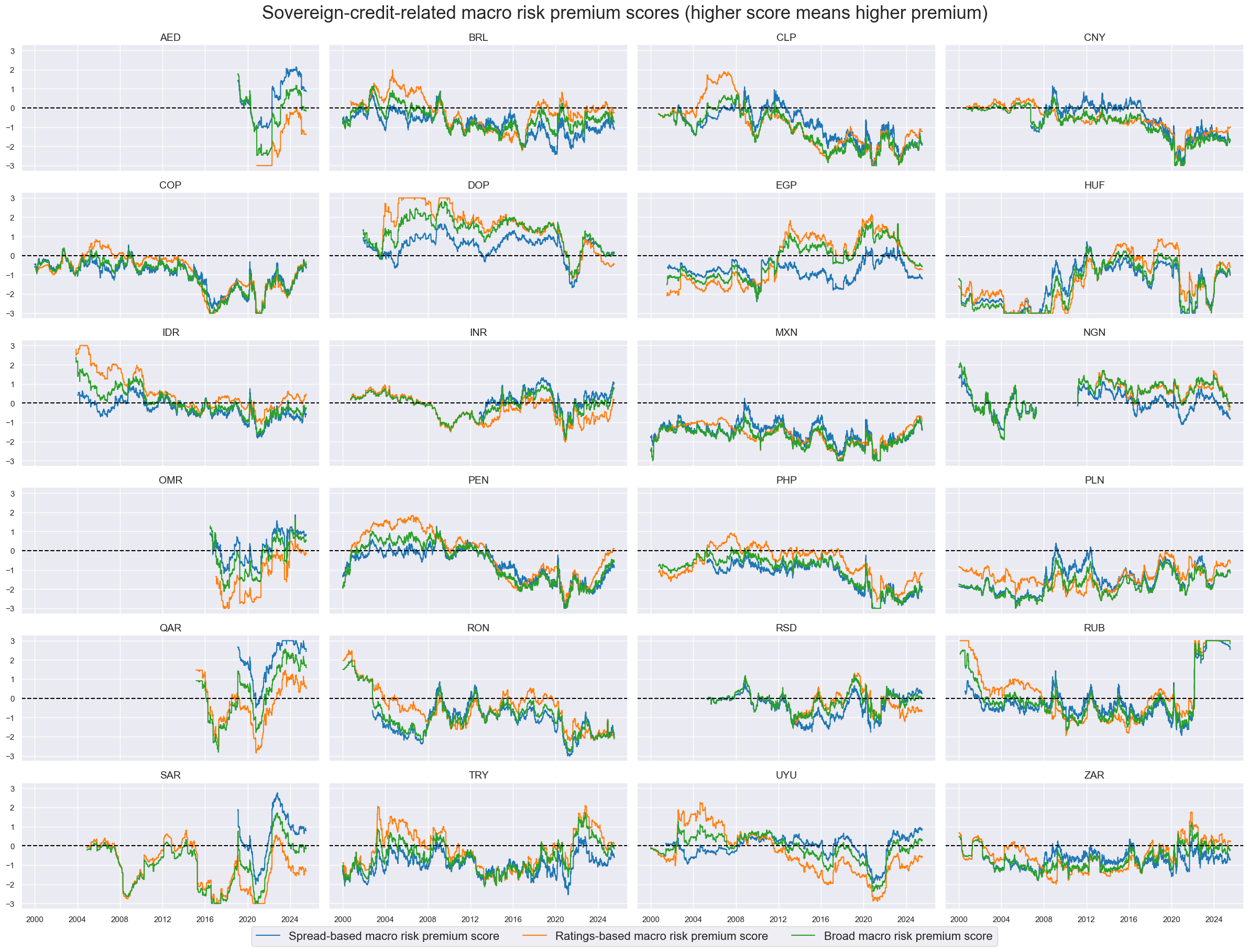
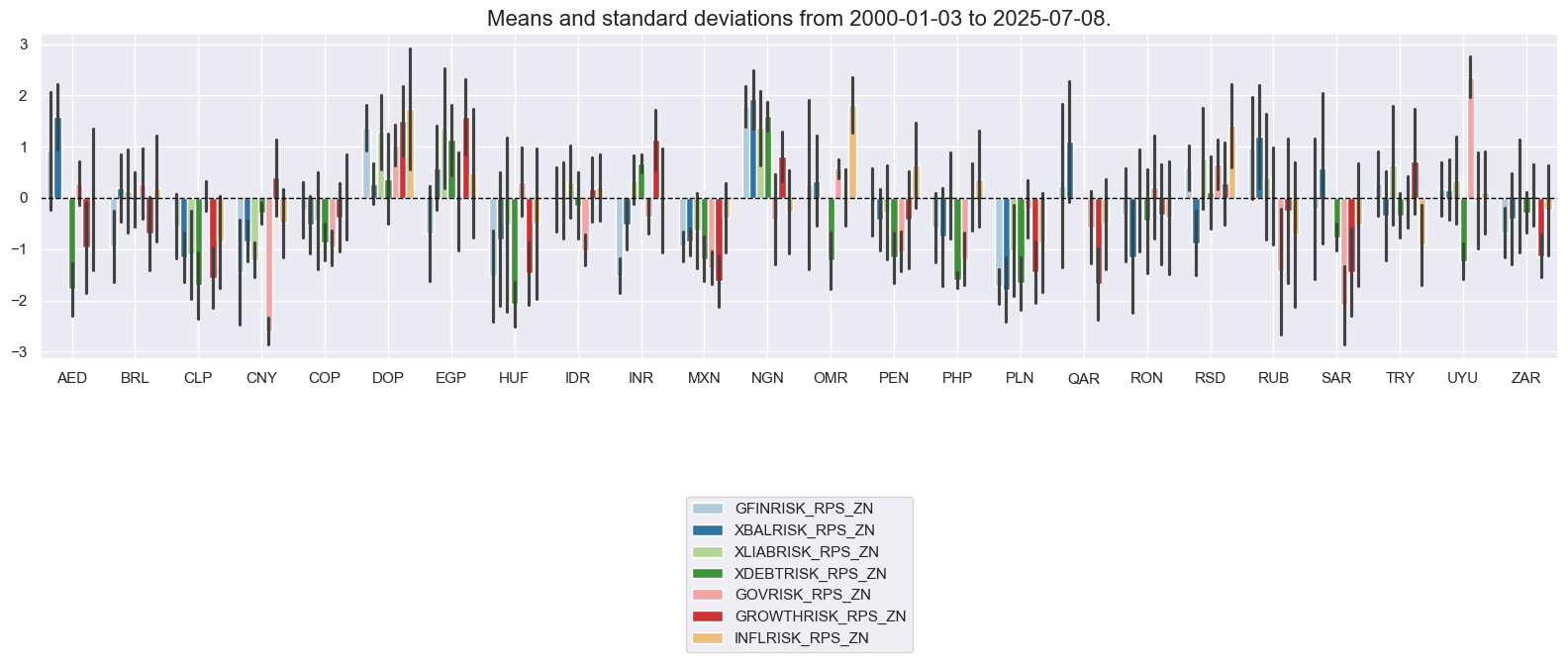
Conceptual macro risk premium scores #
# Conceptual risk premium scores
calcs = []
for macro in macroz:
calcs += f"{macro[:-3]}_RPS = MARKETRISK_ZN - {macro}",
dfa = msp.panel_calculator(dfx, calcs=calcs, cids=cidx)
dfx = msm.update_df(dfx, dfa)
crps = list(dfa['xcat'].unique())
# Re-z-scoring conceptual risk premium scores
for crp in crps:
dfa = msp.make_zn_scores(
dfx,
xcat=crp,
cids=cidx,
sequential=True,
min_obs=261 * 3,
neutral="zero",
pan_weight=1,
thresh=3,
postfix="_ZN",
est_freq="m",
)
dfx = msm.update_df(dfx, dfa)
crpz = [crp + "_ZN" for crp in crps]
xcatx = crpz
cidx = cids_fc
sdate = "2000-01-01"
msp.view_ranges(
dfx,
xcats=xcatx,
kind="bar",
sort_cids_by=None,
start=sdate,
# xcat_labels=dict_labels,
)
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=4,
start=sdate,
same_y=True,
aspect=2,
# xcat_labels=dict_labels,
title=None,
title_fontsize=22,
legend_fontsize=16,
height=2,
)
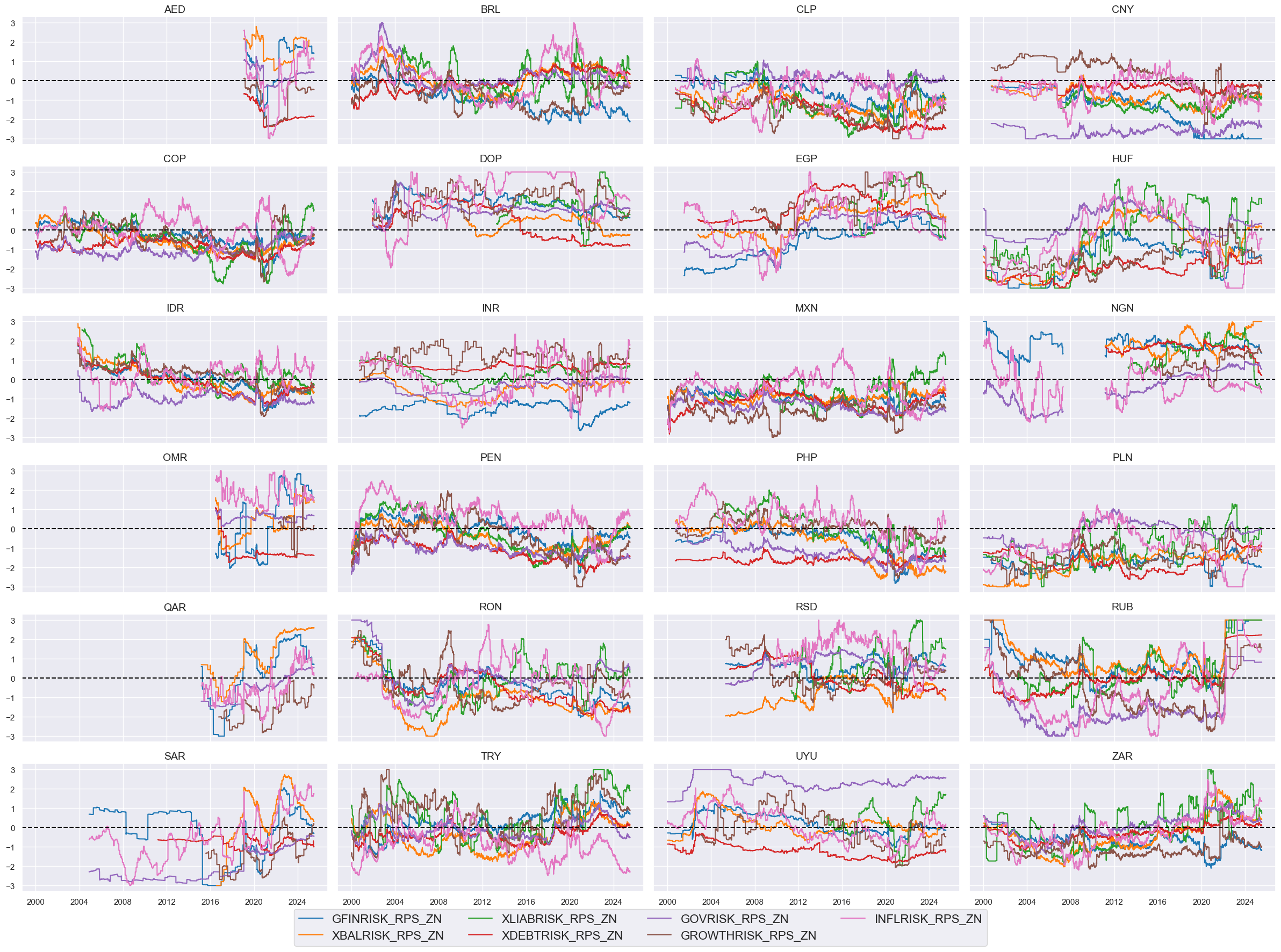
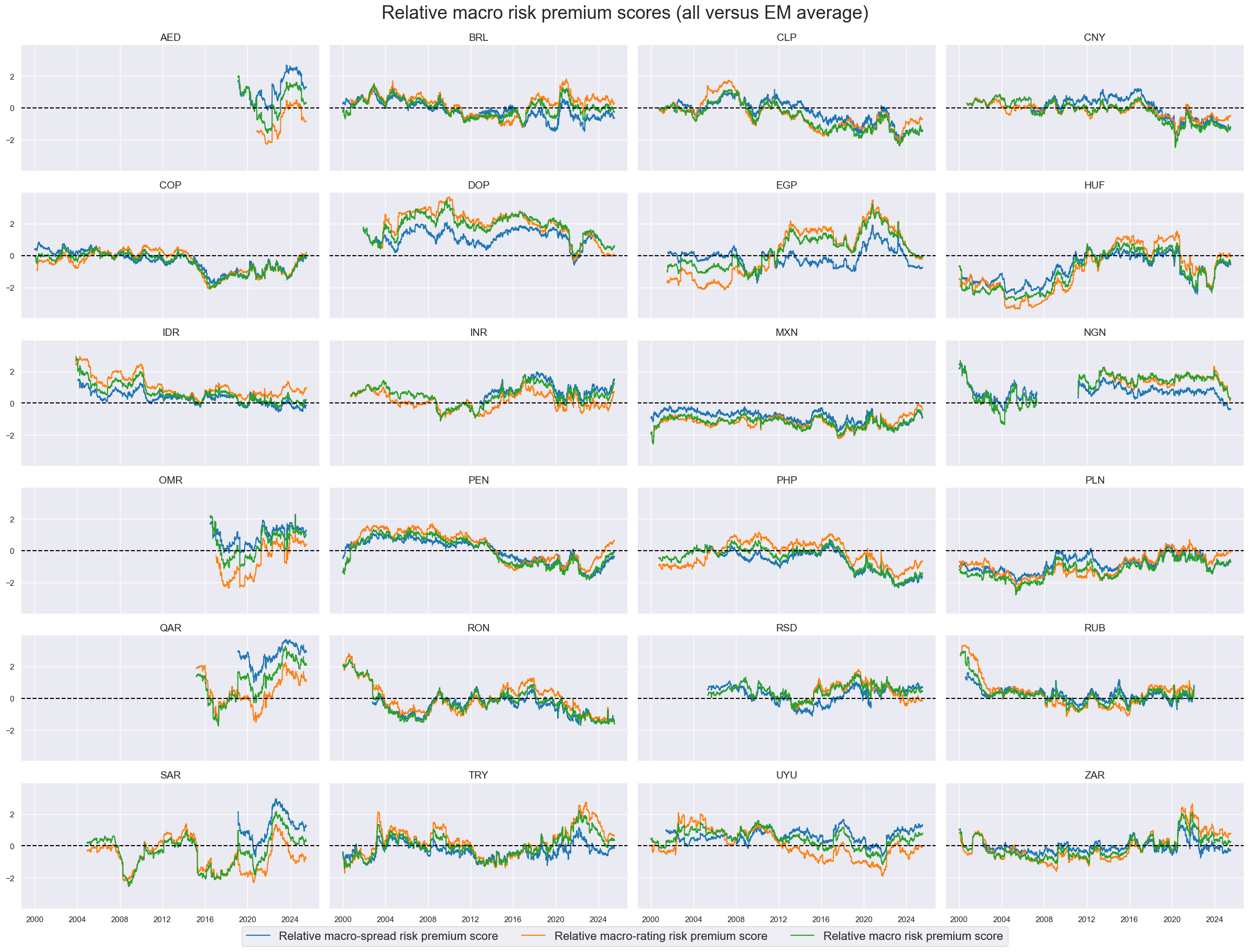
Relative aggregate macro risk premium scores #
cidx = cids_fc
xcatx = xrpz + ["MARKETRISK_ZN", "FCBIXR_NSA", "FCBIXR_VT10"]
dfa = msp.make_relative_value(
df = dfx,
xcats = xcatx,
cids = cidx,
start="2000-01-01",
blacklist=black_fc,
postfix="vEM",
)
dfx = msm.update_df(dfx, dfa)
xrpzr = [xcat + "vEM" for xcat in xrpz]
dict_labels["MACROSPREAD_RPS_ZNvEM"] = "Relative macro-spread risk premium score"
dict_labels["MACRORATING_RPS_ZNvEM"] = "Relative macro-rating risk premium score"
dict_labels["MACROALL_RPS_ZNvEM"] = "Relative macro risk premium score"
dict_labels["MARKETRISK_ZNvEM"] = "Relative market risk score"
dict_labels["MACROSPREAD_RPS_CWS_ZNvEM"] = "Relative macro-spread risk premium score, custom weights"
dict_labels["MACRORATING_RPS_CWS_ZNvEM"] = "Relative macro-rating risk premium score, custom weights"
dict_labels["MACROALL_RPS_CWS_ZNvEM"] = "Relative macro risk premium score, custom weights"
cidx = cids_fc
xcatx = [rp + "vEM" for rp in rpz]
sdate = "2000-01-01"
msp.view_ranges(
dfx,
xcats=xcatx,
kind="bar",
sort_cids_by=None,
start=sdate,
xcat_labels=dict_labels,
)
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=4,
start=sdate,
same_y=True,
aspect=2,
xcat_labels=dict_labels,
title="Relative macro risk premium scores (all versus EM average)",
title_fontsize=25,
legend_fontsize=16,
height=2,
)
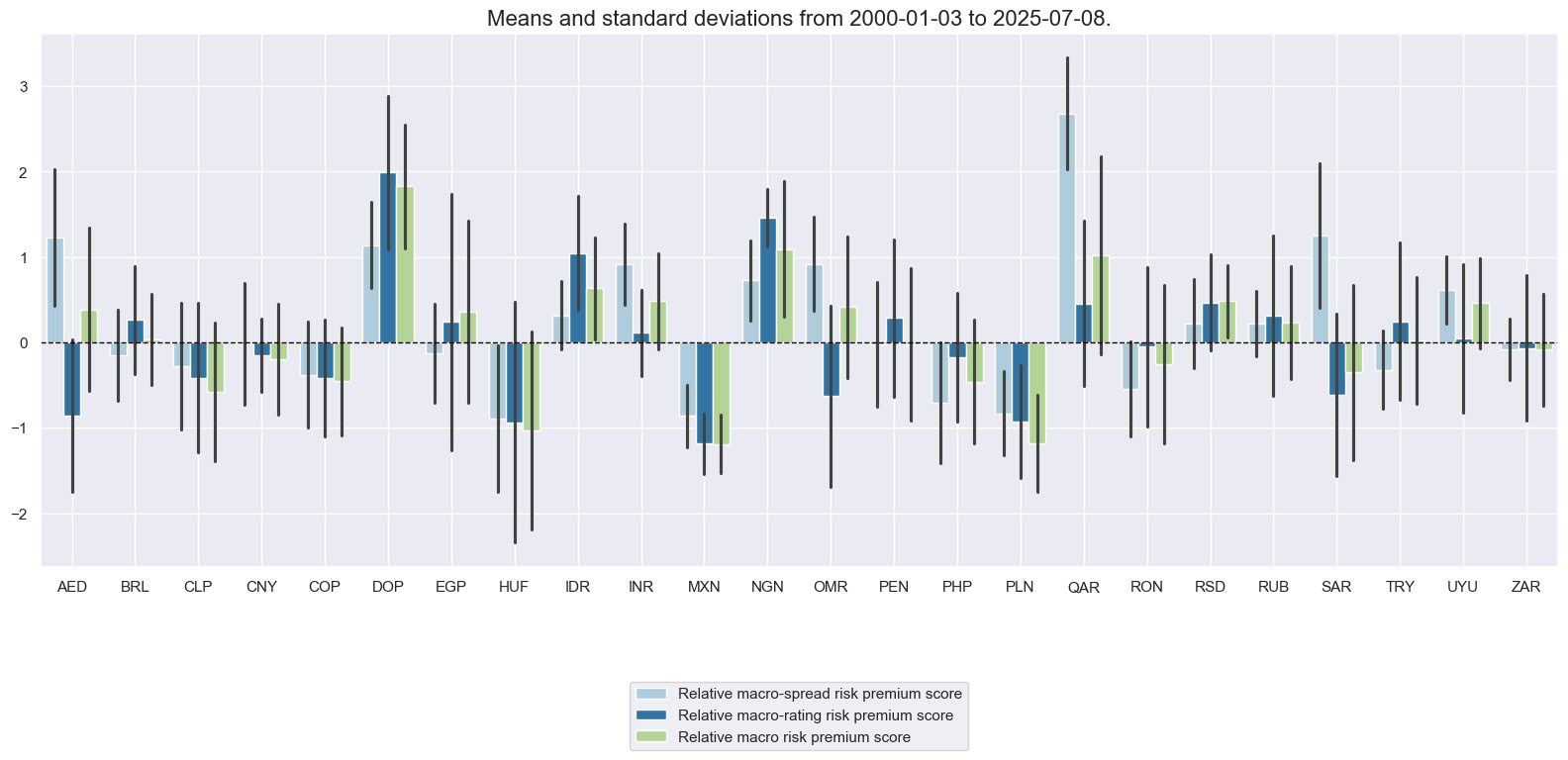
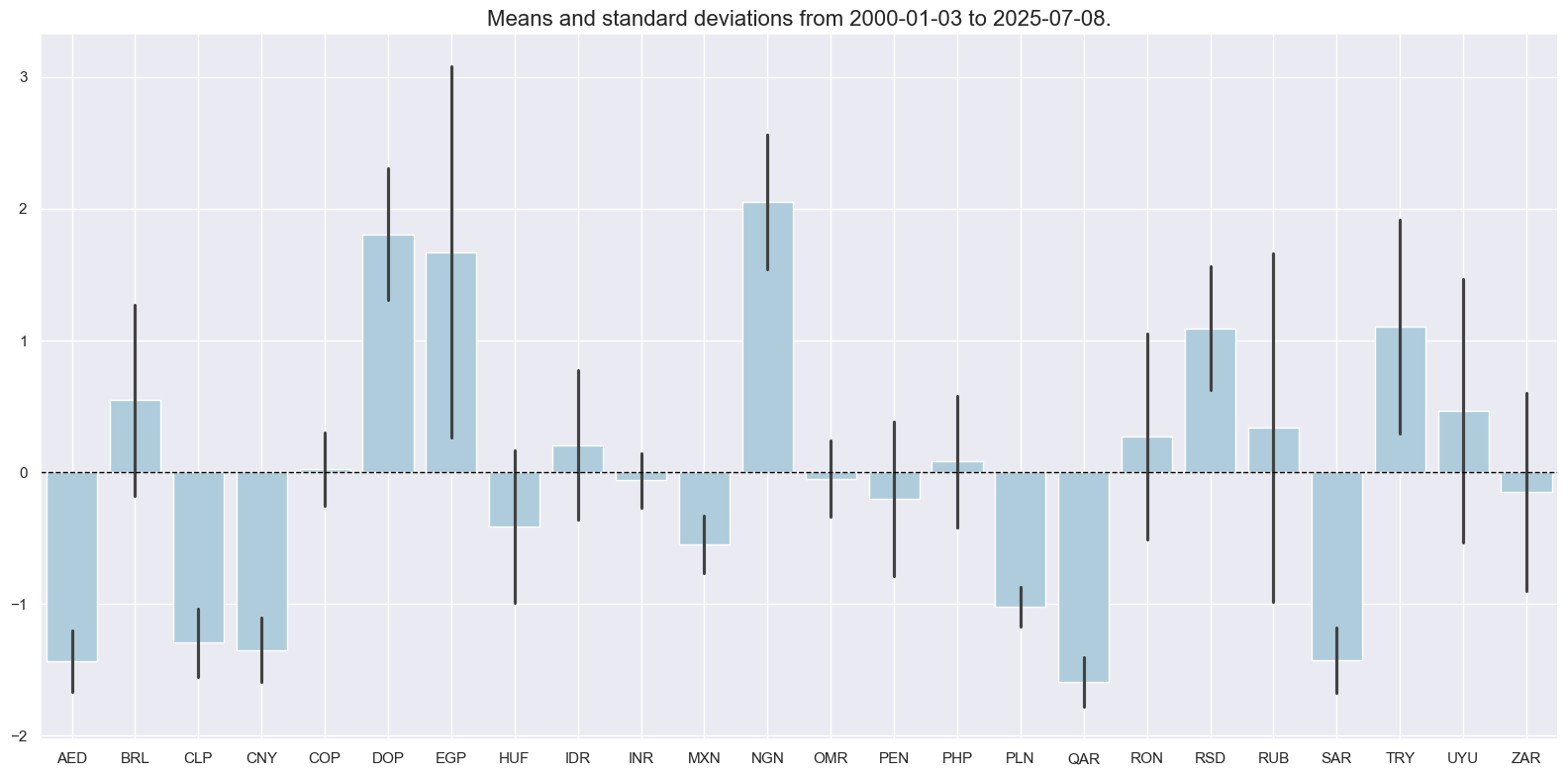
cidx = cids_fc
xcatx = ["LTFCRATING_INV_ZN"]
sdate = "2000-01-01"
msp.view_ranges(
dfx,
xcats=xcatx,
kind="bar",
sort_cids_by=None,
start=sdate,
)
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=4,
start=sdate,
same_y=True,
aspect=2,
title=None,
title_fontsize=22,
legend_fontsize=16,
height=2,
)
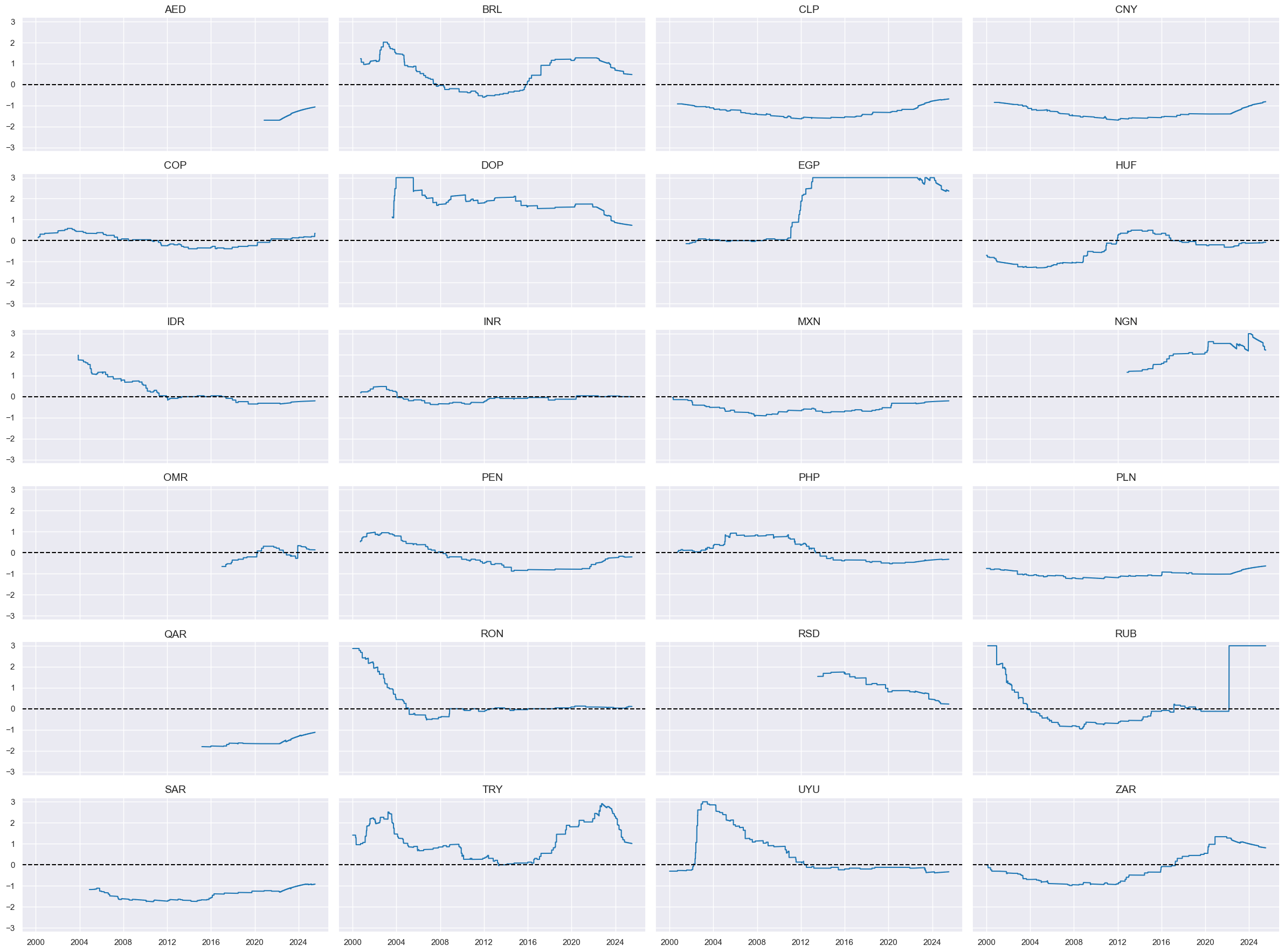
Value checks #
Composite directional signals #
Specs and panel test #
dict_dir = {
"sigs": ['MACROSPREAD_RPS_ZN','MACRORATING_RPS_ZN', 'MACROALL_RPS_ZN', 'MARKETRISK_ZN'],
"targs": ["FCBIXR_VT10", "FCBIXR_NSA"],
"cidx": cids_fc,
"start": "2000-01-01",
"black": black_fc,
}
dix = dict_dir
sigs = dix['sigs']
ret = dix["targs"][0]
cidx = dix["cidx"]
start = dix["start"]
black = dix["black"]
catregs = {}
for sig in sigs:
catregs[sig] = msp.CategoryRelations(
dfx,
xcats=[sig, ret],
cids=cidx,
freq="Q",
lag=1,
xcat_aggs=["last", "sum"],
start=start,
blacklist=black,
)
msv.multiple_reg_scatter(
cat_rels=[v for k, v in catregs.items()],
ncol=2,
nrow=2,
figsize=(14, 12),
title="Risk scores and subsequent foreign currency bond index excess returns, 24 countries since 2000",
title_fontsize=20,
xlab="End-of-quarter score",
ylab="Foreign currency bond index excess returns, vol targeted, %, next quarter",
coef_box="lower right",
prob_est="map",
single_chart=True,
subplot_titles=[dict_labels[key] for key in sigs]
)
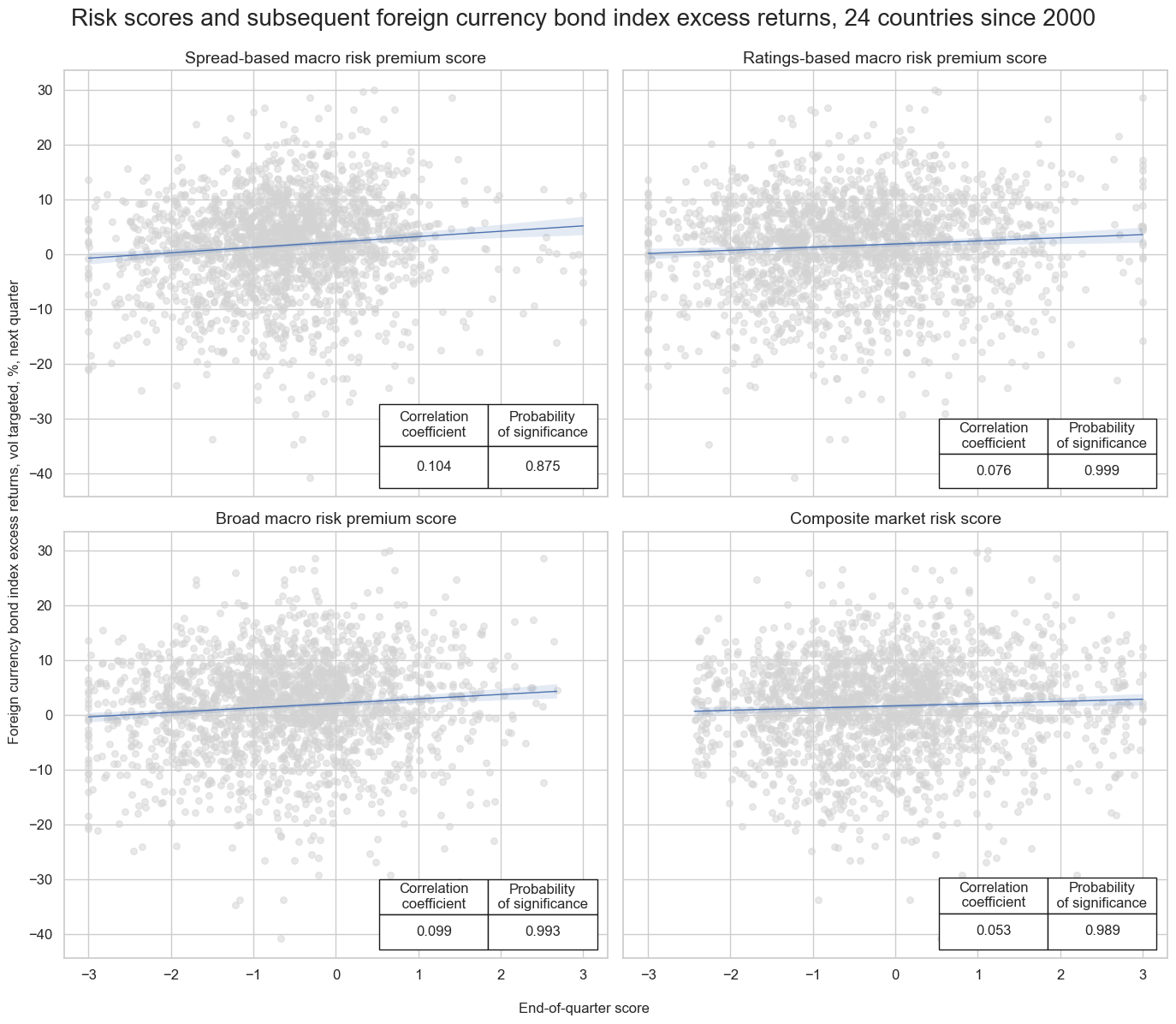
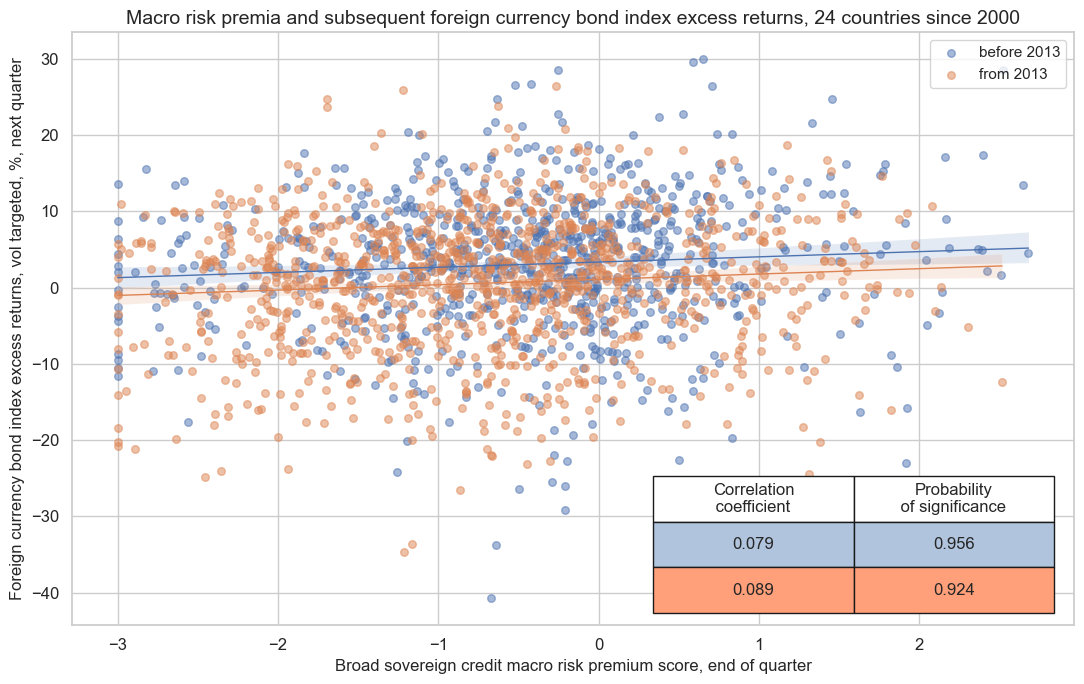
dix = dict_dir
sig = dix["sigs"][2]
ret = dix["targs"][0]
cidx = dix["cidx"]
start = dix["start"]
black = dix["black"]
cr = msp.CategoryRelations(
dfx,
xcats=[sig, ret],
cids=cidx,
freq="Q",
years=None,
lag=1,
xcat_aggs=["last", "sum"], # period mean adds stability
start=start,
blacklist=black,
)
cr.reg_scatter(
title="Macro risk premia and subsequent foreign currency bond index excess returns, 24 countries since 2000",
labels=False,
xlab="Broad sovereign credit macro risk premium score, end of quarter",
ylab="Foreign currency bond index excess returns, vol targeted, %, next quarter",
coef_box="lower right",
prob_est="map",
separator=2013,
size=(11, 7),
)
cr.reg_scatter(
title="Macro risk premia and subsequent foreign currency bond index excess returns, 24 countries since 2000",
labels=False,
xlab=None,
ylab=None,
coef_box="lower right",
prob_est="pool",
separator="cids",
)
Accuracy and correlation check #
dix = dict_dir
sigs = dix['sigs']
ret = dix["targs"][0]
cidx = dix["cidx"]
start = dix["start"]
black = dix["black"]
srr = mss.SignalReturnRelations(
dfx,
rets=ret,
cids=cidx,
sigs=sigs,
# cosp=True,
freqs="M",
agg_sigs=["last"], # for stability
start=start,
)
dix["srr"] = srr
dix = dict_dir
srr = dix["srr"]
tbl=srr.multiple_relations_table().round(3)
display(tbl.transpose())
| Return | FCBIXR_VT10 | |||
|---|---|---|---|---|
| Signal | MACROALL_RPS_ZN | MACRORATING_RPS_ZN | MACROSPREAD_RPS_ZN | MARKETRISK_ZN |
| Frequency | M | M | M | M |
| Aggregation | last | last | last | last |
| accuracy | 0.465 | 0.474 | 0.452 | 0.502 |
| bal_accuracy | 0.515 | 0.511 | 0.511 | 0.510 |
| pos_sigr | 0.282 | 0.336 | 0.239 | 0.462 |
| pos_retr | 0.609 | 0.607 | 0.607 | 0.608 |
| pos_prec | 0.630 | 0.621 | 0.624 | 0.619 |
| neg_prec | 0.400 | 0.400 | 0.398 | 0.401 |
| pearson | 0.042 | 0.035 | 0.040 | 0.020 |
| pearson_pval | 0.001 | 0.009 | 0.003 | 0.122 |
| kendall | 0.038 | 0.028 | 0.045 | 0.025 |
| kendall_pval | 0.000 | 0.002 | 0.000 | 0.004 |
| auc | 0.513 | 0.510 | 0.508 | 0.511 |
dix = dict_dir
srr = dix["srr"]
srr.accuracy_bars(type='cross_section', sigs="MACROALL_RPS_ZN", size=(16, 4))
srr.accuracy_bars(type='signals', size=(16, 4))
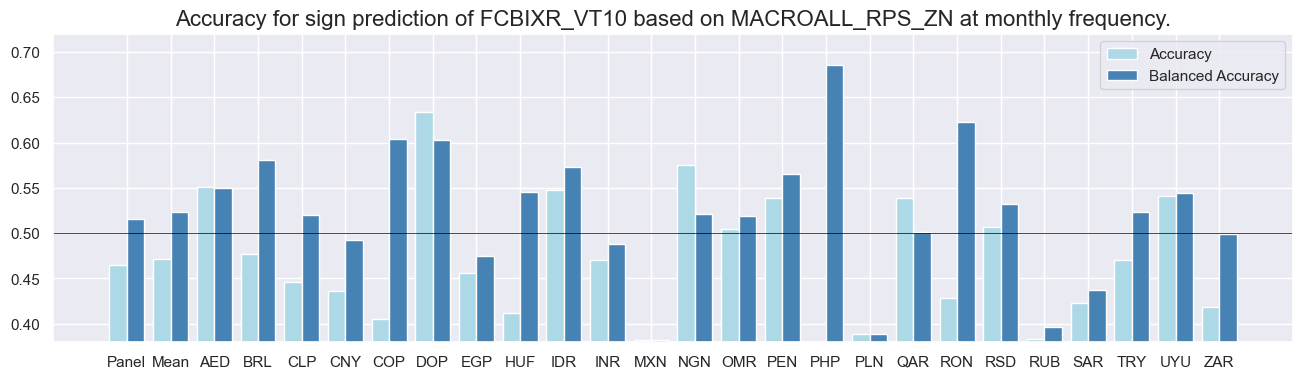
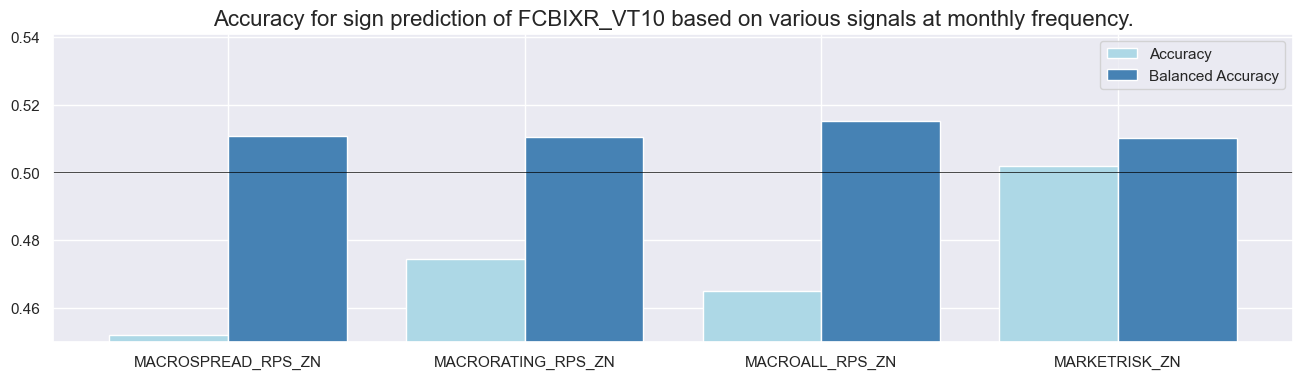
dix = dict_dir
srr = dix["srr"]
srr.correlation_bars(type='cross_section', sigs="MACROALL_RPS_ZN", size=(16, 4))
srr.correlation_bars(type='signals', size=(16, 4))
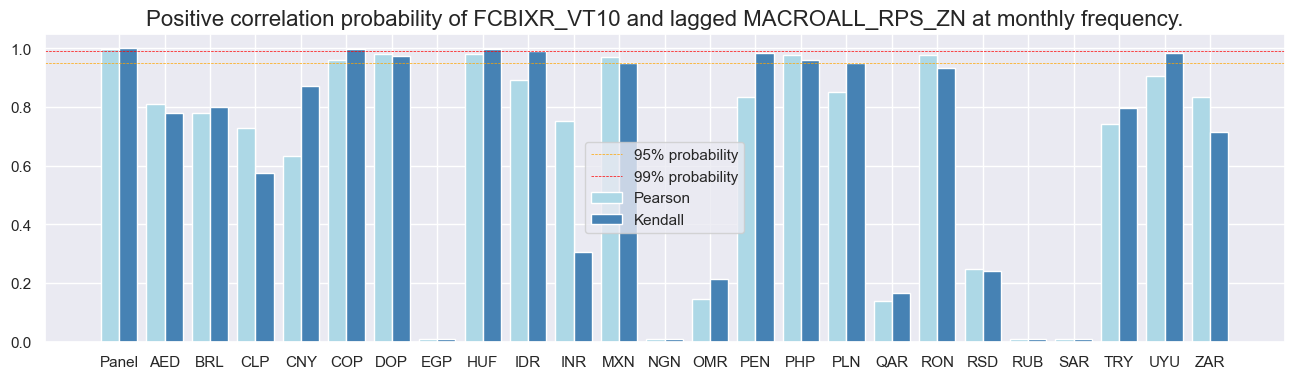
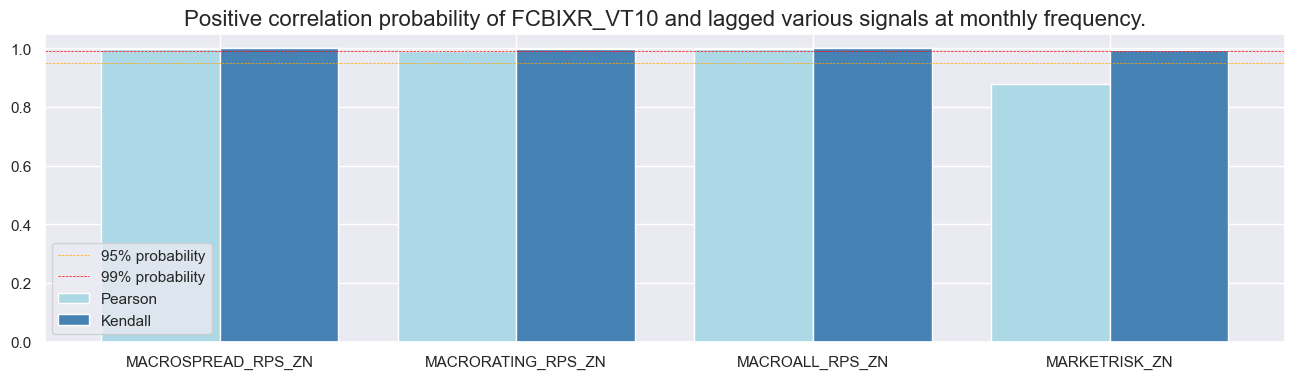
Naive PnLs #
dix = dict_dir
sigs = dix['sigs']
ret = dix["targs"][0]
cidx = dix["cidx"]
start = dix["start"]
black = dix["black"]
rt = ret.split('_')[-1] # 'NSA' or 'VT10'
pnls = msn.NaivePnL(
df=dfx,
ret=ret,
sigs=sigs,
cids=cidx,
start=start,
blacklist=black,
bms=bms,
)
for sig in sigs:
for bias in [0, 1]:
pnls.make_pnl(
sig=sig,
sig_op="zn_score_pan",
thresh=2,
sig_add = bias,
rebal_freq="monthly",
neutral="zero",
pnl_name=sig + "_PNL" + rt + str(bias),
rebal_slip=1,
vol_scale=10,
)
pnls.make_long_pnl(vol_scale=10, label="Long only")
dix["pnls_"+rt.lower()] = pnls
dix = dict_dir
rt = "VT10"
bias = 1
pnls = dix["pnls_"+rt.lower()]
sigs = ["MACROALL_RPS_ZN", "MARKETRISK_ZN"]
strats = [sig + "_PNL" + rt + str(bias) for sig in sigs]
pnl_labels = {
"MACROALL_RPS_ZN_PNL" + rt + str(bias): "Macro risk premium score with long bias",
"MARKETRISK_ZN_PNL" + rt + str(bias): "Market risk score with long bias",
"Long only": "Long only risk parity",
}
pnls.plot_pnls(
title="Naive PnL for risk-premia and benchmark strategies, 24 EM sovereigns, vol-targeted positions",
pnl_cats=strats + ["Long only"],
xcat_labels=pnl_labels,
title_fontsize=14,
)
display(pnls.evaluate_pnls(pnl_cats=strats + ["Long only"]).round(3))
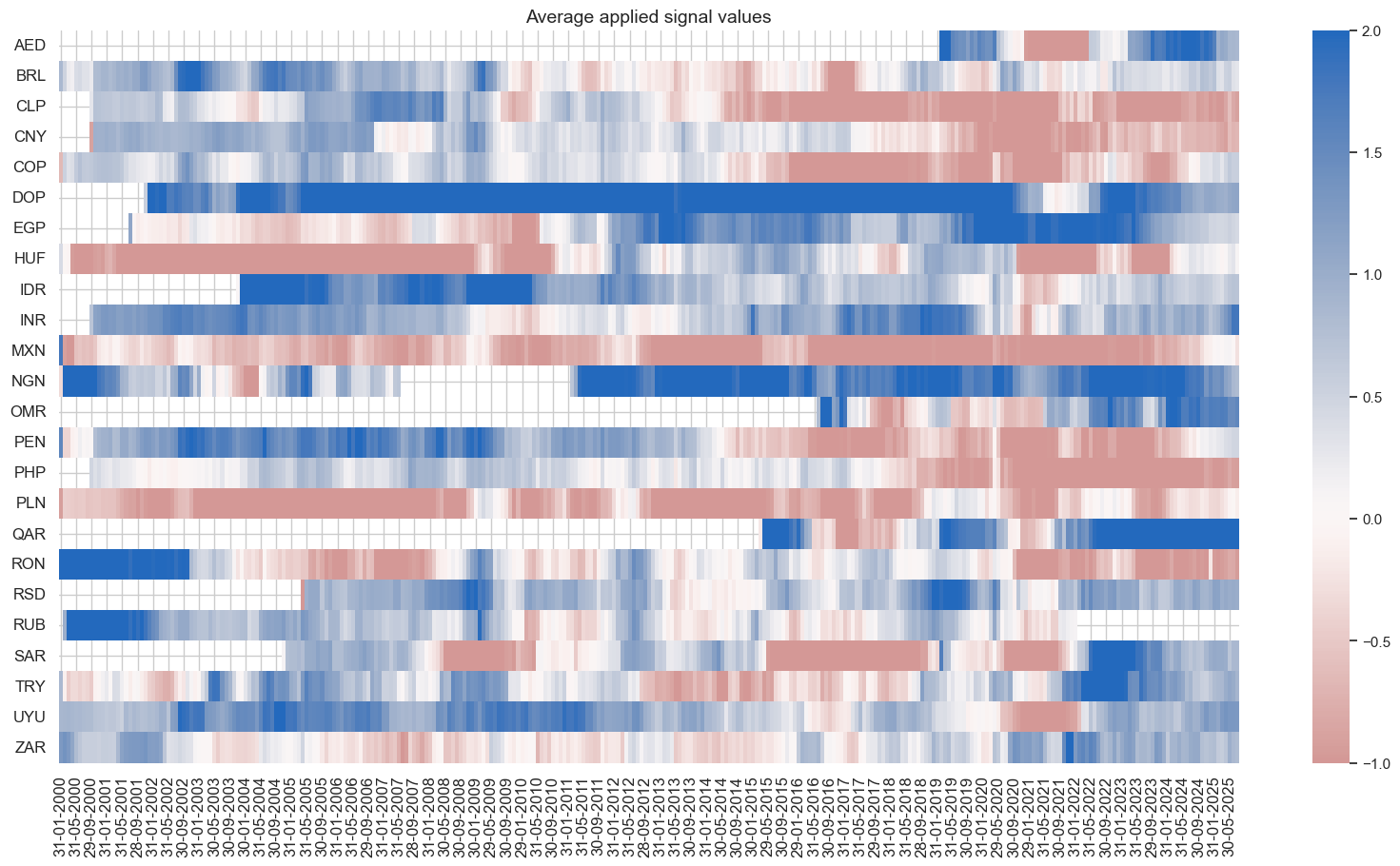
pnls.signal_heatmap(pnl_name=f"MACROALL_RPS_ZN_PNL" + rt + str(bias), figsize=(20, 10))
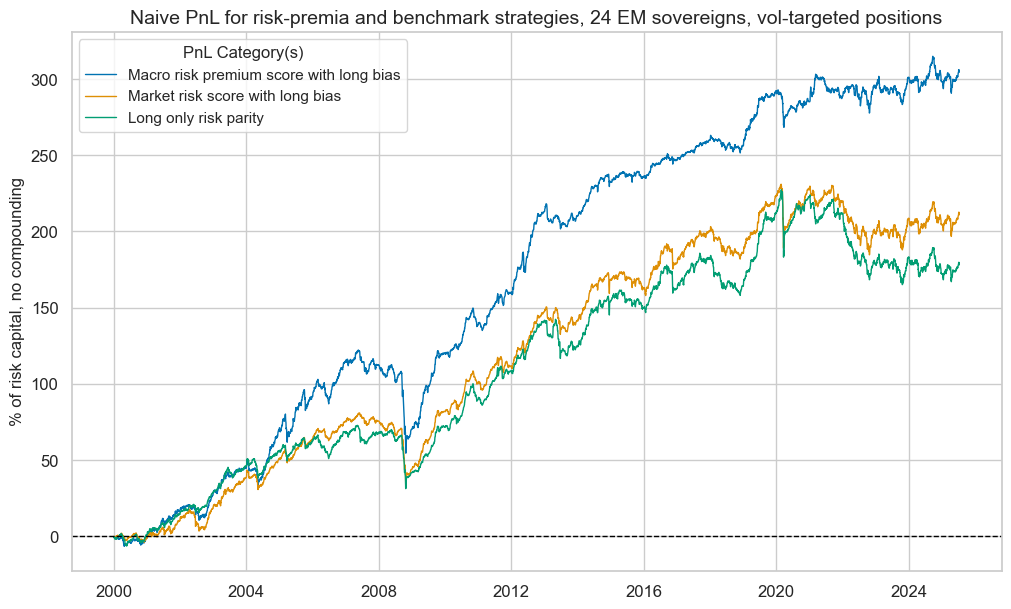
| xcat | MACROALL_RPS_ZN_PNLVT101 | MARKETRISK_ZN_PNLVT101 | Long only |
|---|---|---|---|
| Return % | 11.941121 | 8.271644 | 6.981771 |
| St. Dev. % | 10.0 | 10.0 | 10.0 |
| Sharpe Ratio | 1.194112 | 0.827164 | 0.698177 |
| Sortino Ratio | 1.666455 | 1.107006 | 0.919443 |
| Max 21-Day Draw % | -39.285979 | -41.389511 | -42.691756 |
| Max 6-Month Draw % | -57.287173 | -41.888409 | -37.994155 |
| Peak to Trough Draw % | -67.584771 | -48.767977 | -62.284802 |
| Top 5% Monthly PnL Share | 0.491087 | 0.626005 | 0.765992 |
| USD_EQXR_NSA correl | 0.216796 | 0.293771 | 0.214621 |
| UHY_CRXR_NSA correl | 0.262238 | 0.350945 | 0.273707 |
| UIG_CRXR_NSA correl | 0.257687 | 0.332166 | 0.253349 |
| Traded Months | 307 | 307 | 307 |
dix = dict_dir
sigs = dix['sigs']
ret = dix["targs"][1]
cidx = dix["cidx"]
start = dix["start"]
black = dix["black"]
rt = ret.split('_')[-1] # 'NSA' or 'VT10'
pnls = msn.NaivePnL(
df=dfx,
ret=ret,
sigs=sigs,
cids=cidx,
start=start,
blacklist=black,
bms=bms,
)
for sig in sigs:
for bias in [0, 1]:
pnls.make_pnl(
sig=sig,
sig_op="zn_score_pan",
thresh=2,
sig_add = bias,
rebal_freq="monthly",
neutral="zero",
pnl_name=sig + "_PNL" + rt + str(bias),
rebal_slip=1,
vol_scale=10,
)
pnls.make_long_pnl(vol_scale=10, label="Long only")
dix["pnls_"+rt.lower()] = pnls
dix = dict_dir
rt = "NSA"
bias = 1
pnls = dix["pnls_"+rt.lower()]
sigs = ["MACROALL_RPS_ZN", "MARKETRISK_ZN"]
strats = [sig + "_PNL" + rt + str(bias) for sig in sigs]
pnl_labels = {
"MACROALL_RPS_ZN_PNL" + rt + str(bias): "Macro risk premium score with long bias",
"MARKETRISK_ZN_PNL" + rt + str(bias): "Market risk score with long bias",
"Long only": "Long only risk parity",
}
pnls.plot_pnls(
title="Naive PnL for risk-premia and benchmark strategies, 24 EM sovereigns, nominal positions",
pnl_cats=strats + ["Long only"],
xcat_labels=pnl_labels,
title_fontsize=14,
)
display(pnls.evaluate_pnls(pnl_cats=strats + ["Long only"]).round(3))
pnls.signal_heatmap(pnl_name=f"MACROALL_RPS_ZN_PNL" + rt + str(bias), figsize=(20, 10))
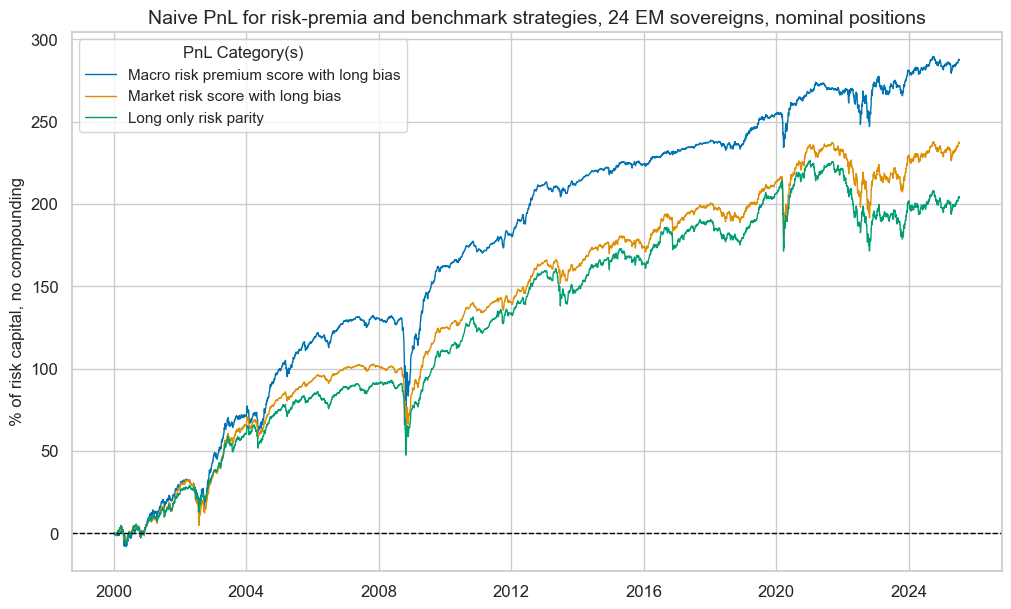
| xcat | MACROALL_RPS_ZN_PNLNSA1 | MARKETRISK_ZN_PNLNSA1 | Long only |
|---|---|---|---|
| Return % | 11.258397 | 9.279441 | 7.977636 |
| St. Dev. % | 10.0 | 10.0 | 10.0 |
| Sharpe Ratio | 1.12584 | 0.927944 | 0.797764 |
| Sortino Ratio | 1.607187 | 1.288616 | 1.076272 |
| Max 21-Day Draw % | -50.833232 | -37.448958 | -40.894491 |
| Max 6-Month Draw % | -58.256379 | -42.61806 | -44.780838 |
| Peak to Trough Draw % | -58.842786 | -45.719661 | -55.016014 |
| Top 5% Monthly PnL Share | 0.570361 | 0.620995 | 0.643287 |
| USD_EQXR_NSA correl | 0.247415 | 0.308574 | 0.270703 |
| UHY_CRXR_NSA correl | 0.304648 | 0.37899 | 0.343767 |
| UIG_CRXR_NSA correl | 0.332373 | 0.376858 | 0.330674 |
| Traded Months | 307 | 307 | 307 |
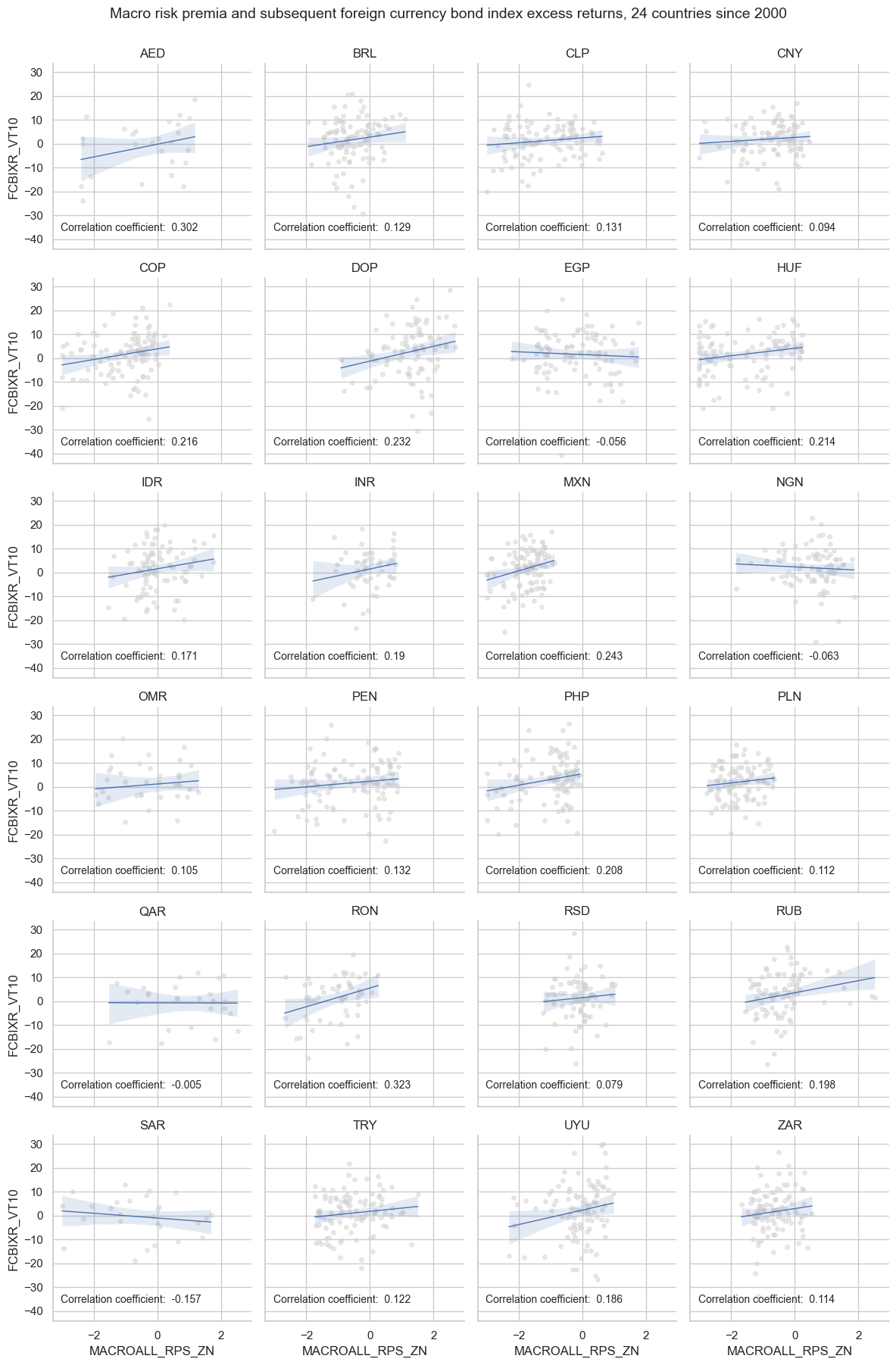
Conceptual directional signals #
Specs and panel test #
dict_cds = {
"sigs": crpz + ['MARKETRISK_ZN'],
"targs": ["FCBIXR_VT10", "FCBIXR_NSA"],
"cidx": cids_fc,
"start": "2000-01-01",
"black": black_fc,
}
dix = dict_cds
sigs = dix['sigs']
ret = dix["targs"][0]
cidx = dix["cidx"]
start = dix["start"]
black = dix["black"]
catregs = {}
for sig in sigs:
catregs[sig] = msp.CategoryRelations(
dfx,
xcats=[sig, ret],
cids=cidx,
freq="Q",
lag=1,
xcat_aggs=["mean", "sum"],
start=start,
blacklist=black,
)
msv.multiple_reg_scatter(
cat_rels=[v for k, v in catregs.items()],
ncol=2,
nrow=4,
figsize=(14, 24),
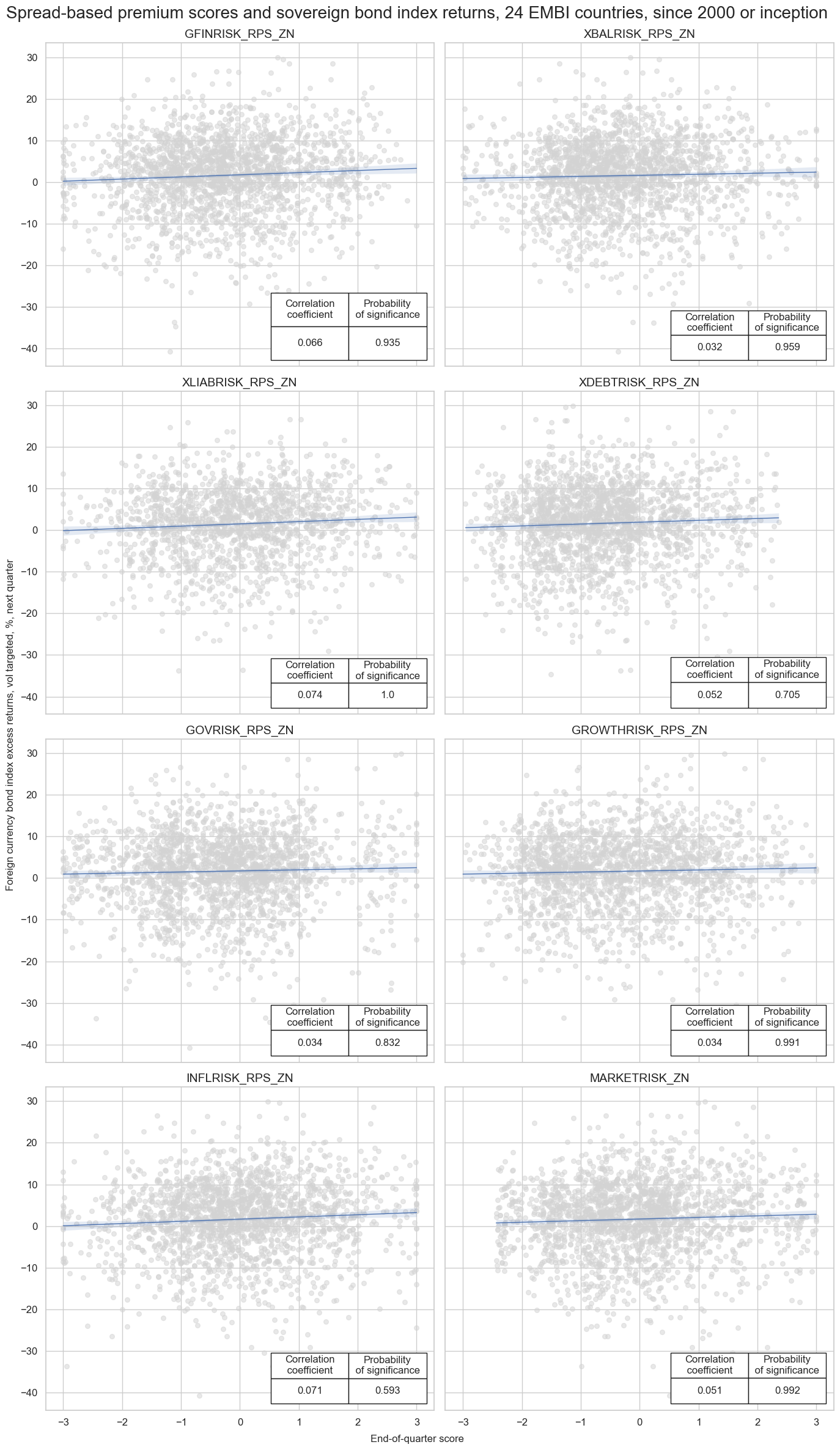
title="Spread-based premium scores and sovereign bond index returns, 24 EMBI countries, since 2000 or inception",
title_fontsize=20,
xlab="End-of-quarter score",
ylab="Foreign currency bond index excess returns, vol targeted, %, next quarter",
coef_box="lower right",
prob_est="map",
single_chart=True,
subplot_titles=sigs,
)
XLIABRISK_RPS_ZN misses: ['AED', 'OMR', 'QAR', 'SAR'].
XDEBTRISK_RPS_ZN misses: ['QAR'].
Accuracy and correlation check #
dix = dict_cds
sigs = dix['sigs']
ret = dix["targs"][0]
cidx = dix["cidx"]
start = dix["start"]
black = dix["black"]
srr = mss.SignalReturnRelations(
dfx,
rets=ret,
cids=cidx,
sigs=sigs,
# cosp=True,
freqs="M",
agg_sigs=["mean"], # for stability
start=start,
)
dix["srr"] = srr
dix = dict_cds
srr = dix["srr"]
tbl=srr.multiple_relations_table().round(3)
display(tbl.transpose())
| Return | FCBIXR_VT10 | |||||||
|---|---|---|---|---|---|---|---|---|
| Signal | GFINRISK_RPS_ZN | GOVRISK_RPS_ZN | GROWTHRISK_RPS_ZN | INFLRISK_RPS_ZN | MARKETRISK_ZN | XBALRISK_RPS_ZN | XDEBTRISK_RPS_ZN | XLIABRISK_RPS_ZN |
| Frequency | M | M | M | M | M | M | M | M |
| Aggregation | mean | mean | mean | mean | mean | mean | mean | mean |
| accuracy | 0.483 | 0.470 | 0.486 | 0.509 | 0.501 | 0.482 | 0.446 | 0.512 |
| bal_accuracy | 0.506 | 0.491 | 0.508 | 0.513 | 0.510 | 0.510 | 0.502 | 0.519 |
| pos_sigr | 0.393 | 0.403 | 0.399 | 0.481 | 0.459 | 0.371 | 0.244 | 0.468 |
| pos_retr | 0.608 | 0.609 | 0.608 | 0.609 | 0.609 | 0.608 | 0.609 | 0.603 |
| pos_prec | 0.616 | 0.598 | 0.618 | 0.623 | 0.619 | 0.620 | 0.611 | 0.623 |
| neg_prec | 0.396 | 0.384 | 0.398 | 0.404 | 0.400 | 0.400 | 0.392 | 0.415 |
| pearson | 0.025 | 0.019 | 0.010 | 0.051 | 0.022 | 0.011 | 0.019 | 0.033 |
| pearson_pval | 0.050 | 0.135 | 0.451 | 0.000 | 0.086 | 0.401 | 0.141 | 0.024 |
| kendall | 0.027 | 0.011 | 0.010 | 0.030 | 0.025 | 0.024 | 0.020 | 0.028 |
| kendall_pval | 0.002 | 0.204 | 0.246 | 0.001 | 0.003 | 0.008 | 0.023 | 0.005 |
| auc | 0.506 | 0.491 | 0.508 | 0.514 | 0.510 | 0.510 | 0.501 | 0.520 |
dix = dict_cds
srr = dix["srr"]
sig = dix['sigs'][0]
srr.accuracy_bars(type='cross_section', sigs=sig, size=(16, 4))
srr.accuracy_bars(type='signals', size=(16, 4))
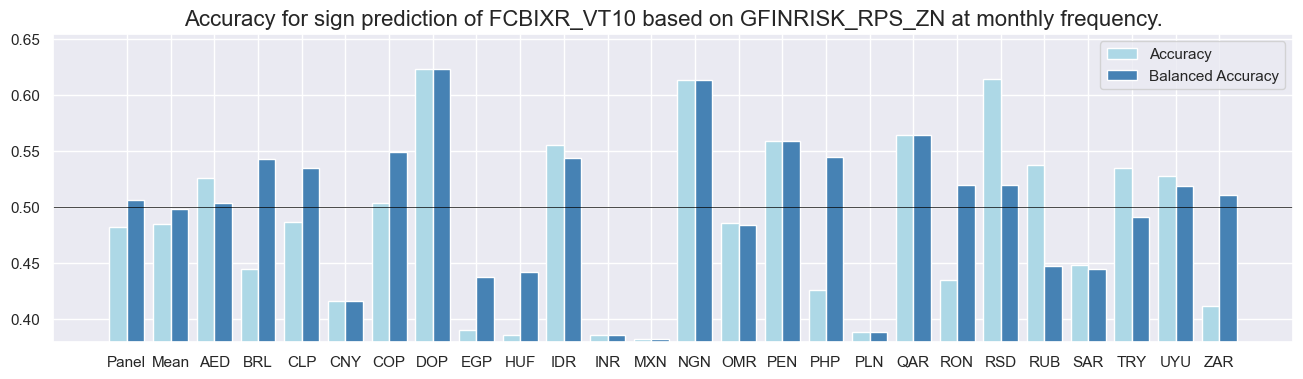
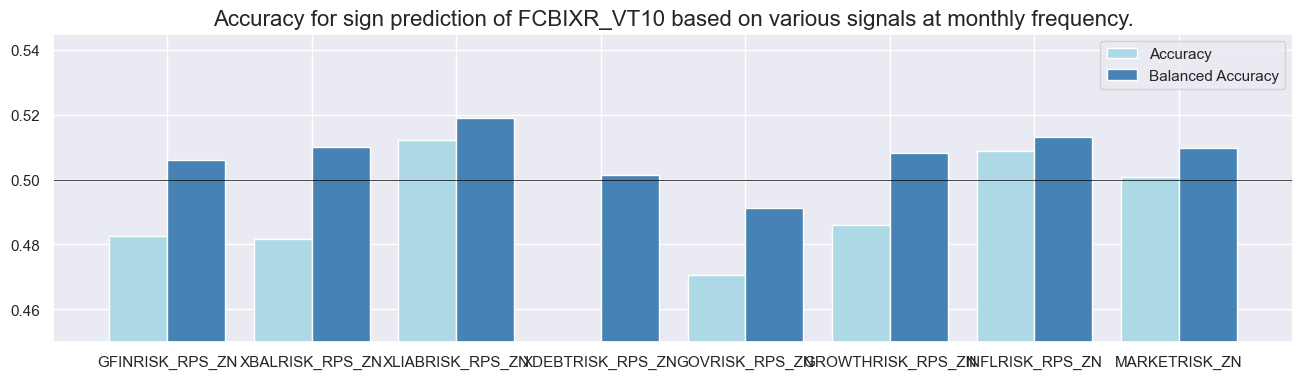
dix = dict_cds
srr = dix["srr"]
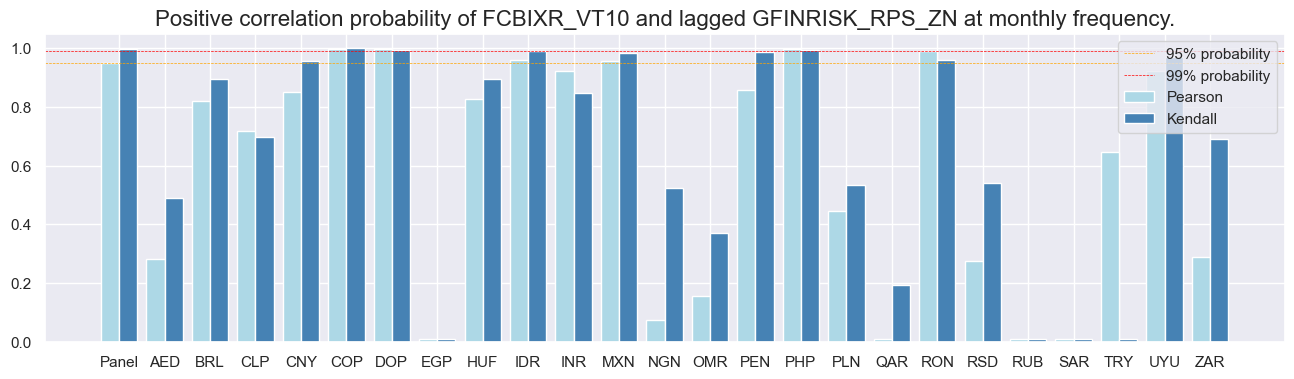
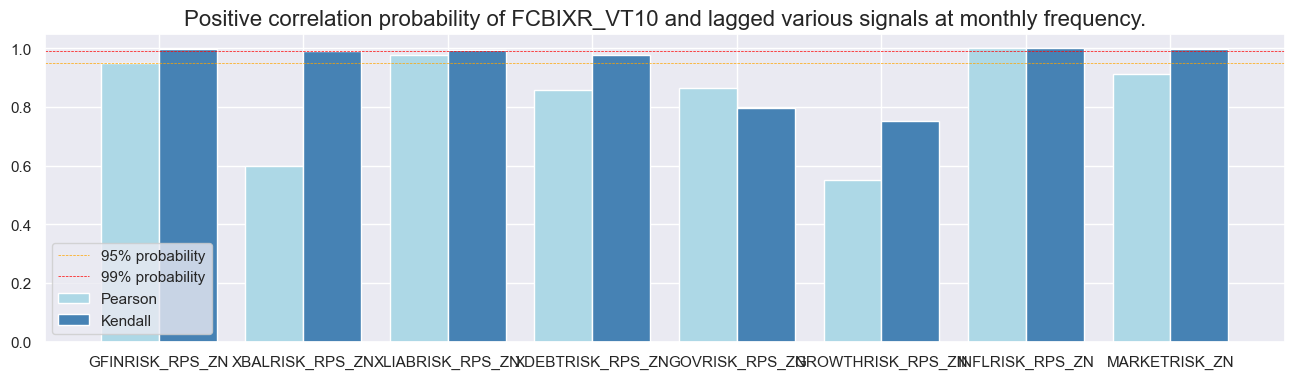
sig = dix['sigs'][0]
srr.correlation_bars(type='cross_section', sigs=sig, size=(16, 4))
srr.correlation_bars(type='signals', size=(16, 4))
Naive PnLs #
dix = dict_cds
sigs = dix['sigs']
ret = dix["targs"][0]
cidx = dix["cidx"]
start = dix["start"]
black = dix["black"]
rt = ret.split('_')[-1] # 'NSA' or 'VT10'
pnls = msn.NaivePnL(
df=dfx,
ret=ret,
sigs=sigs,
cids=cidx,
start=start,
blacklist=black,
bms=bms,
)
for sig in sigs:
for bias in [0, 1]:
pnls.make_pnl(
sig=sig,
sig_op="zn_score_pan",
thresh=2,
sig_add = bias,
rebal_freq="monthly",
neutral="zero",
pnl_name=sig + "_PNL" + rt + str(bias),
rebal_slip=1,
vol_scale=10,
)
pnls.make_long_pnl(vol_scale=10, label="Long only")
dix["pnls_"+rt.lower()] = pnls
dix = dict_cds
rt = "VT10"
bias = 1
pnls = dix["pnls_"+rt.lower()]
sigs = dix["sigs"]
strats = [sig + "_PNL" + rt + str(bias) for sig in sigs]
pnls.plot_pnls(
title=None,
pnl_cats=strats + ["Long only"],
xcat_labels=None,
title_fontsize=14,
)
display(pnls.evaluate_pnls(pnl_cats=strats + ["Long only"]).round(3))
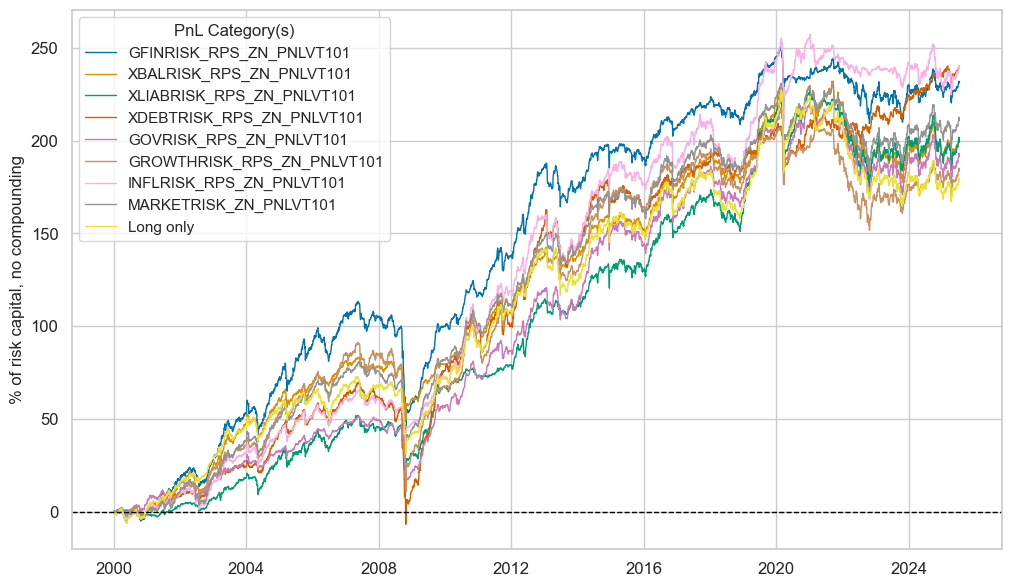
| xcat | GFINRISK_RPS_ZN_PNLVT101 | XBALRISK_RPS_ZN_PNLVT101 | XLIABRISK_RPS_ZN_PNLVT101 | XDEBTRISK_RPS_ZN_PNLVT101 | GOVRISK_RPS_ZN_PNLVT101 | GROWTHRISK_RPS_ZN_PNLVT101 | INFLRISK_RPS_ZN_PNLVT101 | MARKETRISK_ZN_PNLVT101 | Long only |
|---|---|---|---|---|---|---|---|---|---|
| Return % | 9.069923 | 7.845259 | 7.809989 | 9.365857 | 7.504711 | 7.198478 | 9.37071 | 8.271644 | 6.981771 |
| St. Dev. % | 10.0 | 10.0 | 10.0 | 10.0 | 10.0 | 10.0 | 10.0 | 10.0 | 10.0 |
| Sharpe Ratio | 0.906992 | 0.784526 | 0.780999 | 0.936586 | 0.750471 | 0.719848 | 0.937071 | 0.827164 | 0.698177 |
| Sortino Ratio | 1.223952 | 1.053887 | 1.079442 | 1.254567 | 1.008694 | 0.944812 | 1.252072 | 1.107006 | 0.919443 |
| Max 21-Day Draw % | -40.2581 | -45.128045 | -42.395547 | -44.926691 | -41.718641 | -48.35131 | -46.333155 | -41.389511 | -42.691756 |
| Max 6-Month Draw % | -62.208723 | -31.774818 | -30.875384 | -64.946729 | -33.97102 | -75.899135 | -29.854672 | -41.888409 | -37.994155 |
| Peak to Trough Draw % | -70.439488 | -54.783041 | -52.099888 | -76.664861 | -52.11325 | -80.593515 | -47.749902 | -48.767977 | -62.284802 |
| Top 5% Monthly PnL Share | 0.570024 | 0.609965 | 0.726904 | 0.604738 | 0.732884 | 0.682009 | 0.637261 | 0.626005 | 0.765992 |
| USD_EQXR_NSA correl | 0.265795 | 0.274654 | 0.268843 | 0.23677 | 0.233034 | 0.216362 | 0.224042 | 0.293771 | 0.214621 |
| UHY_CRXR_NSA correl | 0.326415 | 0.328388 | 0.318423 | 0.289318 | 0.286144 | 0.260542 | 0.295498 | 0.350945 | 0.273707 |
| UIG_CRXR_NSA correl | 0.327803 | 0.307722 | 0.297385 | 0.308329 | 0.25085 | 0.261868 | 0.267672 | 0.332166 | 0.253349 |
| Traded Months | 307 | 307 | 307 | 307 | 307 | 307 | 307 | 307 | 307 |
Composite relative signals #
Specs and panel test #
dict_rel = {
"sigs": ['MACROSPREAD_RPS_ZNvEM','MACRORATING_RPS_ZNvEM', 'MACROALL_RPS_ZNvEM', 'MARKETRISK_ZNvEM'],
"targs": ["FCBIXR_VT10vEM", "FCBIXR_NSAvEM"],
"cidx": cids_fc,
"start": "2000-01-01",
"black": black_fc,
}
dix = dict_rel
sigs = dix['sigs']
ret = dix["targs"][0]
cidx = dix["cidx"]
start = dix["start"]
black = dix["black"]
catregs = {}
for sig in sigs:
catregs[sig] = msp.CategoryRelations(
dfx,
xcats=[sig, ret],
cids=cidx,
freq="Q",
lag=1,
xcat_aggs=["mean", "sum"],
start=start,
blacklist=black,
)
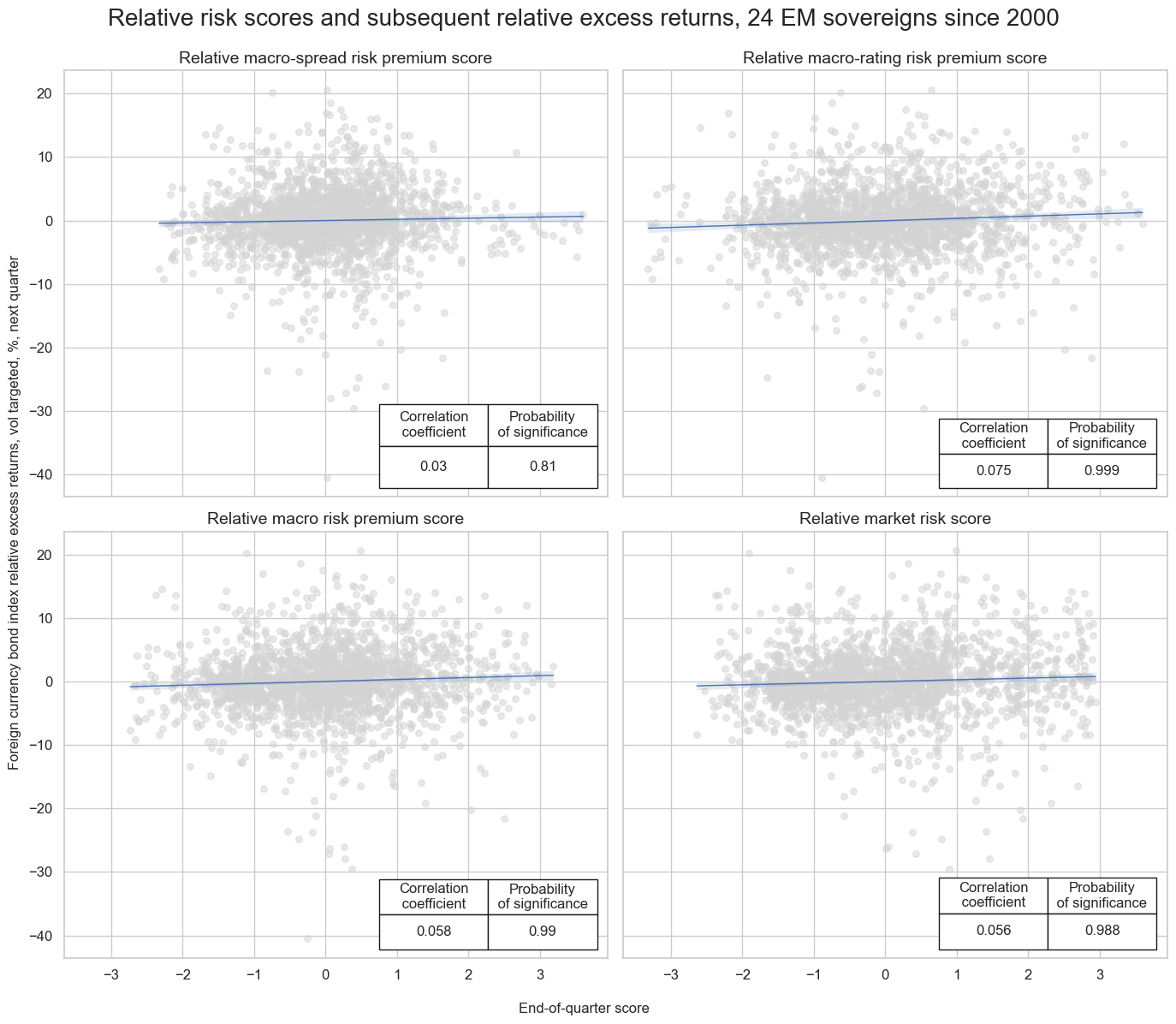
msv.multiple_reg_scatter(
cat_rels=[v for k, v in catregs.items()],
ncol=2,
nrow=2,
figsize=(14, 12),
title="Relative risk scores and subsequent relative excess returns, 24 EM sovereigns since 2000",
title_fontsize=20,
xlab="End-of-quarter score",
ylab="Foreign currency bond index relative excess returns, vol targeted, %, next quarter",
coef_box="lower right",
prob_est="map",
single_chart=True,
subplot_titles=[dict_labels[key] for key in sigs]
)
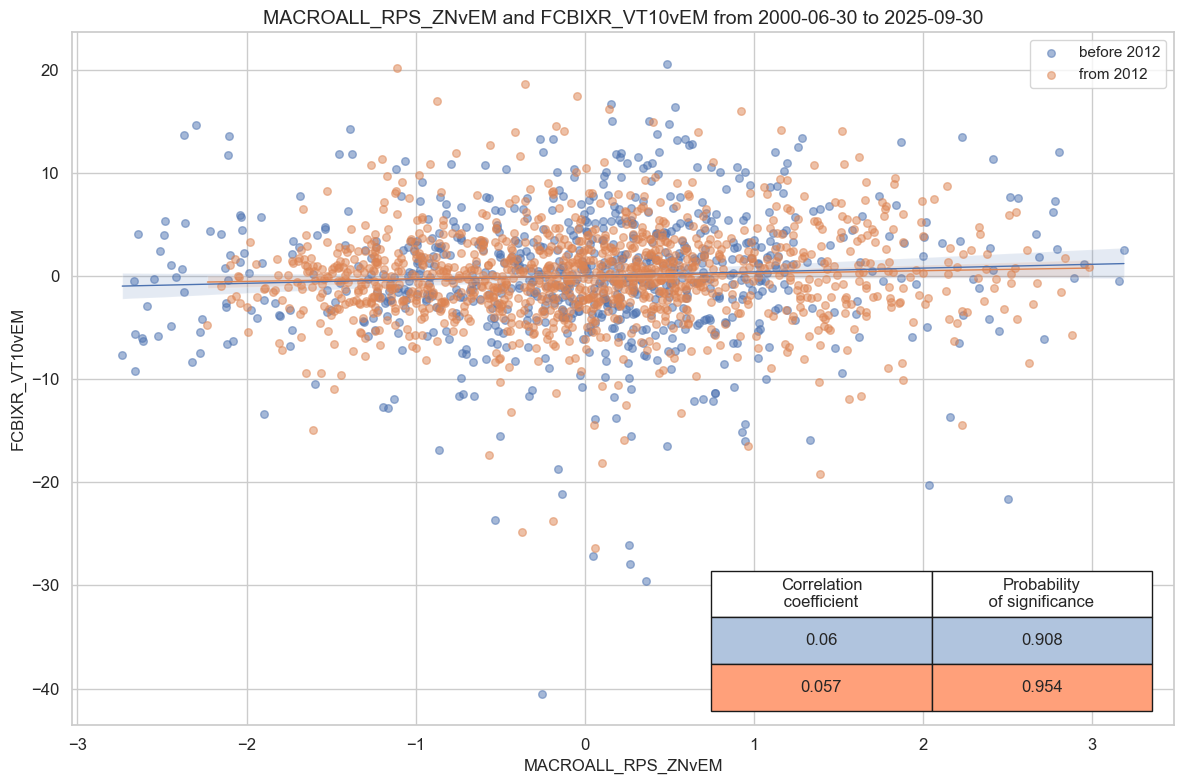
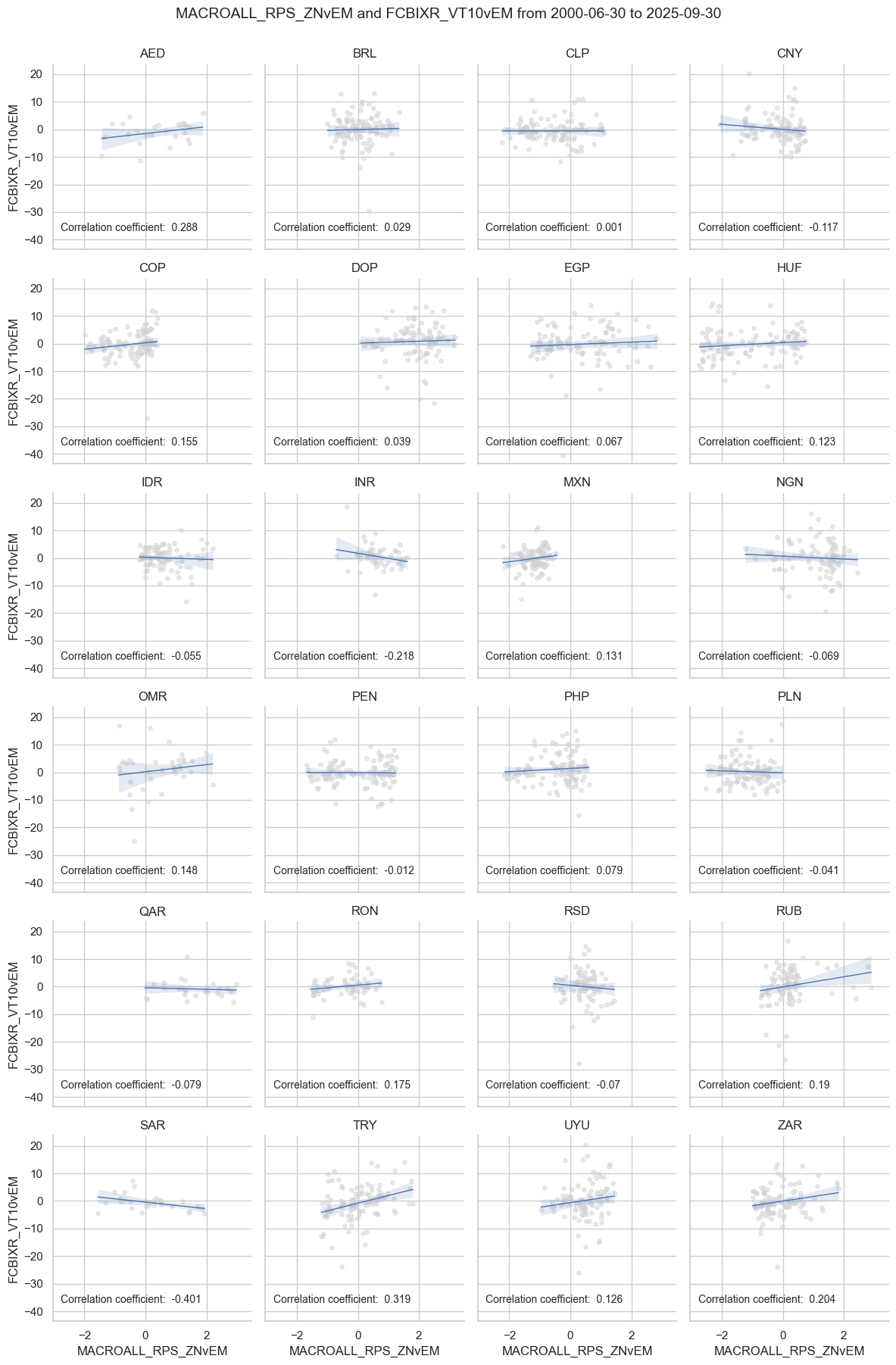
dix = dict_rel
sig = dix["sigs"][2]
ret = dix["targs"][0]
cidx = dix["cidx"]
start = dix["start"]
black = dix["black"]
cr = msp.CategoryRelations(
dfx,
xcats=[sig, ret],
cids=cidx,
freq="Q",
years=None,
lag=1,
xcat_aggs=["mean", "sum"], # period mean adds stability
start=start,
blacklist=black,
)
cr.reg_scatter(
title=None,
labels=False,
xlab=None,
ylab=None,
coef_box="lower right",
prob_est="map",
separator=2012,
size=(12, 8),
)
cr.reg_scatter(
title=None,
labels=False,
xlab=None,
ylab=None,
coef_box="lower right",
prob_est="pool",
separator="cids",
)
Accuracy and correlation check #
dix = dict_rel
sigs = dix['sigs']
ret = dix["targs"][0]
cidx = dix["cidx"]
start = dix["start"]
black = dix["black"]
srr = mss.SignalReturnRelations(
dfx,
rets=ret,
cids=cidx,
sigs=sigs,
# cosp=True,
freqs="M",
agg_sigs=["mean"], # for stability
start=start,
)
dix["srr"] = srr
dix = dict_rel
srr = dix["srr"]
tbl=srr.multiple_relations_table().round(3)
display(tbl.transpose())
| Return | FCBIXR_VT10vEM | |||
|---|---|---|---|---|
| Signal | MACROALL_RPS_ZNvEM | MACRORATING_RPS_ZNvEM | MACROSPREAD_RPS_ZNvEM | MARKETRISK_ZNvEM |
| Frequency | M | M | M | M |
| Aggregation | mean | mean | mean | mean |
| accuracy | 0.527 | 0.521 | 0.525 | 0.532 |
| bal_accuracy | 0.527 | 0.521 | 0.525 | 0.532 |
| pos_sigr | 0.514 | 0.497 | 0.501 | 0.491 |
| pos_retr | 0.500 | 0.499 | 0.501 | 0.500 |
| pos_prec | 0.526 | 0.521 | 0.526 | 0.533 |
| neg_prec | 0.528 | 0.522 | 0.524 | 0.531 |
| pearson | 0.033 | 0.046 | 0.015 | 0.031 |
| pearson_pval | 0.013 | 0.001 | 0.272 | 0.018 |
| kendall | 0.036 | 0.038 | 0.026 | 0.043 |
| kendall_pval | 0.000 | 0.000 | 0.003 | 0.000 |
| auc | 0.527 | 0.521 | 0.525 | 0.532 |
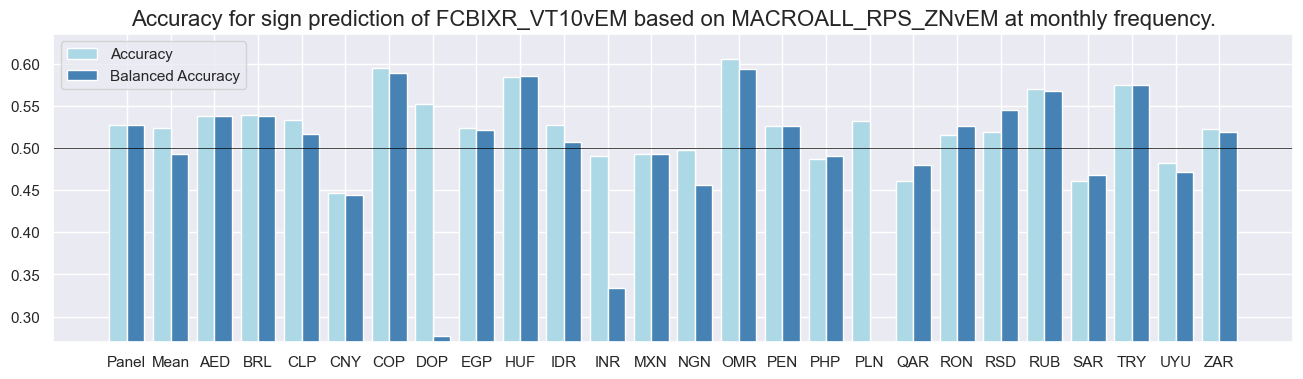
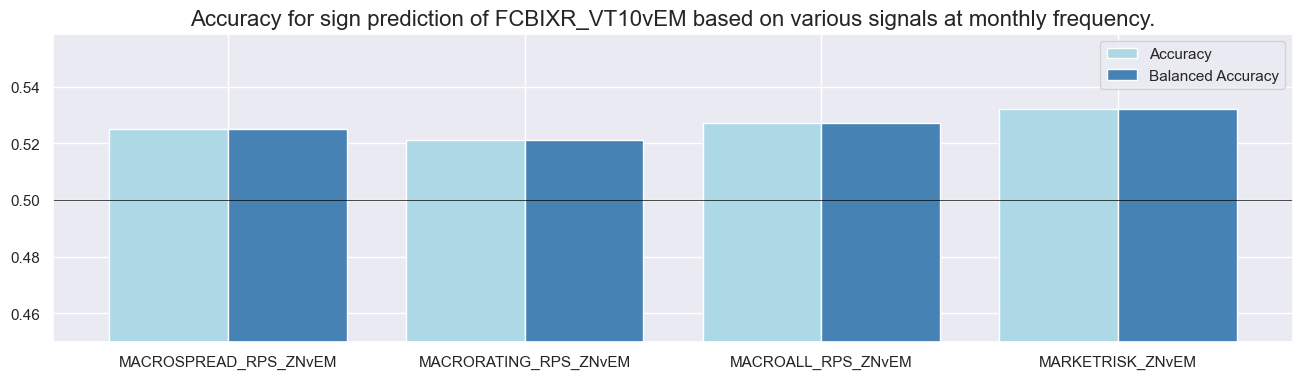
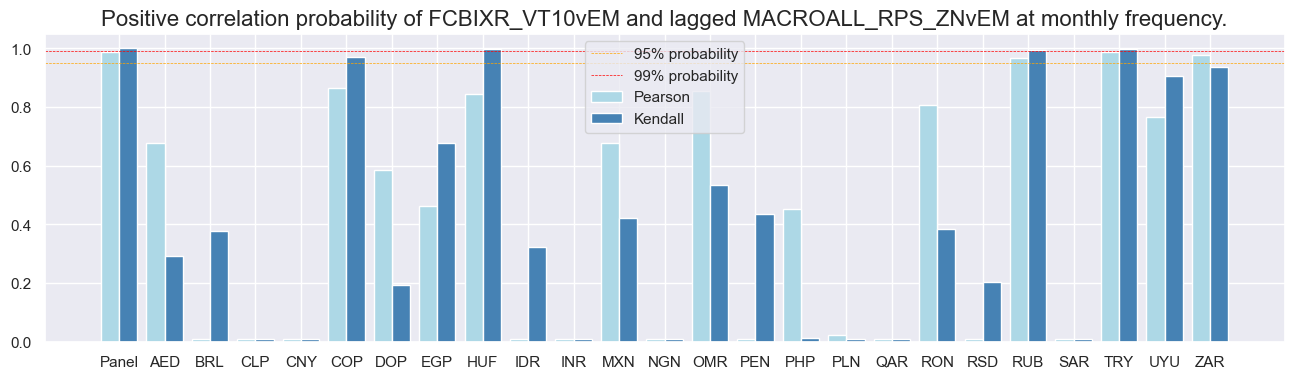
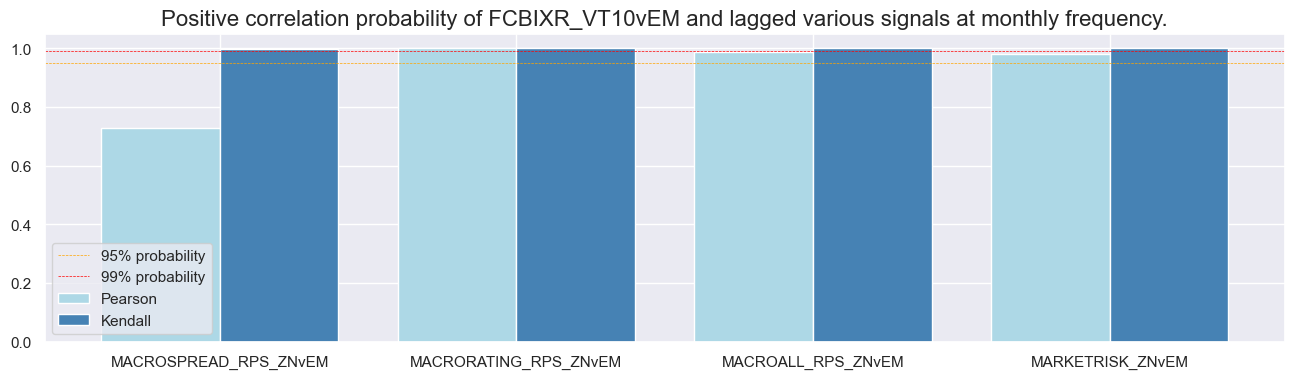
dix = dict_rel
srr = dix["srr"]
srr.accuracy_bars(type='cross_section', sigs="MACROALL_RPS_ZNvEM", size=(16, 4))
srr.accuracy_bars(type='signals', size=(16, 4))
dix = dict_rel
srr = dix["srr"]
srr.correlation_bars(type='cross_section', sigs="MACROALL_RPS_ZNvEM", size=(16, 4))
srr.correlation_bars(type='signals', size=(16, 4))
Naive PnLs #
dix = dict_rel
sigs = dix["sigs"]
ret = dix["targs"][0]
cidx = dix["cidx"]
start = dix["start"]
black = dix["black"]
pnls = msn.NaivePnL(
df=dfx,
ret=ret,
sigs=sigs,
cids=cidx,
start=start,
blacklist=black,
bms=bms,
)
for sig in sigs:
pnls.make_pnl(
sig=sig,
sig_op="zn_score_pan",
thresh=2,
sig_add=0,
rebal_freq="monthly",
neutral="zero",
pnl_name=sig + "_PNL",
rebal_slip=1,
vol_scale=10,
)
dix["pnls"] = pnls
dix = dict_rel
bias = 0
pnls = dix["pnls"]
sigs = dix["sigs"]
sigs = ["MACROSPREAD_RPS_ZNvEM", "MACRORATING_RPS_ZNvEM", "MACROALL_RPS_ZNvEM"]
strats = [sig + "_PNL" for sig in sigs]
pnl_labels = {
"MACROSPREAD_RPS_ZNvEM_PNL": "Spread-based relative macro risk premium score",
"MACRORATING_RPS_ZNvEM_PNL": "Ratings-based relative macro risk premium score",
"MACROALL_RPS_ZNvEM_PNL": "Composite relative macro risk premium score",
}
pnls.plot_pnls(
title="Naive PnL for relative risk-premia strategies, 24 EM sovereigns, 7-factor macro risk",
pnl_cats=strats,
xcat_labels=pnl_labels,
title_fontsize=14,
)
display(pnls.evaluate_pnls(pnl_cats=strats).round(3))
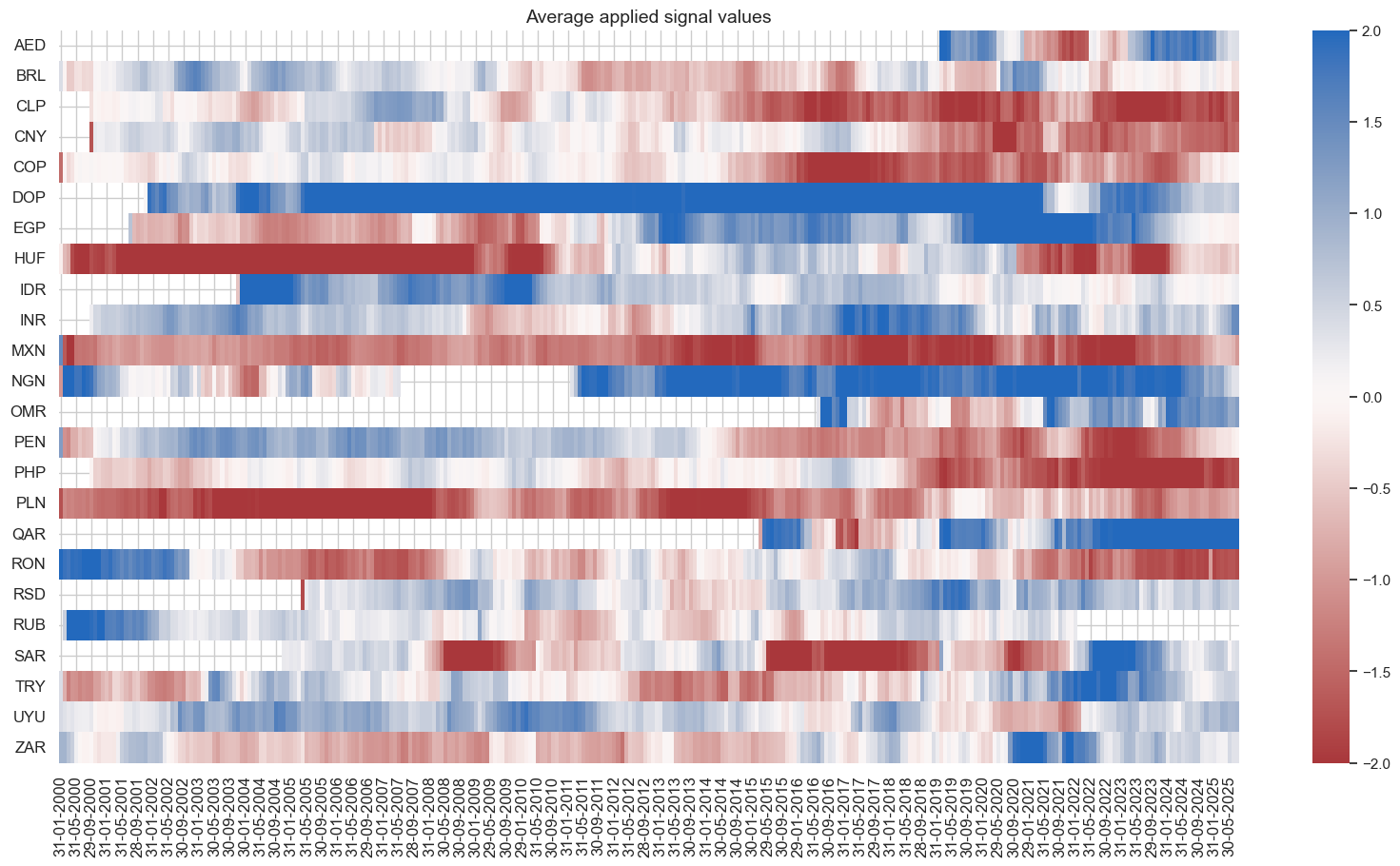
pnls.signal_heatmap(pnl_name=f"MACROALL_RPS_ZNvEM_PNL", figsize=(20, 10))
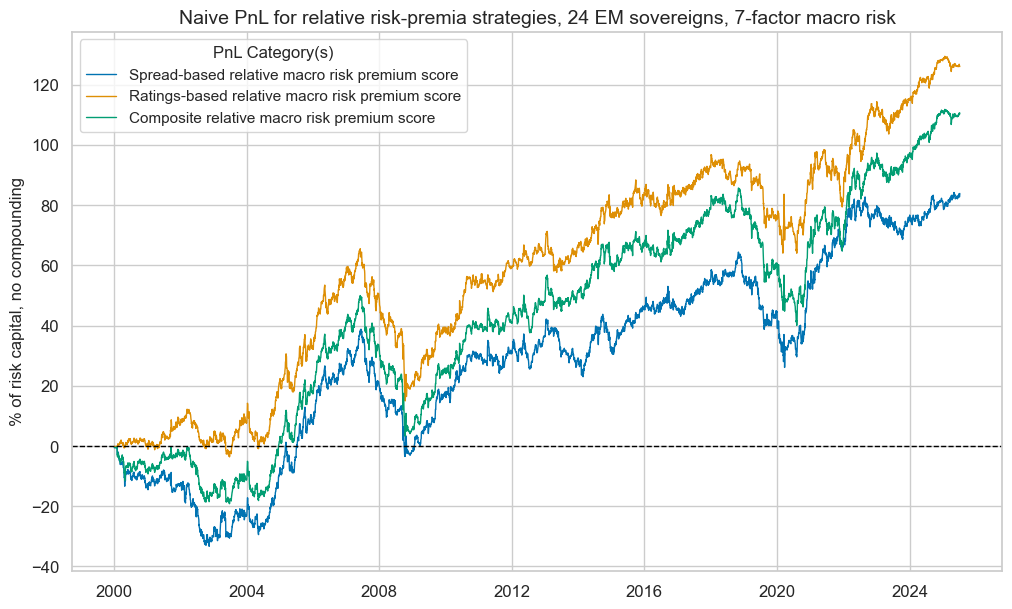
| xcat | MACROSPREAD_RPS_ZNvEM_PNL | MACRORATING_RPS_ZNvEM_PNL | MACROALL_RPS_ZNvEM_PNL |
|---|---|---|---|
| Return % | 3.288327 | 4.940587 | 4.336086 |
| St. Dev. % | 10.0 | 10.0 | 10.0 |
| Sharpe Ratio | 0.328833 | 0.494059 | 0.433609 |
| Sortino Ratio | 0.462594 | 0.701466 | 0.617352 |
| Max 21-Day Draw % | -14.292397 | -21.642034 | -17.734183 |
| Max 6-Month Draw % | -19.451053 | -29.285285 | -24.164561 |
| Peak to Trough Draw % | -42.26313 | -50.507665 | -46.689844 |
| Top 5% Monthly PnL Share | 1.22375 | 0.852004 | 1.022676 |
| USD_EQXR_NSA correl | 0.014075 | 0.094128 | 0.093128 |
| UHY_CRXR_NSA correl | 0.010943 | 0.091992 | 0.092796 |
| UIG_CRXR_NSA correl | -0.011382 | 0.09323 | 0.084991 |
| Traded Months | 307 | 307 | 307 |
Conceptual relative signals #
Specs and panel test #
dict_crs = {
"sigs": crpzr + ["MARKETRISK_ZNvEM"],
"targs": ["FCBIXR_VT10vEM", "FCBIXR_NSAvEM"],
"cidx": cids_fc,
"start": "2000-01-01",
"black": black_fc,
}
dix = dict_crs
sigs = dix['sigs']
ret = dix["targs"][0]
cidx = dix["cidx"]
start = dix["start"]
black = dix["black"]
catregs = {}
for sig in sigs:
catregs[sig] = msp.CategoryRelations(
dfx,
xcats=[sig, ret],
cids=cidx,
freq="Q",
lag=1,
xcat_aggs=["mean", "sum"],
start=start,
blacklist=black,
)
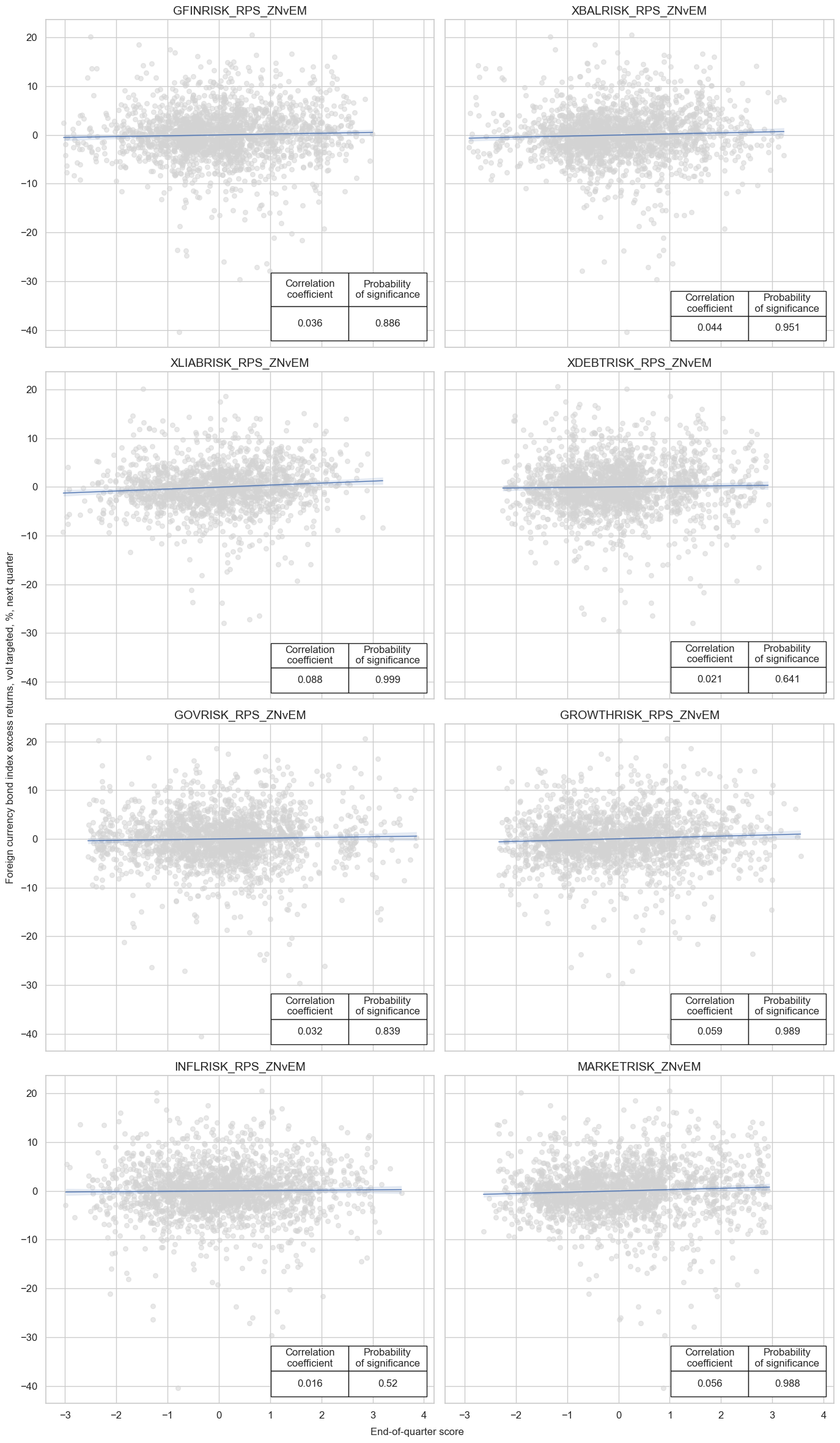
msv.multiple_reg_scatter(
cat_rels=[v for k, v in catregs.items()],
ncol=2,
nrow=4,
figsize=(14, 24),
title=None,
title_fontsize=20,
xlab="End-of-quarter score",
ylab="Foreign currency bond index excess returns, vol targeted, %, next quarter",
coef_box="lower right",
prob_est="map",
single_chart=True,
subplot_titles=sigs,
)
XLIABRISK_RPS_ZNvEM misses: ['AED', 'OMR', 'QAR', 'SAR'].
XDEBTRISK_RPS_ZNvEM misses: ['QAR'].
Accuracy and correlation check #
dix = dict_crs
sigs = dix['sigs']
ret = dix["targs"][0]
cidx = dix["cidx"]
start = dix["start"]
black = dix["black"]
srr = mss.SignalReturnRelations(
dfx,
rets=ret,
cids=cidx,
sigs=sigs,
# cosp=True,
freqs="M",
agg_sigs=["mean"], # for stability
start=start,
)
dix["srr"] = srr
dix = dict_crs
srr = dix["srr"]
tbl=srr.multiple_relations_table().round(3)
display(tbl.transpose())
| Return | FCBIXR_VT10vEM | |||||||
|---|---|---|---|---|---|---|---|---|
| Signal | GFINRISK_RPS_ZNvEM | GOVRISK_RPS_ZNvEM | GROWTHRISK_RPS_ZNvEM | INFLRISK_RPS_ZNvEM | MARKETRISK_ZNvEM | XBALRISK_RPS_ZNvEM | XDEBTRISK_RPS_ZNvEM | XLIABRISK_RPS_ZNvEM |
| Frequency | M | M | M | M | M | M | M | M |
| Aggregation | mean | mean | mean | mean | mean | mean | mean | mean |
| accuracy | 0.518 | 0.513 | 0.525 | 0.512 | 0.532 | 0.527 | 0.517 | 0.538 |
| bal_accuracy | 0.518 | 0.513 | 0.525 | 0.512 | 0.532 | 0.527 | 0.517 | 0.538 |
| pos_sigr | 0.500 | 0.525 | 0.467 | 0.499 | 0.491 | 0.479 | 0.442 | 0.503 |
| pos_retr | 0.500 | 0.500 | 0.499 | 0.500 | 0.500 | 0.500 | 0.500 | 0.498 |
| pos_prec | 0.518 | 0.512 | 0.526 | 0.512 | 0.533 | 0.529 | 0.519 | 0.536 |
| neg_prec | 0.519 | 0.513 | 0.524 | 0.511 | 0.531 | 0.525 | 0.515 | 0.540 |
| pearson | 0.021 | 0.017 | 0.031 | 0.008 | 0.031 | 0.027 | 0.012 | 0.051 |
| pearson_pval | 0.106 | 0.203 | 0.020 | 0.560 | 0.018 | 0.045 | 0.364 | 0.001 |
| kendall | 0.024 | 0.016 | 0.032 | 0.011 | 0.043 | 0.039 | 0.022 | 0.054 |
| kendall_pval | 0.006 | 0.064 | 0.000 | 0.209 | 0.000 | 0.000 | 0.012 | 0.000 |
| auc | 0.518 | 0.513 | 0.525 | 0.512 | 0.532 | 0.527 | 0.517 | 0.538 |
Naive PnLs #
dix = dict_crs
sigs = dix["sigs"]
ret = dix["targs"][0]
cidx = dix["cidx"]
start = dix["start"]
black = dix["black"]
pnls = msn.NaivePnL(
df=dfx,
ret=ret,
sigs=sigs,
cids=cidx,
start=start,
blacklist=black,
bms=bms,
)
for sig in sigs:
pnls.make_pnl(
sig=sig,
sig_op="zn_score_pan",
thresh=2,
sig_add=0,
rebal_freq="monthly",
neutral="zero",
pnl_name=sig + "_PNL",
rebal_slip=1,
vol_scale=10,
)
dix["pnls"] = pnls
dix = dict_crs
bias = 0
pnls = dix["pnls"]
sigs = dix["sigs"]
strats = [sig + "_PNL" for sig in sigs]
pnls.plot_pnls(
title=None,
pnl_cats=strats,
xcat_labels=None,
title_fontsize=14,
)
display(pnls.evaluate_pnls(pnl_cats=strats).round(3))
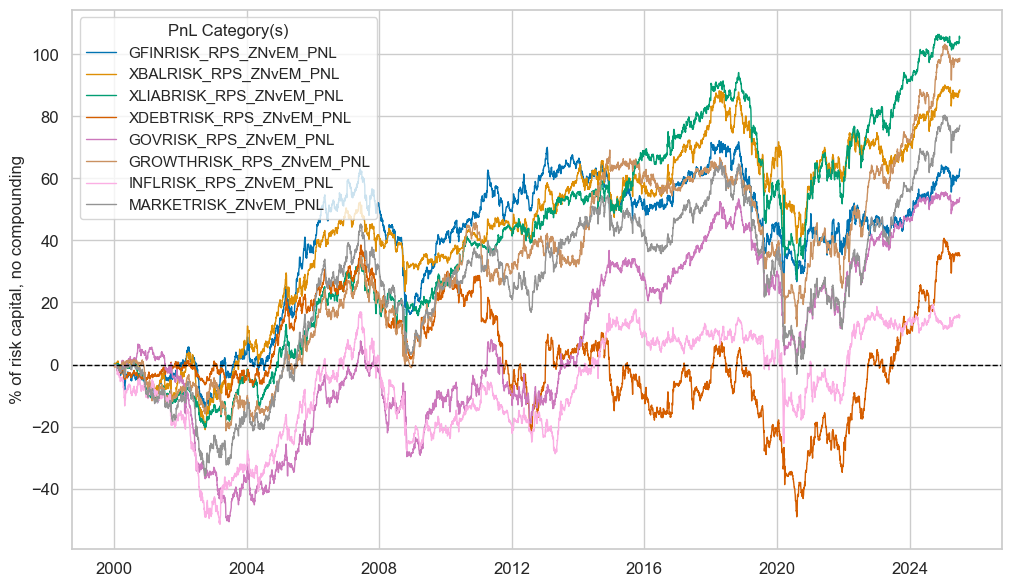
| xcat | GFINRISK_RPS_ZNvEM_PNL | XBALRISK_RPS_ZNvEM_PNL | XLIABRISK_RPS_ZNvEM_PNL | XDEBTRISK_RPS_ZNvEM_PNL | GOVRISK_RPS_ZNvEM_PNL | GROWTHRISK_RPS_ZNvEM_PNL | INFLRISK_RPS_ZNvEM_PNL | MARKETRISK_ZNvEM_PNL |
|---|---|---|---|---|---|---|---|---|
| Return % | 2.47308 | 3.473918 | 4.12682 | 1.383826 | 2.109722 | 3.8722 | 0.616067 | 3.02565 |
| St. Dev. % | 10.0 | 10.0 | 10.0 | 10.0 | 10.0 | 10.0 | 10.0 | 10.0 |
| Sharpe Ratio | 0.247308 | 0.347392 | 0.412682 | 0.138383 | 0.210972 | 0.38722 | 0.061607 | 0.302565 |
| Sortino Ratio | 0.345823 | 0.482246 | 0.582193 | 0.192992 | 0.290773 | 0.549068 | 0.084237 | 0.416436 |
| Max 21-Day Draw % | -19.310212 | -24.721489 | -19.278482 | -14.346869 | -20.308393 | -15.011376 | -28.951867 | -26.061055 |
| Max 6-Month Draw % | -28.772082 | -29.927572 | -40.062134 | -26.601295 | -30.361158 | -26.344571 | -32.909141 | -35.628673 |
| Peak to Trough Draw % | -49.081092 | -49.161827 | -67.013019 | -87.665029 | -57.298105 | -56.962764 | -51.144561 | -68.505051 |
| Top 5% Monthly PnL Share | 1.548534 | 1.092845 | 1.00857 | 3.963254 | 2.049111 | 1.266296 | 6.857896 | 1.517778 |
| USD_EQXR_NSA correl | 0.197936 | 0.220929 | 0.18575 | 0.085974 | 0.107427 | 0.053381 | 0.182097 | 0.252877 |
| UHY_CRXR_NSA correl | 0.222129 | 0.233202 | 0.184669 | 0.072825 | 0.108661 | 0.031029 | 0.202996 | 0.262652 |
| UIG_CRXR_NSA correl | 0.231882 | 0.229148 | 0.184079 | 0.087605 | 0.049114 | 0.018697 | 0.207417 | 0.24825 |
| Traded Months | 307 | 307 | 307 | 307 | 307 | 307 | 307 | 307 |
Customized directional signals #
Specs and panel test #
dict_dirc = {
"sigs": ['MACROSPREAD_RPS_CWS_ZN','MACRORATING_RPS_CWS_ZN', 'MACROALL_RPS_CWS_ZN', 'MARKETRISK_ZN'],
"targs": ["FCBIXR_VT10", "FCBIXR_NSA"],
"cidx": cids_fc,
"start": "2000-01-01",
"black": black_fc,
}
dix = dict_dirc
sigs = dix['sigs']
ret = dix["targs"][0]
cidx = dix["cidx"]
start = dix["start"]
black = dix["black"]
catregs = {}
for sig in sigs:
catregs[sig] = msp.CategoryRelations(
dfx,
xcats=[sig, ret],
cids=cidx,
freq="Q",
lag=1,
xcat_aggs=["last", "sum"],
start=start,
blacklist=black,
)
msv.multiple_reg_scatter(
cat_rels=[v for k, v in catregs.items()],
ncol=2,
nrow=2,
figsize=(14, 12),
title=None,
title_fontsize=20,
xlab="End-of-quarter score",
ylab="Foreign currency bond index excess returns, vol targeted, %, next quarter",
coef_box="lower right",
prob_est="map",
single_chart=True,
subplot_titles=[dict_labels[key] for key in sigs]
)
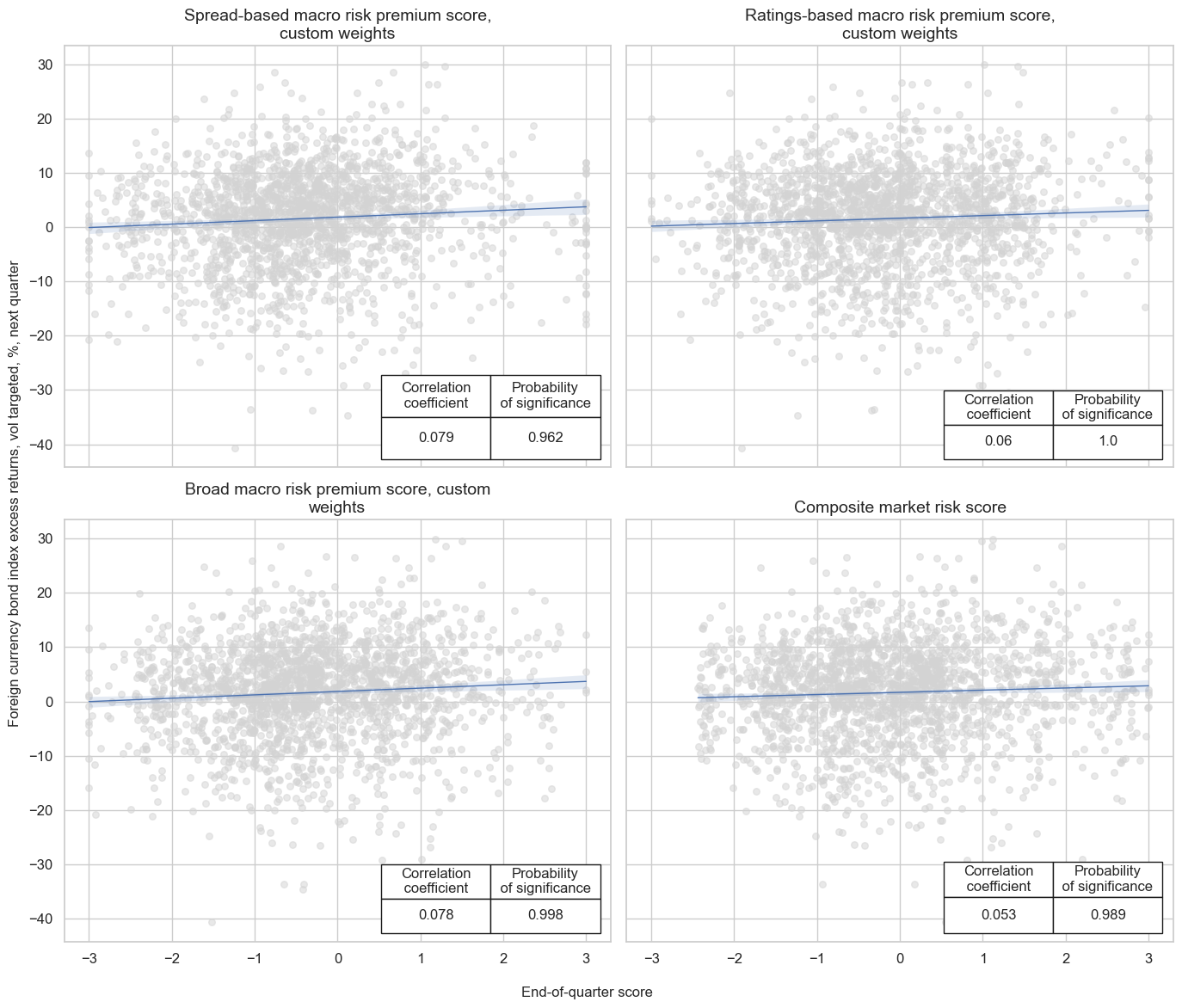
Accuracy and correlation check #
dix = dict_dirc
sigs = dix['sigs']
ret = dix["targs"][0]
cidx = dix["cidx"]
start = dix["start"]
black = dix["black"]
srr = mss.SignalReturnRelations(
dfx,
rets=ret,
cids=cidx,
sigs=sigs,
# cosp=True,
freqs="M",
agg_sigs=["last"], # for stability
start=start,
)
dix["srr"] = srr
dix = dict_dirc
srr = dix["srr"]
tbl=srr.multiple_relations_table().round(3)
display(tbl.transpose())
| Return | FCBIXR_VT10 | |||
|---|---|---|---|---|
| Signal | MACROALL_RPS_CWS_ZN | MACRORATING_RPS_CWS_ZN | MACROSPREAD_RPS_CWS_ZN | MARKETRISK_ZN |
| Frequency | M | M | M | M |
| Aggregation | last | last | last | last |
| accuracy | 0.486 | 0.500 | 0.475 | 0.502 |
| bal_accuracy | 0.514 | 0.516 | 0.515 | 0.510 |
| pos_sigr | 0.375 | 0.423 | 0.322 | 0.462 |
| pos_retr | 0.609 | 0.606 | 0.608 | 0.608 |
| pos_prec | 0.625 | 0.626 | 0.628 | 0.619 |
| neg_prec | 0.402 | 0.407 | 0.402 | 0.401 |
| pearson | 0.031 | 0.024 | 0.028 | 0.020 |
| pearson_pval | 0.016 | 0.076 | 0.031 | 0.122 |
| kendall | 0.034 | 0.022 | 0.041 | 0.025 |
| kendall_pval | 0.000 | 0.014 | 0.000 | 0.004 |
| auc | 0.513 | 0.517 | 0.514 | 0.511 |
Naive PnLs #
dix = dict_dirc
sigs = dix['sigs']
ret = dix["targs"][0]
cidx = dix["cidx"]
start = dix["start"]
black = dix["black"]
rt = ret.split('_')[-1] # 'NSA' or 'VT10'
pnls = msn.NaivePnL(
df=dfx,
ret=ret,
sigs=sigs,
cids=cidx,
start=start,
blacklist=black,
bms=bms,
)
for sig in sigs:
for bias in [0, 1]:
pnls.make_pnl(
sig=sig,
sig_op="zn_score_pan",
thresh=2,
sig_add = bias,
rebal_freq="monthly",
neutral="zero",
pnl_name=sig + "_PNL" + rt + str(bias),
rebal_slip=1,
vol_scale=10,
)
pnls.make_long_pnl(vol_scale=10, label="Long only")
dix["pnls_"+rt.lower()] = pnls
dix = dict_dirc
rt = "VT10"
bias = 1
pnls = dix["pnls_"+rt.lower()]
sigs = ["MACROALL_RPS_CWS_ZN", "MARKETRISK_ZN"]
strats = [sig + "_PNL" + rt + str(bias) for sig in sigs]
pnls.plot_pnls(
title=None,
pnl_cats=strats + ["Long only"],
xcat_labels=None,
title_fontsize=14,
)
display(pnls.evaluate_pnls(pnl_cats=strats + ["Long only"]).round(3))
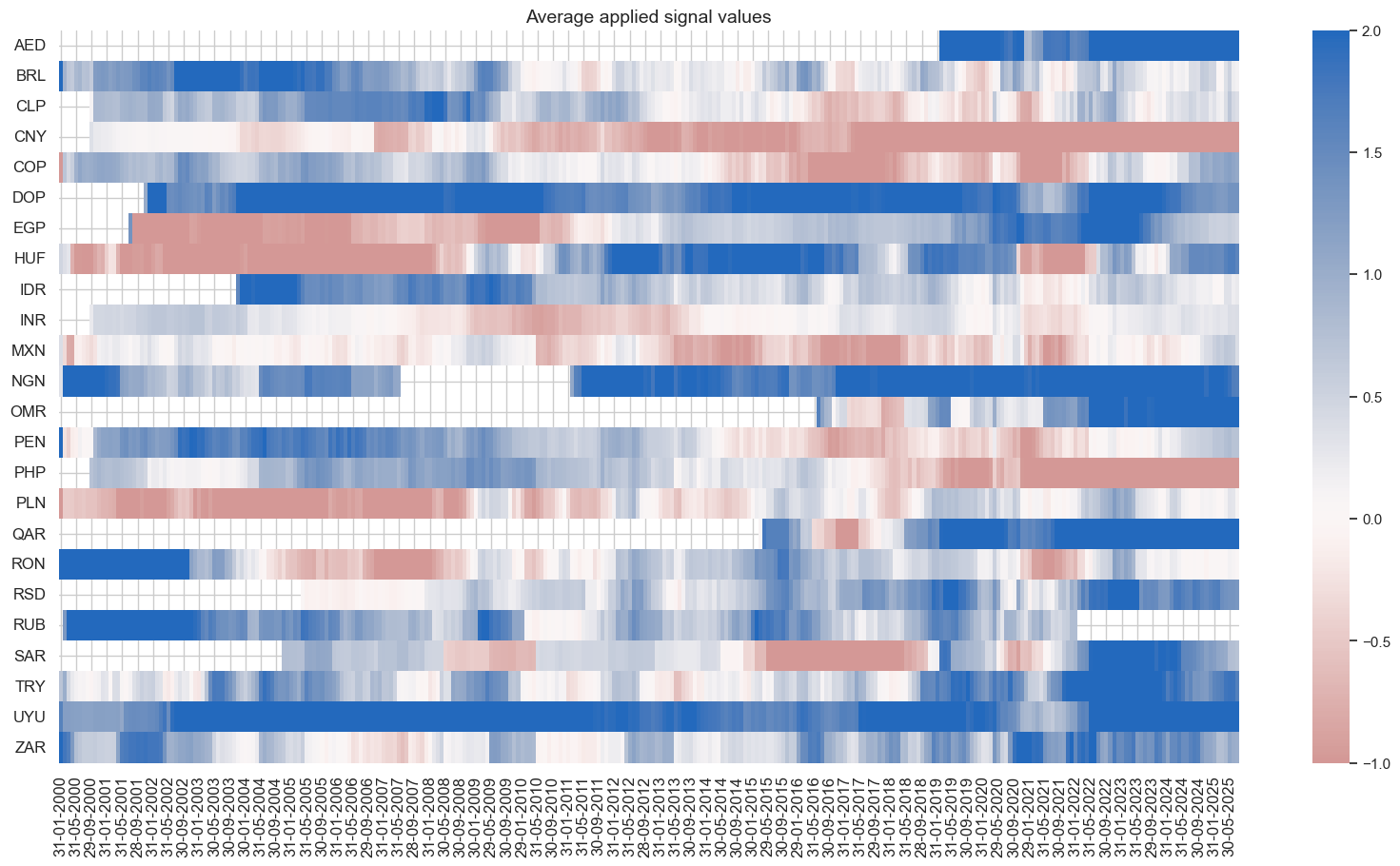
pnls.signal_heatmap(pnl_name=f"MACROALL_RPS_CWS_ZN_PNL" + rt + str(bias), figsize=(20, 10))
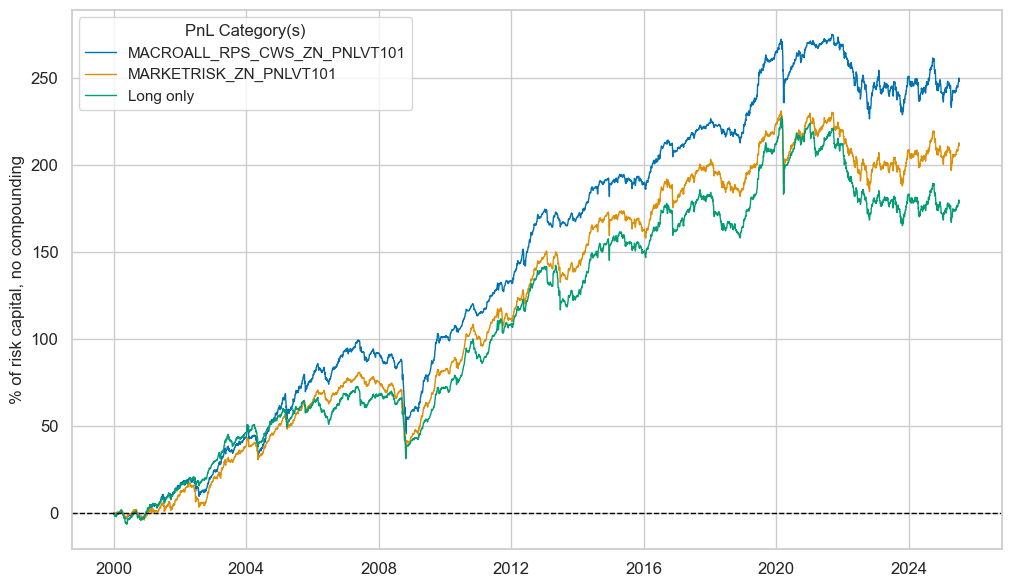
| xcat | MACROALL_RPS_CWS_ZN_PNLVT101 | MARKETRISK_ZN_PNLVT101 | Long only |
|---|---|---|---|
| Return % | 9.723982 | 8.271644 | 6.981771 |
| St. Dev. % | 10.0 | 10.0 | 10.0 |
| Sharpe Ratio | 0.972398 | 0.827164 | 0.698177 |
| Sortino Ratio | 1.330586 | 1.107006 | 0.919443 |
| Max 21-Day Draw % | -36.552005 | -41.389511 | -42.691756 |
| Max 6-Month Draw % | -45.795554 | -41.888409 | -37.994155 |
| Peak to Trough Draw % | -54.065154 | -48.767977 | -62.284802 |
| Top 5% Monthly PnL Share | 0.559016 | 0.626005 | 0.765992 |
| USD_EQXR_NSA correl | 0.264369 | 0.293771 | 0.214621 |
| UHY_CRXR_NSA correl | 0.318083 | 0.350945 | 0.273707 |
| UIG_CRXR_NSA correl | 0.294593 | 0.332166 | 0.253349 |
| Traded Months | 307 | 307 | 307 |
dix = dict_dirc
sigs = dix['sigs']
ret = dix["targs"][1]
cidx = dix["cidx"]
start = dix["start"]
black = dix["black"]
rt = ret.split('_')[-1] # 'NSA' or 'VT10'
pnls = msn.NaivePnL(
df=dfx,
ret=ret,
sigs=sigs,
cids=cidx,
start=start,
blacklist=black,
bms=bms,
)
for sig in sigs:
for bias in [0, 1]:
pnls.make_pnl(
sig=sig,
sig_op="zn_score_pan",
thresh=2,
sig_add = bias,
rebal_freq="monthly",
neutral="zero",
pnl_name=sig + "_PNL" + rt + str(bias),
rebal_slip=1,
vol_scale=10,
)
pnls.make_long_pnl(vol_scale=10, label="Long only")
dix["pnls_"+rt.lower()] = pnls
dix = dict_dirc
rt = "NSA"
bias = 1
pnls = dix["pnls_"+rt.lower()]
sigs = ["MACROALL_RPS_CWS_ZN", "MARKETRISK_ZN"]
strats = [sig + "_PNL" + rt + str(bias) for sig in sigs]
pnls.plot_pnls(
title=None,
pnl_cats=strats + ["Long only"],
xcat_labels=None,
title_fontsize=14,
)
display(pnls.evaluate_pnls(pnl_cats=strats + ["Long only"]).round(3))
pnls.signal_heatmap(pnl_name=f"MACROALL_RPS_CWS_ZN_PNL" + rt + str(bias), figsize=(20, 10))
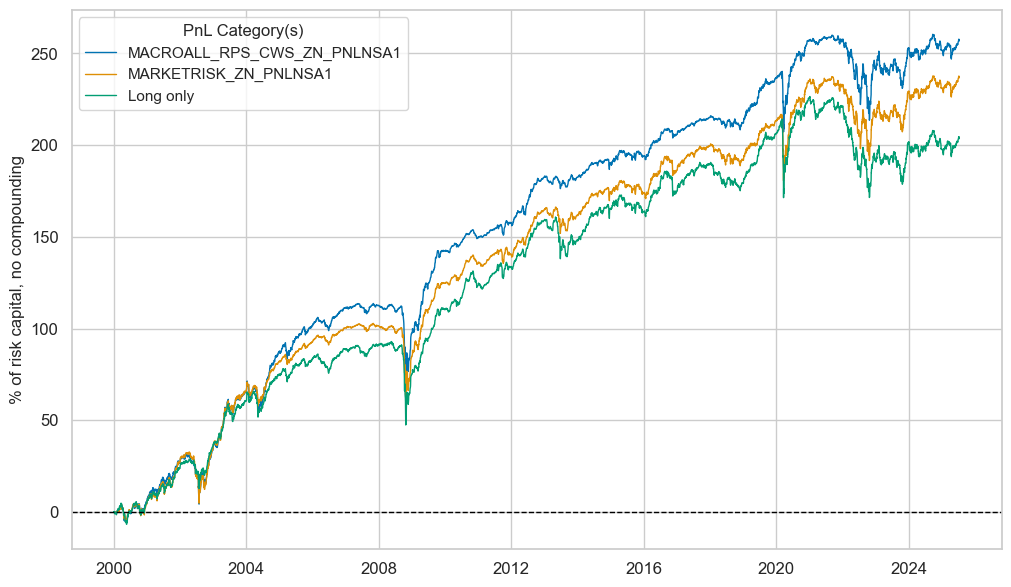
| xcat | MACROALL_RPS_CWS_ZN_PNLNSA1 | MARKETRISK_ZN_PNLNSA1 | Long only |
|---|---|---|---|
| Return % | 10.068208 | 9.279441 | 7.977636 |
| St. Dev. % | 10.0 | 10.0 | 10.0 |
| Sharpe Ratio | 1.006821 | 0.927944 | 0.797764 |
| Sortino Ratio | 1.416162 | 1.288616 | 1.076272 |
| Max 21-Day Draw % | -40.423659 | -37.448958 | -40.894491 |
| Max 6-Month Draw % | -46.023889 | -42.61806 | -44.780838 |
| Peak to Trough Draw % | -46.616176 | -45.719661 | -55.016014 |
| Top 5% Monthly PnL Share | 0.596812 | 0.620995 | 0.643287 |
| USD_EQXR_NSA correl | 0.281831 | 0.308574 | 0.270703 |
| UHY_CRXR_NSA correl | 0.349138 | 0.37899 | 0.343767 |
| UIG_CRXR_NSA correl | 0.349461 | 0.376858 | 0.330674 |
| Traded Months | 307 | 307 | 307 |
Customized relative signals #
Specs and panel test #
dict_relc = {
"sigs": ['MACROSPREAD_RPS_CWS_ZNvEM','MACRORATING_RPS_CWS_ZNvEM', 'MACROALL_RPS_CWS_ZNvEM', 'MARKETRISK_ZNvEM'],
"targs": ["FCBIXR_VT10vEM", "FCBIXR_NSAvEM"],
"cidx": cids_fc,
"start": "2000-01-01",
"black": black_fc,
}
dix = dict_relc
sigs = dix['sigs']
ret = dix["targs"][0]
cidx = dix["cidx"]
start = dix["start"]
black = dix["black"]
catregs = {}
for sig in sigs:
catregs[sig] = msp.CategoryRelations(
dfx,
xcats=[sig, ret],
cids=cidx,
freq="Q",
lag=1,
xcat_aggs=["mean", "sum"],
start=start,
blacklist=black,
)
msv.multiple_reg_scatter(
cat_rels=[v for k, v in catregs.items()],
ncol=2,
nrow=2,
figsize=(14, 12),
title=None,
title_fontsize=20,
xlab="End-of-quarter score",
ylab="Foreign currency bond index excess returns, vol targeted, %, next quarter",
coef_box="lower right",
prob_est="map",
single_chart=True,
subplot_titles=[dict_labels[key] for key in sigs]
)
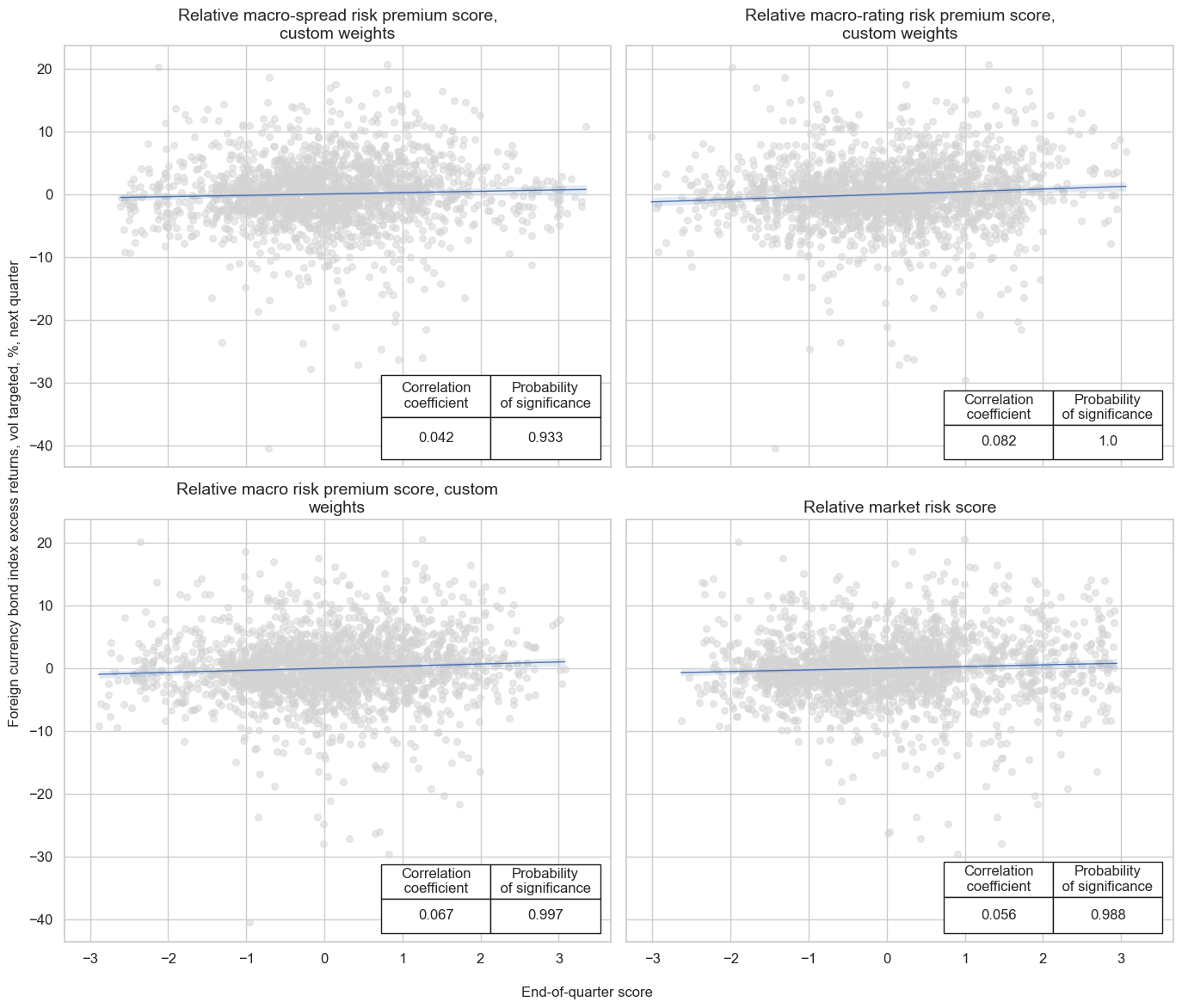
Accuracy and correlation check #
dix = dict_relc
sigs = dix['sigs']
ret = dix["targs"][0]
cidx = dix["cidx"]
start = dix["start"]
black = dix["black"]
srr = mss.SignalReturnRelations(
dfx,
rets=ret,
cids=cidx,
sigs=sigs,
# cosp=True,
freqs="M",
agg_sigs=["mean"], # for stability
start=start,
)
dix["srr"] = srr
dix = dict_relc
srr = dix["srr"]
tbl=srr.multiple_relations_table().round(3)
display(tbl.transpose())
| Return | FCBIXR_VT10vEM | |||
|---|---|---|---|---|
| Signal | MACROALL_RPS_CWS_ZNvEM | MACRORATING_RPS_CWS_ZNvEM | MACROSPREAD_RPS_CWS_ZNvEM | MARKETRISK_ZNvEM |
| Frequency | M | M | M | M |
| Aggregation | mean | mean | mean | mean |
| accuracy | 0.534 | 0.525 | 0.529 | 0.532 |
| bal_accuracy | 0.534 | 0.525 | 0.529 | 0.532 |
| pos_sigr | 0.498 | 0.522 | 0.488 | 0.491 |
| pos_retr | 0.500 | 0.499 | 0.501 | 0.500 |
| pos_prec | 0.534 | 0.523 | 0.530 | 0.533 |
| neg_prec | 0.534 | 0.527 | 0.527 | 0.531 |
| pearson | 0.040 | 0.050 | 0.024 | 0.031 |
| pearson_pval | 0.002 | 0.000 | 0.072 | 0.018 |
| kendall | 0.039 | 0.041 | 0.030 | 0.043 |
| kendall_pval | 0.000 | 0.000 | 0.001 | 0.000 |
| auc | 0.534 | 0.525 | 0.529 | 0.532 |
Naive PnLs #
dix = dict_relc
sigs = dix["sigs"]
ret = dix["targs"][0]
cidx = dix["cidx"]
start = dix["start"]
black = dix["black"]
pnls = msn.NaivePnL(
df=dfx,
ret=ret,
sigs=sigs,
cids=cidx,
start=start,
blacklist=black,
bms=bms,
)
for sig in sigs:
pnls.make_pnl(
sig=sig,
sig_op="zn_score_pan",
thresh=2,
sig_add=0,
rebal_freq="monthly",
neutral="zero",
pnl_name=sig + "_PNL",
rebal_slip=1,
vol_scale=10,
)
dix["pnls"] = pnls
dix = dict_relc
bias = 0
pnls = dix["pnls"]
sigs = dix["sigs"]
sigs = ["MACROSPREAD_RPS_CWS_ZNvEM", "MACRORATING_RPS_CWS_ZNvEM", "MACROALL_RPS_CWS_ZNvEM"]
strats = [sig + "_PNL" for sig in sigs]
pnl_labels = {
"MACROSPREAD_RPS_CWS_ZNvEM_PNL": "Spread-based relative macro risk premium score",
"MACRORATING_RPS_CWS_ZNvEM_PNL": "Ratings-based relative macro risk premium score",
"MACROALL_RPS_CWS_ZNvEM_PNL": "Composite relative macro risk premium score",
}
pnls.plot_pnls(
title="Naive PnL for relative risk-premia strategies, 24 EM sovereigns, 4-factor macro risk",
pnl_cats=strats,
xcat_labels=pnl_labels,
title_fontsize=14,
)
display(pnls.evaluate_pnls(pnl_cats=strats).round(3))
pnls.signal_heatmap(pnl_name=f"MACROALL_RPS_CWS_ZNvEM_PNL", figsize=(20, 10))
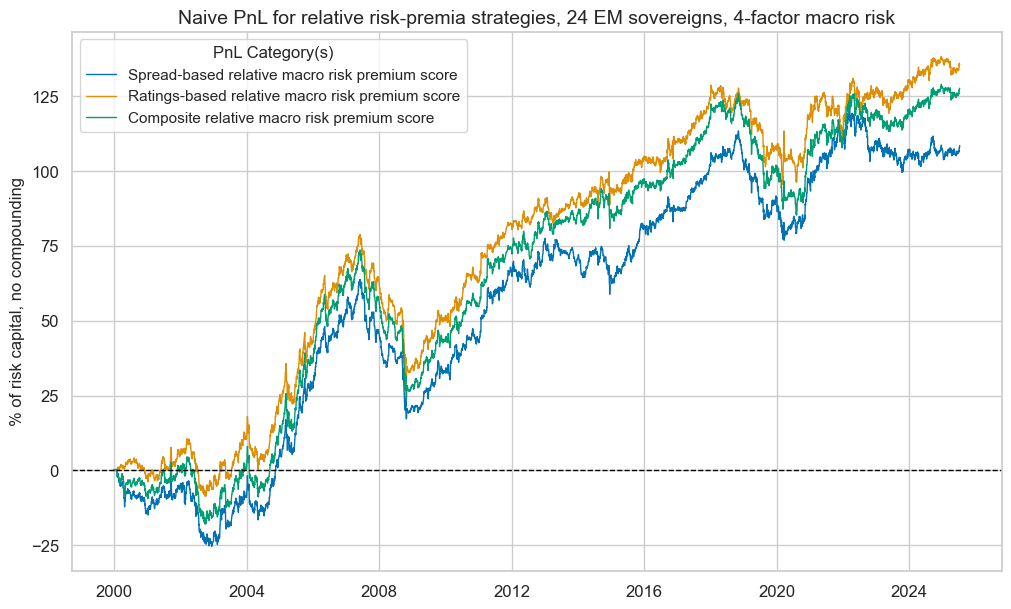
| xcat | MACROSPREAD_RPS_CWS_ZNvEM_PNL | MACRORATING_RPS_CWS_ZNvEM_PNL | MACROALL_RPS_CWS_ZNvEM_PNL |
|---|---|---|---|
| Return % | 4.255976 | 5.319186 | 5.008264 |
| St. Dev. % | 10.0 | 10.0 | 10.0 |
| Sharpe Ratio | 0.425598 | 0.531919 | 0.500826 |
| Sortino Ratio | 0.599296 | 0.751592 | 0.705644 |
| Max 21-Day Draw % | -16.477927 | -20.290186 | -19.037499 |
| Max 6-Month Draw % | -24.371469 | -28.475671 | -27.764184 |
| Peak to Trough Draw % | -46.543223 | -49.702669 | -49.978826 |
| Top 5% Monthly PnL Share | 0.992143 | 0.783188 | 0.835917 |
| USD_EQXR_NSA correl | 0.118208 | 0.176955 | 0.171197 |
| UHY_CRXR_NSA correl | 0.141007 | 0.18947 | 0.190258 |
| UIG_CRXR_NSA correl | 0.120558 | 0.173319 | 0.173795 |
| Traded Months | 307 | 307 | 307 |
EMBI Global proxy and modification #
Import EMBI global weights #
# Dictionary for labelling and mapping
dict_cids = {
"AED": ["AE", "UAE"],
"ARS": ["AR", "Argentina"],
"BRL": ["BR", "Brazil"],
"CLP": ["CL", "Chile"],
"CNY": ["CN", "China"],
"COP": ["CO", "Colombia"],
"EGP": ["EG", "Egypt"],
"DOP": ["DO", "Dominican Republic"],
"HUF": ["HU", "Hungary"],
"IDR": ["ID", "Indonesia"],
"INR": ["IN", "India"],
"MXN": ["MX", "Mexico"],
"MYR": ["MY", "Malaysia"],
"NGN": ["NG", "Nigeria"],
"OMR": ["OM", "Oman"],
"PAB": ["PA", "Panama"],
"PEN": ["PE", "Peru"],
"PHP": ["PH", "Philippines"],
"PLN": ["PL", "Poland"],
"QAR": ["QA", "Qatar"],
"SAR": ["SA", "Saudi Arabia"],
"RON": ["RO", "Romania"],
"RSD": ["CS", "Serbia"],
"RUB": ["RU", "Russia"],
"THB": ["TH", "Thailand"],
"TRY": ["TR", "Turkey"],
"UYU": ["UY", "Uruguay"],
"VEF": ["VE", "Venezuela"],
"ZAR": ["ZA", "South Africa"],
}
cids_fc
['AED',
'BRL',
'CLP',
'CNY',
'COP',
'DOP',
'EGP',
'HUF',
'IDR',
'INR',
'MXN',
'NGN',
'OMR',
'PEN',
'PHP',
'PLN',
'QAR',
'RON',
'RSD',
'RUB',
'SAR',
'TRY',
'UYU',
'ZAR']
# Import EMBI weights from DataQuery
## Mapping dataframe
expression_mapping_csv = "expression,country,cid\n"
DQ_ticker = "StatIndxWght"
for cid in cids_fc:
expression_mapping_csv += f'"DB(SAGE,FC_EMBIG_{dict_cids[cid][0]},{DQ_ticker})",{dict_cids[cid][0]},{cid}\n'
df_map = pd.read_csv(io.StringIO(expression_mapping_csv), sep=",")
extra_expression = {
"expression": "DB(SAGE,EMBIG,AM_IDX_TOT)",
"country": "ALL",
"cid": "ALL",
"ticker": "ALL_EMBI_IDX",
}
df_map["ticker"] = df_map["cid"] + "_" + "EMBIWGT"
df_map = pd.concat([df_map, pd.DataFrame([extra_expression])], ignore_index=True)
## Download wide dataframe from J.P. Morgan DataQuery
with JPMaQSDownload() as downloader:
dfw_weights = downloader.download(
expressions=df_map["expression"].tolist(),
start_date="1998-01-01",
dataframe_format="wide",
show_progress=True,
)
dfw_weights = dfw_weights.rename(columns=df_map.set_index("expression")["ticker"].to_dict())
st, ed = dfw_weights.index.min(), dfw_weights.index.max()
bdates = pd.bdate_range(st, ed, freq="B")
# Forward filling weights and convert to quantamental dataframe (and merge)
dfw_weights = dfw_weights.reindex(bdates).ffill()
dfw_weights.index.name = "real_date"
df_embi = msm.utils.ticker_df_to_qdf(dfw_weights)
dfx = msm.update_df(dfx, df_embi)
Downloading data from JPMaQS.
Timestamp UTC: 2025-07-09 08:56:12
Connection successful!
Requesting data: 100%|█████████████████████████████████████| 2/2 [00:00<00:00, 4.90it/s]
Downloading data: 100%|████████████████████████████████████| 2/2 [00:13<00:00, 6.93s/it]
Some dates are missing from the downloaded data.
305 out of 7179 dates are missing.
risk_macros = ['MACROSPREAD_RPS_ZN','MACRORATING_RPS_ZN', 'MACROALL_RPS_ZN', 'MARKETRISK_ZN']
mask = dfx["xcat"] == "EMBIWGT"
dfx.loc[mask, "value"] = dfx.loc[mask].groupby("real_date")["value"].transform(lambda x: (x / x.sum() ) * 1 )
Modified weights #
Calculation #
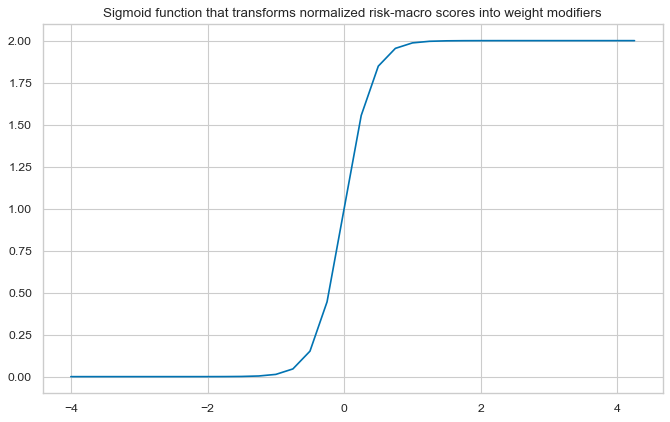
# Define appropriate sigmoid function for adjusting weights
amplitude = 2
steepness = 5
midpoint = 0
def sigmoid(x, a=amplitude, b=steepness, c=midpoint):
return a / (1 + np.exp(-b * (x - c)))
ar = np.array([i / 4 for i in range(-16, 18)])
plt.figure(figsize=(10, 6), dpi=80)
plt.plot(ar, sigmoid(ar))
plt.title("Sigmoid function that transforms normalized risk-macro scores into weight modifiers")
plt.show()
# Calculate adjusted weights
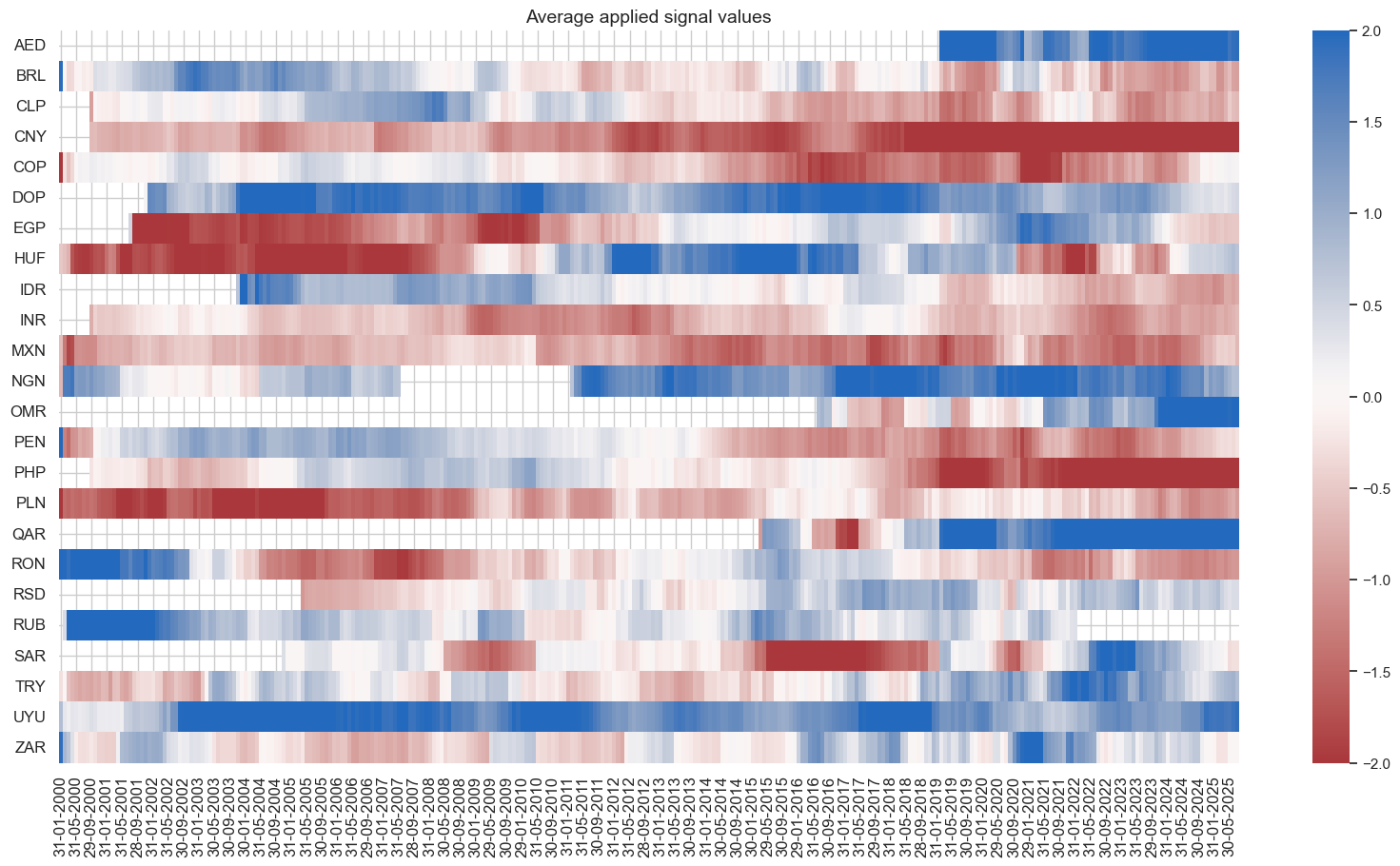
dfj = adjust_weights(
dfx,
weights_xcat="EMBIWGT",
adj_zns_xcat="MACROALL_RPS_ZN",
method="generic",
adj_func=sigmoid,
blacklist=black_fc,
cids=cidx,
adj_name="EMBIWGT_MOD",
)
dfj["value"] = dfj["value"] # remove after change in function
dfx = msm.update_df(dfx, dfj)
dict_labels["EMBIWGT"] = "EMBI Global proxy weights"
dict_labels["EMBIWGT_MOD"] = "EMBIG weights modified by macro risk premia"
# View timelines of weights
xcatx = ["EMBIWGT", "EMBIWGT_MOD"]
cidx = cids_fc
sdate = "2002-01-01"
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=4,
start=sdate,
same_y=False,
xcat_labels=dict_labels,
title="Standard weights and modified weights for the EMBI proxy index",
title_fontsize=22,
legend_fontsize=16,
height=2,
)
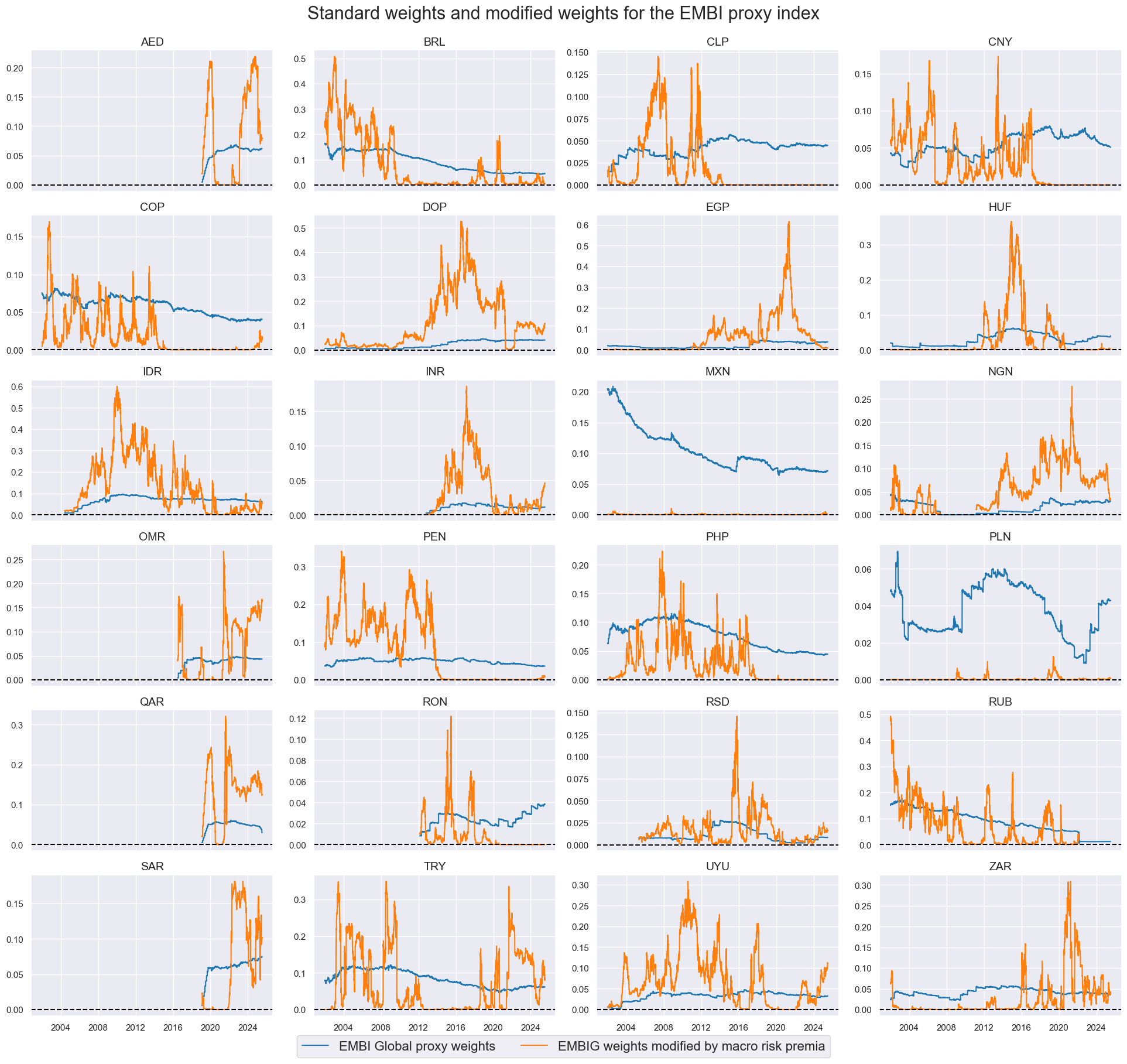
Evaluation #
dict_mod = {
"sigs": ["EMBIWGT_MOD", "EMBIWGT"],
"targ": "FCBIR_NSA",
"cidx": cids_fc,
"start": "2002-01-01",
"black": black_fc,
"srr": None,
"pnls": None,
}
dix = dict_mod
sigs = dix["sigs"]
ret = dix["targ"]
cidx = dix["cidx"]
start = dix["start"]
black = dix["black"]
pnls = msn.NaivePnL(
df=dfx,
ret=ret,
sigs=sigs,
cids=cidx,
start=start,
blacklist=black,
bms=bms,
)
for sig in sigs:
pnls.make_pnl(
sig=sig,
sig_op="raw",
rebal_freq="monthly",
neutral="zero",
rebal_slip=1,
vol_scale=None,
)
dix["pnls"] = pnls
dix = dict_mod
pnls = dix["pnls"]
sigs = dix["sigs"]
pnl_cats=["PNL_" + sig for sig in sigs]
pnls.plot_pnls(
title="EMBI proxy index and modified weights based on macro risk premia: naive PnLs",
pnl_cats=pnl_cats,
xcat_labels=[dict_labels[k] for k in sigs],
title_fontsize=14,
compounding=True,
)
pnls.evaluate_pnls(pnl_cats=pnl_cats)
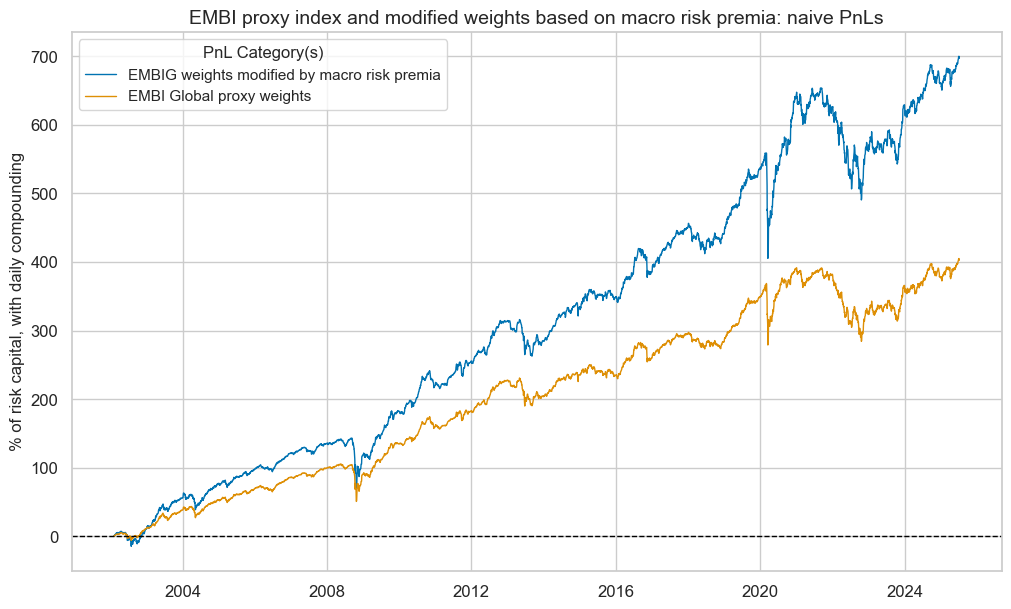
| xcat | PNL_EMBIWGT_MOD | PNL_EMBIWGT |
|---|---|---|
| Return % | 9.165722 | 7.09129 |
| St. Dev. % | 7.747423 | 6.2589 |
| Sharpe Ratio | 1.183067 | 1.132993 |
| Sortino Ratio | 1.637671 | 1.561661 |
| Max 21-Day Draw % | -30.643599 | -25.999432 |
| Max 6-Month Draw % | -34.396888 | -29.848671 |
| Peak to Trough Draw % | -35.156008 | -30.147379 |
| Top 5% Monthly PnL Share | 0.473556 | 0.467006 |
| USD_EQXR_NSA correl | 0.283995 | 0.293117 |
| UHY_CRXR_NSA correl | 0.354631 | 0.372223 |
| UIG_CRXR_NSA correl | 0.368565 | 0.383069 |
| Traded Months | 282 | 282 |
Adjusted weights #
dfa = msp.adjust_weights(
df=dfx,
weights_xcat="EMBIWGT",
adj_zns_xcat="MACROALL_RPS_ZN",
method="lincomb",
params=dict(min_score=-3, coeff_new=0.5),
blacklist=black_fc,
adj_name="EMBIWGT_ADJ",
)
dfx = msm.update_df(dfx, dfa)
dict_labels["EMBIWGT_ADJ"] = (
"EMBIG weights adjusted towards weights of macro risk premium scores"
)
# View timelines of weights
xcatx = ["EMBIWGT", "EMBIWGT_ADJ"]
cidx = cids_fc
sdate = "2002-01-01"
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=4,
start=sdate,
same_y=False,
xcat_labels=dict_labels,
title="Standard weights and adjusted weights for the EMBI proxy index",
title_fontsize=22,
legend_fontsize=16,
height=2,
)
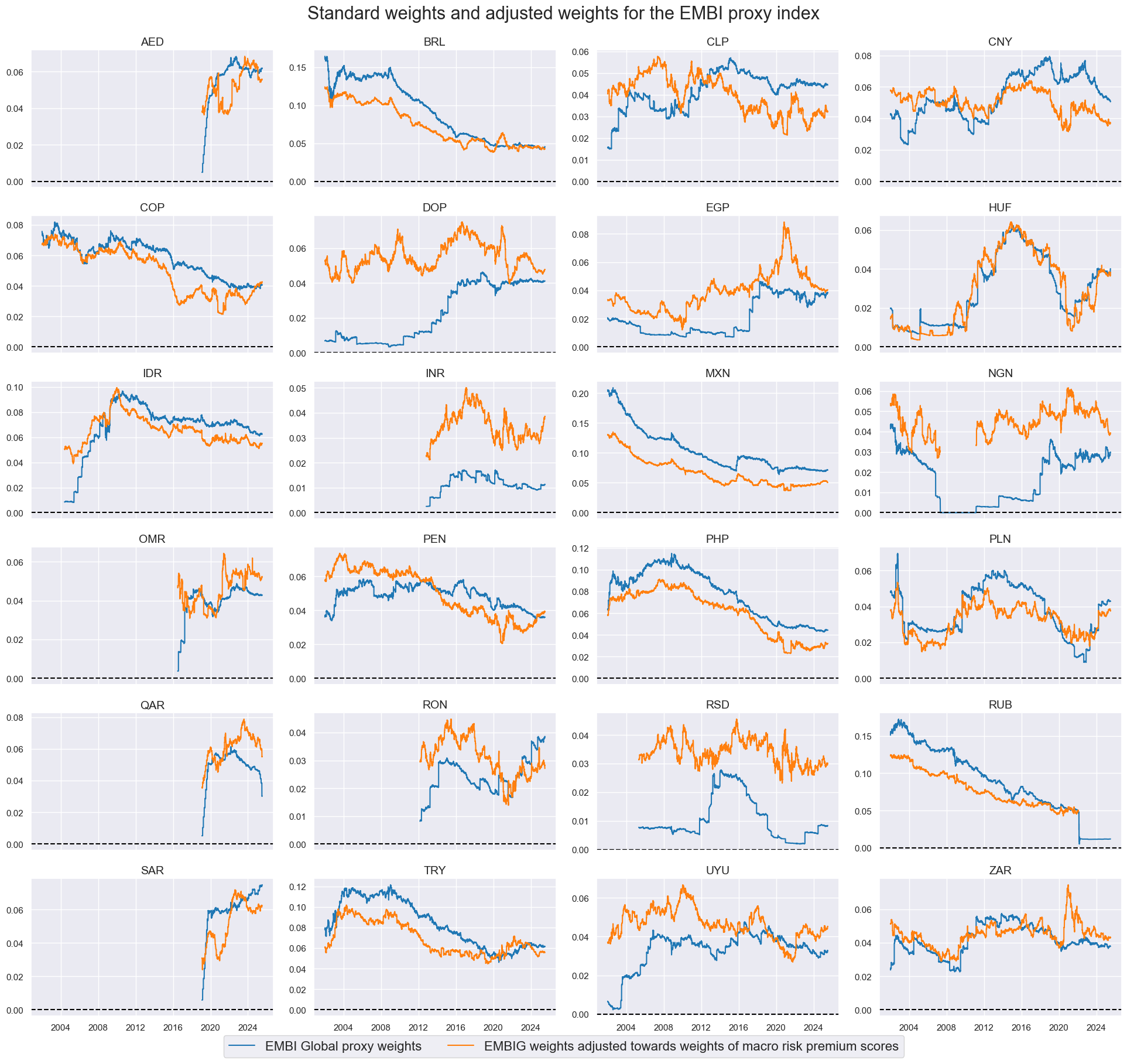
Evaluation #
dict_adj = {
"sigs": ["EMBIWGT_ADJ", "EMBIWGT"],
"targ": "FCBIR_NSA",
"cidx": cids_fc,
"start": "2002-01-01",
"black": black_fc,
"srr": None,
"pnls": None,
}
dix = dict_adj
sigs = dix["sigs"]
ret = dix["targ"]
cidx = dix["cidx"]
start = dix["start"]
black = dix["black"]
pnls = msn.NaivePnL(
df=dfx,
ret=ret,
sigs=sigs,
cids=cidx,
start=start,
blacklist=black,
bms=bms,
)
for sig in sigs:
pnls.make_pnl(
sig=sig,
sig_op="raw",
rebal_freq="monthly",
neutral="zero",
rebal_slip=1,
vol_scale=None,
)
dix["pnls"] = pnls
dix = dict_adj
pnls = dix["pnls"]
sigs = dix["sigs"]
pnl_cats=["PNL_" + sig for sig in sigs]
pnls.plot_pnls(
title="EMBI proxy index and adjusted weights based on macro risk premium scores: naive PnLs",
pnl_cats=pnl_cats,
xcat_labels=[dict_labels[k] for k in sigs],
title_fontsize=14,
compounding=True,
)
pnls.evaluate_pnls(pnl_cats=pnl_cats)
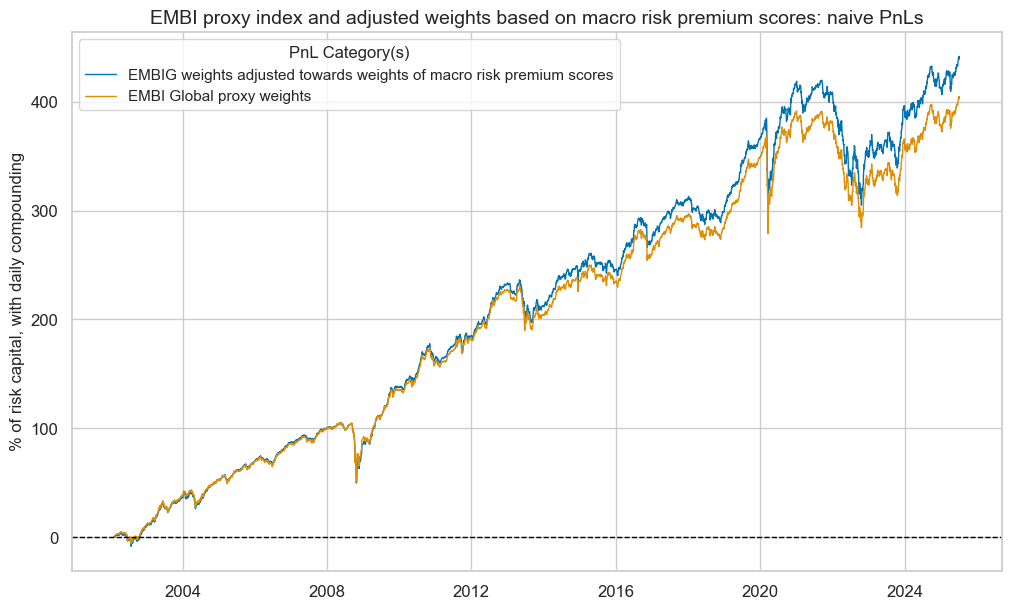
| xcat | PNL_EMBIWGT_ADJ | PNL_EMBIWGT |
|---|---|---|
| Return % | 7.381873 | 7.09129 |
| St. Dev. % | 6.098419 | 6.2589 |
| Sharpe Ratio | 1.210457 | 1.132993 |
| Sortino Ratio | 1.658746 | 1.561661 |
| Max 21-Day Draw % | -26.731977 | -25.999432 |
| Max 6-Month Draw % | -30.531728 | -29.848671 |
| Peak to Trough Draw % | -30.938537 | -30.147379 |
| Top 5% Monthly PnL Share | 0.45935 | 0.467006 |
| USD_EQXR_NSA correl | 0.289818 | 0.293117 |
| UHY_CRXR_NSA correl | 0.364825 | 0.372223 |
| UIG_CRXR_NSA correl | 0.370317 | 0.383069 |
| Traded Months | 282 | 282 |