Cross-country rates relative value with macro factors #
import numpy as np
import pandas as pd
from pandas import Timestamp
import matplotlib.pyplot as plt
from datetime import date
import seaborn as sns
import os
from datetime import datetime
import macrosynergy.management as msm
import macrosynergy.panel as msp
import macrosynergy.signal as mss
import macrosynergy.pnl as msn
import macrosynergy.visuals as msv
import macrosynergy.learning as msl
from macrosynergy.management.utils import merge_categories
from macrosynergy.download import JPMaQSDownload
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import root_mean_squared_error, make_scorer
from sklearn.linear_model import Ridge
pd.set_option("display.width", 400)
import warnings
warnings.simplefilter("ignore")
# Cross-sections of interest
cids_dm = ["AUD", "CAD", "CHF", "EUR", "GBP", "JPY", "NOK", "NZD", "SEK", "USD"]
cids_latm = ["BRL", "COP", "CLP", "MXN"] # Latam countries
cids_emea = ["CZK", "HUF", "ILS", "PLN", "RUB", "TRY", "ZAR"] # EMEA countries
cids_emas = ["IDR", "INR", "KRW", "MYR", "THB", "TWD"] # EM Asia countries
cids_em = cids_latm + cids_emea + cids_emas
cids = sorted(cids_dm + cids_em)
cids_dux = sorted(list(set(cids) - set(["IDR", "INR", "NZD"])))
# Quantamental categories of interest
infl = [
"CPIH_SA_P1M1ML12",
"CPIH_SJA_P6M6ML6AR",
"CPIH_SJA_P3M3ML3AR",
"CPIC_SA_P1M1ML12",
"CPIC_SJA_P6M6ML6AR",
"CPIC_SJA_P3M3ML3AR",
"INFTEFF_NSA",
]
infl_changes = [
"CPIH_SA_P1M1ML12_D1M1ML3",
"CPIC_SA_P1M1ML12_D1M1ML3",
]
infs = infl + infl_changes
irs = [
"RYLDIRS05Y_NSA",
"DU05YCRY_NSA",
"DU05YCRY_VT10",
]
reer = [
"REEROADJ_NSA_P1W4WL1",
"REEROADJ_NSA_P1M1ML12",
"REEROADJ_NSA_P1M12ML1",
"REEROADJ_NSA_P1M60ML1",
]
reals = irs + reer
external_balances = [
"CABGDPRATIO_NSA_12MMA",
"CABGDPRATIOE_NSA_12MMA",
"CABGDPRATIO_SA",
"CABGDPRATIO_SA_3MMA",
"BXBGDPRATIO_NSA_12MMA",
"BXBGDPRATIOE_NSA_12MMA",
]
mtb_changes = [
"MTBGDPRATIO_SA_3MMA_D1M1ML3",
"MTBGDPRATIO_SA_6MMA_D1M1ML6",
"MTBGDPRATIO_NSA_12MMA_D1M1ML3",
]
interv_liquidity = [
"INTLIQGDP_NSA_D1M1ML1",
"INTLIQGDP_NSA_D1M1ML3",
"INTLIQGDP_NSA_D1M1ML6",
]
xliq = external_balances + mtb_changes + interv_liquidity
gdp = [
"INTRGDPv5Y_NSA_P1M1ML12_3MMA",
"RGDPTECHv5Y_SA_P1M1ML12_3MMA",
"RGDP_SA_P1Q1QL4_20QMA",
]
pcons = [
"RRSALES_SA_P1M1ML12",
"RRSALES_SA_P1M1ML12_3MMA",
"RRSALES_SA_P1Q1QL4",
"RPCONS_SA_P1Q1QL4",
"RPCONS_SA_P1M1ML12_3MMA",
"RPCONS_SA_P1Q1QL1AR",
"RPCONS_SA_P2Q2QL2AR",
"RPCONS_SA_P3M3ML3AR",
"RPCONS_SA_P6M6ML6AR",
]
growth = gdp + pcons
credit = [
"PCREDITBN_SJA_P1M1ML12",
]
house_prices = [
"HPI_SA_P1M1ML12",
"HPI_SA_P1M1ML12_3MMA",
"HPI_SA_P1Q1QL4",
"HPI_SA_P3M3ML3AR",
"HPI_SA_P6M6ML6AR",
"HPI_SA_P1Q1QL1AR",
"HPI_SA_P2Q2QL2AR",
]
credhouse = credit + house_prices
govs = ["GGFTGDPRATIO_NSA", "GGOBGDPRATIO_NSA"]
main = (
infl
+ infs
+ reals
+ xliq
+ growth
+ credhouse
+ govs
)
econ = ["FXTARGETED_NSA", "FXUNTRADABLE_NSA"]
mkts = [
"DU02YXR_VT10",
"DU05YXR_NSA",
"DU05YXR_VT10",
"DU10YXR_VT10",
]
xcats = main + econ + mkts
# Resultant tickers for download
xtra = ["USD_EQXR_NSA", "USD_GB10YXR_NSA"]
tickers = [cid + "_" + xcat for cid in cids for xcat in xcats] + xtra
# Download series from J.P. Morgan DataQuery by tickers
start_date = "2000-01-01"
end_date = None
# Retrieve credentials
oauth_id = os.getenv("DQ_CLIENT_ID") # Replace with own client ID
oauth_secret = os.getenv("DQ_CLIENT_SECRET") # Replace with own secret
# Download from DataQuery
with JPMaQSDownload(client_id=oauth_id, client_secret=oauth_secret) as downloader:
df = downloader.download(
tickers=tickers,
start_date=start_date,
end_date=end_date,
metrics=["value"],
suppress_warning=True,
show_progress=True,
)
dfx = df.copy()
dfx.info()
Downloading data from JPMaQS.
Timestamp UTC: 2025-10-22 14:59:22
Connection successful!
Requesting data: 100%|██████████| 76/76 [00:15<00:00, 4.93it/s]
Downloading data: 100%|██████████| 76/76 [00:25<00:00, 2.96it/s]
Some expressions are missing from the downloaded data. Check logger output for complete list.
228 out of 1514 expressions are missing. To download the catalogue of all available expressions and filter the unavailable expressions, set `get_catalogue=True` in the call to `JPMaQSDownload.download()`.
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 8116912 entries, 0 to 8116911
Data columns (total 4 columns):
# Column Dtype
--- ------ -----
0 real_date datetime64[ns]
1 cid object
2 xcat object
3 value float64
dtypes: datetime64[ns](1), float64(1), object(2)
memory usage: 247.7+ MB
Availability, renaming and blacklisting #
Renaming quarterly categories #
dict_repl = {
"HPI_SA_P1Q1QL4": "HPI_SA_P1M1ML12_3MMA",
"HPI_SA_P1Q1QL1AR": "HPI_SA_P3M3ML3AR",
"HPI_SA_P2Q2QL2AR": "HPI_SA_P6M6ML6AR",
# Real retail sales
"RRSALES_SA_P1Q1QL4": "RRSALES_SA_P1M1ML12_3MMA",
"RPCONS_SA_P1Q1QL4": "RPCONS_SA_P1M1ML12_3MMA",
"RPCONS_SA_P1Q1QL1AR": "RPCONS_SA_P3M3ML3AR",
"RPCONS_SA_P2Q2QL2AR": "RPCONS_SA_P6M6ML6AR",
}
for key, value in dict_repl.items():
dfx["xcat"] = dfx["xcat"].str.replace(key, value)
Check availability #
xcatx = infs
cidx = cids_dux
msm.check_availability(df=dfx, xcats=xcatx, cids=cidx, missing_recent=False)
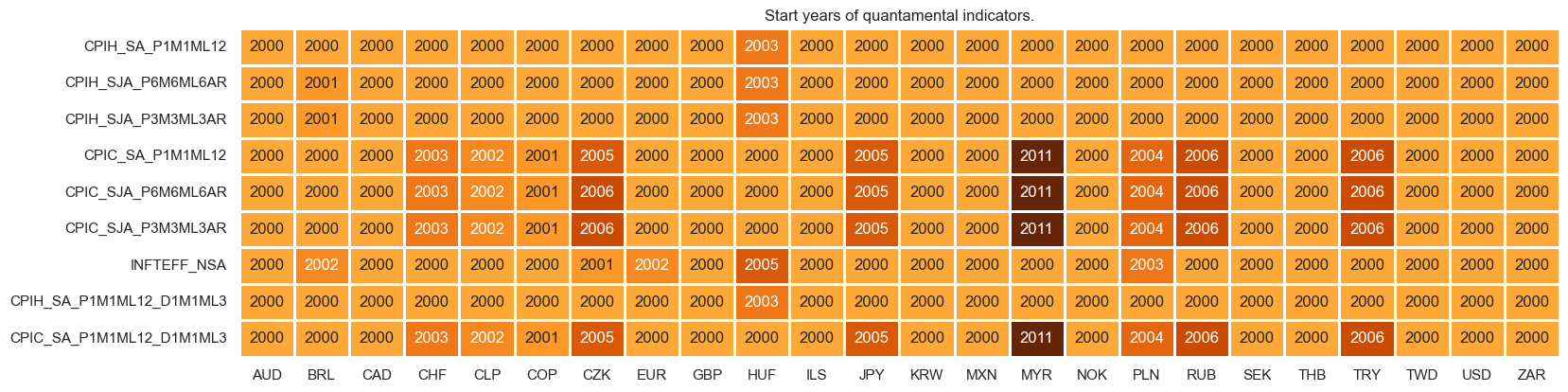
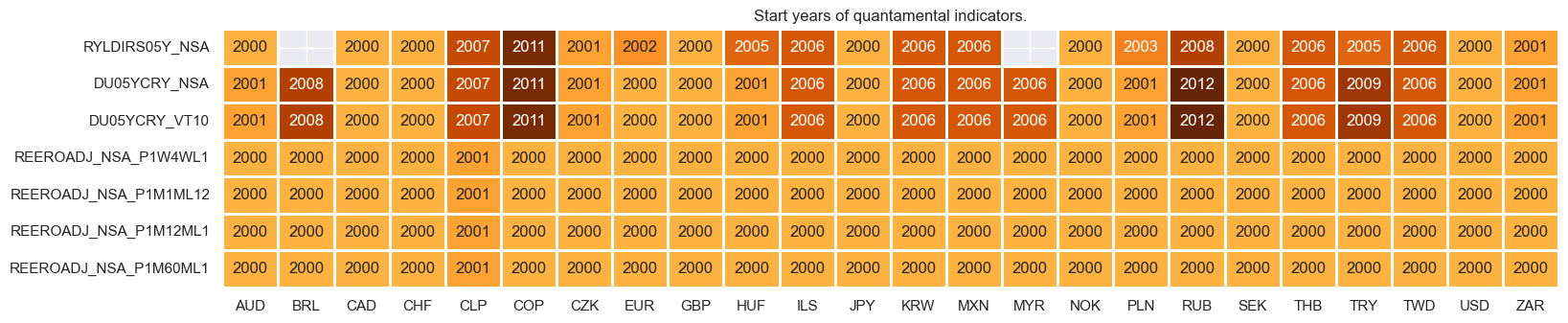
xcatx = reals
cidx = cids_dux
msm.check_availability(df=dfx, xcats=xcatx, cids=cidx, missing_recent=False)
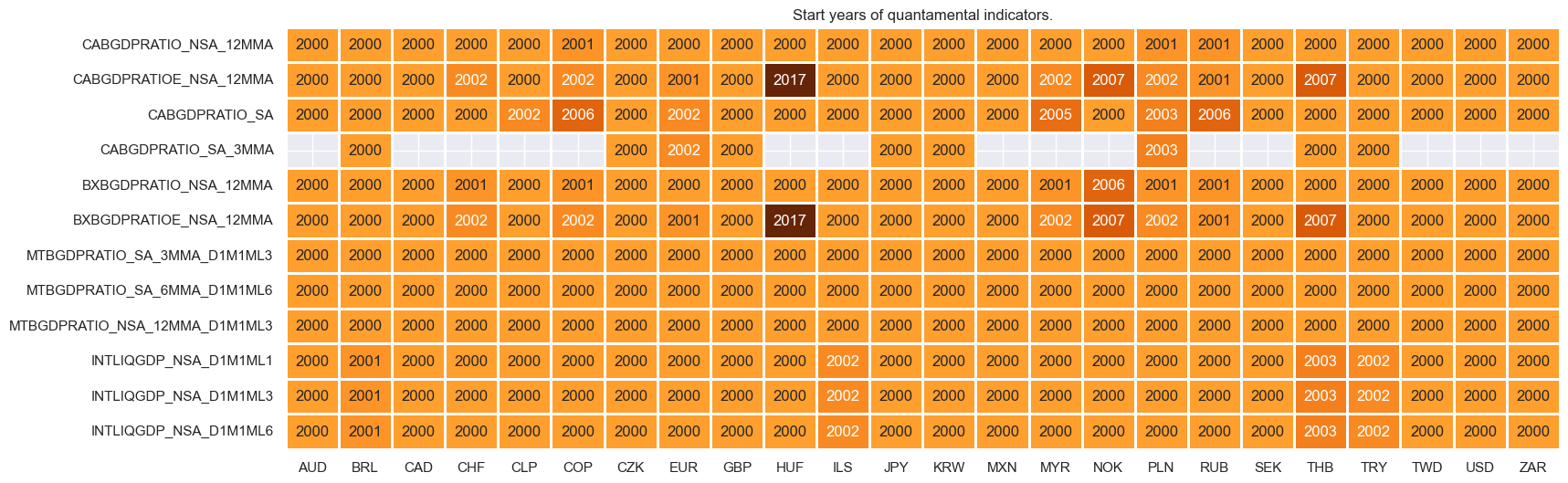
xcatx = xliq
cidx = cids_dux
msm.check_availability(df=dfx, xcats=xcatx, cids=cidx, missing_recent=False)
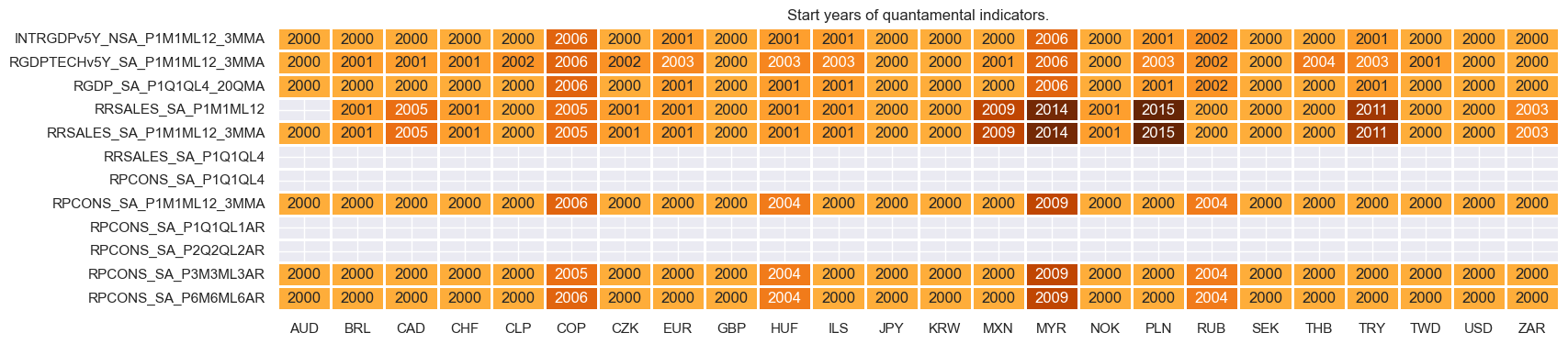
xcatx = growth
cidx = cids_dux
msm.check_availability(df=dfx, xcats=xcatx, cids=cidx, missing_recent=False)
xcatx = credhouse
cidx = cids_dux
msm.check_availability(df=dfx, xcats=xcatx, cids=cidx, missing_recent=False)

xcatx = govs
cidx = cids_dux
msm.check_availability(df=dfx, xcats=xcatx, cids=cidx, missing_recent=False)

Blacklisting dictionary for empirical research #
# Create blacklisting dictionary
dfb = df[df["xcat"].isin(["FXTARGETED_NSA", "FXUNTRADABLE_NSA"])].loc[
:, ["cid", "xcat", "real_date", "value"]
]
dfba = (
dfb.groupby(["cid", "real_date"])
.aggregate(value=pd.NamedAgg(column="value", aggfunc="max"))
.reset_index()
)
dfba["xcat"] = "FXBLACK"
fxblack = msp.make_blacklist(dfba, "FXBLACK")
fxblack
{'BRL': (Timestamp('2012-12-03 00:00:00'), Timestamp('2013-09-30 00:00:00')),
'CHF': (Timestamp('2011-10-03 00:00:00'), Timestamp('2015-01-30 00:00:00')),
'CZK': (Timestamp('2014-01-01 00:00:00'), Timestamp('2017-07-31 00:00:00')),
'ILS': (Timestamp('2000-01-03 00:00:00'), Timestamp('2005-12-30 00:00:00')),
'INR': (Timestamp('2000-01-03 00:00:00'), Timestamp('2004-12-31 00:00:00')),
'MYR_1': (Timestamp('2000-01-03 00:00:00'), Timestamp('2007-11-30 00:00:00')),
'MYR_2': (Timestamp('2018-07-02 00:00:00'), Timestamp('2025-10-21 00:00:00')),
'RUB_1': (Timestamp('2000-01-03 00:00:00'), Timestamp('2005-11-30 00:00:00')),
'RUB_2': (Timestamp('2022-02-01 00:00:00'), Timestamp('2025-10-21 00:00:00')),
'THB': (Timestamp('2007-01-01 00:00:00'), Timestamp('2008-11-28 00:00:00')),
'TRY_1': (Timestamp('2000-01-03 00:00:00'), Timestamp('2003-09-30 00:00:00')),
'TRY_2': (Timestamp('2020-01-01 00:00:00'), Timestamp('2024-07-31 00:00:00'))}
Factor engineering and checks #
dict_facts = {}
Relative inflation shortfall ratios #
# Base indicators and score weights
dict_xinfl = {
"CPIH_SA_P1M1ML12": (1/6, -1),
"CPIH_SJA_P6M6ML6AR": (1/6, -1),
"CPIH_SJA_P3M3ML3AR": (1/6, -1),
"CPIC_SA_P1M1ML12": (1/6, -1),
"CPIC_SJA_P6M6ML6AR": (1/6, -1),
"CPIC_SJA_P3M3ML3AR": (1/6, -1),
}
# Effective target capped at 2%
dfa = msp.panel_calculator(df, ["INFTEBASIS = INFTEFF_NSA.clip(lower=2)"], cids=cids_dux)
dfx = msm.update_df(dfx, dfa)
# Excess inflation ratios
cidx = cids_dux
xcatx = list(dict_xinfl.keys())
for xc in xcatx:
calcs = [f"{xc}vIETR = ( {xc} - INFTEFF_NSA ) / INFTEBASIS",]
dfa = msp.panel_calculator(dfx, calcs=calcs, cids=cids_dux)
dfx = msm.update_df(dfx, dfa)
cidx = cids_dux
xcatx = [xc + "vIETR" for xc in list(dict_xinfl.keys())]
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=4,
same_y=True,
all_xticks=True,
size=(12, 7),
aspect=1.8
)
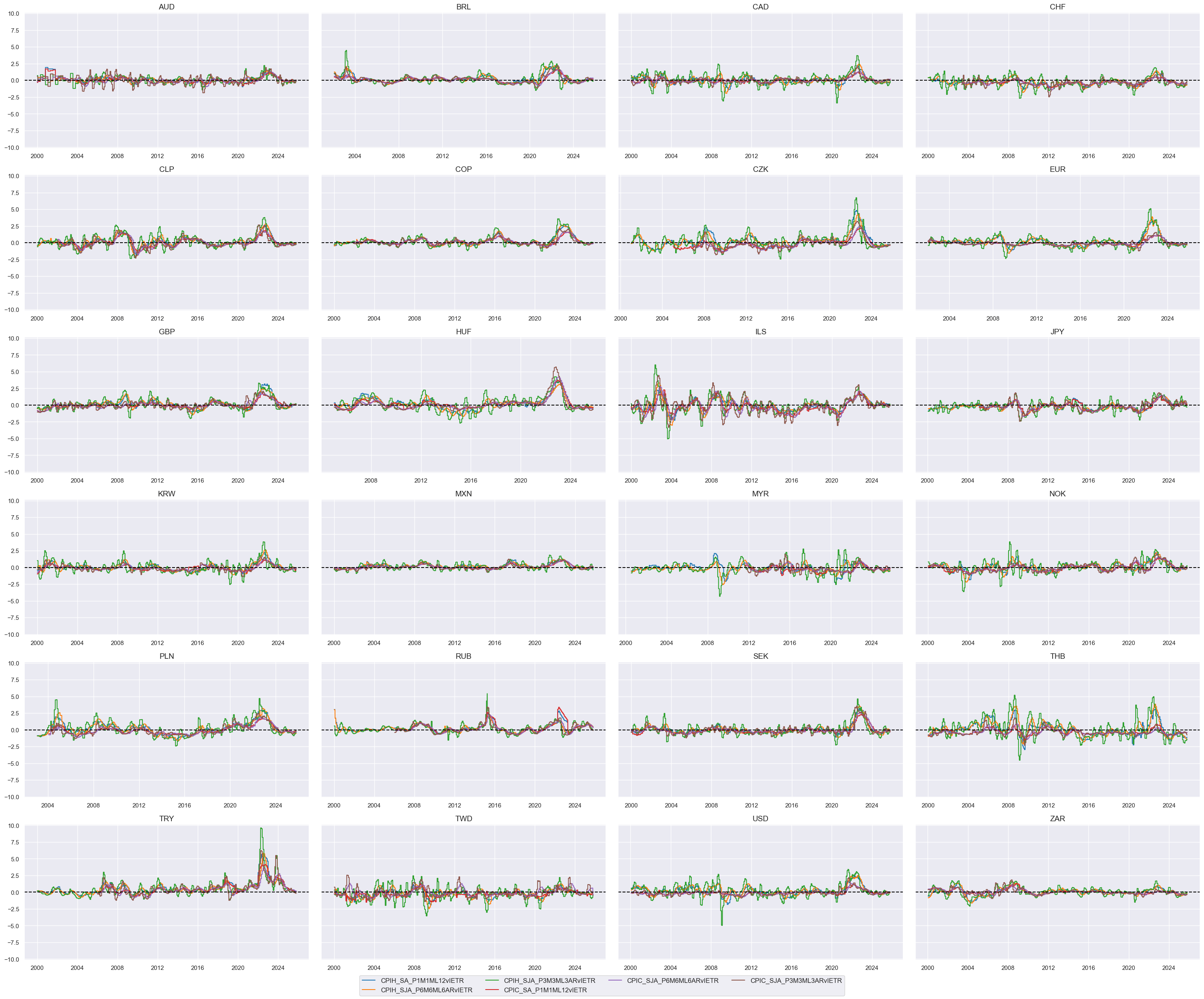
# Relative value of constituents
cidx = cids_dux
xcatx = [xc + "vIETR" for xc in list(dict_xinfl.keys())]
dfa = msp.make_relative_value(
df=dfx,
xcats=xcatx,
cids=cidx,
blacklist=fxblack,
postfix="vGLB",
)
dfx = msm.update_df(dfx, dfa)
# Scoring of relative values
cidx = cids_dux
xcatx = [xc + "vIETRvGLB" for xc in list(dict_xinfl.keys())]
dfa = pd.DataFrame(columns=dfx.columns)
for xc in xcatx:
dfaa = msp.make_zn_scores(
dfx,
xcat=xc,
cids=cidx,
sequential=True,
min_obs=261 * 3,
neutral="zero",
pan_weight=1,
thresh=3,
postfix="_ZN",
est_freq="m",
)
dfa = msm.update_df(dfa, dfaa)
dfx = msm.update_df(dfx, dfa)
cidx = cids_dux
xcatx = [xc + "vIETRvGLB_ZN" for xc in list(dict_xinfl.keys())]
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=4,
same_y=True,
all_xticks=True,
size=(12, 7),
aspect=1.8
)
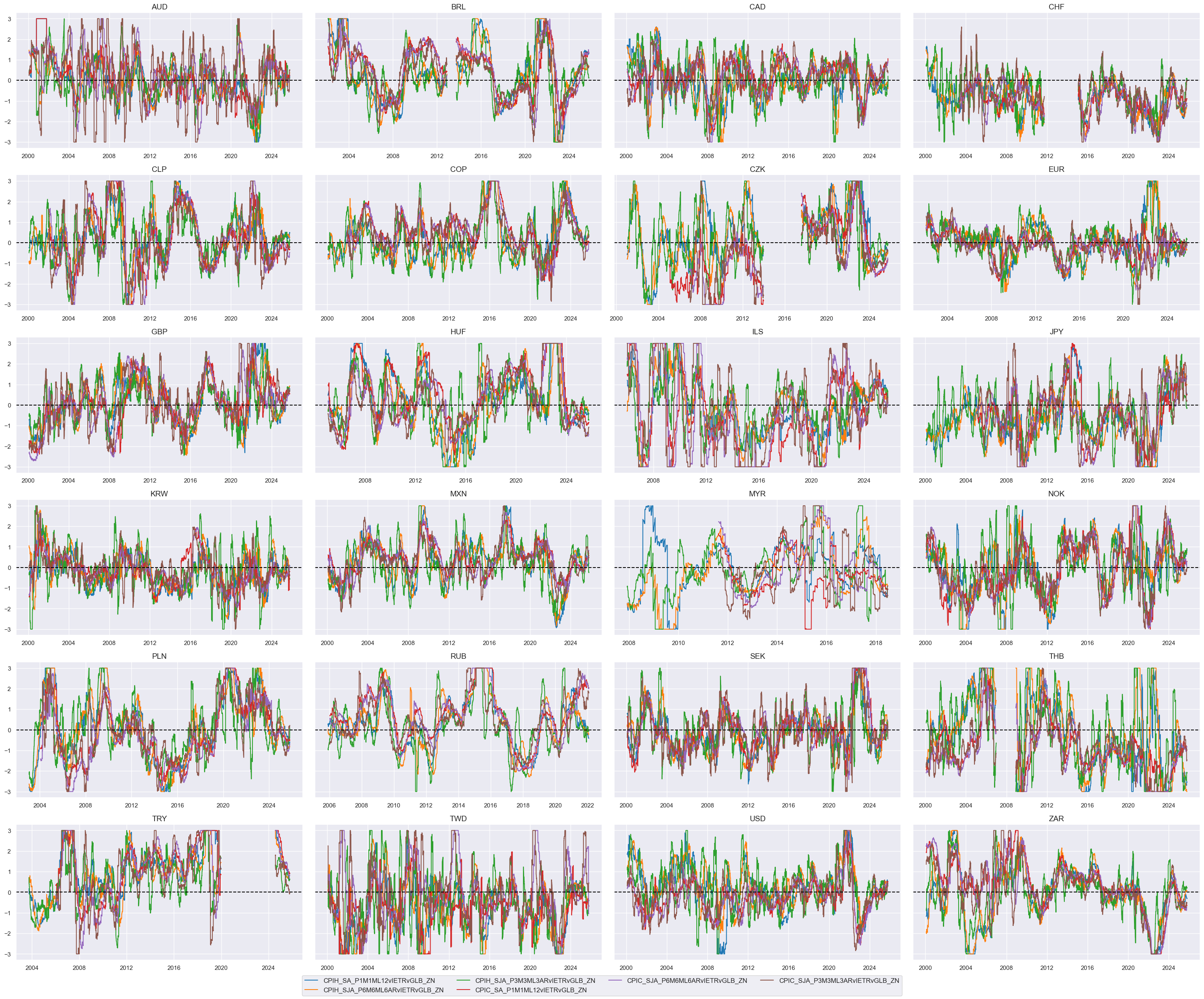
# Weighted linear combination
cidx = cids_dux
dix = dict_xinfl
xcatx = [k + "vIETRvGLB_ZN" for k in list(dix.keys())]
weights = [v[0] for v in list(dix.values())]
signs = [v[1] for v in list(dix.values())]
czs = "XINFLvGLB_NEG"
dfa = msp.linear_composite(
dfx,
xcats=xcatx,
cids=cidx,
weights=weights,
signs=signs,
normalize_weights=True,
complete_xcats=False, # score works with what is available
new_xcat=czs,
)
dfx = msm.update_df(dfx, dfa)
# Re-scoring
dfa = msp.make_zn_scores(
dfx,
xcat=czs,
cids=cidx,
sequential=True,
min_obs=261 * 3,
neutral="zero",
pan_weight=1,
thresh=3,
postfix="_ZN",
est_freq="m",
)
dfx = msm.update_df(dfx, dfa)
dict_facts[czs + "_ZN"] = "Relative inflation shortfall"
cids_dux
xcatx = 'XINFLvGLB_NEG_ZN'
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=4,
same_y=True,
all_xticks=True,
size=(12, 7),
aspect=1.8
)
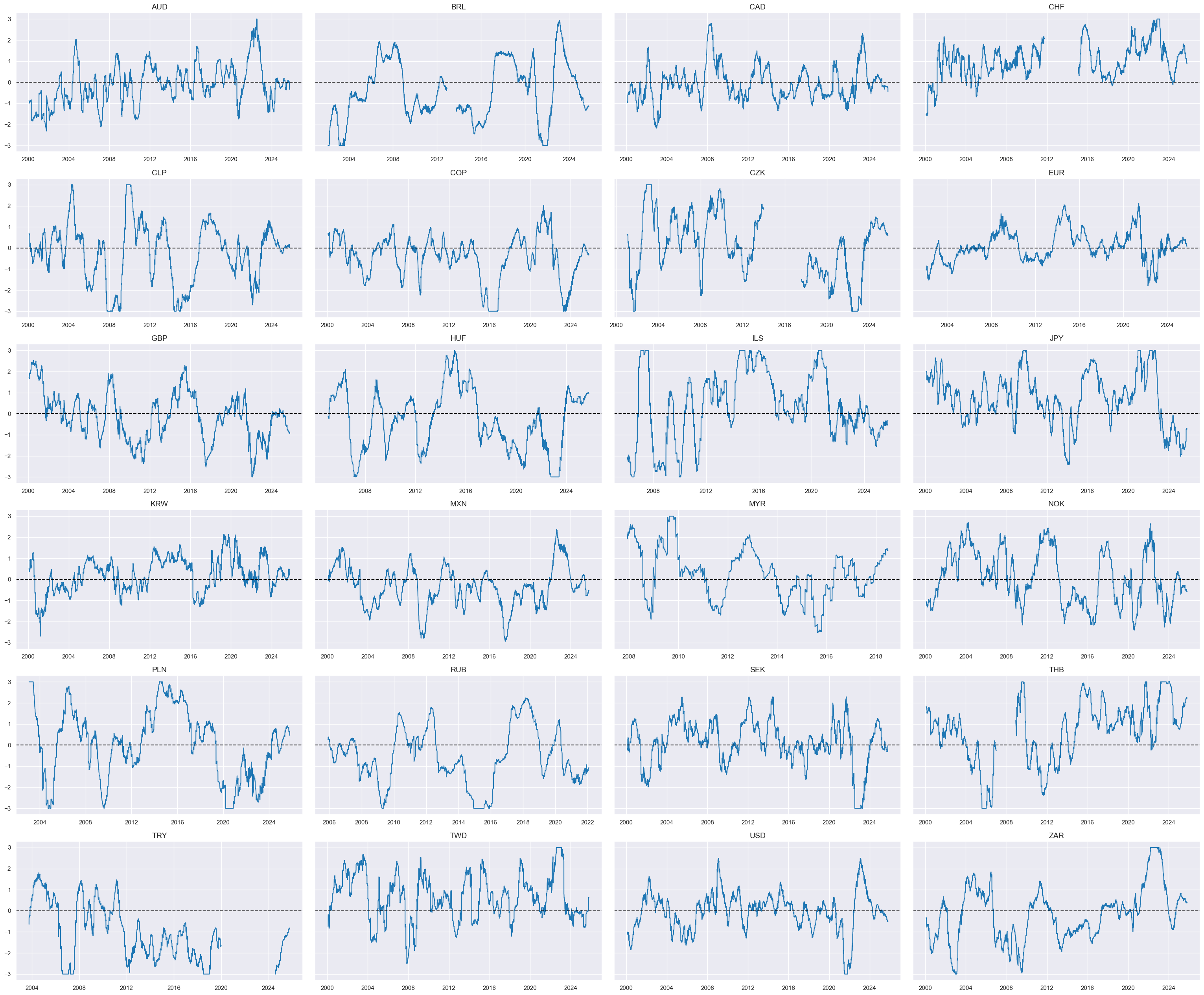
Relative disinflation ratios #
dict_infl_chg = {
"CPIH_SA_P1M1ML12_D1M1ML3": (1/2, -1),
"CPIC_SA_P1M1ML12_D1M1ML3": (1/2, -1),
}
cidx = cids_dux
xcatx = list(dict_infl_chg.keys())
for xc in xcatx:
calcs = [f"{xc}R = {xc} / INFTEBASIS",]
dfa = msp.panel_calculator(dfx, calcs=calcs, cids=cids_dux)
dfx = msm.update_df(dfx, dfa)
cidx = cids_dux
xcatx = [xc + "R" for xc in list(dict_infl_chg.keys())]
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=4,
same_y=False,
all_xticks=True,
size=(12, 7),
aspect=1.8
)
# Relative value of constituents
cidx = cids_dux
xcatx = [xc + "R" for xc in list(dict_infl_chg.keys())]
dfa = msp.make_relative_value(
df=dfx,
xcats=xcatx,
cids=cidx,
blacklist=fxblack,
postfix="vGLB",
)
dfx = msm.update_df(dfx, dfa)
# Scoring of relative values
cidx = cids_dux
xcatx = [xc + "RvGLB" for xc in list(dict_infl_chg.keys())]
dfa = pd.DataFrame(columns=dfx.columns)
for xc in xcatx:
dfaa = msp.make_zn_scores(
dfx,
xcat=xc,
cids=cidx,
sequential=True,
min_obs=261 * 3,
neutral="zero",
pan_weight=1,
thresh=3,
postfix="_ZN",
est_freq="m",
)
dfa = msm.update_df(dfa, dfaa)
dfx = msm.update_df(dfx, dfa)
cidx = cids_dux
xcatx = [xc + "RvGLB_ZN" for xc in list(dict_infl_chg.keys())]
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=4,
same_y=True,
all_xticks=True,
size=(12, 7),
aspect=1.8
)
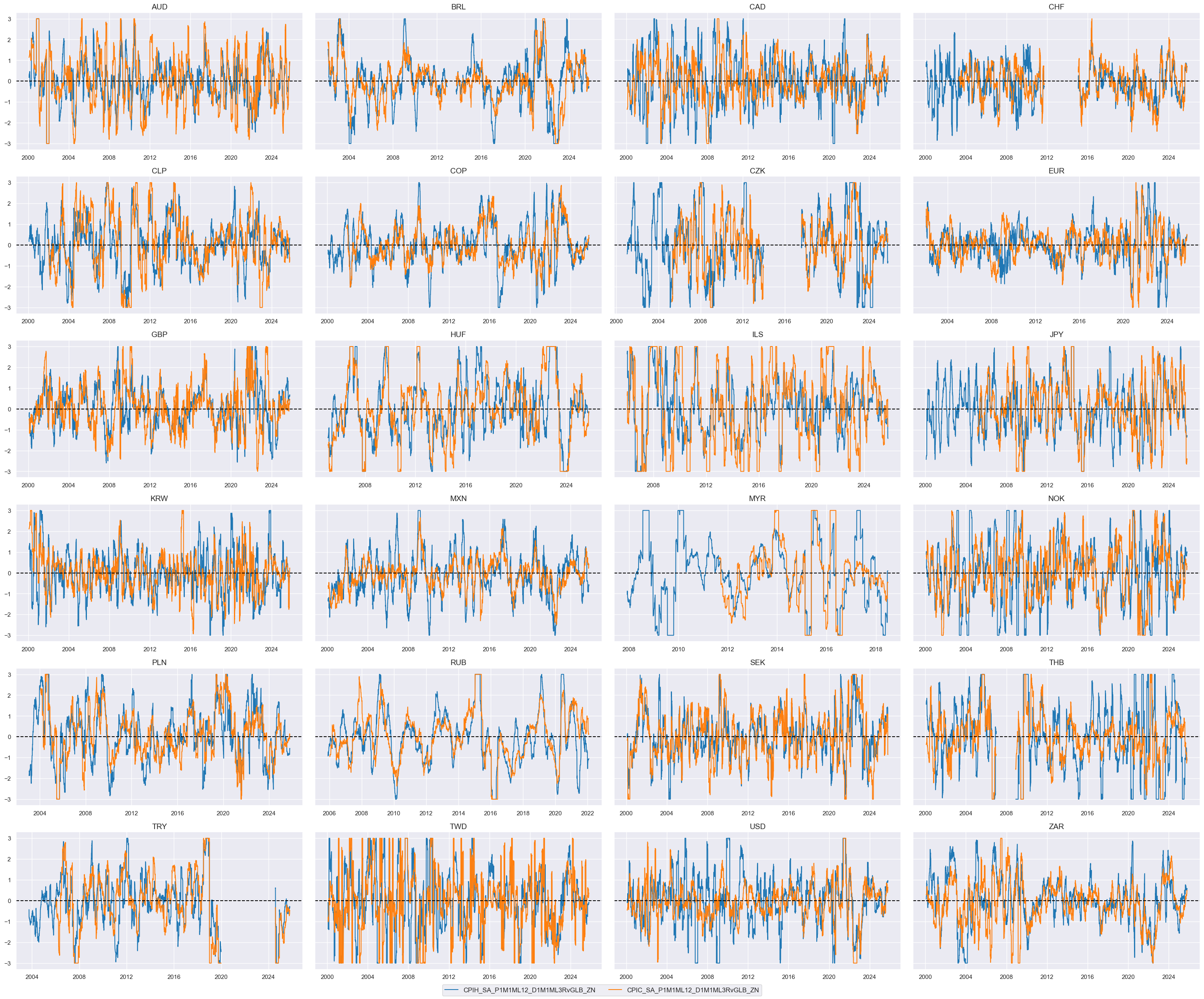
# Weighted linear combination
cidx = cids_dux
dix = dict_infl_chg
xcatx = [k + "RvGLB_ZN" for k in list(dix.keys())]
weights = [v[0] for v in list(dix.values())]
signs = [v[1] for v in list(dix.values())]
czs = "INFLCHGRvGLB_NEG"
dfa = msp.linear_composite(
dfx,
xcats=xcatx,
cids=cidx,
weights=weights,
signs=signs,
normalize_weights=True,
complete_xcats=False, # score works with what is available
new_xcat=czs,
)
dfx = msm.update_df(dfx, dfa)
# Re-scoring
dfa = msp.make_zn_scores(
dfx,
xcat=czs,
cids=cidx,
sequential=True,
min_obs=261 * 3,
neutral="zero",
pan_weight=1,
thresh=3,
postfix="_ZN",
est_freq="m",
)
dfx = msm.update_df(dfx, dfa)
dict_facts[czs + "_ZN"] = "Relative disinflation ratio"
cids_dux
xcatx = ['INFLCHGRvGLB_NEG_ZN']
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=4,
same_y=True,
all_xticks=True,
size=(12, 7),
aspect=1.8
)
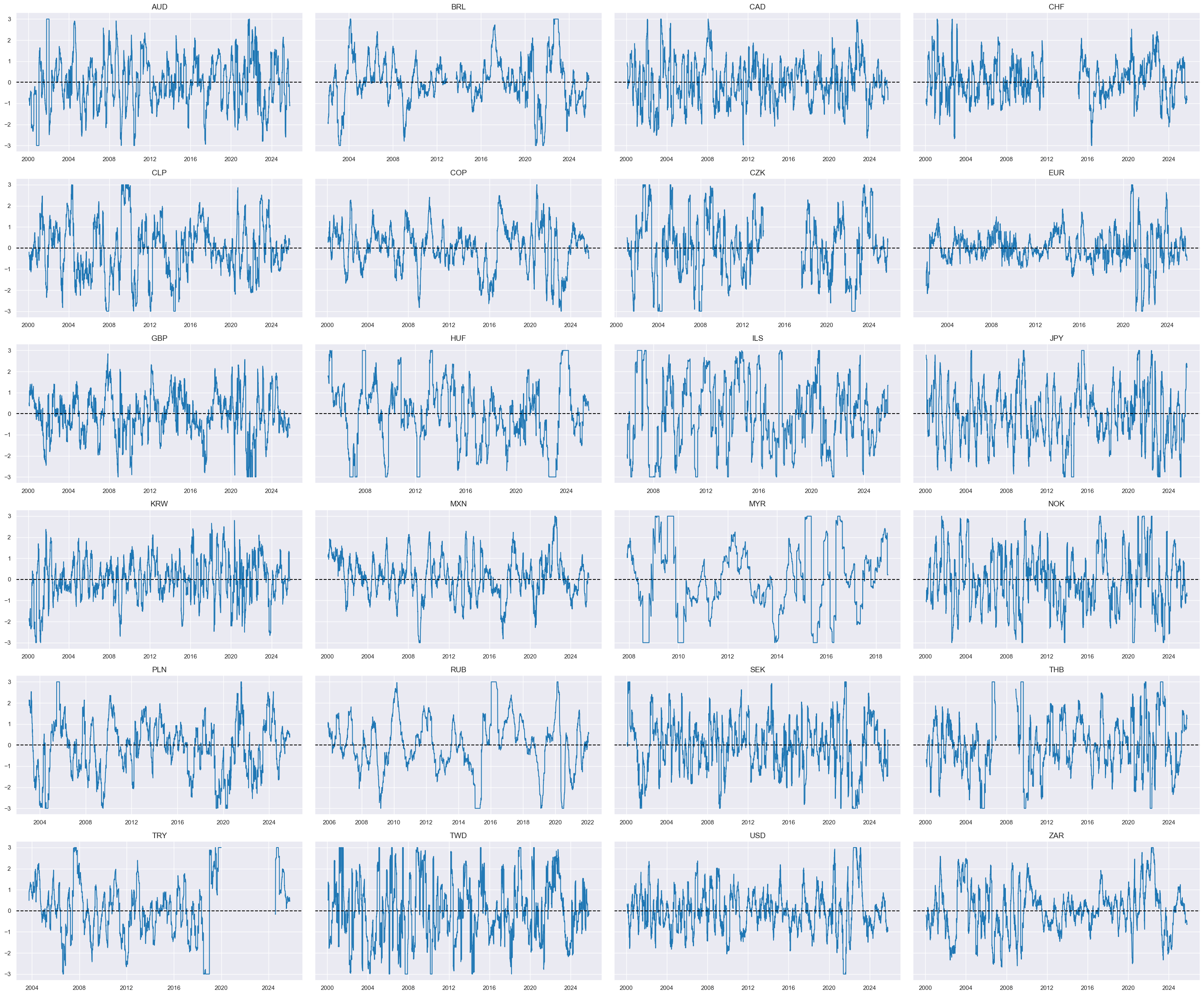
Relative real yields and carry #
# Base indicators and score weights
dict_ir = {
"RYLDIRS05Y_NSA": (1/2, 1),
"DU05YCRY_NSA": (1/4, 1),
"DU05YCRY_VT10": (1/4, 1),
}
cidx = cids_dux
xcatx = list(dict_ir.keys())
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=4,
same_y=False,
all_xticks=True,
size=(12, 7),
aspect=1.8
)
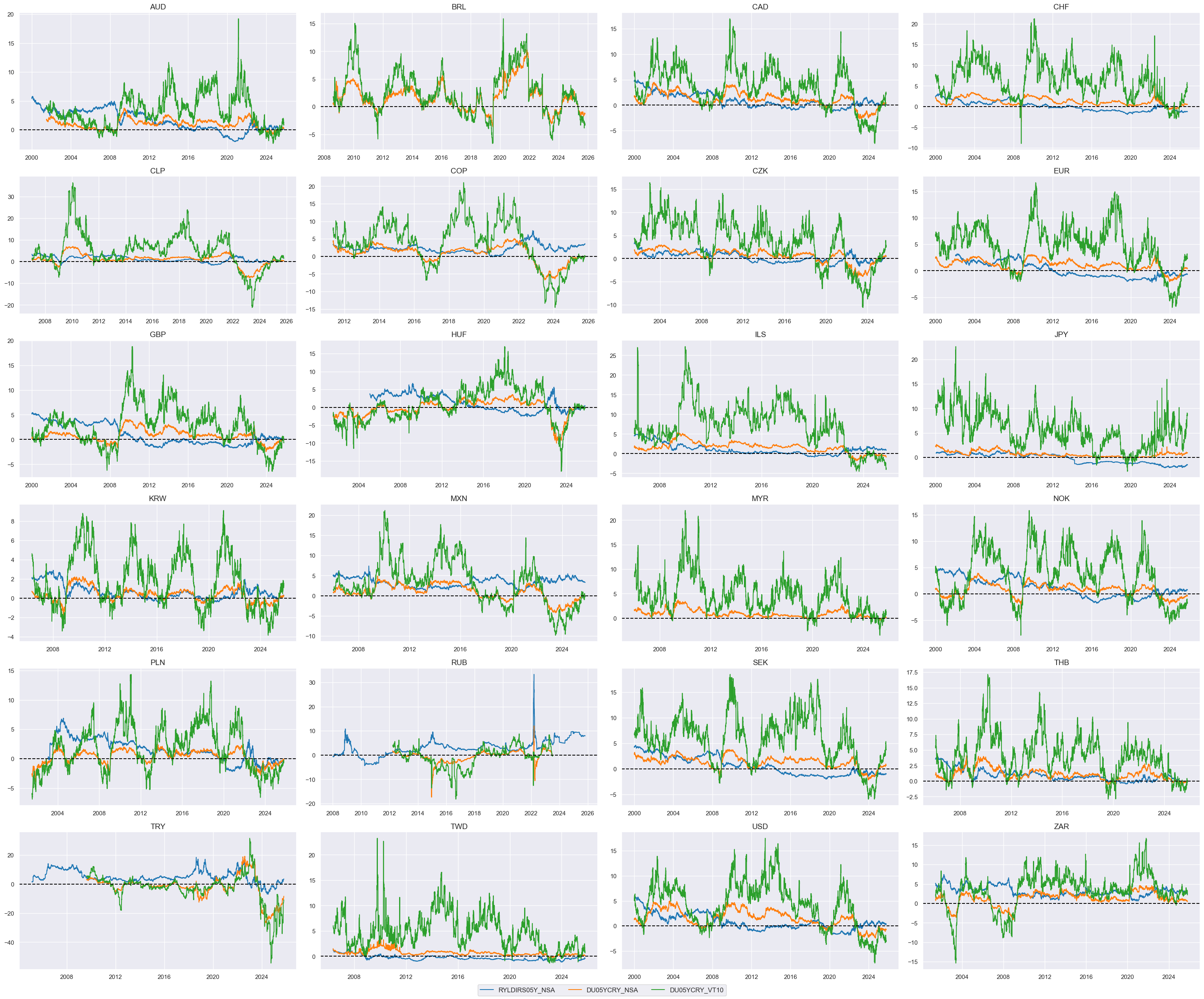
# Relative value of constituents
cidx = cids_dux
xcatx = list(dict_ir.keys())
dfa = msp.make_relative_value(
df=dfx,
xcats=xcatx,
cids=cidx,
blacklist=fxblack,
postfix="vGLB",
)
dfx = msm.update_df(dfx, dfa)
# Scoring of relative values
cidx = cids_dux
xcatx = [xc + "vGLB" for xc in list(dict_ir.keys())]
dfa = pd.DataFrame(columns=dfx.columns)
for xc in xcatx:
dfaa = msp.make_zn_scores(
dfx,
xcat=xc,
cids=cidx,
sequential=True,
min_obs=261 * 3,
neutral="zero",
pan_weight=1,
thresh=3,
postfix="_ZN",
est_freq="m",
)
dfa = msm.update_df(dfa, dfaa)
dfx = msm.update_df(dfx, dfa)
cidx = cids_dux
xcatx = [xcat + "vGLB_ZN" for xcat in list(dict_ir.keys())]
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=4,
same_y=False,
all_xticks=True,
size=(12, 7),
aspect=1.8,
title = "Relative real interest rates and duration carries"
)
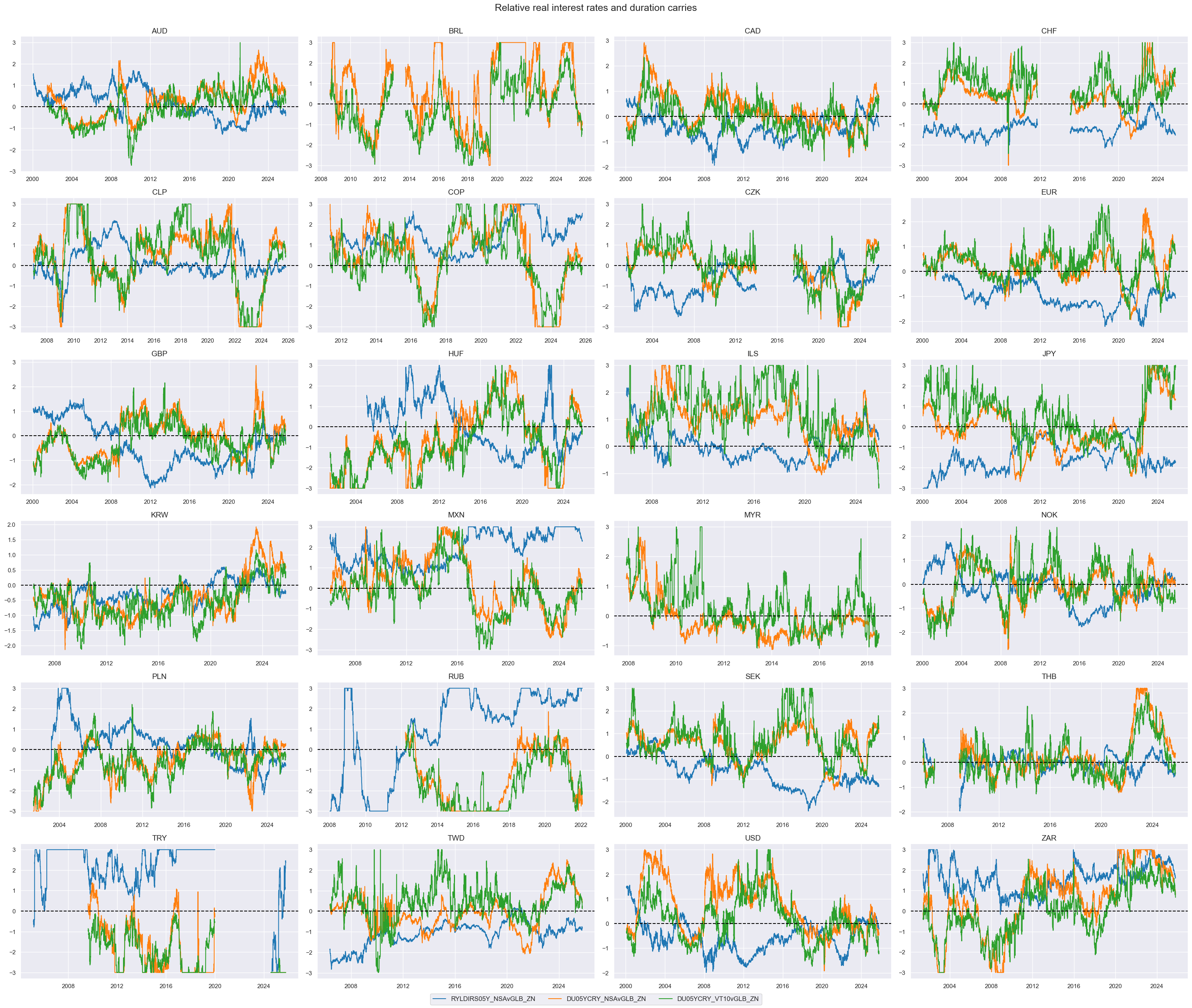
# Weighted linear combination
cidx = cids_dux
dix = dict_ir
xcatx = [k + "vGLB_ZN" for k in list(dix.keys())]
weights = [v[0] for v in list(dix.values())]
signs = [v[1] for v in list(dix.values())]
czs = "RRCRvGLB"
dfa = msp.linear_composite(
dfx,
xcats=xcatx,
cids=cidx,
weights=weights,
signs=signs,
normalize_weights=True,
complete_xcats=False, # score works with what is available
new_xcat=czs,
)
dfx = msm.update_df(dfx, dfa)
# Re-scoring
dfa = msp.make_zn_scores(
dfx,
xcat=czs,
cids=cidx,
sequential=True,
min_obs=261 * 3,
neutral="zero",
pan_weight=1,
thresh=3,
postfix="_ZN",
est_freq="m",
)
dfx = msm.update_df(dfx, dfa)
dict_facts[czs + "_ZN"] = "Relative real yields and carry"
cids_dux
xcatx = ['RRCRvGLB_ZN']
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=4,
same_y=True,
all_xticks=True,
size=(12, 7),
aspect=1.8
)
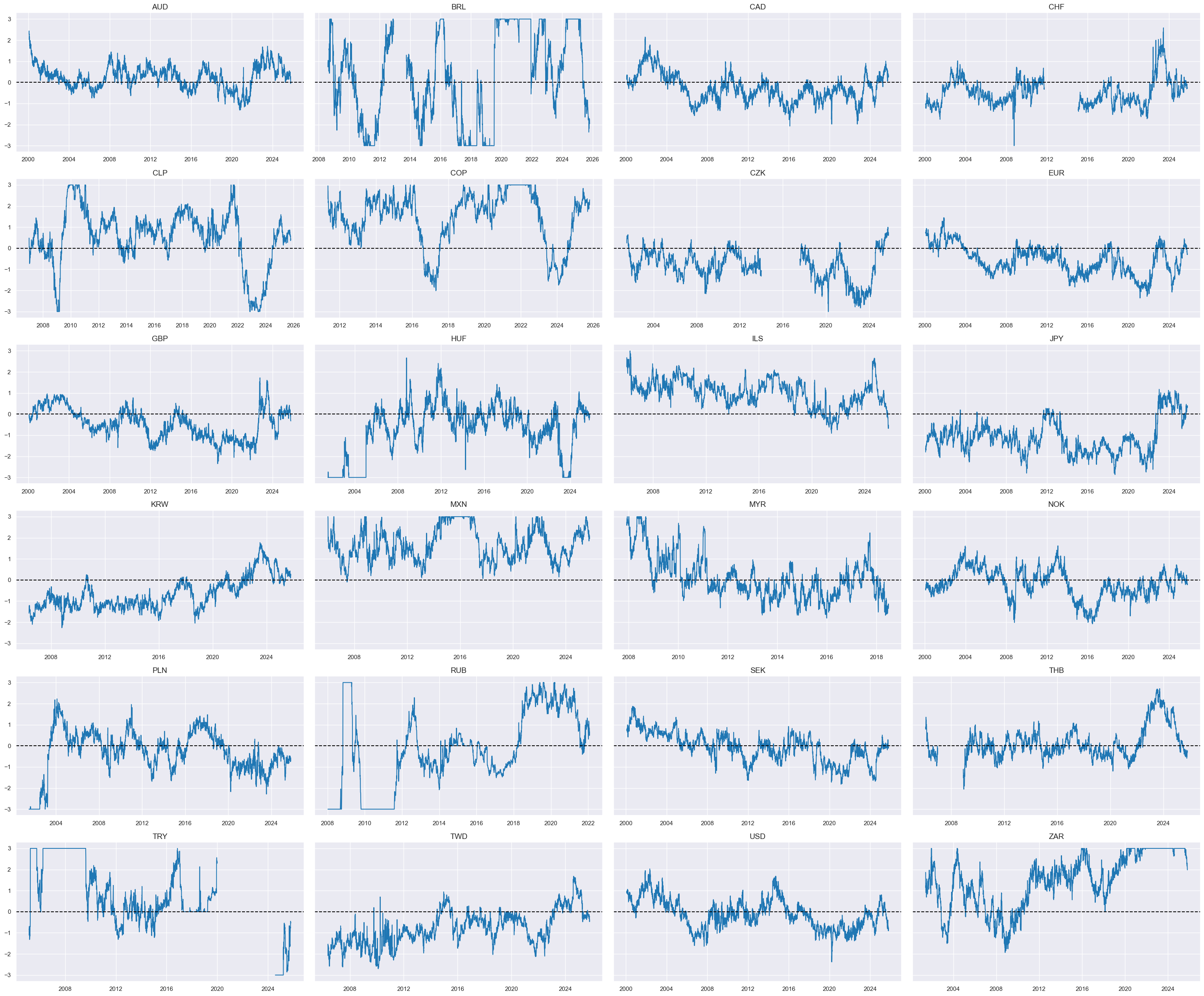
Relative openness-adjusted real appreciation #
dict_reer = {
"REEROADJ_NSA_P1W4WL1": (1/4, 1),
"REEROADJ_NSA_P1M1ML12": (1/4, 1),
"REEROADJ_NSA_P1M12ML1": (1/4, 1),
"REEROADJ_NSA_P1M60ML1": (1/4, 1),
}
cidx = cids_dux
xcatx = list(dict_reer.keys())
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=4,
same_y=False,
all_xticks=True,
size=(12, 7),
aspect=1.8
)
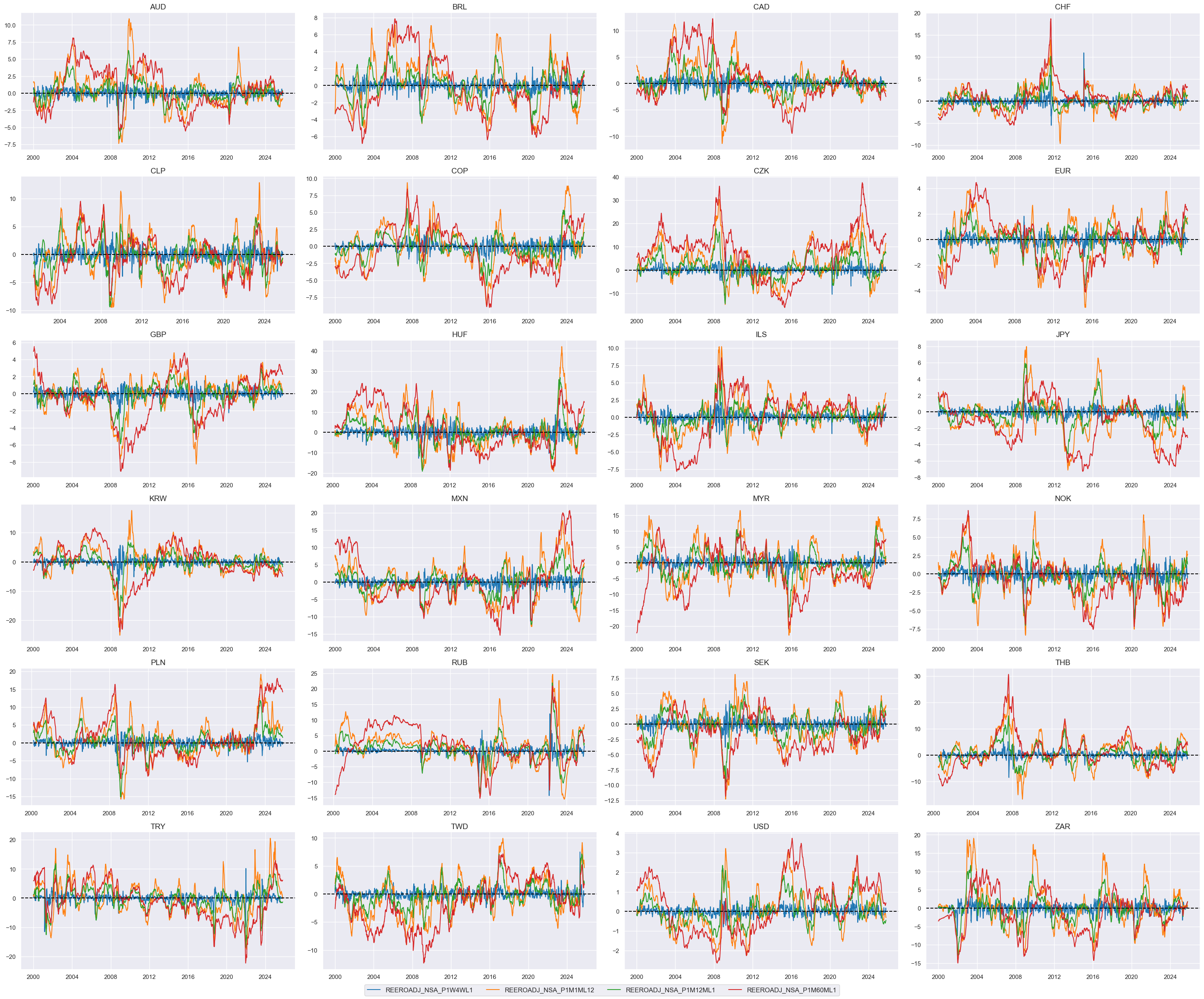
# Relative value of constituents
cidx = cids_dux
xcatx = list(dict_reer.keys())
dfa = msp.make_relative_value(
df=dfx,
xcats=xcatx,
cids=cidx,
blacklist=fxblack,
postfix="vGLB",
)
dfx = msm.update_df(dfx, dfa)
# Scoring of relative values
cidx = cids_dux
xcatx = [xc + "vGLB" for xc in list(dict_reer.keys())]
dfa = pd.DataFrame(columns=dfx.columns)
for xc in xcatx:
dfaa = msp.make_zn_scores(
dfx,
xcat=xc,
cids=cidx,
sequential=True,
min_obs=261 * 3,
neutral="zero",
pan_weight=1,
thresh=3,
postfix="_ZN",
est_freq="m",
)
dfa = msm.update_df(dfa, dfaa)
dfx = msm.update_df(dfx, dfa)
cidx = cids_dux
xcatx = [xcat + "vGLB_ZN" for xcat in list(dict_reer.keys())]
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=4,
same_y=False,
all_xticks=True,
size=(12, 7),
aspect=1.8,
)
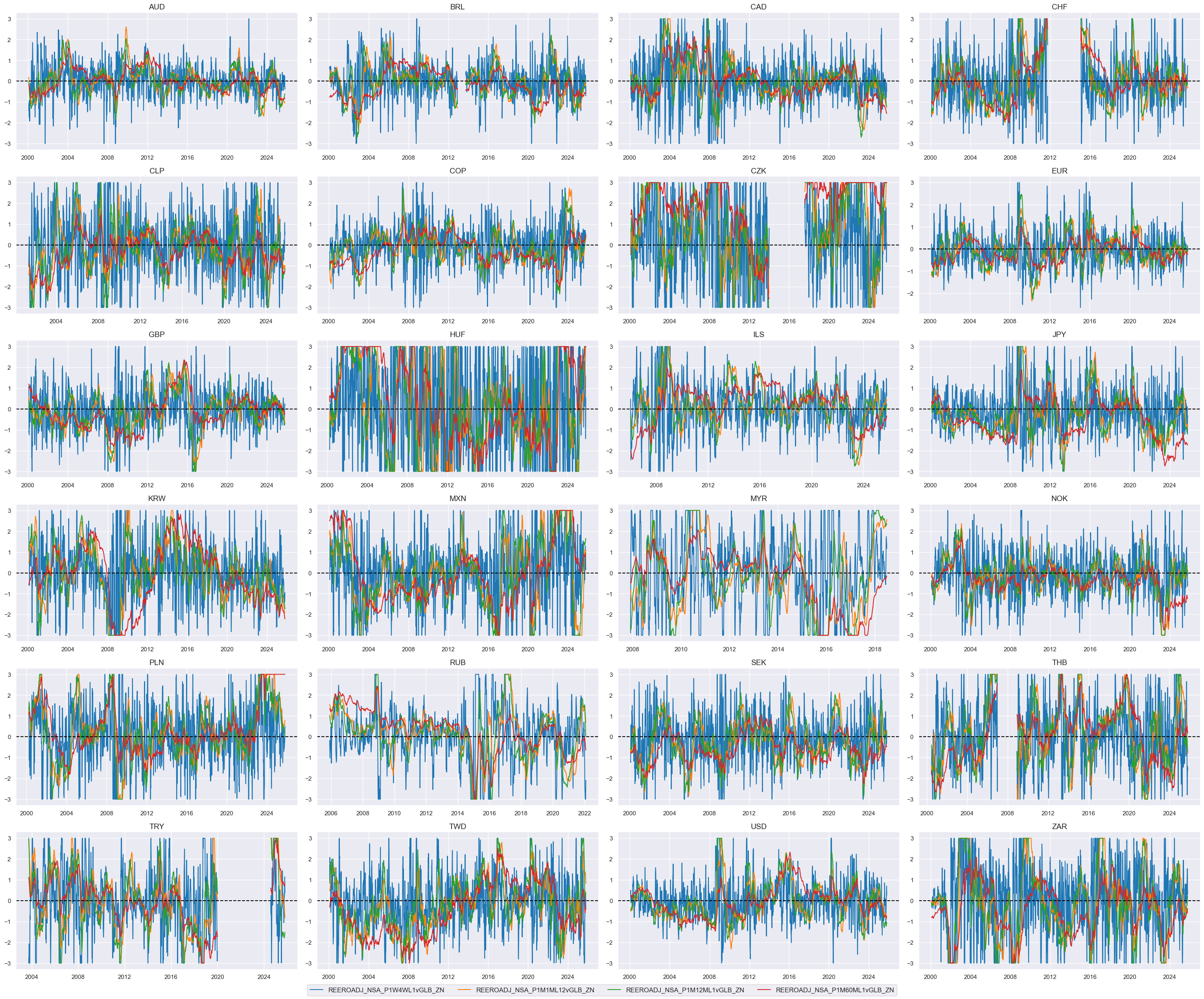
# Weighted linear combination
cidx = cids_dux
dix = dict_reer
xcatx = [k + "vGLB_ZN" for k in list(dix.keys())]
weights = [v[0] for v in list(dix.values())]
signs = [v[1] for v in list(dix.values())]
czs = "REEROACHGvGLB"
dfa = msp.linear_composite(
dfx,
xcats=xcatx,
cids=cidx,
weights=weights,
signs=signs,
normalize_weights=True,
complete_xcats=False, # score works with what is available
new_xcat=czs,
)
dfx = msm.update_df(dfx, dfa)
# Re-scoring
dfa = msp.make_zn_scores(
dfx,
xcat=czs,
cids=cidx,
sequential=True,
min_obs=261 * 3,
neutral="zero",
pan_weight=1,
thresh=3,
postfix="_ZN",
est_freq="m",
)
dfx = msm.update_df(dfx, dfa)
dict_facts[czs + "_ZN"] = "Relative real appreciation"
cids_dux
xcatx = ['REEROACHGvGLB_ZN']
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=4,
same_y=True,
all_xticks=True,
size=(12, 7),
aspect=1.8
)
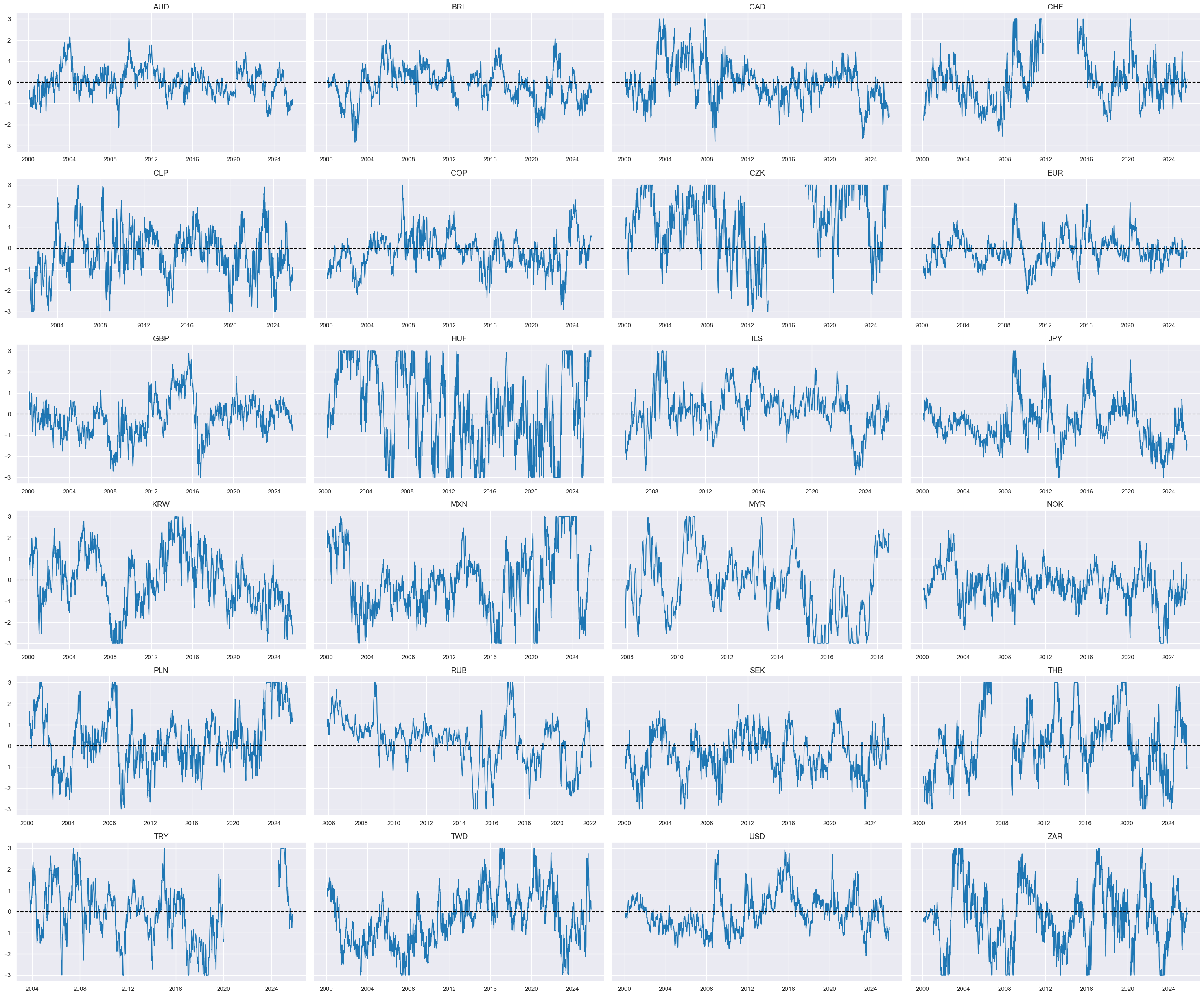
Relative external balances #
dict_xb = {
"CABGDPRATIO_NSA_12MMA": (1/2, 1),
"BXBGDPRATIOE_NSA_12MMA": (1/2, 1),
}
cidx = cids_dux
xcatx = list(dict_xb.keys())
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=4,
same_y=False,
all_xticks=True,
size=(12, 7),
aspect=1.8
)
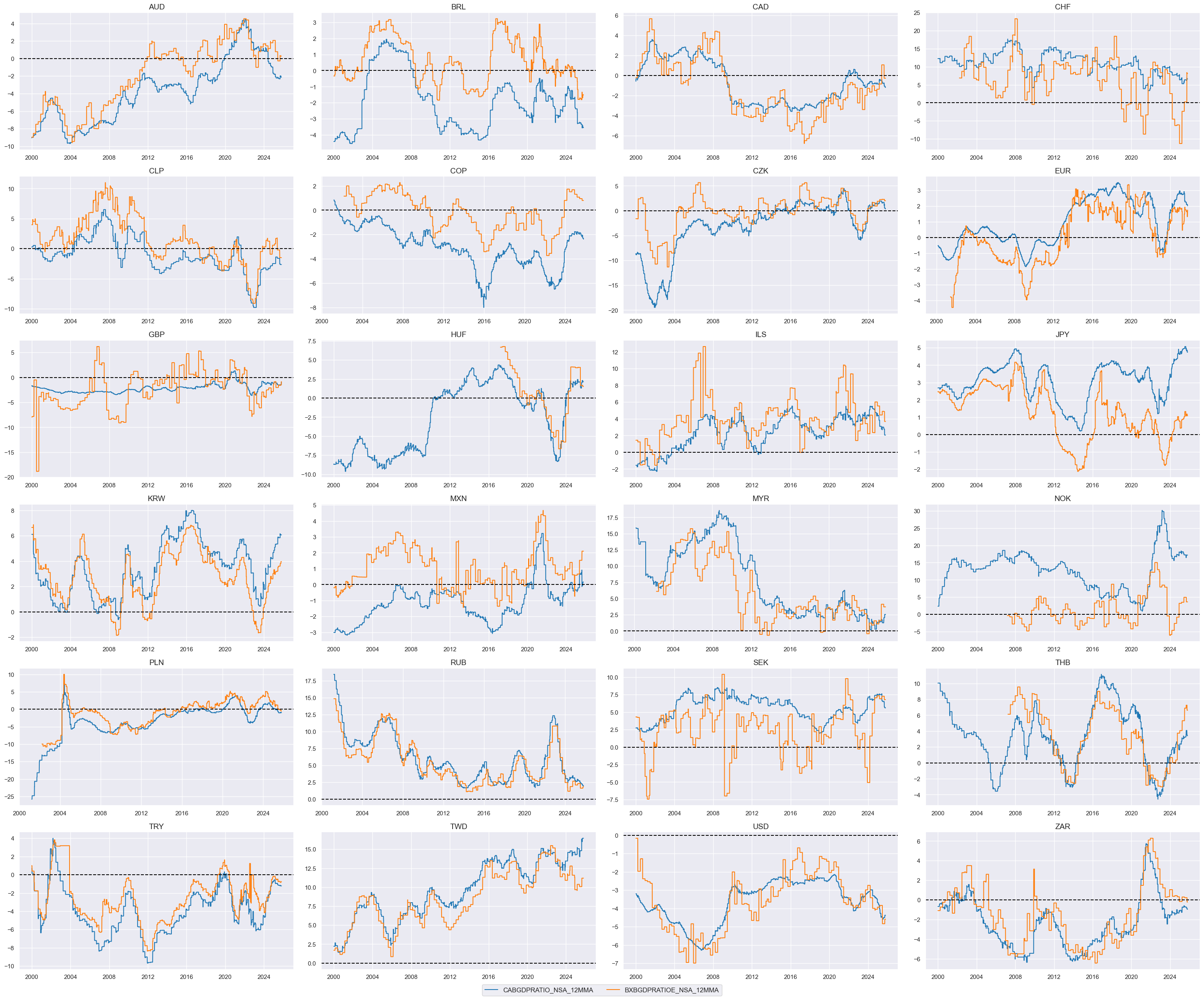
# Relative value of constituents
cidx = cids_dux
xcatx = list(dict_xb.keys())
dfa = msp.make_relative_value(
df=dfx,
xcats=xcatx,
cids=cidx,
blacklist=fxblack,
postfix="vGLB",
)
dfx = msm.update_df(dfx, dfa)
# Scoring of relative values
cidx = cids_dux
xcatx = [xc + "vGLB" for xc in list(dict_xb.keys())]
dfa = pd.DataFrame(columns=dfx.columns)
for xc in xcatx:
dfaa = msp.make_zn_scores(
dfx,
xcat=xc,
cids=cidx,
sequential=True,
min_obs=261 * 3,
neutral="zero",
pan_weight=1,
thresh=3,
postfix="_ZN",
est_freq="m",
)
dfa = msm.update_df(dfa, dfaa)
dfx = msm.update_df(dfx, dfa)
cidx = cids_dux
xcatx = [xcat + "vGLB_ZN" for xcat in list(dict_xb.keys())]
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=4,
same_y=False,
all_xticks=True,
size=(12, 7),
aspect=1.8,
)
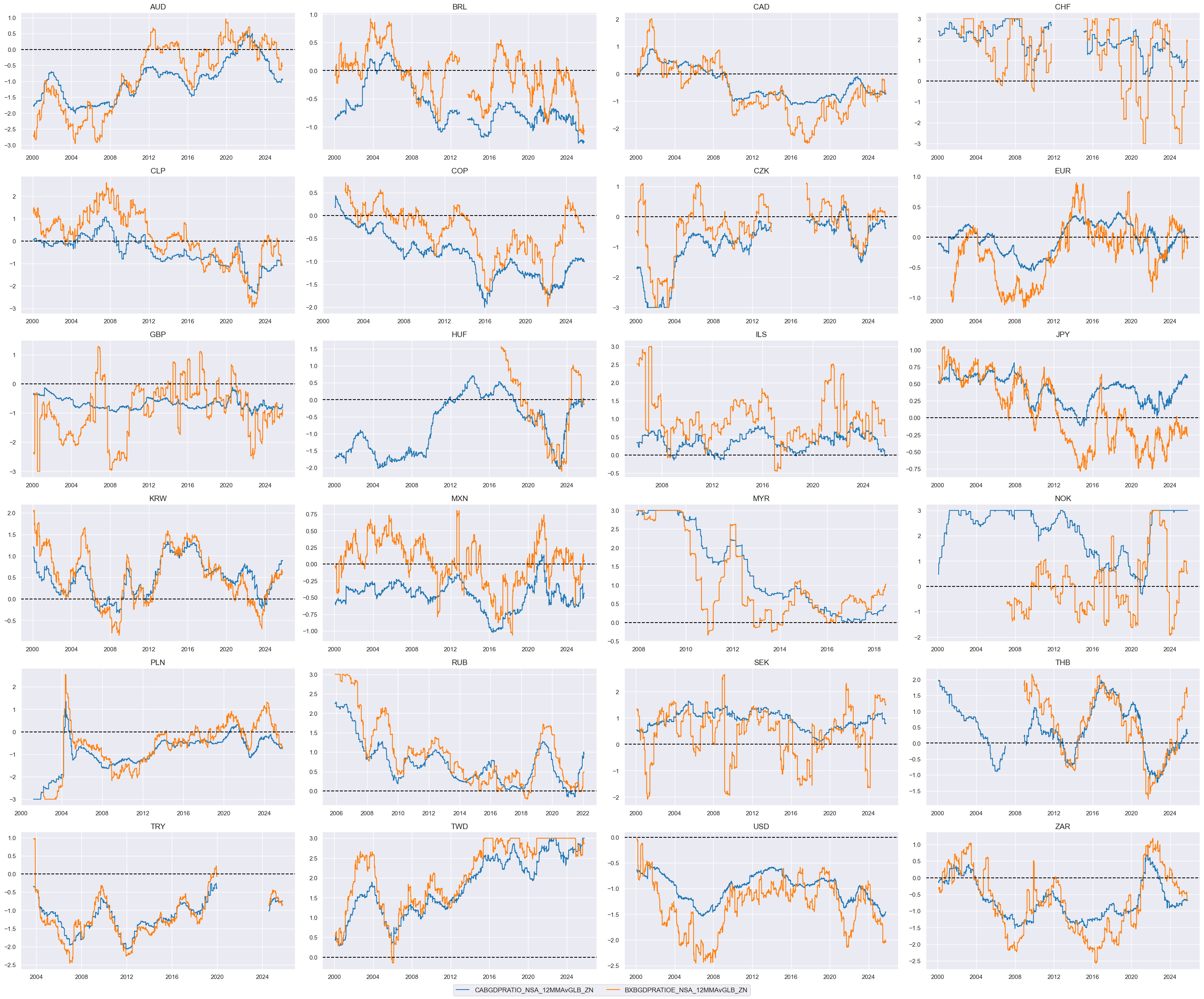
# Weighted linear combination
cidx = cids_dux
dix = dict_xb
xcatx = [k + "vGLB_ZN" for k in list(dix.keys())]
weights = [v[0] for v in list(dix.values())]
signs = [v[1] for v in list(dix.values())]
czs = "XBALvGLB"
dfa = msp.linear_composite(
dfx,
xcats=xcatx,
cids=cidx,
weights=weights,
signs=signs,
normalize_weights=True,
complete_xcats=False, # score works with what is available
new_xcat=czs,
)
dfx = msm.update_df(dfx, dfa)
# Re-scoring
dfa = msp.make_zn_scores(
dfx,
xcat=czs,
cids=cidx,
sequential=True,
min_obs=261 * 3, # why not 3?
neutral="zero",
pan_weight=1,
thresh=3,
postfix="_ZN",
est_freq="m",
)
dfx = msm.update_df(dfx, dfa)
dict_facts[czs + "_ZN"] = "Relative external balances"
cids_dux
xcatx = ['XBALvGLB_ZN']
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=4,
same_y=True,
all_xticks=True,
size=(12, 7),
aspect=1.8
)
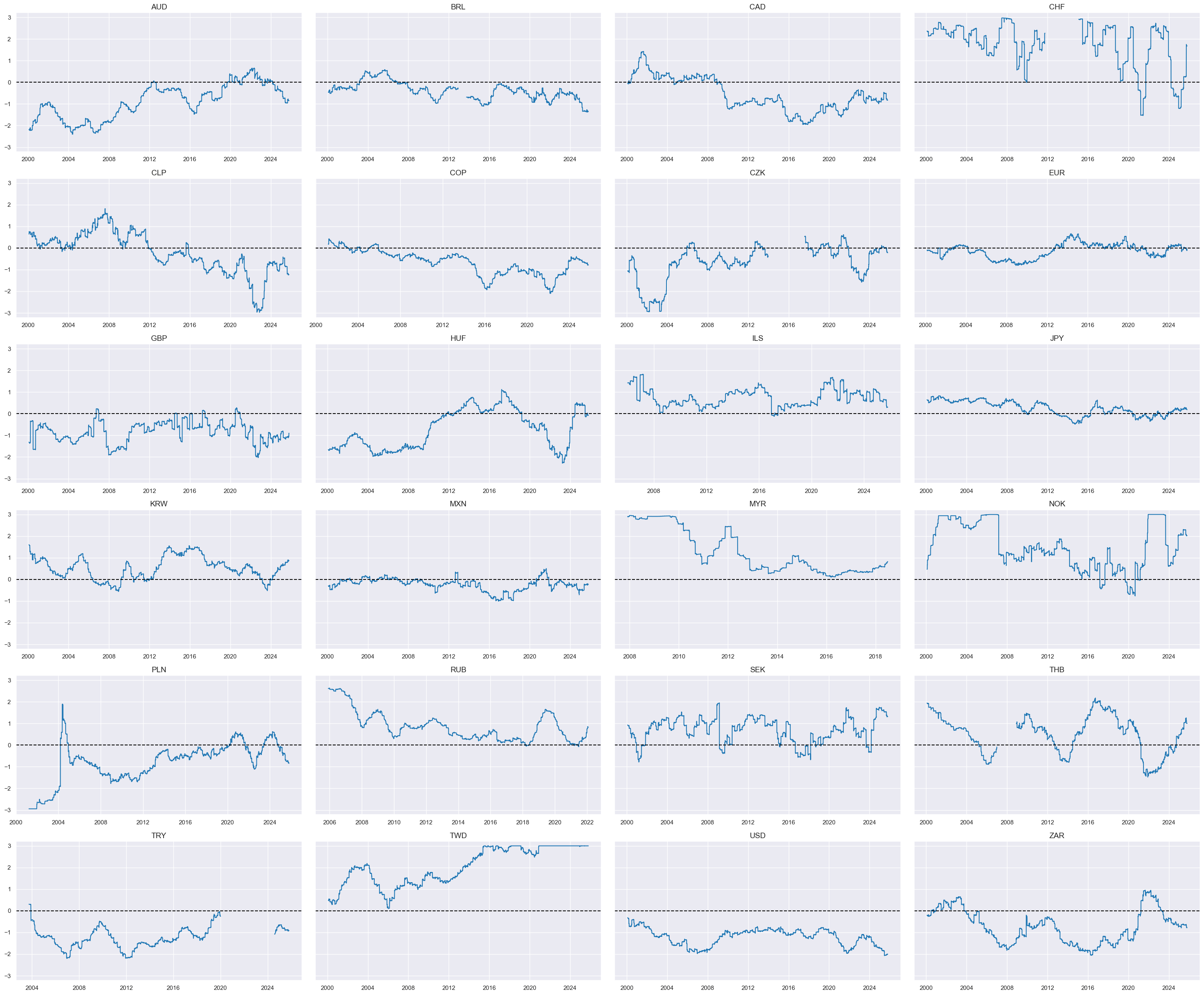
Relative trade balance ratio changes #
dict_mtb = {
"MTBGDPRATIO_SA_3MMA_D1M1ML3": (1/3, 1),
"MTBGDPRATIO_SA_6MMA_D1M1ML6": (1/3, 1),
"MTBGDPRATIO_NSA_12MMA_D1M1ML3": (1/3, 1),
}
cidx = cids_dux
xcatx = list(dict_mtb.keys())
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=4,
same_y=False,
all_xticks=True,
size=(12, 7),
aspect=1.8
)
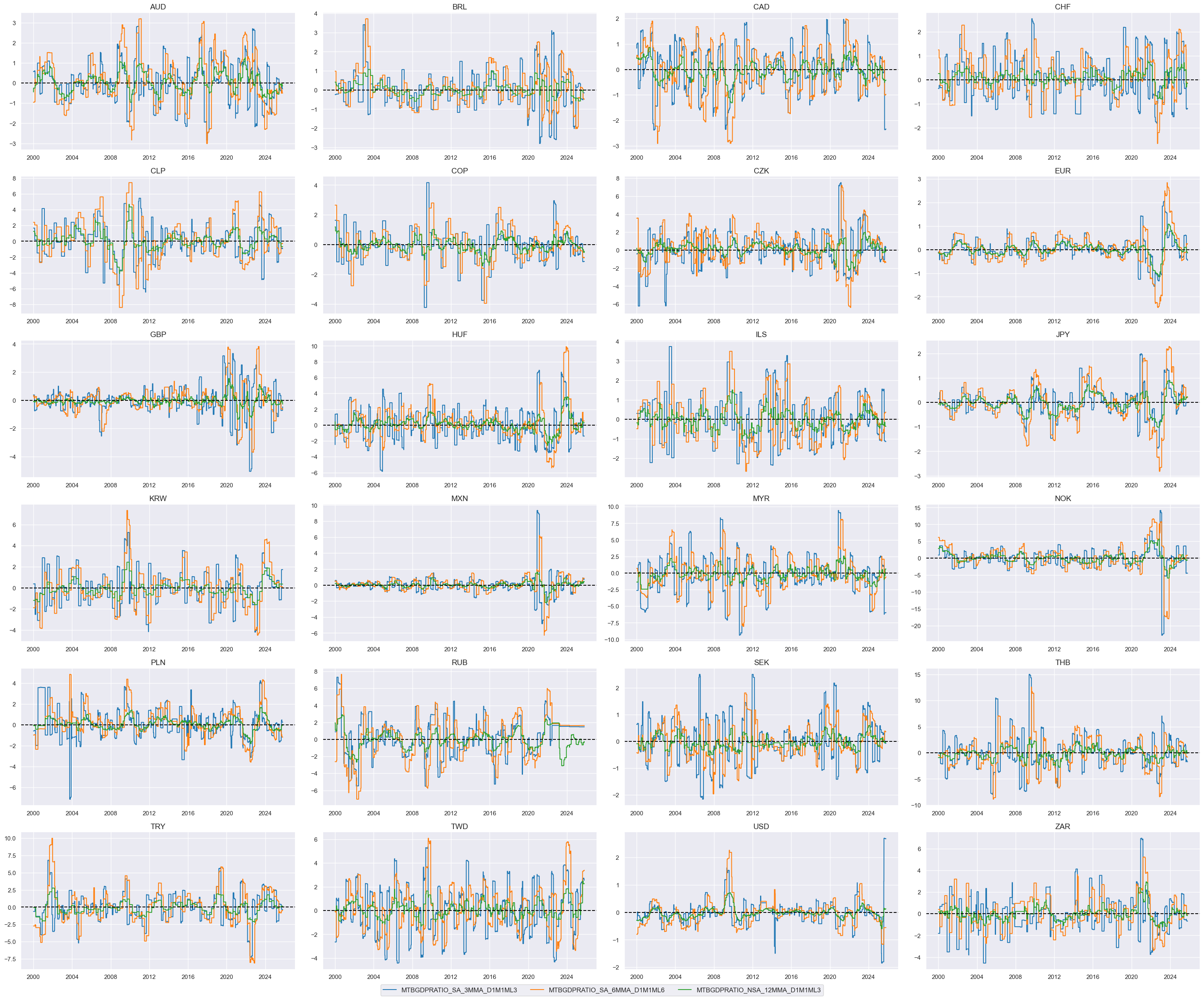
# Relative value of constituents
cidx = cids_dux
xcatx = list(dict_mtb.keys())
dfa = msp.make_relative_value(
df=dfx,
xcats=xcatx,
cids=cidx,
blacklist=fxblack,
postfix="vGLB",
)
dfx = msm.update_df(dfx, dfa)
# Scoring of relative values
cidx = cids_dux
xcatx = [xc + "vGLB" for xc in list(dict_mtb.keys())]
dfa = pd.DataFrame(columns=dfx.columns)
for xc in xcatx:
dfaa = msp.make_zn_scores(
dfx,
xcat=xc,
cids=cidx,
sequential=True,
min_obs=261 * 3,
neutral="zero",
pan_weight=1,
thresh=3,
postfix="_ZN",
est_freq="m",
)
dfa = msm.update_df(dfa, dfaa)
dfx = msm.update_df(dfx, dfa)
cidx = cids_dux
xcatx = [xcat + "vGLB_ZN" for xcat in list(dict_mtb.keys())]
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=4,
same_y=False,
all_xticks=True,
size=(12, 7),
aspect=1.8,
title = "Merchandise trade balance differences"
)
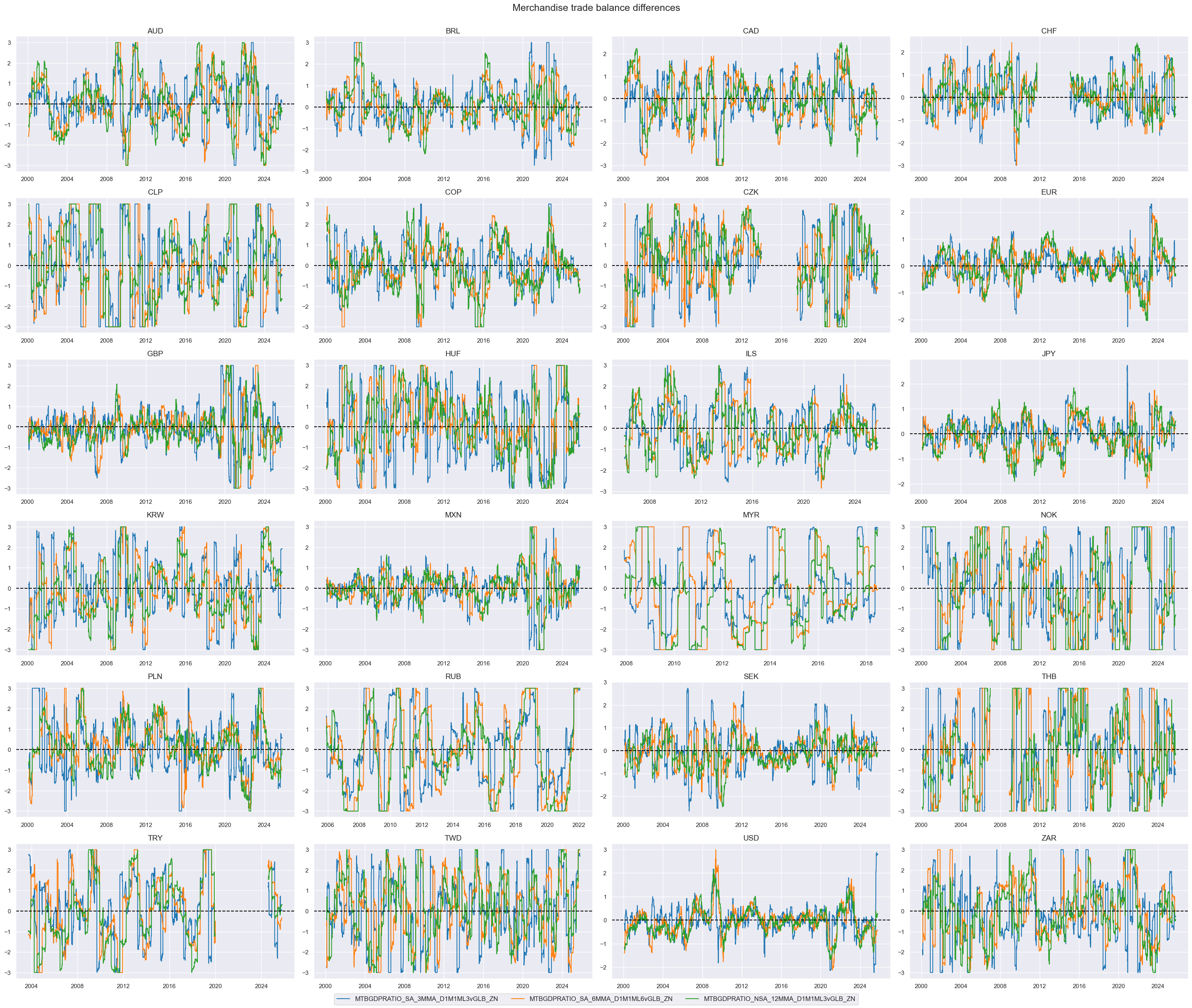
# Weighted linear combination
cidx = cids_dux
dix = dict_mtb
xcatx = [k + "vGLB_ZN" for k in list(dix.keys())]
weights = [v[0] for v in list(dix.values())]
signs = [v[1] for v in list(dix.values())]
czs = "MTBCHGvGLB"
dfa = msp.linear_composite(
dfx,
xcats=xcatx,
cids=cidx,
weights=weights,
signs=signs,
normalize_weights=True,
complete_xcats=False, # score works with what is available
new_xcat=czs,
)
dfx = msm.update_df(dfx, dfa)
# Re-scoring
dfa = msp.make_zn_scores(
dfx,
xcat=czs,
cids=cidx,
sequential=True,
min_obs=261 * 3,
neutral="zero",
pan_weight=1,
thresh=3,
postfix="_ZN",
est_freq="m",
)
dfx = msm.update_df(dfx, dfa)
dict_facts[czs + "_ZN"] = "Relative trade balance changes"
cids_dux
xcatx = ['MTBCHGvGLB_ZN']
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=4,
same_y=True,
all_xticks=True,
size=(12, 7),
aspect=1.8
)
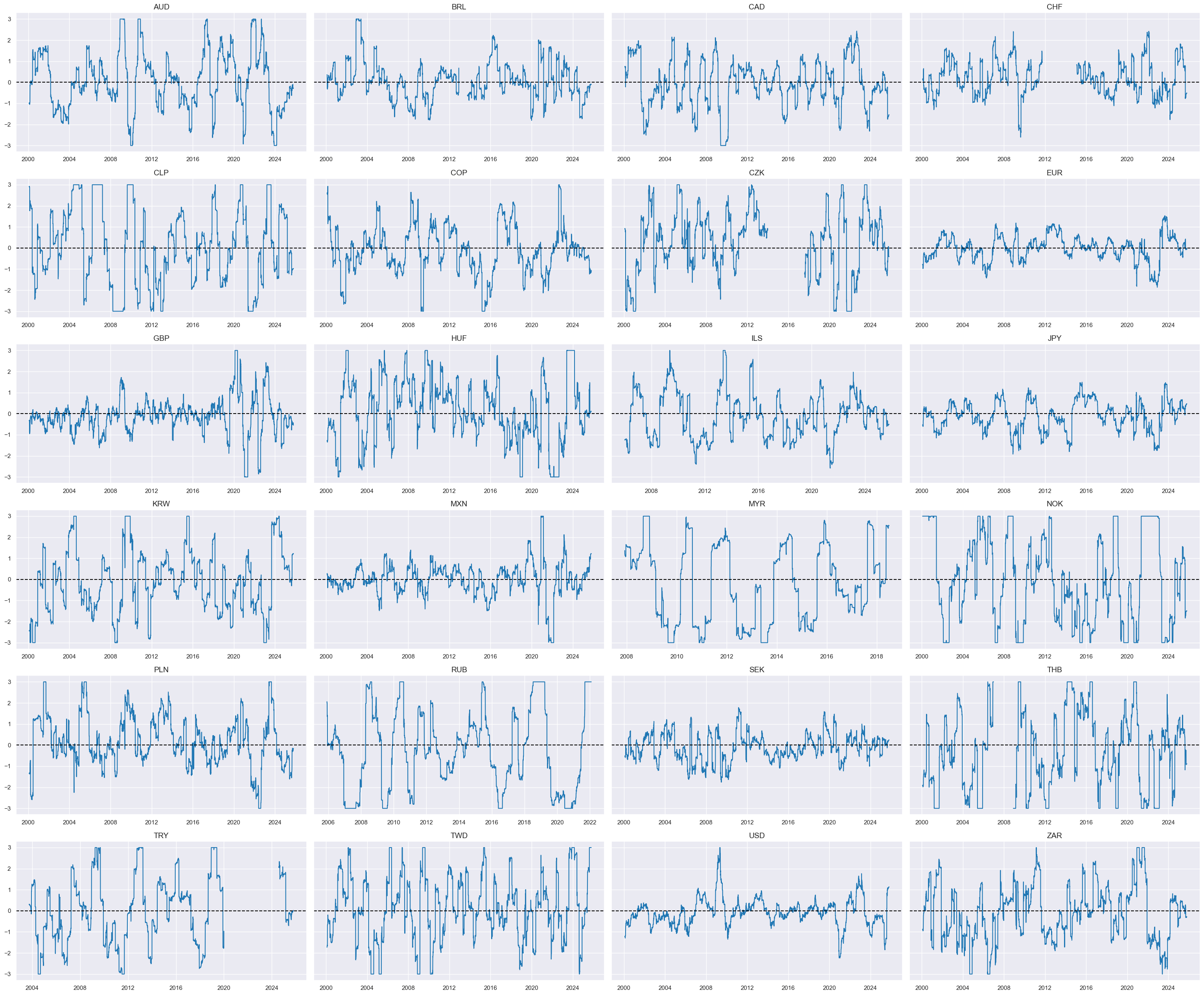
Relative liquidity growth #
dict_liq = {
"INTLIQGDP_NSA_D1M1ML3": (1/2, 1),
"INTLIQGDP_NSA_D1M1ML6": (1/2, 1),
}
cidx = cids_dux
xcatx = list(dict_liq.keys())
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=4,
same_y=False,
all_xticks=True,
size=(12, 7),
aspect=1.8
)
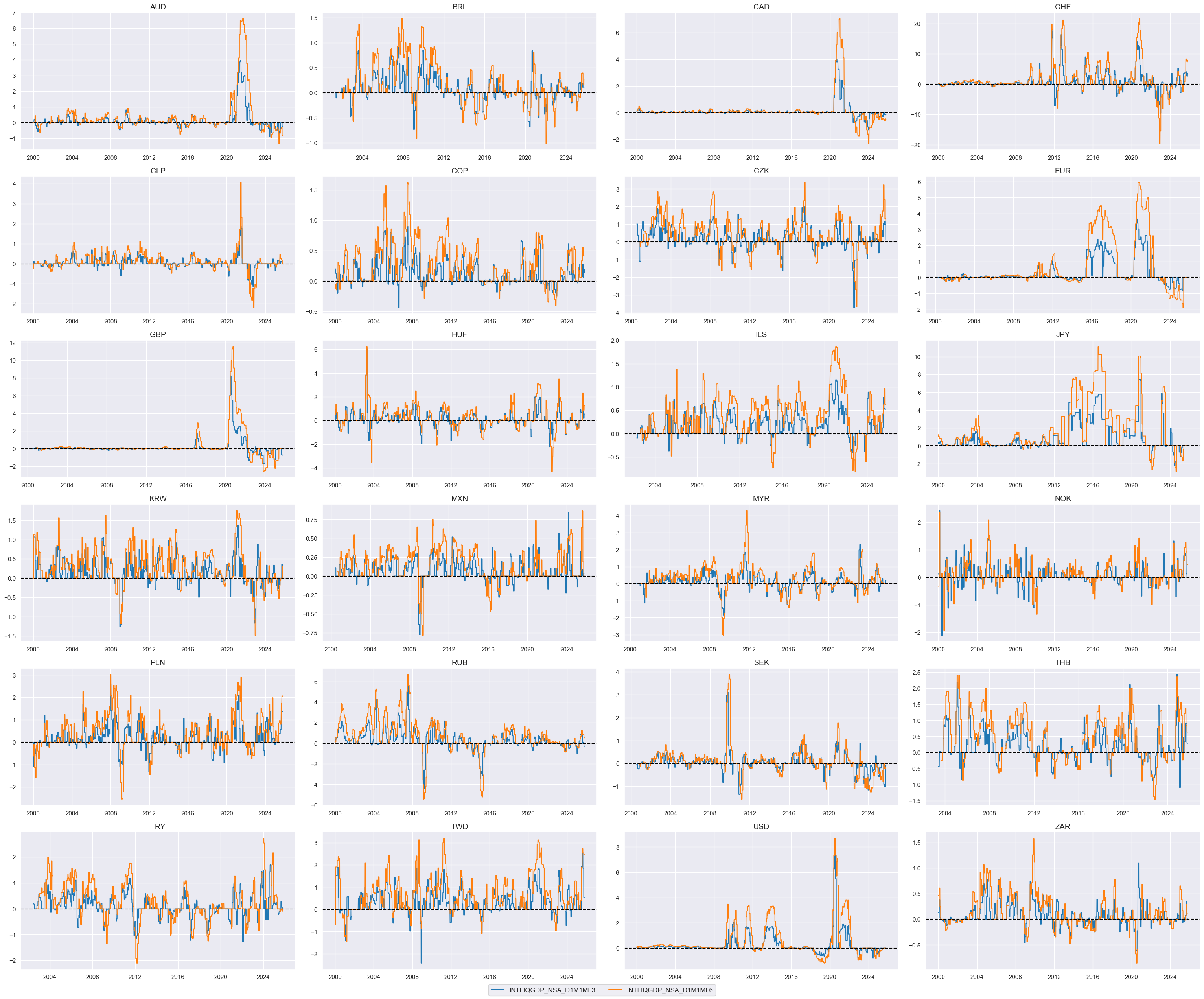
# Relative value of constituents
cidx = cids_dux
xcatx = list(dict_liq.keys())
dfa = msp.make_relative_value(
df=dfx,
xcats=xcatx,
cids=cidx,
blacklist=fxblack,
postfix="vGLB",
)
dfx = msm.update_df(dfx, dfa)
# Scoring of relative values
cidx = cids_dux
xcatx = [xc + "vGLB" for xc in list(dict_liq.keys())]
dfa = pd.DataFrame(columns=dfx.columns)
for xc in xcatx:
dfaa = msp.make_zn_scores(
dfx,
xcat=xc,
cids=cidx,
sequential=True,
min_obs=261 * 3,
neutral="zero",
pan_weight=1,
thresh=3,
postfix="_ZN",
est_freq="m",
)
dfa = msm.update_df(dfa, dfaa)
dfx = msm.update_df(dfx, dfa)
cidx = cids_dux
xcatx = [xcat + "vGLB_ZN" for xcat in list(dict_liq.keys())]
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=4,
same_y=False,
all_xticks=True,
size=(12, 7),
aspect=1.8,
)
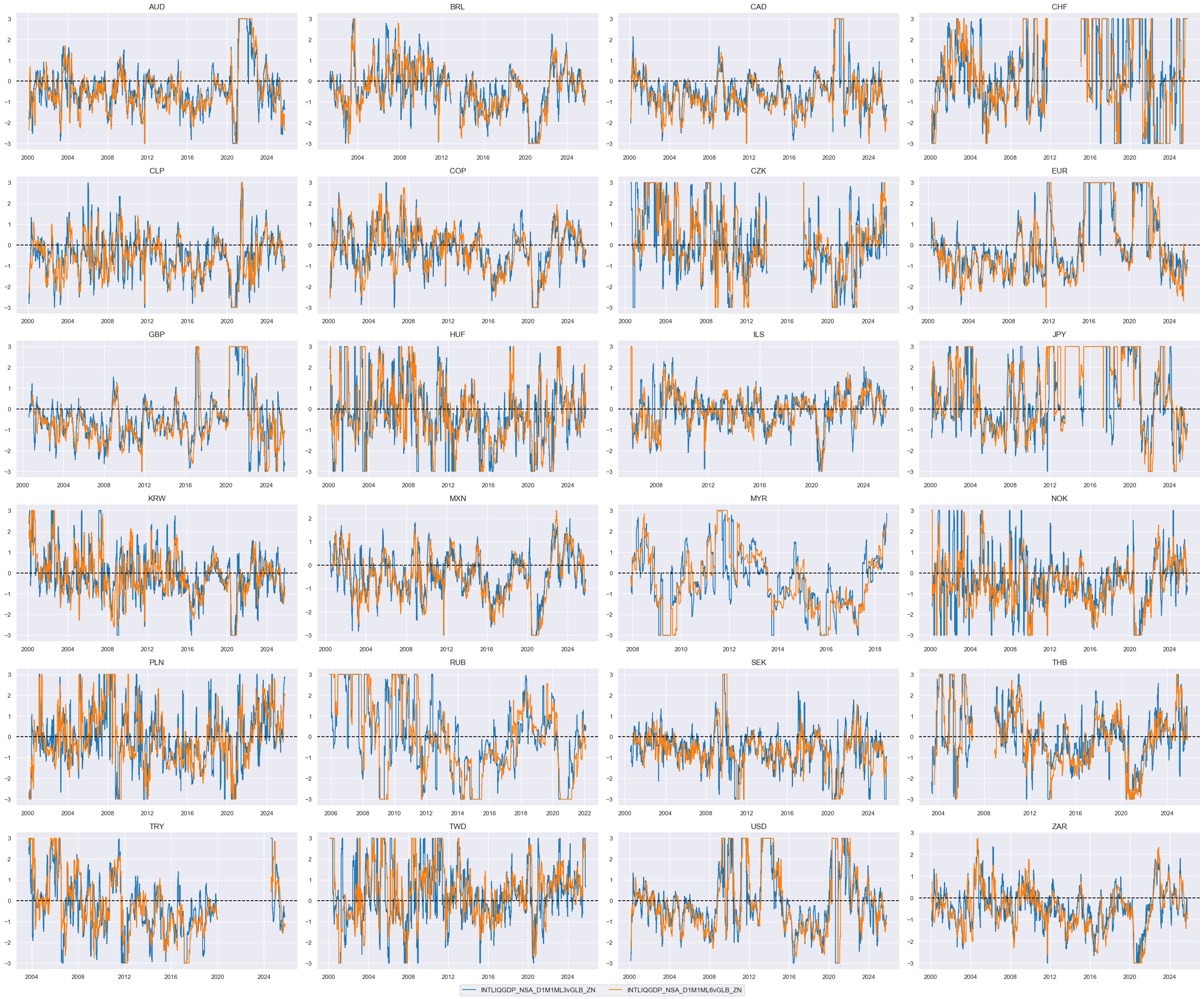
# Weighted linear combination
cidx = cids_dux
dix = dict_liq
xcatx = [k + "vGLB_ZN" for k in list(dix.keys())]
weights = [v[0] for v in list(dix.values())]
signs = [v[1] for v in list(dix.values())]
czs = "LIQCHGvGLB"
dfa = msp.linear_composite(
dfx,
xcats=xcatx,
cids=cidx,
weights=weights,
signs=signs,
normalize_weights=True,
complete_xcats=False, # score works with what is available
new_xcat=czs,
)
dfx = msm.update_df(dfx, dfa)
# Re-scoring
dfa = msp.make_zn_scores(
dfx,
xcat=czs,
cids=cidx,
sequential=True,
min_obs=261 * 3,
neutral="zero",
pan_weight=1,
thresh=3,
postfix="_ZN",
est_freq="m",
)
dfx = msm.update_df(dfx, dfa)
dict_facts[czs + "_ZN"] = "Relative liquidity growth"
cids_dux
xcatx = ['LIQCHGvGLB_ZN']
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=4,
same_y=True,
all_xticks=True,
size=(12, 7),
aspect=1.8
)
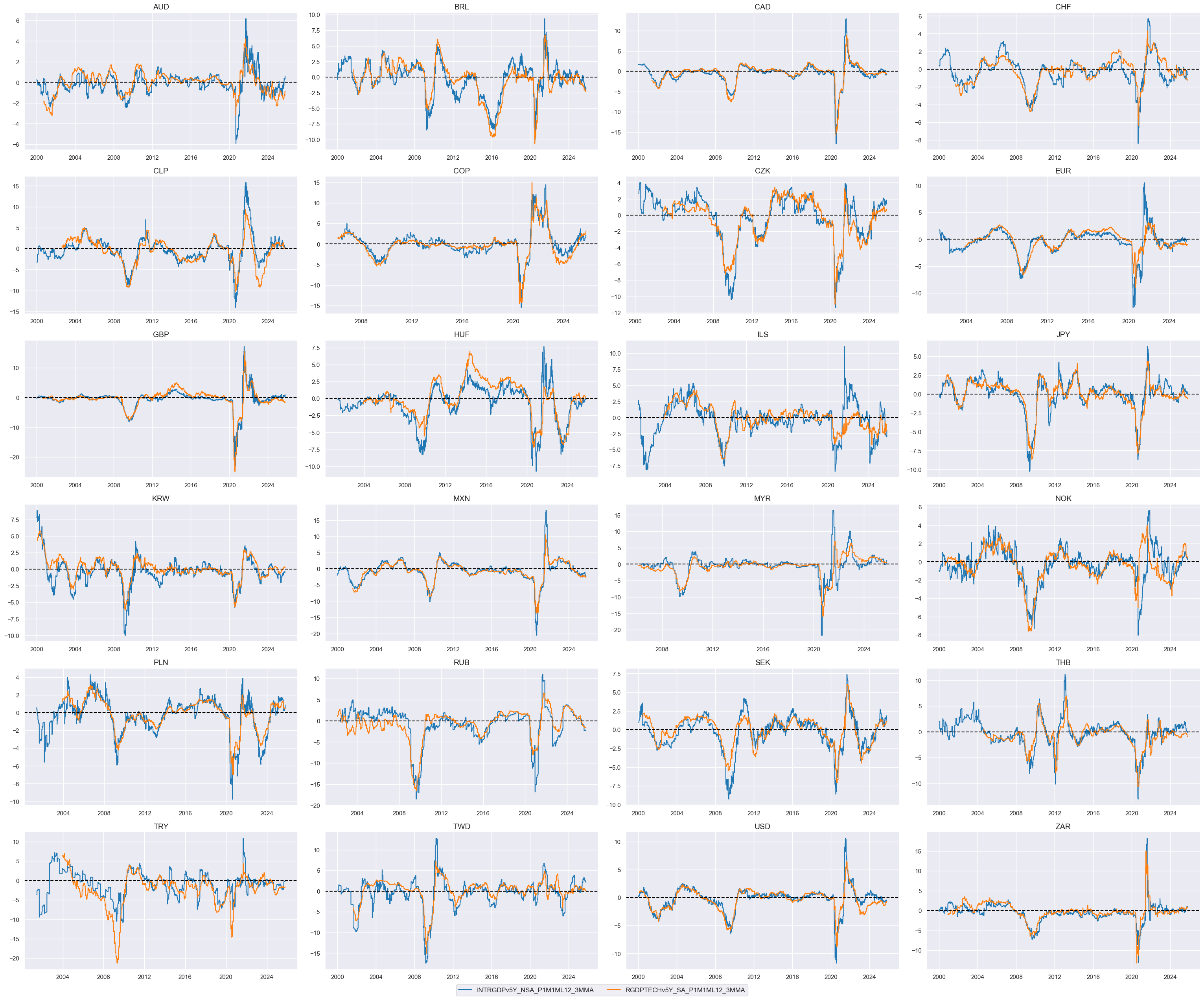
Relative GDP growth shortfall #
dict_gdp = {
"INTRGDPv5Y_NSA_P1M1ML12_3MMA": (1/2, -1),
"RGDPTECHv5Y_SA_P1M1ML12_3MMA": (1/2, -1),
}
cidx = cids_dux
xcatx = list(dict_gdp.keys())
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=4,
same_y=False,
all_xticks=True,
size=(12, 7),
aspect=1.8
)
# Relative value of constituents
cidx = cids_dux
xcatx = list(dict_gdp.keys())
dfa = msp.make_relative_value(
df=dfx,
xcats=xcatx,
cids=cidx,
blacklist=fxblack,
postfix="vGLB",
)
dfx = msm.update_df(dfx, dfa)
# Scoring of relative values
cidx = cids_dux
xcatx = [xc + "vGLB" for xc in list(dict_gdp.keys())]
dfa = pd.DataFrame(columns=dfx.columns)
for xc in xcatx:
dfaa = msp.make_zn_scores(
dfx,
xcat=xc,
cids=cidx,
sequential=True,
min_obs=261 * 3,
neutral="zero",
pan_weight=1,
thresh=3,
postfix="_ZN",
est_freq="m",
)
dfa = msm.update_df(dfa, dfaa)
dfx = msm.update_df(dfx, dfa)
cidx = cids_dux
xcatx = [xcat + "vGLB_ZN" for xcat in list(dict_gdp.keys())]
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=4,
same_y=False,
all_xticks=True,
size=(12, 7),
aspect=1.8,
title = "GDP growth"
)
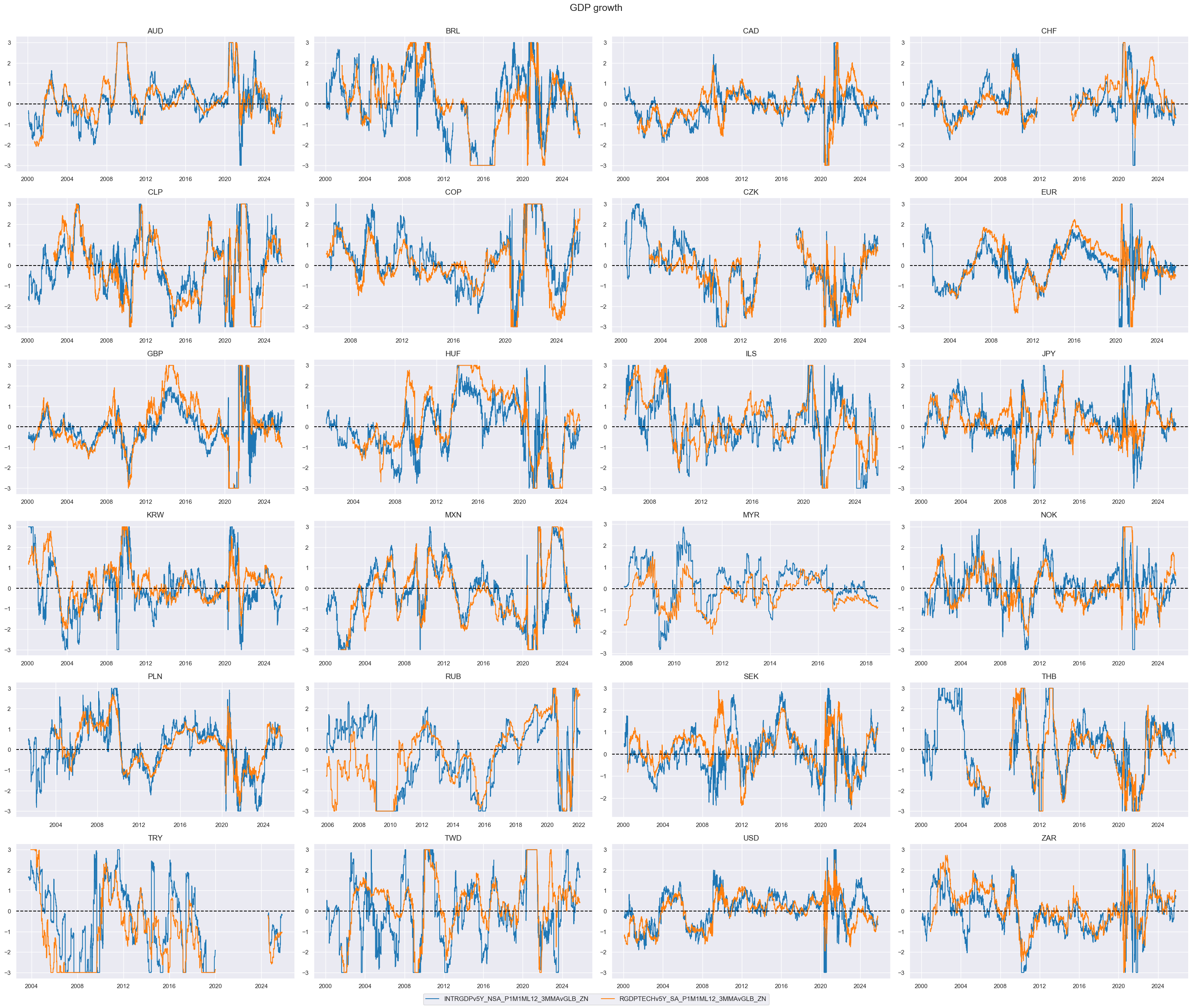
# Weighted linear combination
cidx = cids_dux
dix = dict_gdp
xcatx = [k + "vGLB_ZN" for k in list(dix.keys())]
weights = [v[0] for v in list(dix.values())]
signs = [v[1] for v in list(dix.values())]
czs = "RGDPGROWTHvGLB_NEG"
dfa = msp.linear_composite(
dfx,
xcats=xcatx,
cids=cidx,
weights=weights,
signs=signs,
normalize_weights=True,
complete_xcats=False, # score works with what is available
new_xcat=czs,
)
dfx = msm.update_df(dfx, dfa)
# Re-scoring
dfa = msp.make_zn_scores(
dfx,
xcat=czs,
cids=cidx,
sequential=True,
min_obs=261 * 3,
neutral="zero",
pan_weight=1,
thresh=3,
postfix="_ZN",
est_freq="m",
)
dfx = msm.update_df(dfx, dfa)
dict_facts[czs + "_ZN"] = "Relative GDP growth shortfall"
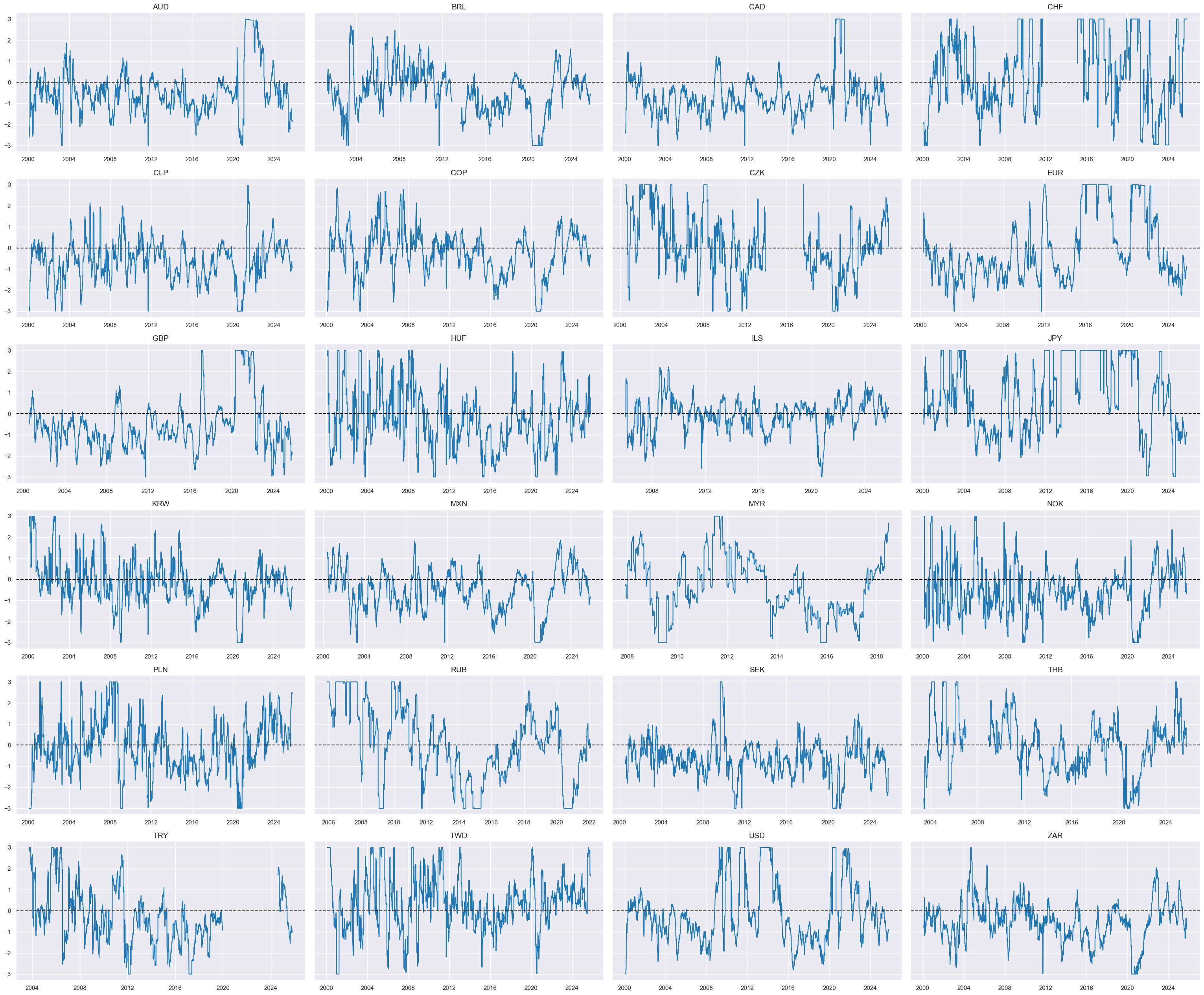
cids_dux
xcatx = ['RGDPGROWTHvGLB_NEG_ZN']
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=4,
same_y=True,
all_xticks=True,
size=(12, 7),
aspect=1.8
)
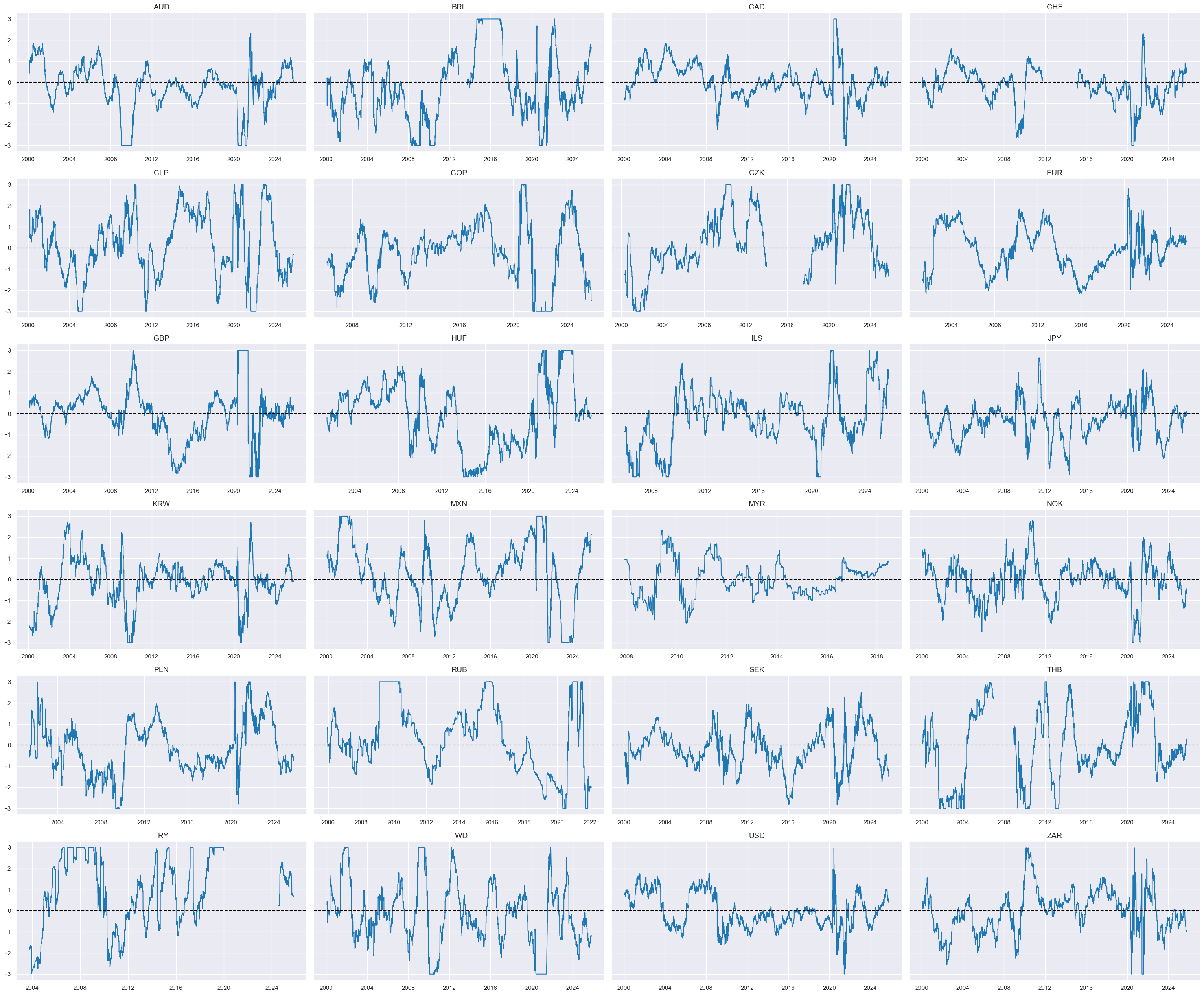
Relative consumption growth shortfall #
dict_pcons = {
"RRSALES_SA_P1M1ML12_3MMA": (1/6, -1),
"RPCONS_SA_P1M1ML12_3MMA": (1/6, -1),
}
# Excess private consumption
cidx = cids_dux
xcatx = list(dict_pcons.keys())
for xc in xcatx:
calcs = [f"X{xc} = {xc} - RGDP_SA_P1Q1QL4_20QMA",]
dfa = msp.panel_calculator(dfx, calcs=calcs, cids=cids_dux)
dfx = msm.update_df(dfx, dfa)
cidx = cids_dux
xcatx = [f"X{xcat}" for xcat in dict_pcons.keys()]
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=4,
same_y=False,
all_xticks=True,
size=(12, 7),
aspect=1.8
)
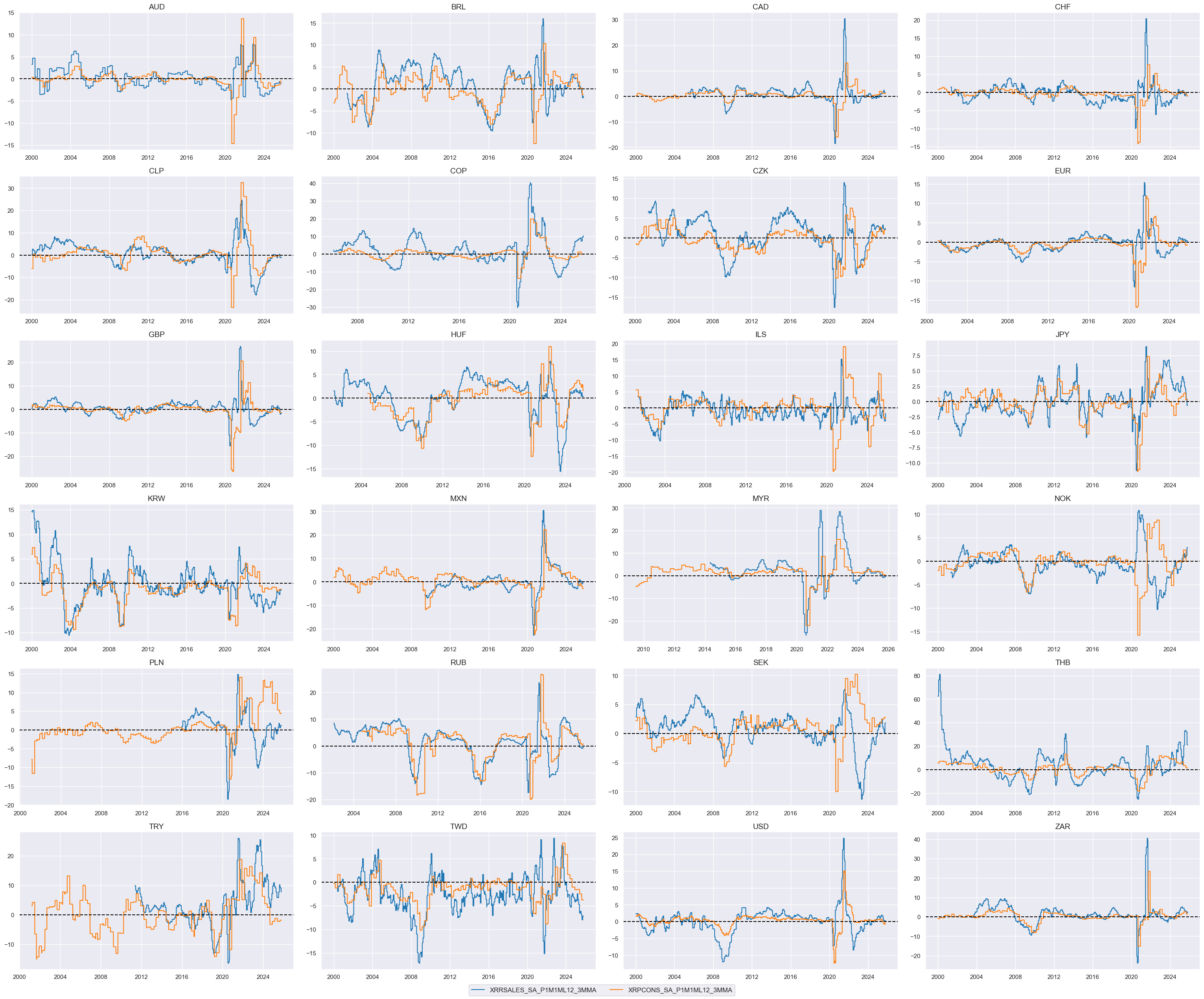
# Relative value of constituents
cidx = cids_dux
xcatx = [f"X{xcat}" for xcat in dict_pcons.keys()]
dfa = msp.make_relative_value(
df=dfx,
xcats=xcatx,
cids=cidx,
blacklist=fxblack,
postfix="vGLB",
)
dfx = msm.update_df(dfx, dfa)
# Scoring of relative values
cidx = cids_dux
xcatx = ["X" + xc + "vGLB" for xc in list(dict_pcons.keys())]
dfa = pd.DataFrame(columns=dfx.columns)
for xc in xcatx:
dfaa = msp.make_zn_scores(
dfx,
xcat=xc,
cids=cidx,
sequential=True,
min_obs=261 * 3,
neutral="zero",
pan_weight=1,
thresh=3,
postfix="_ZN",
est_freq="m",
)
dfa = msm.update_df(dfa, dfaa)
dfx = msm.update_df(dfx, dfa)
cidx = cids_dux
xcatx = ["X" + xcat + "vGLB_ZN" for xcat in list(dict_pcons.keys())]
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=4,
same_y=False,
all_xticks=True,
size=(12, 7),
aspect=1.8,
)
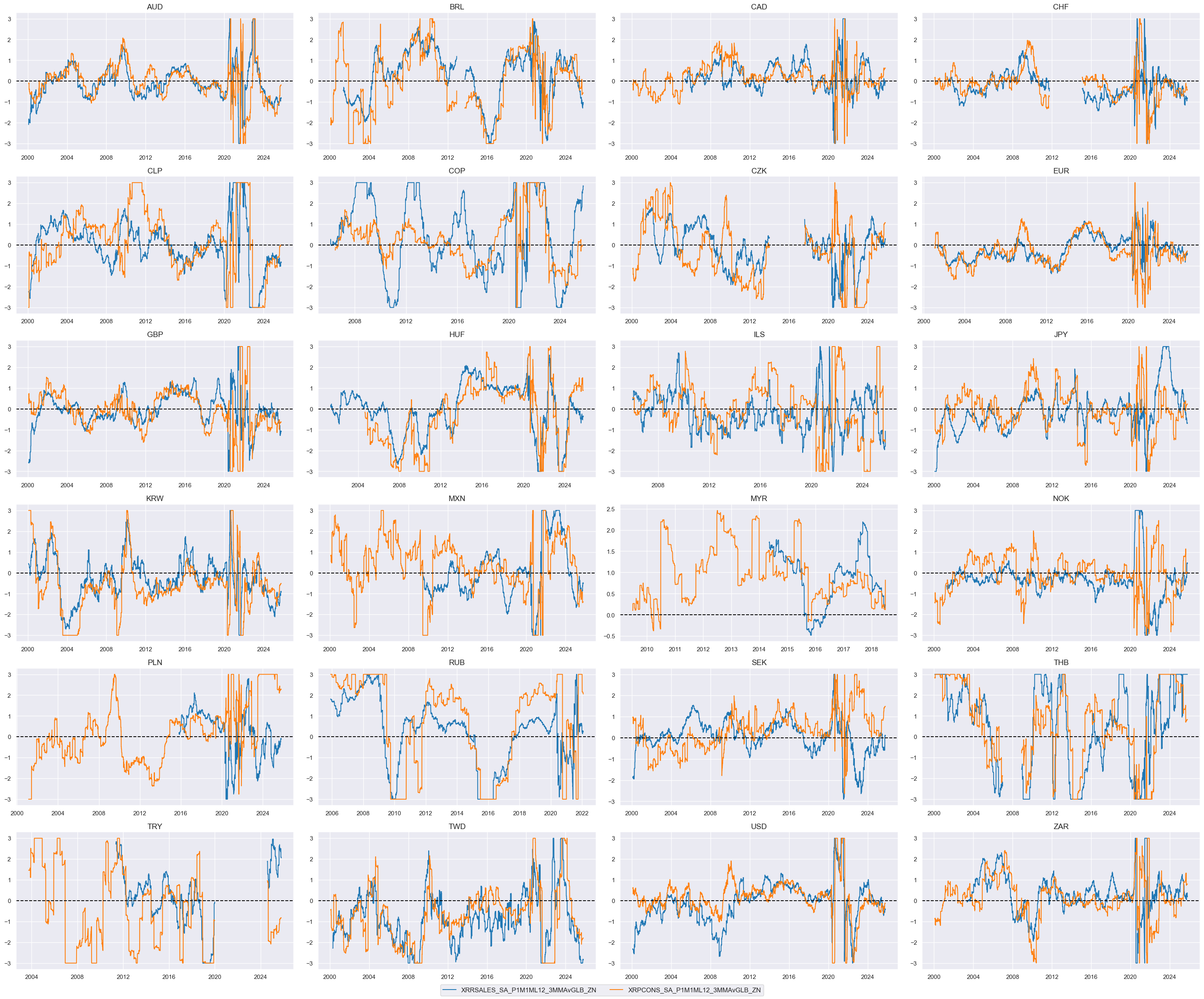
# Weighted linear combination
cidx = cids_dux
dix = dict_pcons
xcatx = ["X" + k + "vGLB_ZN" for k in list(dix.keys())]
weights = [v[0] for v in list(dix.values())]
signs = [v[1] for v in list(dix.values())]
czs = "PCONSGROWTHvGLB_NEG"
dfa = msp.linear_composite(
dfx,
xcats=xcatx,
cids=cidx,
weights=weights,
signs=signs,
normalize_weights=True,
complete_xcats=False, # score works with what is available
new_xcat=czs,
)
dfx = msm.update_df(dfx, dfa)
# Re-scoring
dfa = msp.make_zn_scores(
dfx,
xcat=czs,
cids=cidx,
sequential=True,
min_obs=261 * 3,
neutral="zero",
pan_weight=1,
thresh=3,
postfix="_ZN",
est_freq="m",
)
dfx = msm.update_df(dfx, dfa)
dict_facts[czs + "_ZN"] = "Relative consumption growth shortfall"
cids_dux
xcatx = ['PCONSGROWTHvGLB_NEG_ZN']
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=4,
same_y=True,
all_xticks=True,
size=(12, 7),
aspect=1.8
)
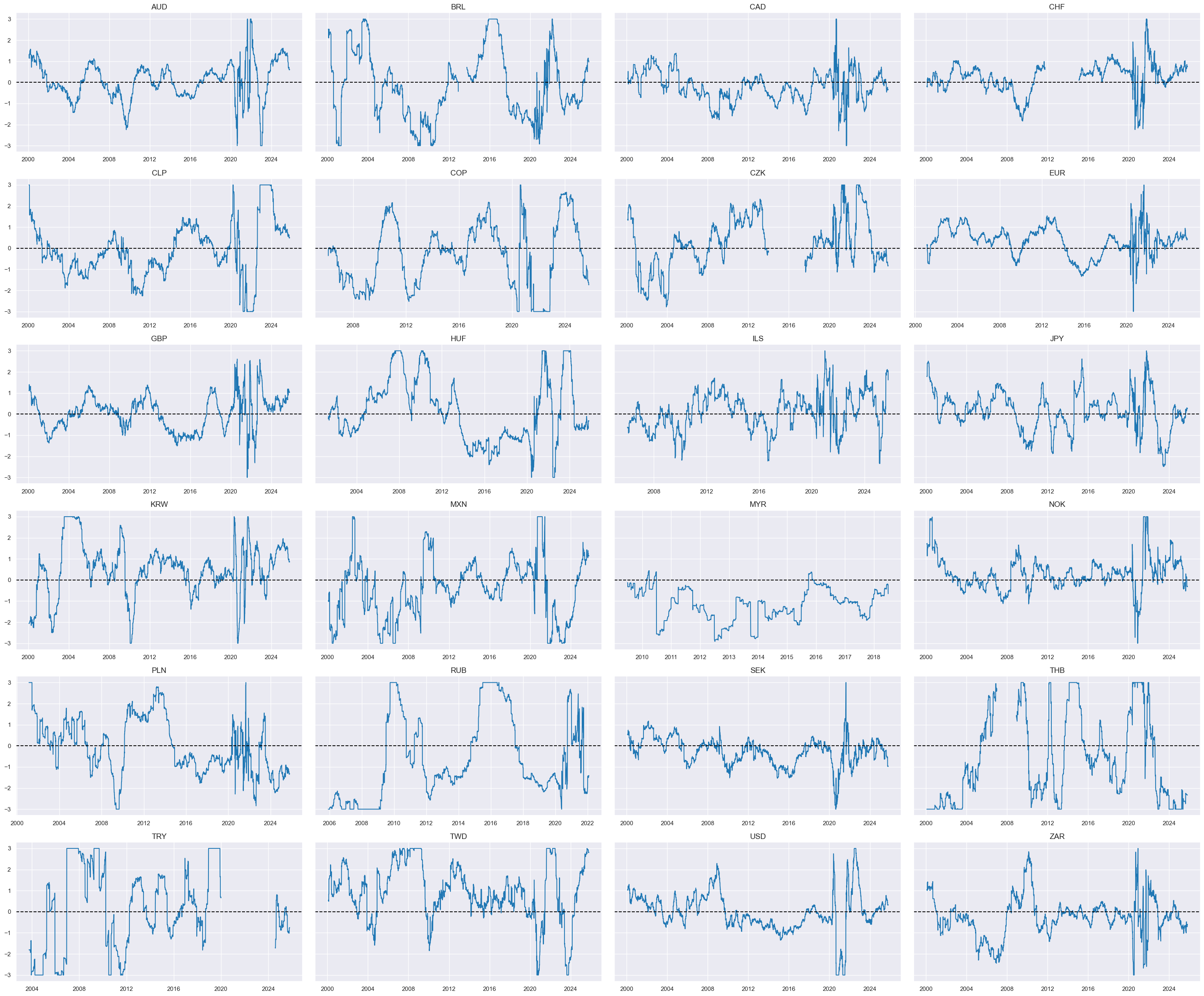
Relative credit growth shortfall #
dict_credit = {
"XPCREDITBN_SJA_P1M1ML12" : (1/2, -1),
"PCREDITBN_SJA_P1M1ML12" : (1/2, -1),
}
calcs = [
"XPCREDITBN_SJA_P1M1ML12 = PCREDITBN_SJA_P1M1ML12 - INFTEFF_NSA - RGDP_SA_P1Q1QL4_20QMA",
]
dfa = msp.panel_calculator(dfx, calcs=calcs, cids=cids)
dfx = msm.update_df(dfx, dfa)
cidx = cids_dux
xcatx = list(dict_credit.keys())
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=4,
same_y=False,
all_xticks=True,
size=(12, 7),
aspect=1.8
)
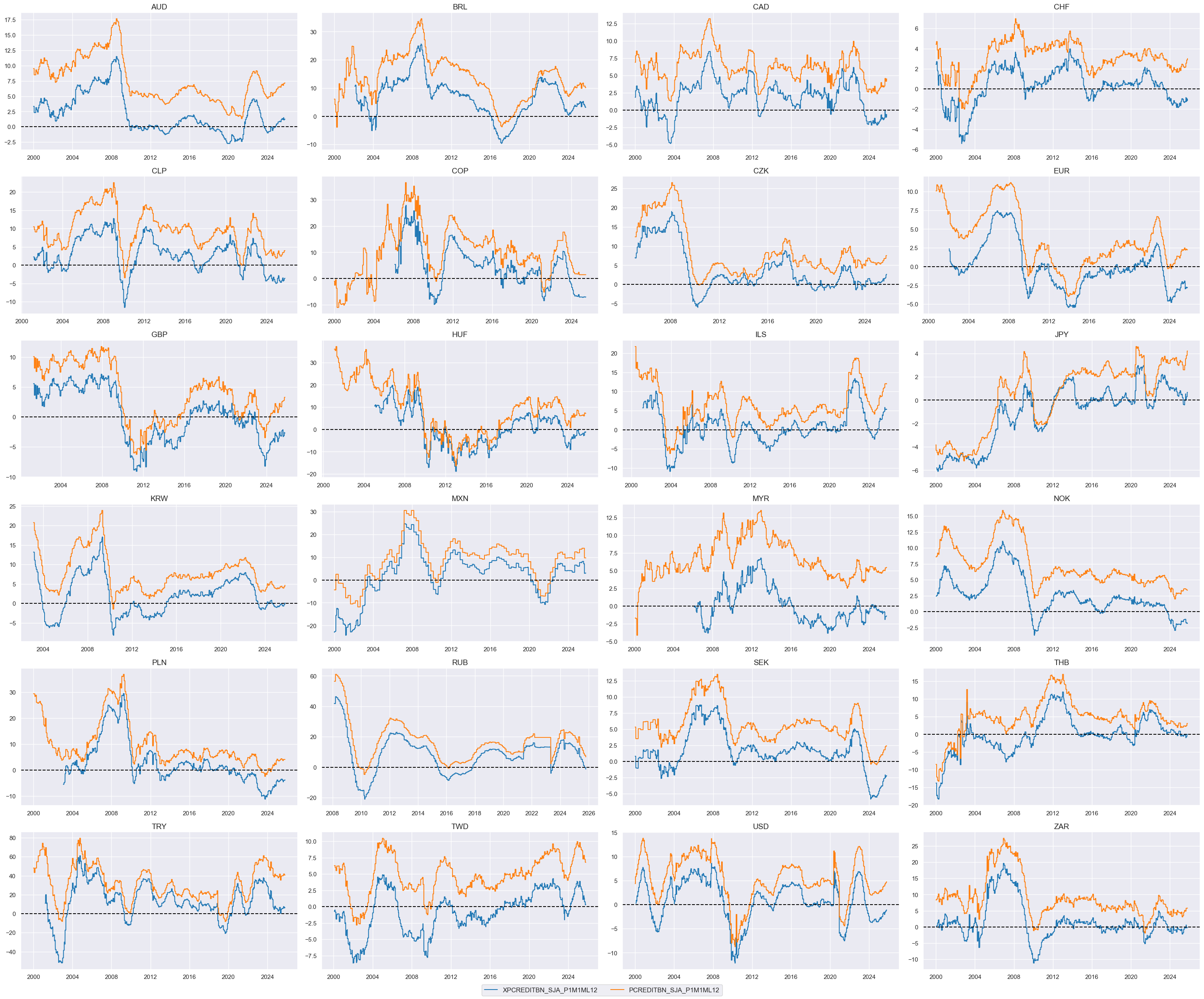
# Relative value of constituents
cidx = cids_dux
xcatx = list(dict_credit.keys())
dfa = msp.make_relative_value(
df=dfx,
xcats=xcatx,
cids=cidx,
blacklist=fxblack,
postfix="vGLB",
)
dfx = msm.update_df(dfx, dfa)
# Scoring of relative values
cidx = cids_dux
xcatx = [xc + "vGLB" for xc in list(dict_credit.keys())]
dfa = pd.DataFrame(columns=dfx.columns)
for xc in xcatx:
dfaa = msp.make_zn_scores(
dfx,
xcat=xc,
cids=cidx,
sequential=True,
min_obs=261 * 3,
neutral="zero",
pan_weight=1,
thresh=3,
postfix="_ZN",
est_freq="m",
)
dfa = msm.update_df(dfa, dfaa)
dfx = msm.update_df(dfx, dfa)
cidx = cids_dux
xcatx = [xc + "vGLB_ZN" for xc in list(dict_credit.keys())]
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=4,
same_y=False,
all_xticks=True,
size=(12, 7),
aspect=1.8,
)
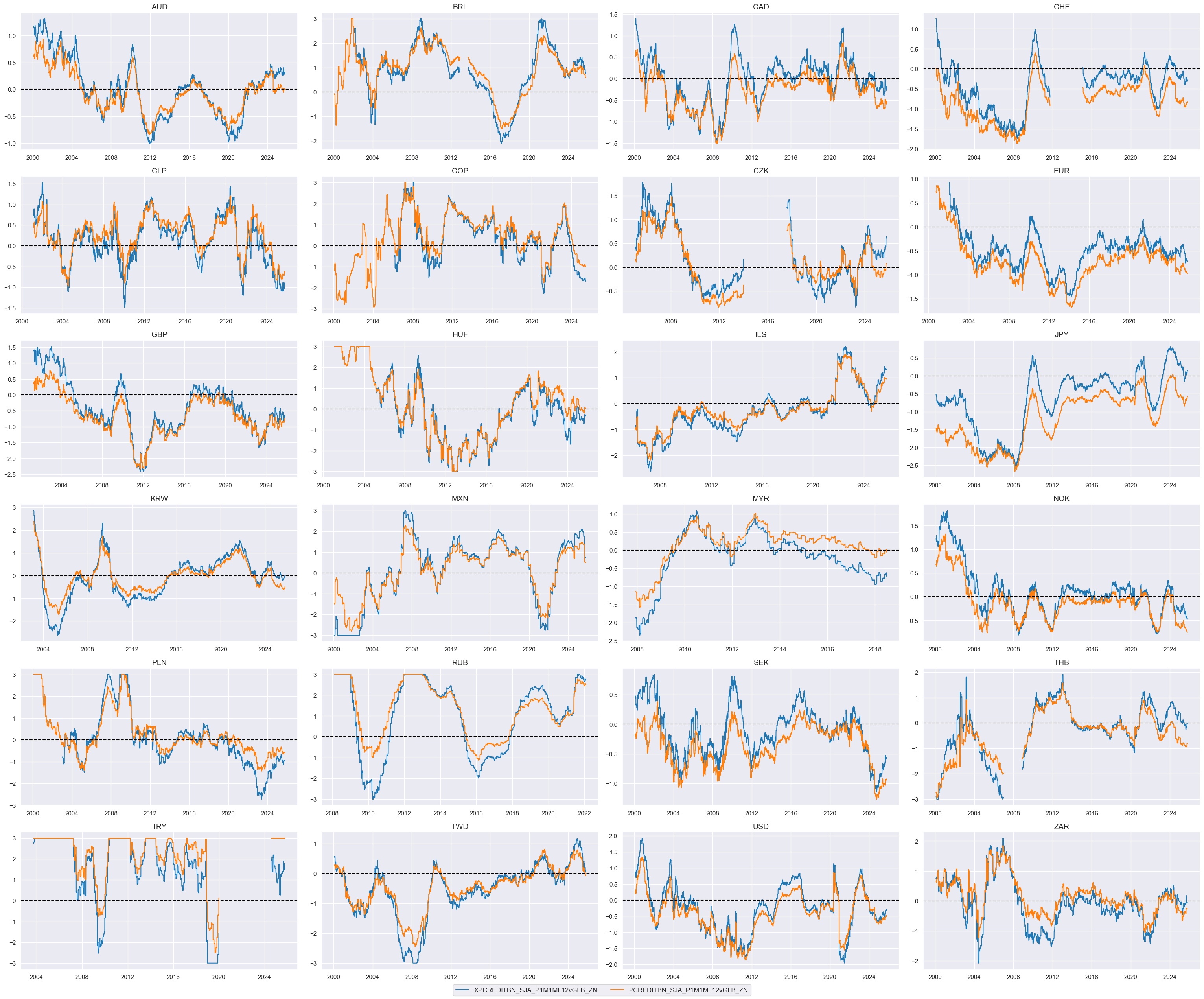
# Weighted linear combination
cidx = cids_dux
dix = dict_credit
xcatx = [k + "vGLB_ZN" for k in list(dix.keys())]
weights = [v[0] for v in list(dix.values())]
signs = [v[1] for v in list(dix.values())]
czs = "PCREDITGROWTHvGLB_NEG"
dfa = msp.linear_composite(
dfx,
xcats=xcatx,
cids=cidx,
weights=weights,
signs=signs,
normalize_weights=True,
complete_xcats=False, # score works with what is available
new_xcat=czs,
)
dfx = msm.update_df(dfx, dfa)
# Re-scoring
dfa = msp.make_zn_scores(
dfx,
xcat=czs,
cids=cidx,
sequential=True,
min_obs=261 * 3,
neutral="zero",
pan_weight=1,
thresh=3,
postfix="_ZN",
est_freq="m",
)
dfx = msm.update_df(dfx, dfa)
dict_facts[czs + "_ZN"] = "Relative credit growth shortfall"
cids_dux
xcatx = 'PCREDITGROWTHvGLB_NEG_ZN'
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=4,
same_y=True,
all_xticks=True,
size=(12, 7),
aspect=1.8
)
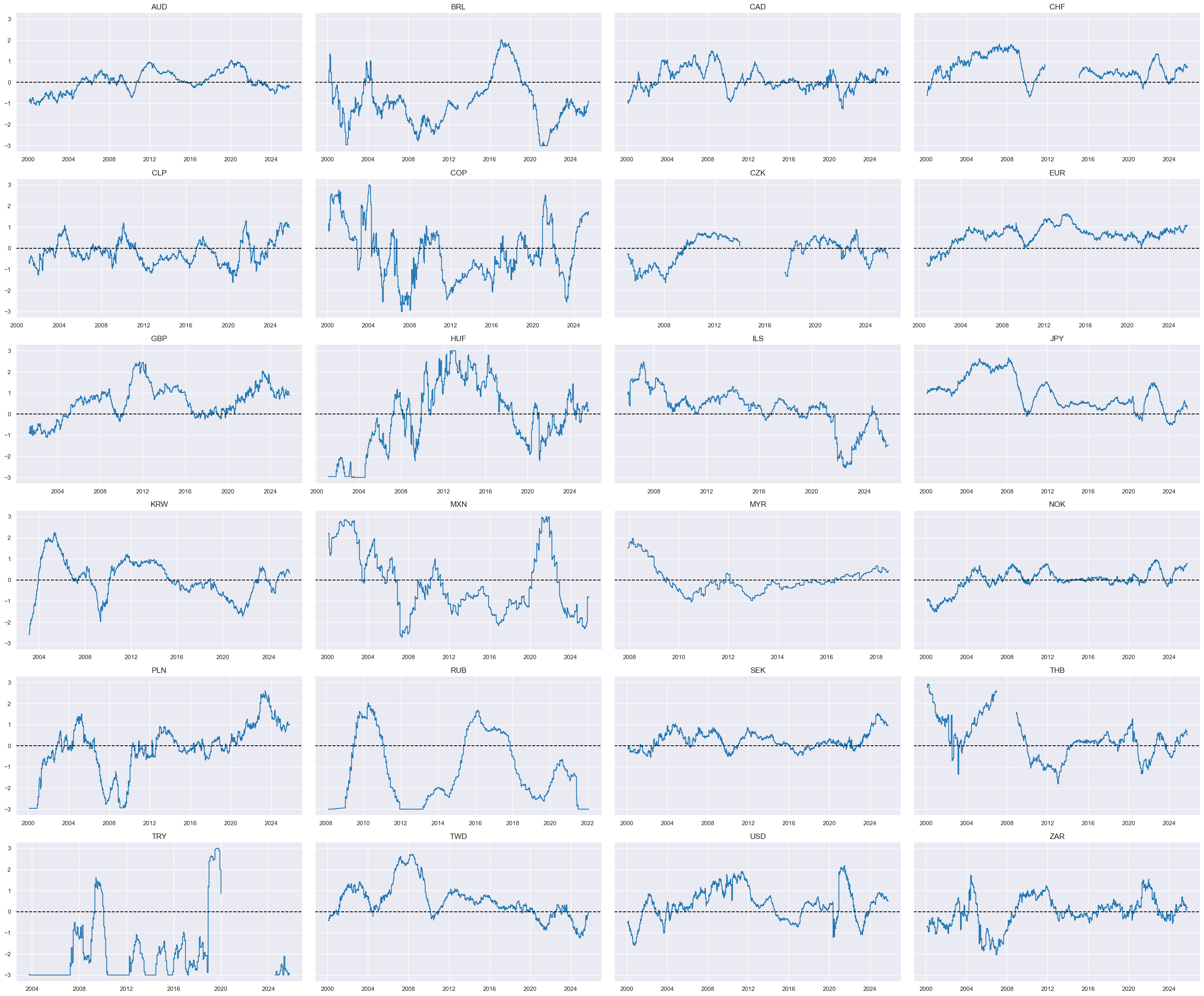
Relative house price growth shortfall ratios #
dict_hpi = {
"HPI_SA_P1M1ML12_3MMA" : (1/2, -1),
"HPI_SA_P6M6ML6AR": (1/2, -1)
}
cidx = cids_dux
xcatx = list(dict_hpi.keys())
for xc in xcatx:
calcs = [f"{xc}vIETR = ( {xc} - INFTEFF_NSA ) / INFTEBASIS",]
dfa = msp.panel_calculator(dfx, calcs=calcs, cids=cids_dux)
dfx = msm.update_df(dfx, dfa)
cidx = cids_dux
xcatx = [xc + "vIETR" for xc in list(dict_hpi.keys())]
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=4,
same_y=True,
all_xticks=True,
size=(12, 7),
aspect=1.8
)
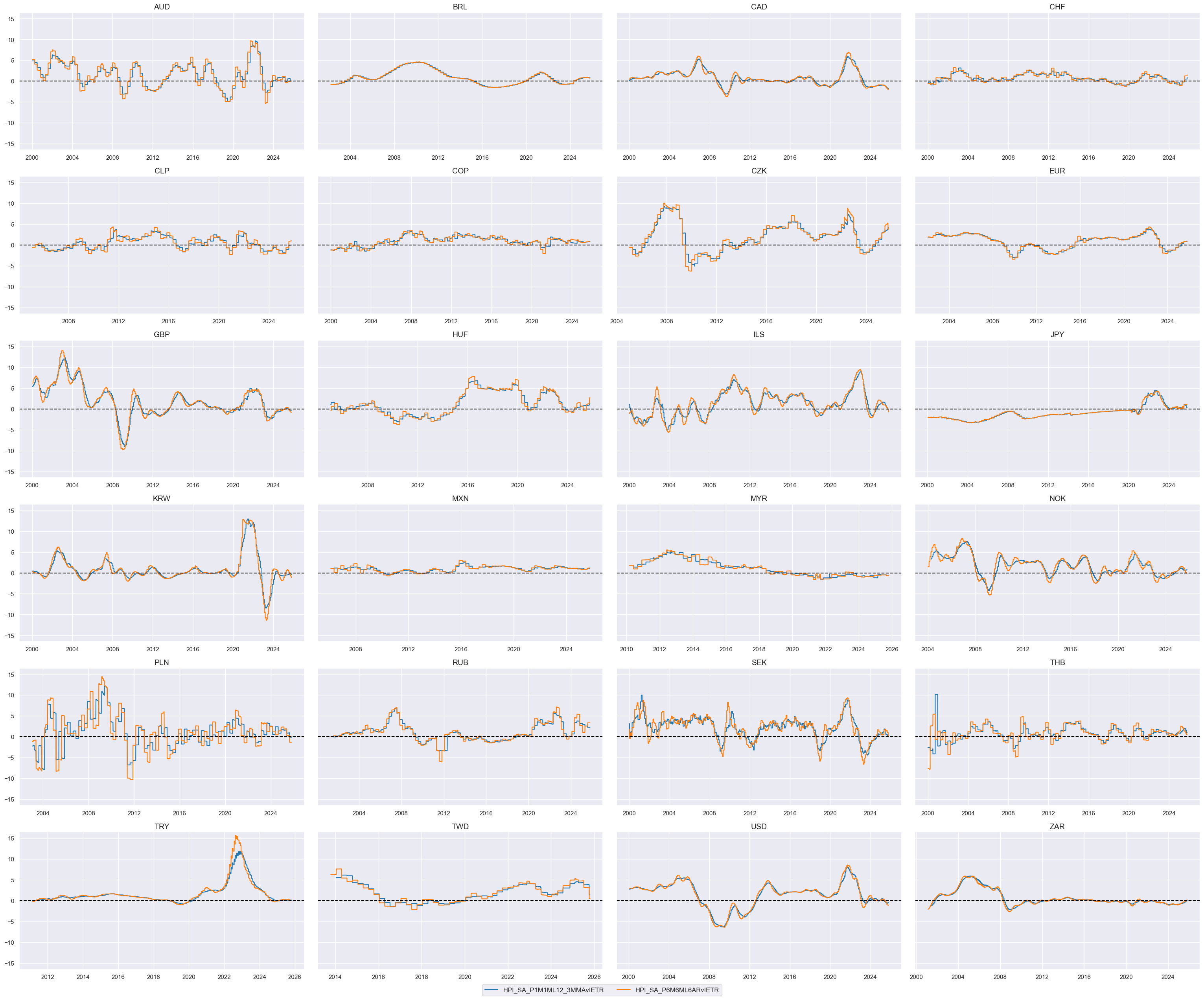
# Relative value of constituents
cidx = cids_dux
xcatx = list(dict_hpi.keys())
dfa = msp.make_relative_value(
df=dfx,
xcats=xcatx,
cids=cidx,
blacklist=fxblack,
postfix="vGLB",
)
dfx = msm.update_df(dfx, dfa)
# Scoring of relative values
cidx = cids_dux
xcatx = [xc + "vGLB" for xc in list(dict_hpi.keys())]
dfa = pd.DataFrame(columns=dfx.columns)
for xc in xcatx:
dfaa = msp.make_zn_scores(
dfx,
xcat=xc,
cids=cidx,
sequential=True,
min_obs=261 * 3,
neutral="zero",
pan_weight=1,
thresh=3,
postfix="_ZN",
est_freq="m",
)
dfa = msm.update_df(dfa, dfaa)
dfx = msm.update_df(dfx, dfa)
cidx = cids_dux
xcatx = [xcat + "vGLB_ZN" for xcat in list(dict_hpi.keys())]
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=4,
same_y=False,
all_xticks=True,
size=(12, 7),
aspect=1.8,
)
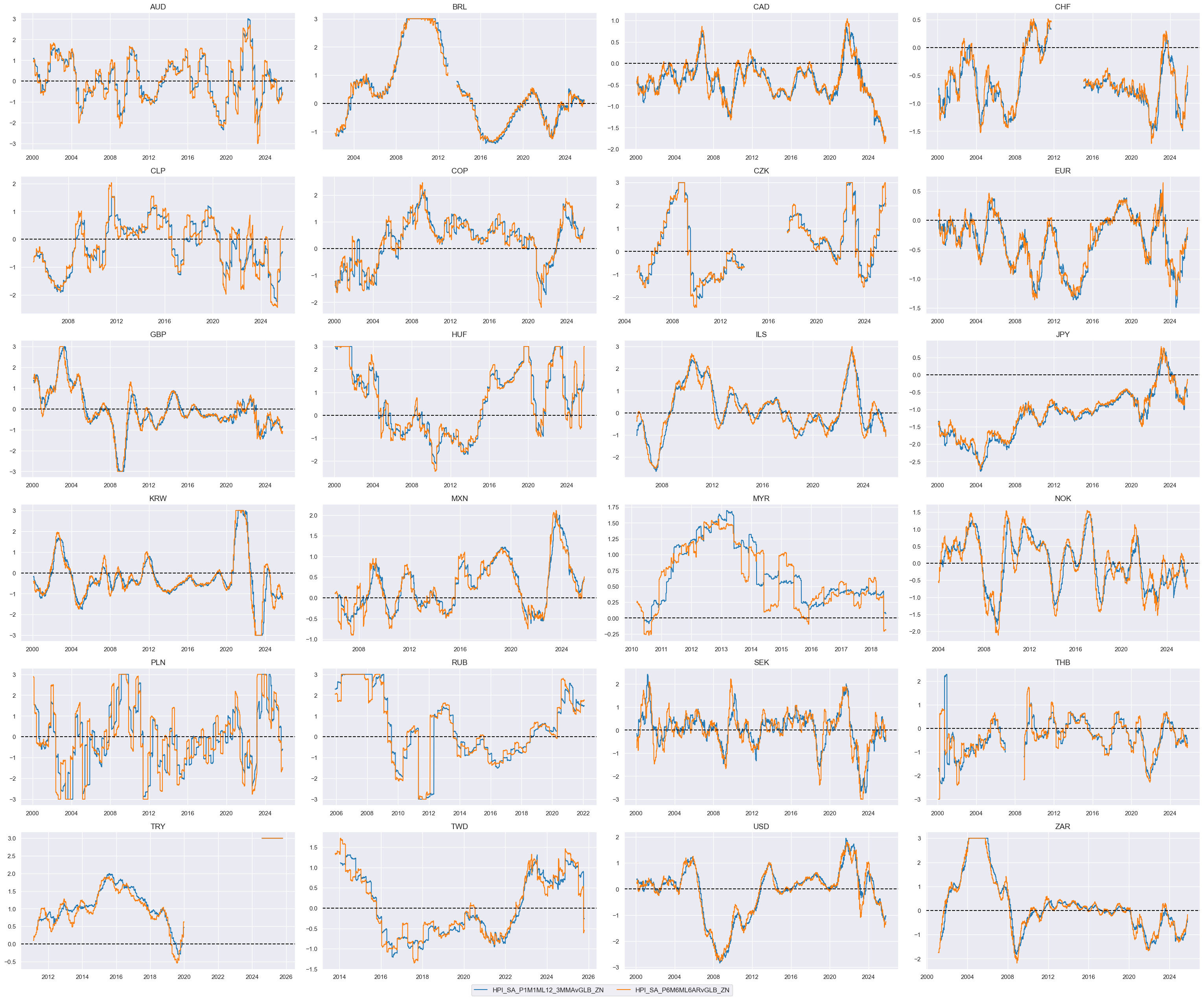
# Weighted linear combination (degenerate case)
cidx = cids_dux
dix = dict_hpi
xcatx = [k + "vGLB_ZN" for k in list(dix.keys())]
weights = [v[0] for v in list(dix.values())]
signs = [v[1] for v in list(dix.values())]
czs = "XHPIvGLB_NEG"
dfa = msp.linear_composite(
dfx,
xcats=xcatx,
cids=cidx,
weights=weights,
signs=signs,
normalize_weights=True,
complete_xcats=False, # score works with what is available
new_xcat=czs,
)
dfx = msm.update_df(dfx, dfa)
# Re-scoring
dfa = msp.make_zn_scores(
dfx,
xcat=czs,
cids=cidx,
sequential=True,
min_obs=261 * 3,
neutral="zero",
pan_weight=1,
thresh=3,
postfix="_ZN",
est_freq="m",
)
dfx = msm.update_df(dfx, dfa)
dict_facts[czs + "_ZN"] = "Relative house price shortfall"
cids_dux
xcatx = 'XHPIvGLB_NEG_ZN'
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=4,
same_y=True,
all_xticks=True,
size=(12, 7),
aspect=1.8
)
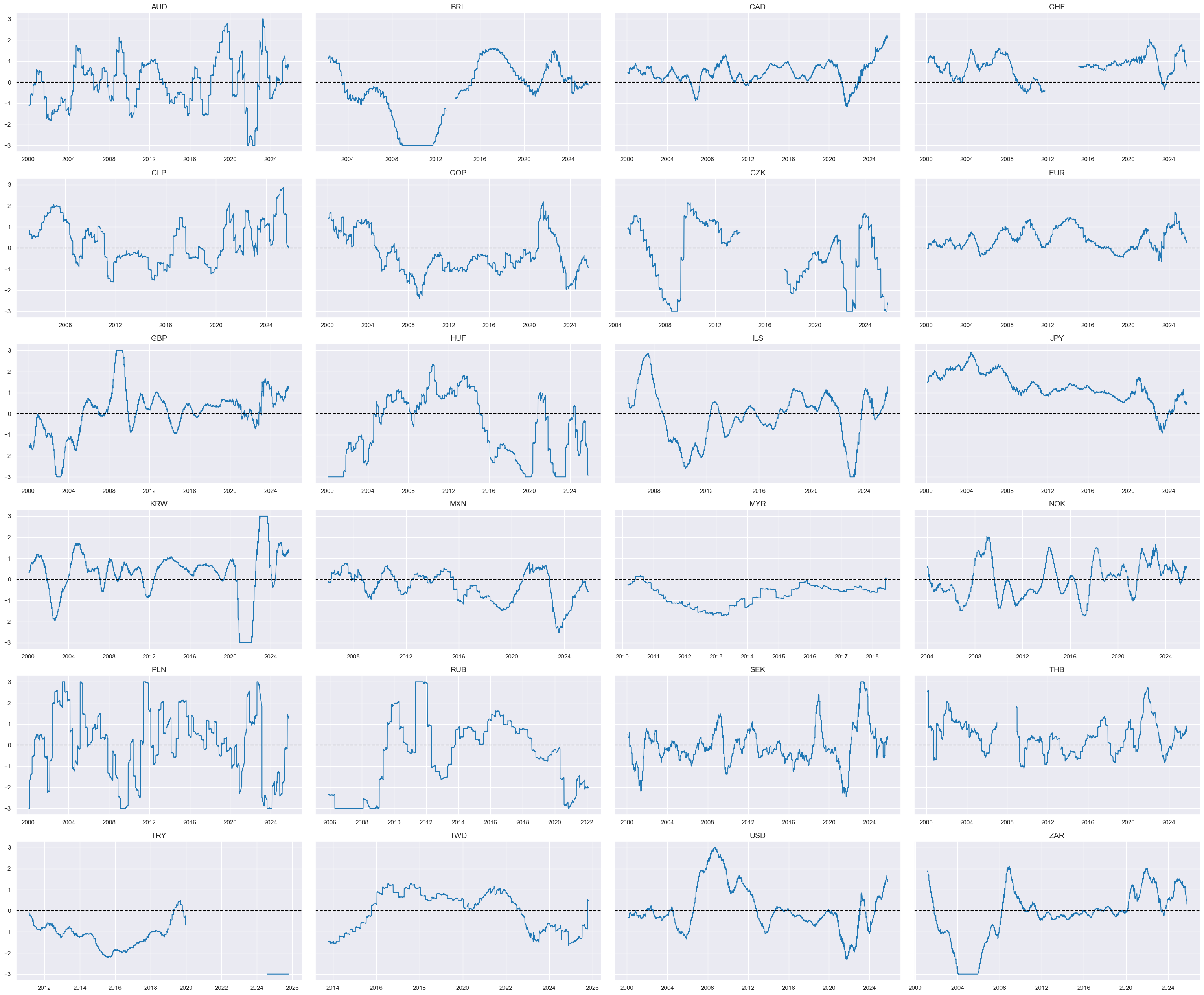
Relative fiscal austerity #
dict_fisc = {
"GGFTGDPRATIO_NSA" : (1/2, -1),
"GGOBGDPRATIO_NSA" : (1/2, 1),
}
cidx = cids_dux
xcatx = list(dict_fisc.keys())
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=4,
same_y=False,
all_xticks=True,
size=(12, 7),
aspect=1.8
)
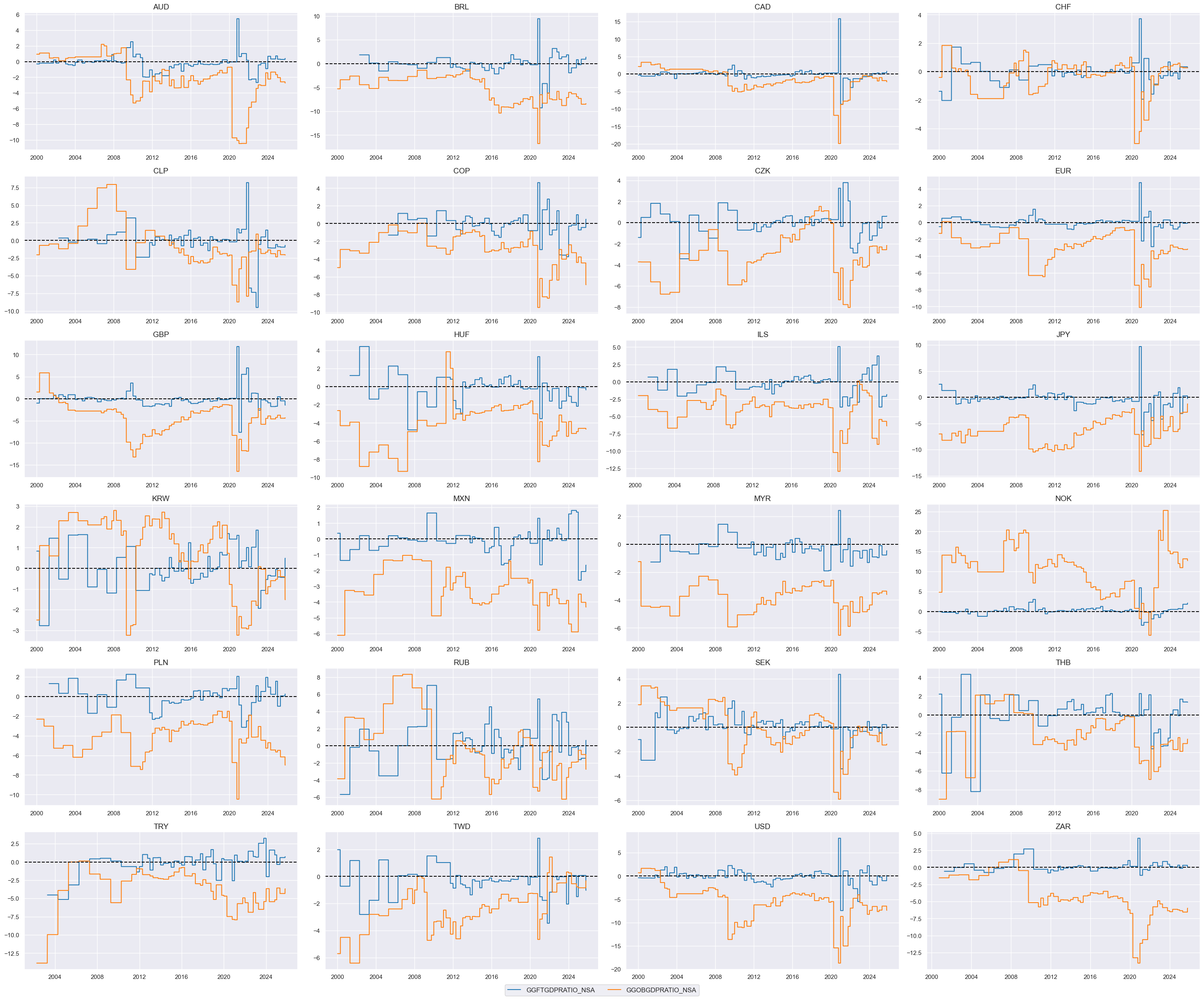
# Relative value of constituents
cidx = cids_dux
xcatx = list(dict_fisc.keys())
dfa = msp.make_relative_value(
df=dfx,
xcats=xcatx,
cids=cidx,
blacklist=fxblack,
postfix="vGLB",
)
dfx = msm.update_df(dfx, dfa)
# Scoring of relative values
cidx = cids_dux
xcatx = [xc + "vGLB" for xc in list(dict_fisc.keys())]
dfa = pd.DataFrame(columns=dfx.columns)
for xc in xcatx:
dfaa = msp.make_zn_scores(
dfx,
xcat=xc,
cids=cidx,
sequential=True,
min_obs=261 * 3,
neutral="zero",
pan_weight=1,
thresh=3,
postfix="_ZN",
est_freq="m",
)
dfa = msm.update_df(dfa, dfaa)
dfx = msm.update_df(dfx, dfa)
cidx = cids_dux
xcatx = [xcat + "vGLB_ZN" for xcat in list(dict_fisc.keys())]
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=4,
same_y=False,
all_xticks=True,
size=(12, 7),
aspect=1.8,
)
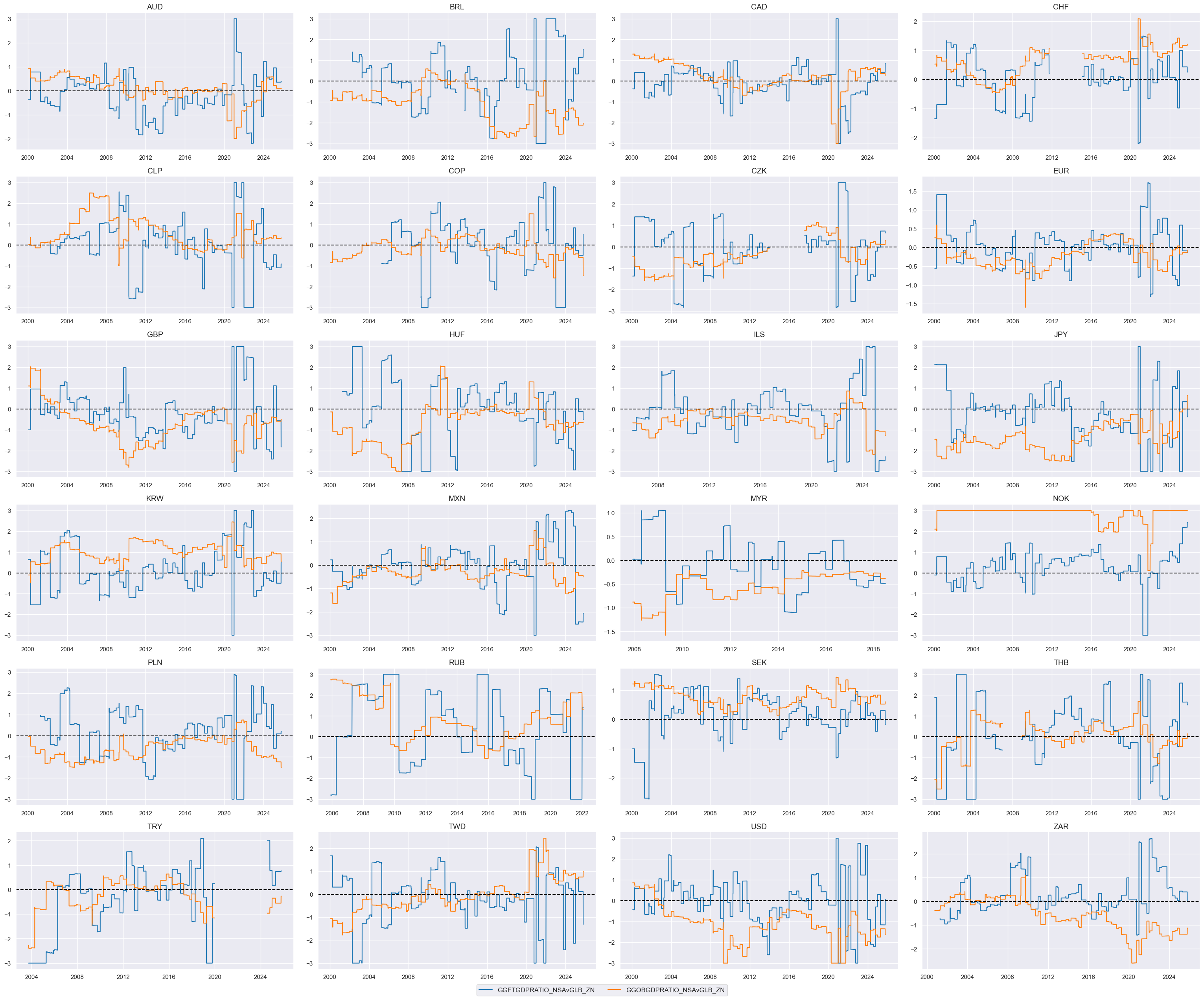
# Weighted linear combination (degenerate case)
cidx = cids_dux
dix = dict_fisc
xcatx = [k + "vGLB_ZN" for k in list(dix.keys())]
weights = [v[0] for v in list(dix.values())]
signs = [v[1] for v in list(dix.values())]
czs = "AUSTERITYvGLB"
dfa = msp.linear_composite(
dfx,
xcats=xcatx,
cids=cidx,
weights=weights,
signs=signs,
normalize_weights=True,
complete_xcats=False, # score works with what is available
new_xcat=czs,
)
dfx = msm.update_df(dfx, dfa)
# Re-scoring
dfa = msp.make_zn_scores(
dfx,
xcat=czs,
cids=cidx,
sequential=True,
min_obs=261 * 3,
neutral="zero",
pan_weight=1,
thresh=3,
postfix="_ZN",
est_freq="m",
)
dfx = msm.update_df(dfx, dfa)
dict_facts[czs + "_ZN"] = "Relative fiscal austerity"
cids_dux
xcatx = 'AUSTERITYvGLB_ZN'
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
ncol=4,
same_y=True,
all_xticks=True,
size=(12, 7),
aspect=1.8
)
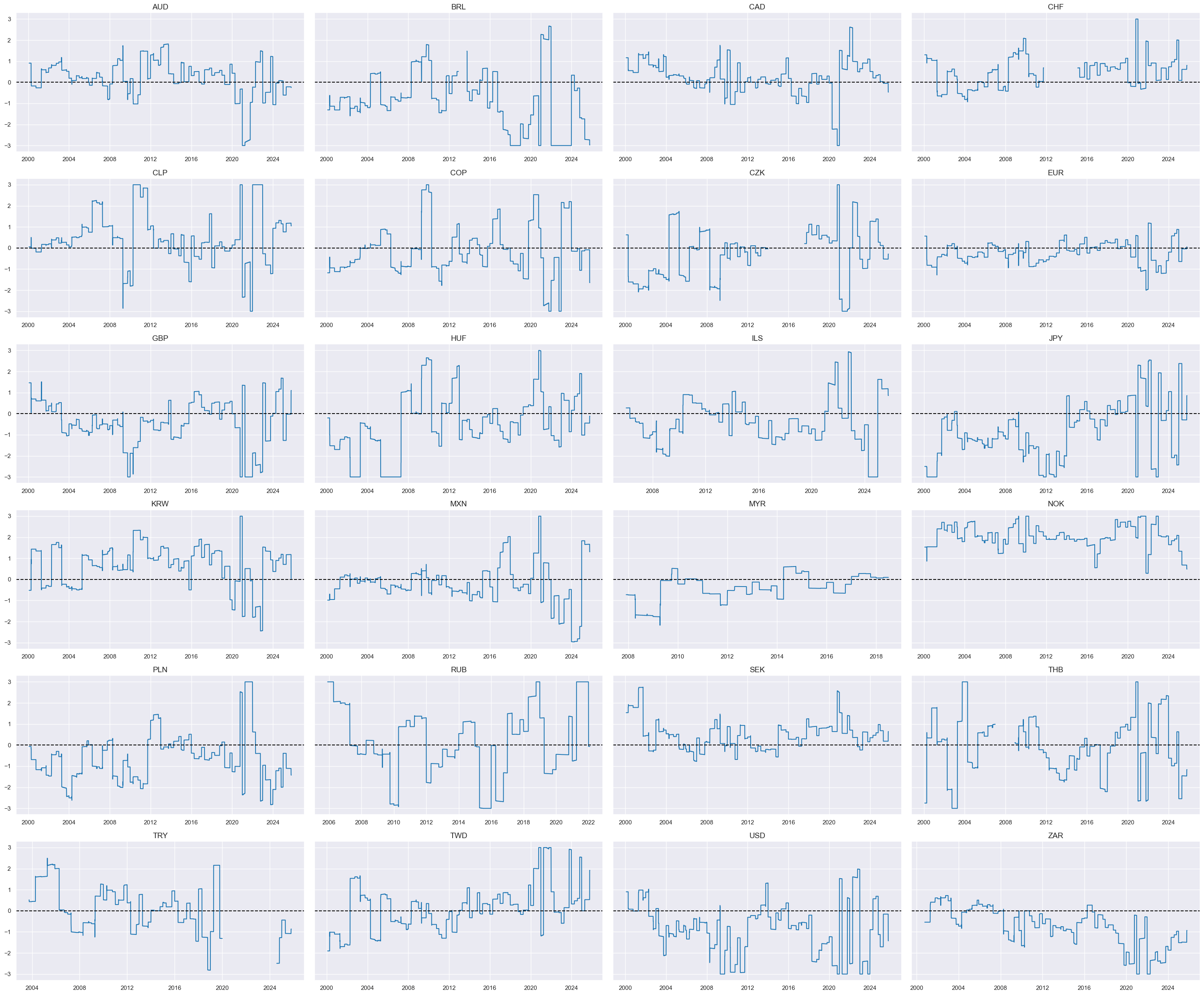
Visual checks #
dict_facts
{'XINFLvGLB_NEG_ZN': 'Relative inflation shortfall',
'INFLCHGRvGLB_NEG_ZN': 'Relative disinflation ratio',
'RRCRvGLB_ZN': 'Relative real yields and carry',
'REEROACHGvGLB_ZN': 'Relative real appreciation',
'XBALvGLB_ZN': 'Relative external balances',
'MTBCHGvGLB_ZN': 'Relative trade balance changes',
'LIQCHGvGLB_ZN': 'Relative liquidity growth',
'RGDPGROWTHvGLB_NEG_ZN': 'Relative GDP growth shortfall',
'PCONSGROWTHvGLB_NEG_ZN': 'Relative consumption growth shortfall',
'PCREDITGROWTHvGLB_NEG_ZN': 'Relative credit growth shortfall',
'XHPIvGLB_NEG_ZN': 'Relative house price shortfall',
'AUSTERITYvGLB_ZN': 'Relative fiscal austerity'}
factorz = [k for k in dict_facts.keys() ]
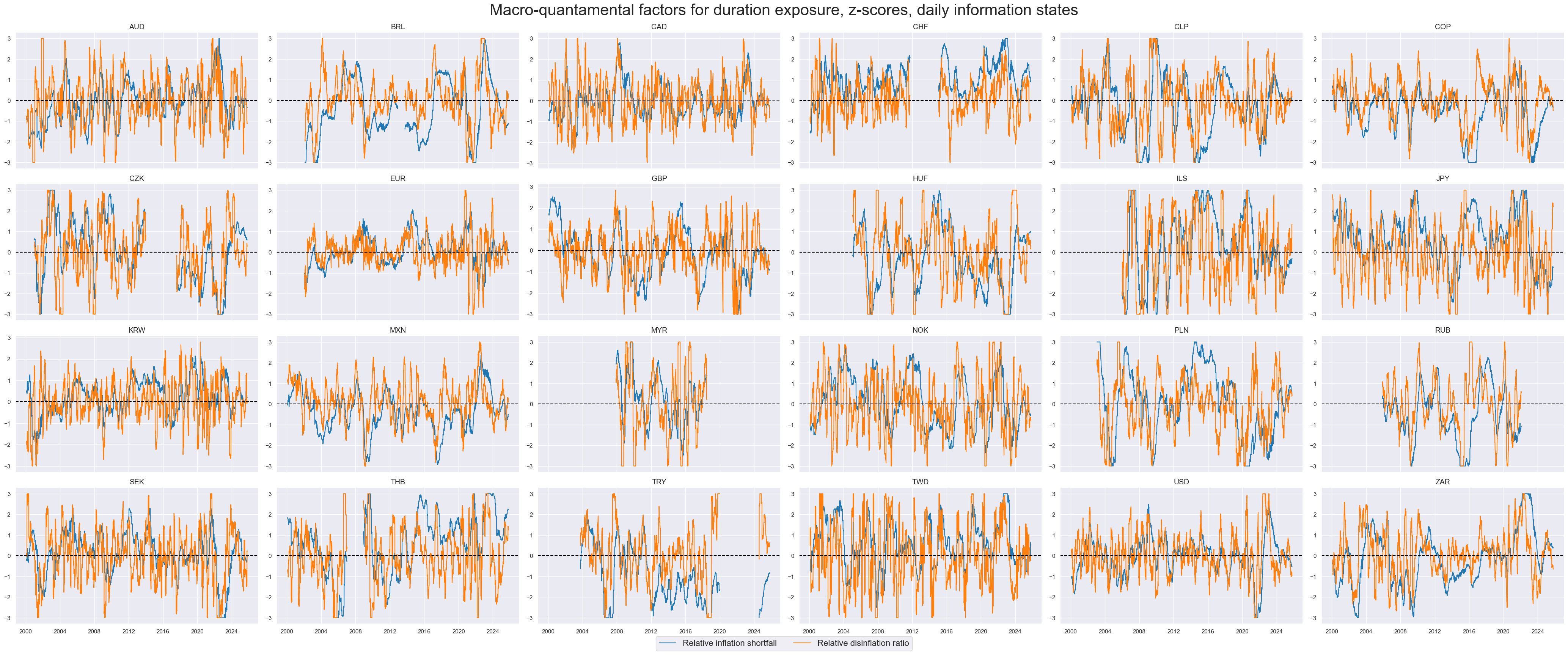
xcatx = ["XINFLvGLB_NEG_ZN", "INFLCHGRvGLB_NEG_ZN"]
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cids_dux,
ncol=6,
start="2000-01-01",
title="Macro-quantamental factors for duration exposure, z-scores, daily information states",
title_fontsize=30,
same_y=False,
cs_mean=False,
legend_fontsize=16,
xcat_labels=dict_facts,
)
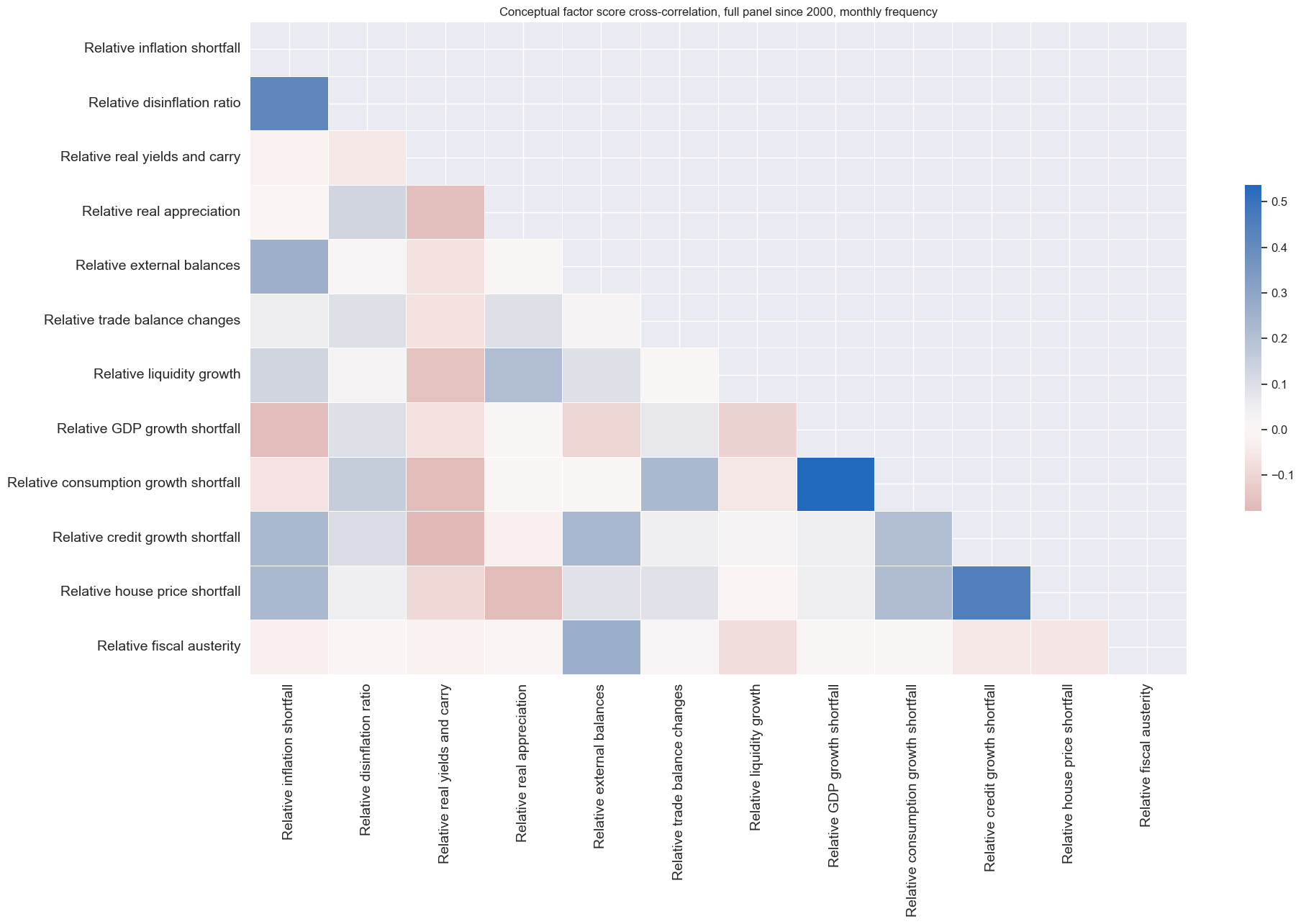
msp.correl_matrix(
df = dfx,
xcats = factorz,
cids = cids_dux,
freq='m',
title="Conceptual factor score cross-correlation, full panel since 2000, monthly frequency",
size=(20, 13),
xcat_labels=dict_facts,
# cluster=True,
)
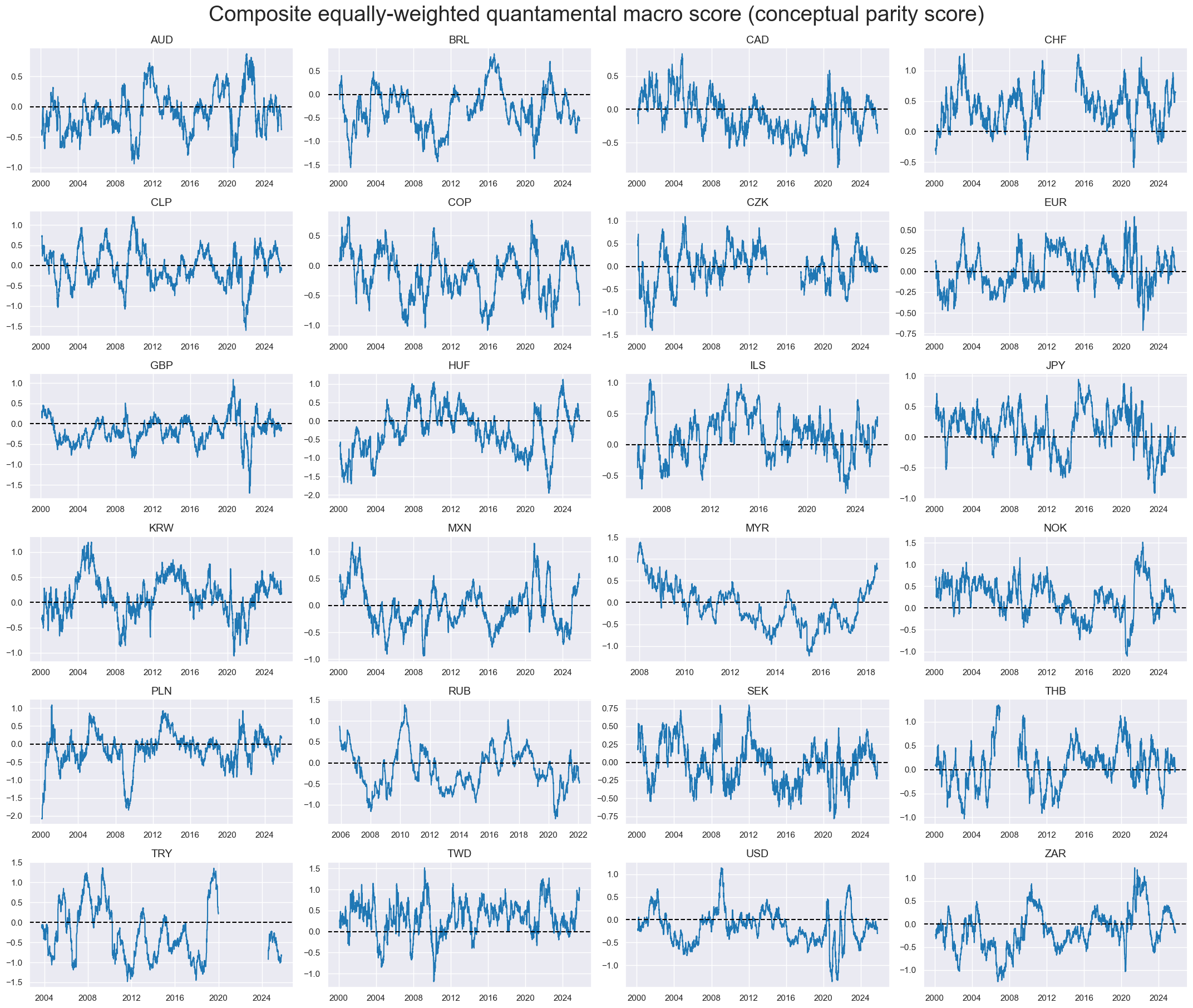
Conceptual parity #
dfa = msp.linear_composite(
df=dfx,
xcats=factorz,
cids=cids,
new_xcat="MACRO_AVGZ",
)
dfx = msm.update_df(dfx, dfa)
xcatx = ["MACRO_AVGZ"]
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
cumsum=False,
ncol=4,
start="2000-01-01",
title_fontsize=28,
size=(10, 6),
aspect=1.8,
height=2,
same_y=False,
title="Composite equally-weighted quantamental macro score (conceptual parity score)",
blacklist=fxblack,
all_xticks=True,
legend_fontsize=16,
)
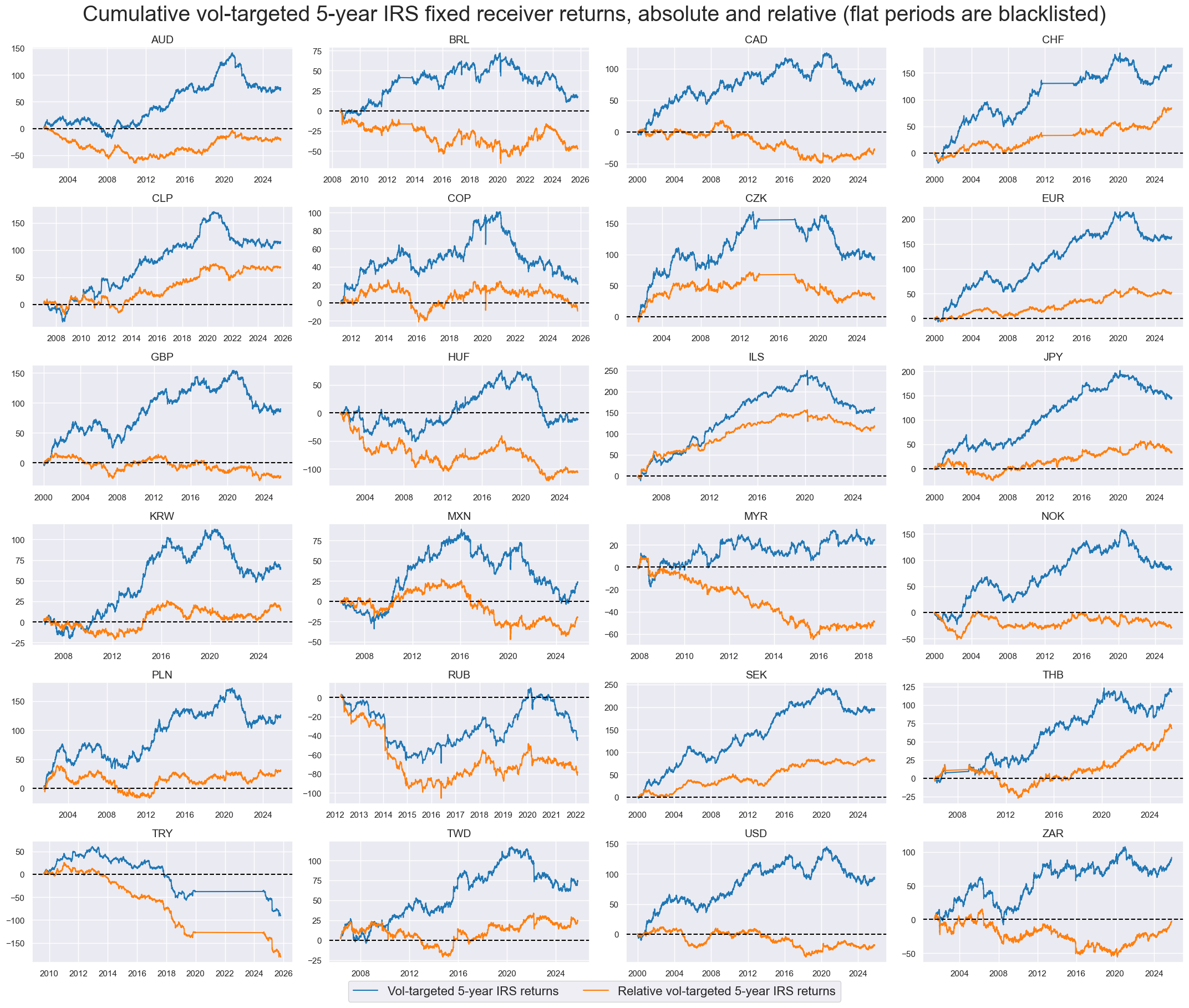
Target relative returns #
cidx = cids_dux
xcatx = ["DU05YXR_VT10", "DU05YXR_NSA"]
dfa = msp.make_relative_value(
df=dfx,
xcats=xcatx,
cids=cidx,
blacklist=fxblack,
)
dfx = msm.update_df(dfx, dfa)
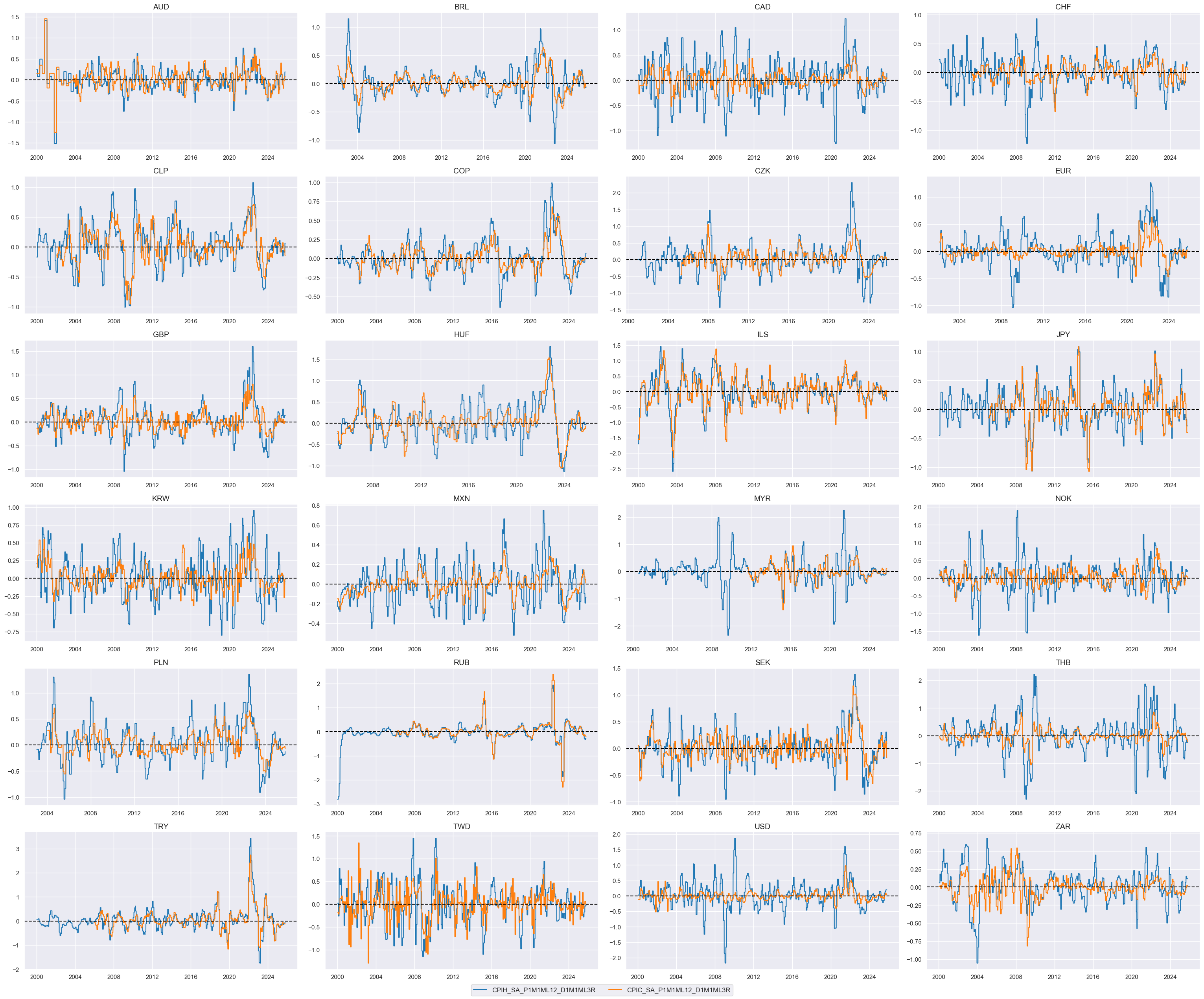
dict_rets = {
"DU05YXR_NSA": "Simple 5-year IRS returns",
"DU05YXR_VT10": "Vol-targeted 5-year IRS returns",
"DU05YXR_NSAR": "Relative simple 5-year IRS returns",
"DU05YXR_VT10R": "Relative vol-targeted 5-year IRS returns",
}
dict_labs = dict_facts | dict_rets
cidx = cids_dux
xcatx = ["DU05YXR_VT10", "DU05YXR_VT10R"]
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
cumsum=True,
ncol=4,
start="2000-01-01",
title_fontsize=28,
size=(10, 6),
aspect=1.8,
height=2,
same_y=False,
title="Cumulative vol-targeted 5-year IRS fixed receiver returns, absolute and relative (flat periods are blacklisted)",
blacklist=fxblack,
xcat_labels=dict_labs,
all_xticks=True,
legend_fontsize=16,
)
cidx = cids_dux
xcatx = ["DU05YXR_VT10R", "DU05YXR_NSAR"]
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
cumsum=True,
ncol=4,
start="2000-01-01",
title_fontsize=28,
size=(10, 6),
aspect=1.8,
height=2,
same_y=False,
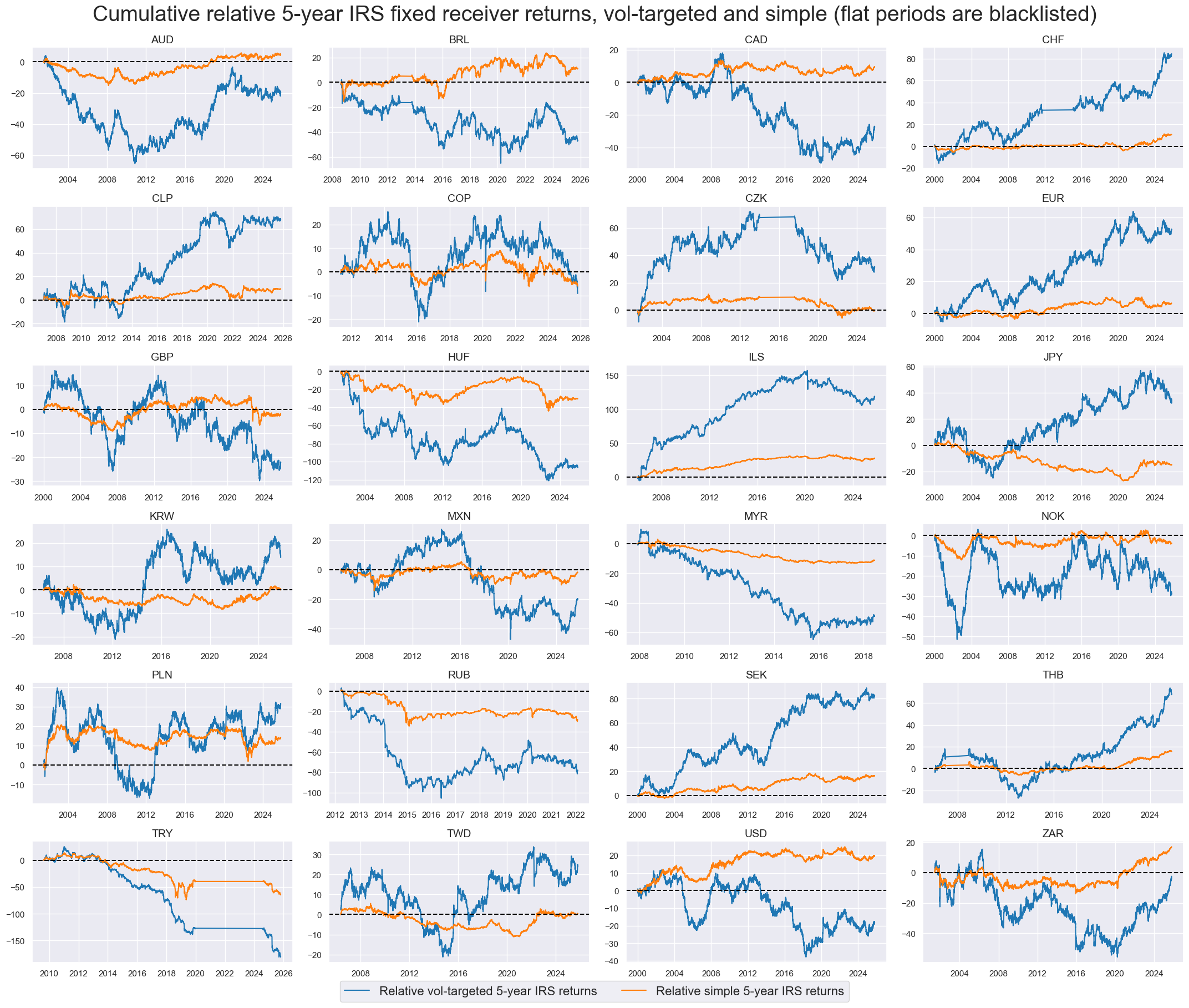
title="Cumulative relative 5-year IRS fixed receiver returns, vol-targeted and simple (flat periods are blacklisted)",
blacklist=fxblack,
xcat_labels=dict_labs,
all_xticks=True,
legend_fontsize=16,
)
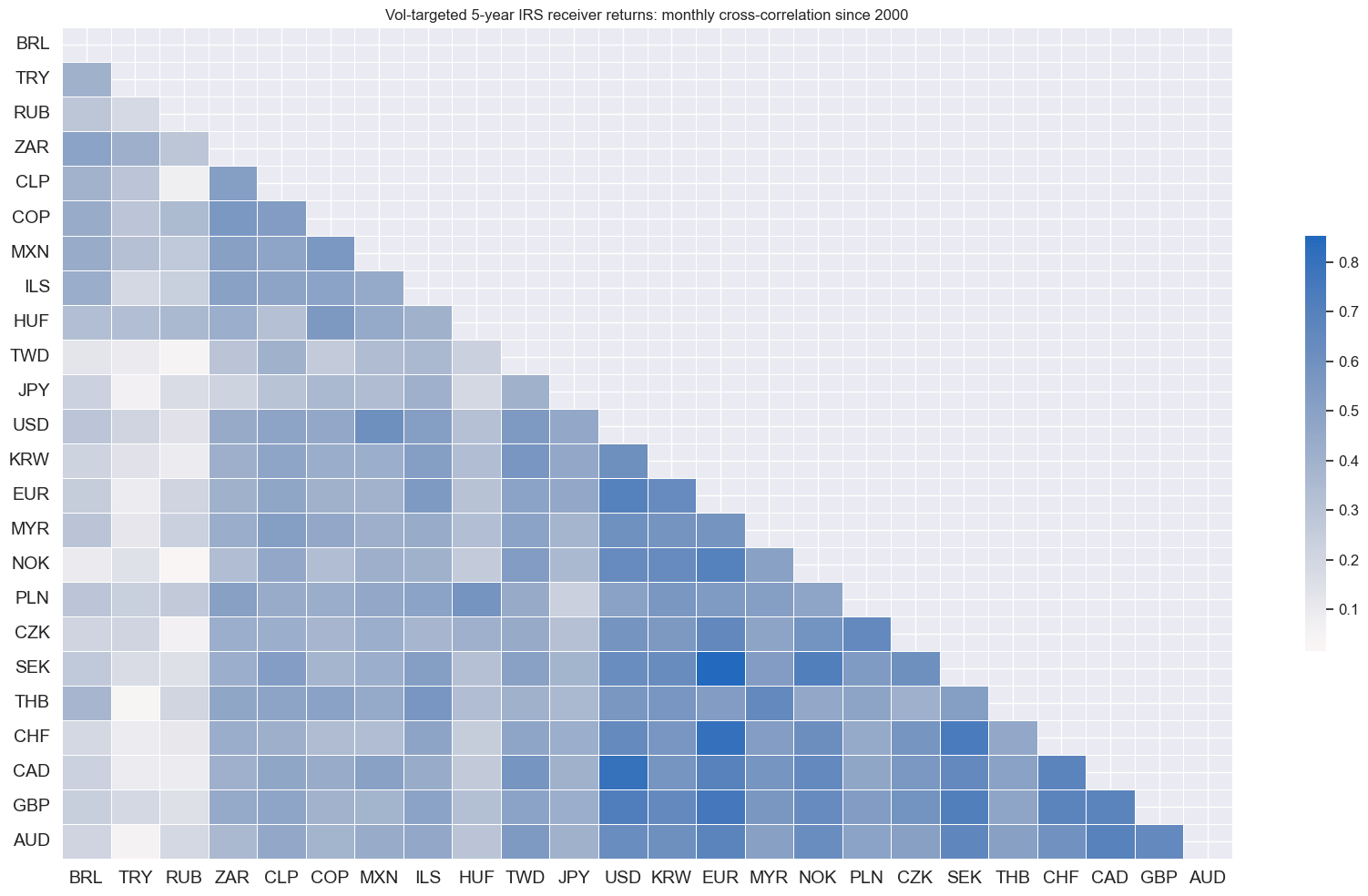
cidx = cids_dux
msp.correl_matrix(
dfx,
xcats="DU05YXR_VT10",
cids=cidx,
freq="M",
title="Vol-targeted 5-year IRS receiver returns: monthly cross-correlation since 2000",
size=(17, 10),
cluster=True,
)
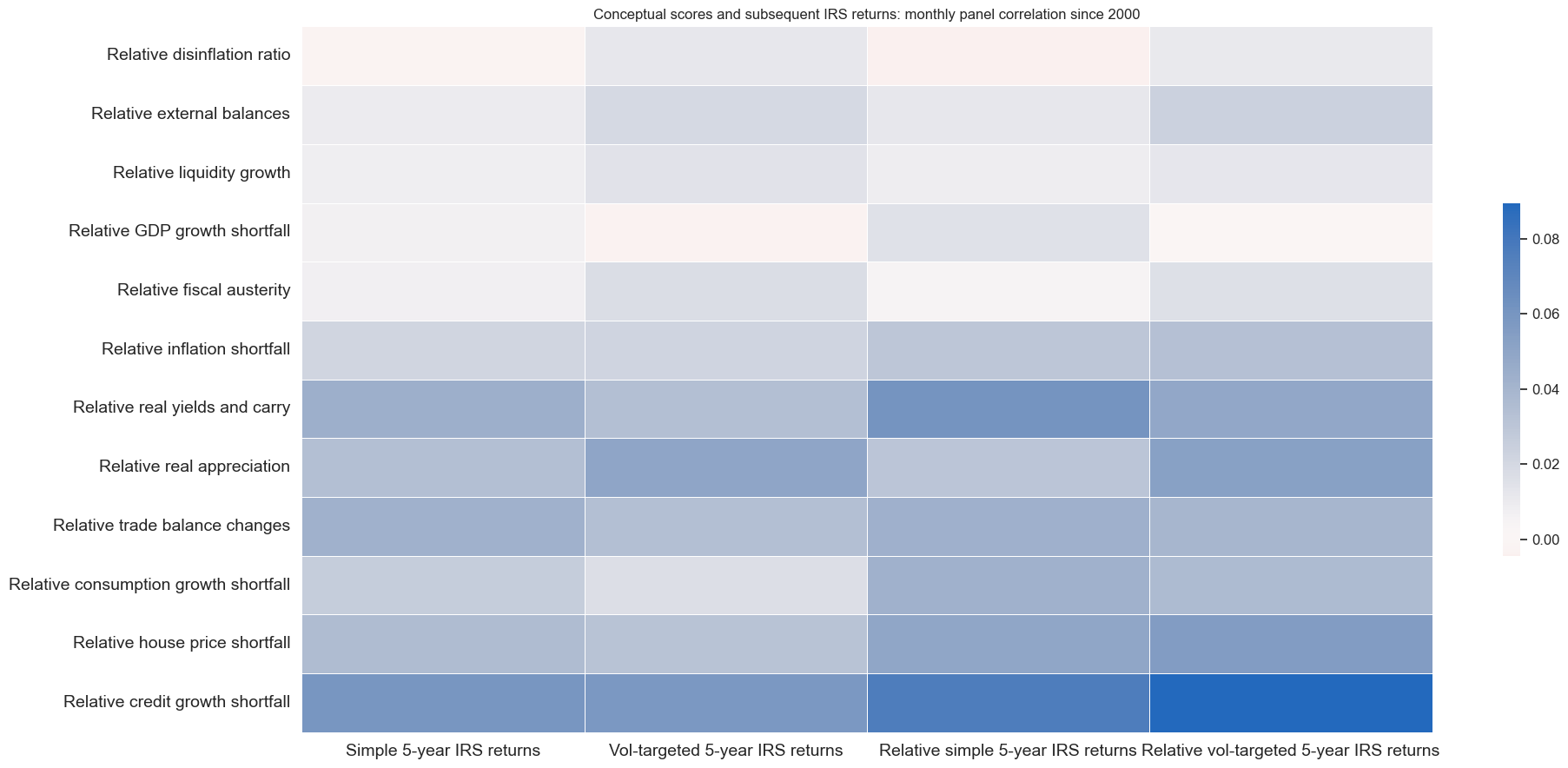
cidx = cids_dux
xcatx = [k for k in dict_rets.keys()]
xcatx2 = factorz
msp.correl_matrix(
dfx,
xcats=xcatx,
cids=cidx,
xcats_secondary=xcatx2,
lags_secondary={k:1 for k in xcatx2},
freq="M",
title="Conceptual scores and subsequent IRS returns: monthly panel correlation since 2000",
size=(20, 9),
cluster=True,
xcat_labels=dict_rets,
xcat_secondary_labels=dict_facts,
)
Signal generation #
Regularized (Ridge) regression #
so = msl.SignalOptimizer(
df=dfx,
cids=cids_dux,
xcats=factorz + ["DU05YXR_VT10R"],
xcat_aggs=["last", "sum"],
lag=1,
blacklist=fxblack,
freq="M",
start="2000-01-01",
)
so.calculate_predictions(
name="Ridge",
models={
"Ridge": Ridge(positive=True, fit_intercept=False, random_state=42),
},
hyperparameters={
"Ridge": {
"alpha": [1, 10, 100, 1000, 10000],
},
},
scorers={
"SHARPE": make_scorer(msl.sharpe_ratio, greater_is_better=True),
},
inner_splitters={
"Expanding": msl.ExpandingKFoldPanelSplit(n_splits=5),
},
cv_summary="mean-std",
test_size=1,
)
dfa = so.get_optimized_signals("Ridge")
dfx = msm.update_df(dfx, dfa)
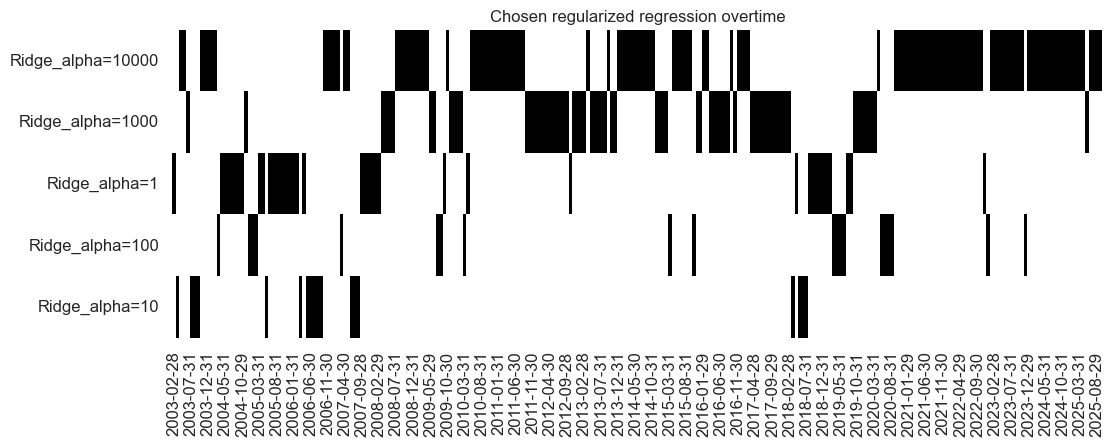
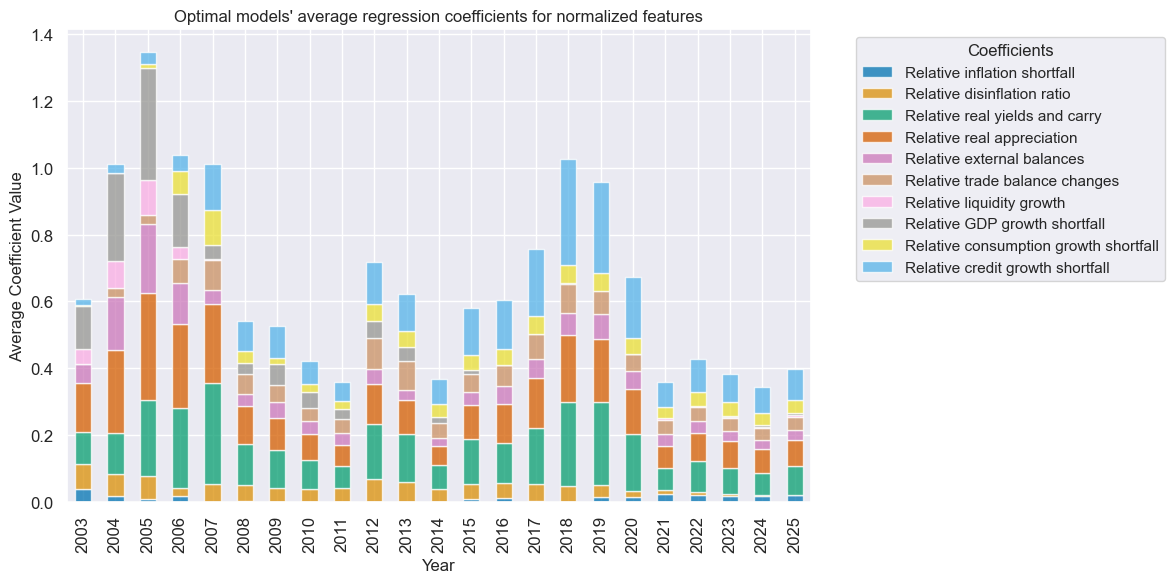
The first 5 yeras are dominated a model close to an OLS linear regression. As more time progresses, greater regularization is imposed.
alpha=1000
dominated the 2010s whilst
alpha=10000
has dominated the 2020s. There is some instability in the middle years of the process, highlighting difficulties in finding a regularization hyperparameter to optimize Sharpe. A residual-based metric will lead to a more stable model selection.
so.models_heatmap(
"Ridge",
title="Chosen regularized regression overtime",
figsize=(12, 4),
)
dict_facts1 = {
"XINFLvGLB_NEG_ZN": "Relative inflation shortfall",
"INFLCHGRvGLB_NEG_ZN": "Relative disinflation ratio",
"RRCRvGLB_ZN": "Relative real yields and carry",
"REEROACHGvGLB_ZN": "Relative real appreciation",
"XBALvGLB_ZN": "Relative external balances",
"MTBCHGvGLB_ZN": "Relative trade balance changes",
"LIQCHGvGLB_ZN": "Relative liquidity growth",
"RGDPGROWTHvGLB_NEG_ZN": "Relative GDP growth shortfall",
"PCONSGROWTHvGLB_NEG_ZN": "Relative consumption growth shortfall",
"PCREDITGROWTHvGLB_NEG_ZN": "Relative credit growth shortfall",
"XHPIvGLB_NEG_ZN": "Relative house price shortfall",
"AUSTERITYvGLB_ZN": "Relative fiscal austerity",
}
so.coefs_stackedbarplot(
"Ridge",
title="Optimal models' average regression coefficients for normalized features",
ftrs_renamed=dict_facts1,
figsize=(12, 6),
)
Random forest regression #
so.calculate_predictions(
name="RF",
models={
"RF_DEEP": RandomForestRegressor(
random_state=42,
max_samples=None,
n_estimators=100,
monotonic_cst=[1 for i in factorz],
),
"RF_SHALLOW": RandomForestRegressor(
random_state=42,
max_samples=0.1,
n_estimators=100,
monotonic_cst=[1 for i in factorz],
),
},
hyperparameters={
"RF_DEEP": {
"min_samples_leaf": [12, 36, 60],
"max_features": [0.3, None],
"max_samples": [None, 0.5]
},
"RF_SHALLOW": {
"min_samples_leaf": [1, 6],
"max_features": [0.3, None],
"max_samples": [0.1, 0.25]
},
},
scorers={
"SHARPE": make_scorer(msl.sharpe_ratio, greater_is_better=True),
},
inner_splitters={
"Expanding": msl.ExpandingKFoldPanelSplit(n_splits=5),
},
cv_summary="mean-std",
test_size=1,
)
dfa = so.get_optimized_signals("RF")
dfx = msm.update_df(dfx, dfa)
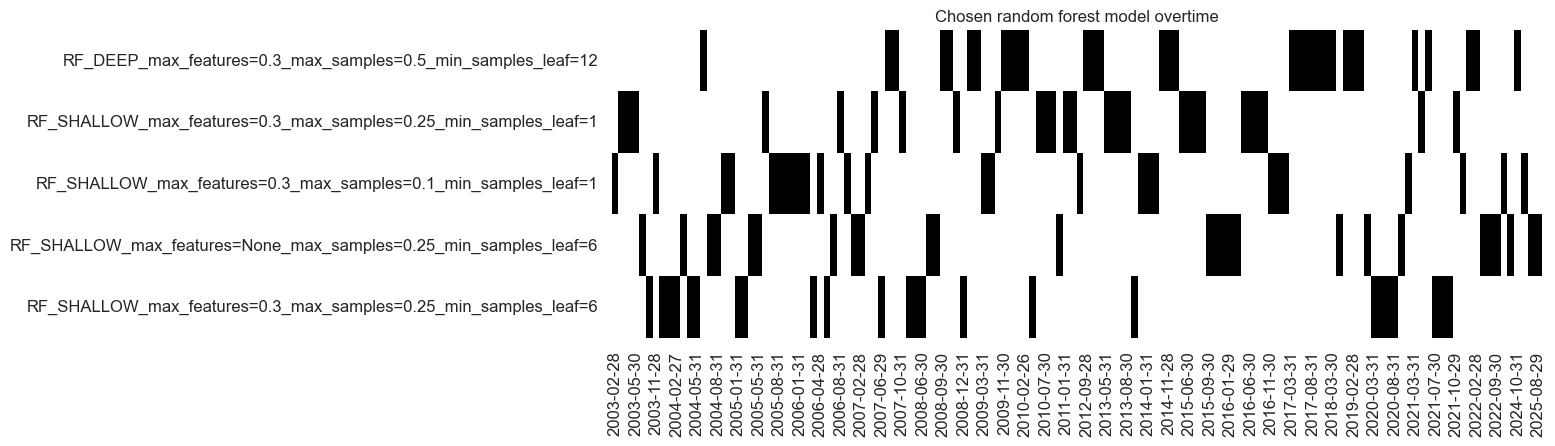
so.models_heatmap(
"RF",
title="Chosen random forest model overtime",
figsize=(12, 4),
)
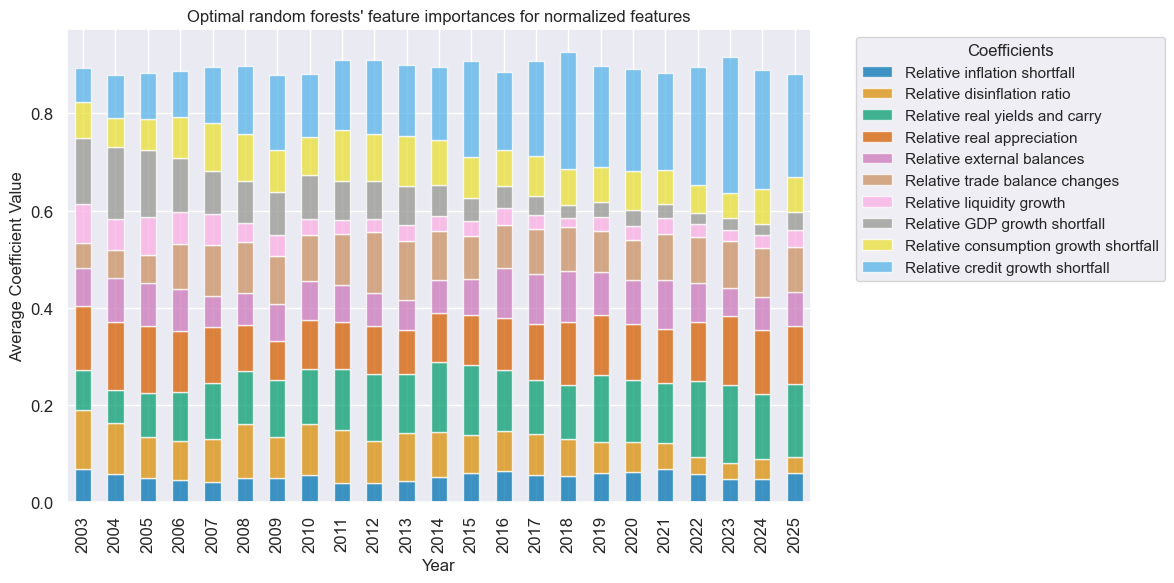
so.coefs_stackedbarplot(
"RF",
title="Optimal random forests' feature importances for normalized features",
ftrs_renamed=dict_facts,
figsize=(12, 6),
)
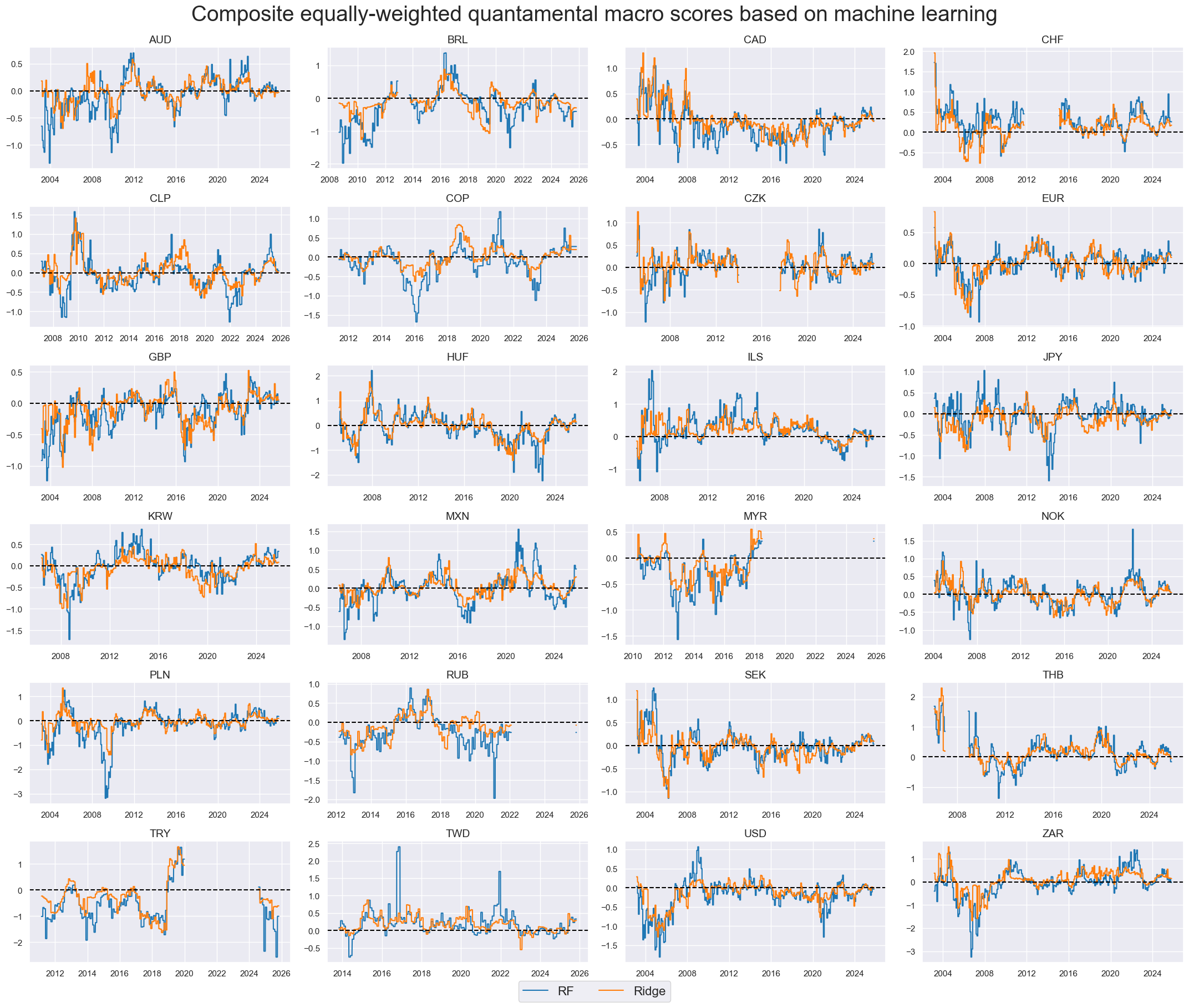
xcatx = ["RF", "Ridge"]
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
cumsum=False,
ncol=4,
start="2000-01-01",
title_fontsize=28,
size=(10, 6),
aspect=1.8,
height=2,
same_y=False,
title="Composite equally-weighted quantamental macro scores based on machine learning",
#blacklist=fxblack,
all_xticks=True,
legend_fontsize=16,
)
Signal value checks #
Accuracy and correlation check #
srr = mss.SignalReturnRelations(
df = dfx,
rets = ["DU05YXR_VT10R"],
sigs = ["RF", "Ridge", "MACRO_AVGZ"],
cids = cids_dux,
blacklist = fxblack,
freqs = "M",
slip = 1,
cosp = True,
ms_panel_test = True
)
srr.multiple_relations_table().round(3)
| accuracy | bal_accuracy | pos_sigr | pos_retr | pos_prec | neg_prec | pearson | pearson_pval | kendall | kendall_pval | auc | map_pval | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Return | Signal | Frequency | Aggregation | ||||||||||||
| DU05YXR_VT10R | MACRO_AVGZ | M | last | 0.539 | 0.540 | 0.472 | 0.516 | 0.559 | 0.522 | 0.099 | 0.0 | 0.068 | 0.0 | 0.540 | 0.0 |
| RF | M | last | 0.536 | 0.537 | 0.473 | 0.516 | 0.555 | 0.519 | 0.100 | 0.0 | 0.073 | 0.0 | 0.537 | 0.0 | |
| Ridge | M | last | 0.542 | 0.542 | 0.496 | 0.516 | 0.559 | 0.526 | 0.104 | 0.0 | 0.071 | 0.0 | 0.542 | 0.0 |
Naive PnL #
xcatx = ["MACRO_AVGZ", "RF", "Ridge"]
pnl = msn.NaivePnL(
df=dfx,
ret="DU05YXR_VT10R",
sigs=xcatx,
cids=cids_dux,
blacklist=fxblack,
start="2004-01-01",
bms=["USD_GB10YXR_NSA"],
)
for xcat in xcatx:
pnl.make_pnl(
sig=xcat,
sig_op="zn_score_pan",
rebal_freq="monthly",
rebal_slip=1,
vol_scale=10,
neutral="zero",
thresh=3,
)
dict_pnl_labs = {
"PNL_MACRO_AVGZ": "Conceptual parity composite macro score",
"PNL_RF": "Random forest-based learning signal",
"PNL_Ridge": "Ridge regression-based learning signal",
}
pnl.plot_pnls(
title="Cumulative PnL of cross-country 5-year IRS positions (10% annualized volatility)",
title_fontsize=16,
figsize=(14, 8),
xcat_labels=dict_pnl_labs,
)
pnl.signal_heatmap(
pnl_name="PNL_Ridge",
title="Traded ridge-based learning signals, quarterly averages",
freq="Q",
start="2004-01-01",
figsize=(12, 6),
)
pnl.signal_heatmap(
pnl_name="PNL_Ridge",
title="Snapshot of standard ridge-based learning signals",
freq="M",
start="2024-01-01",
figsize=(16, 6),
)
pnl.evaluate_pnls(pnl_cats=pnl.pnl_names)
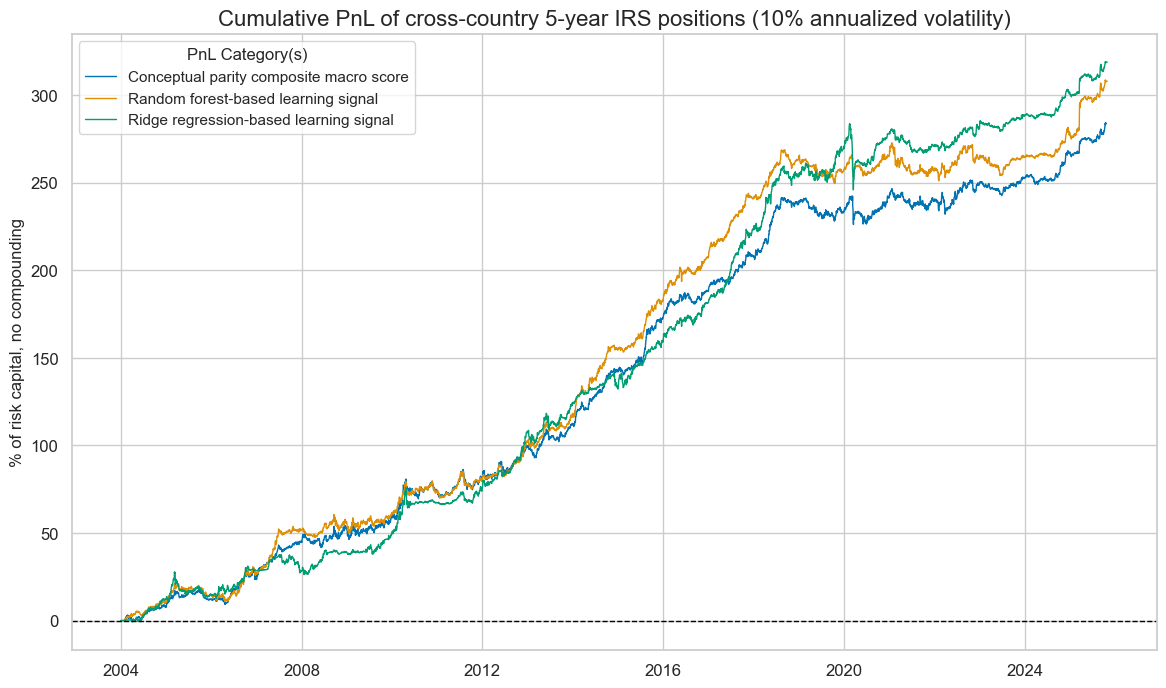
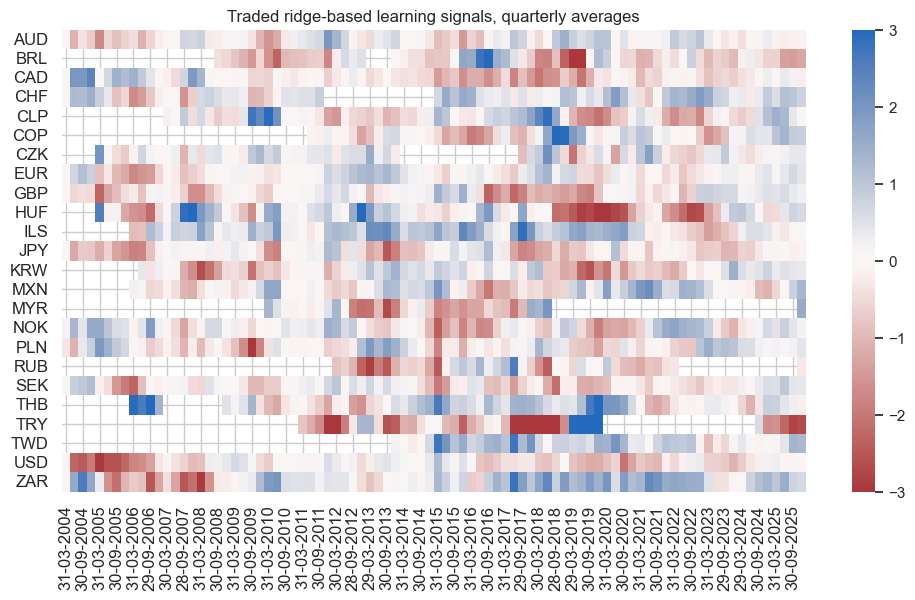
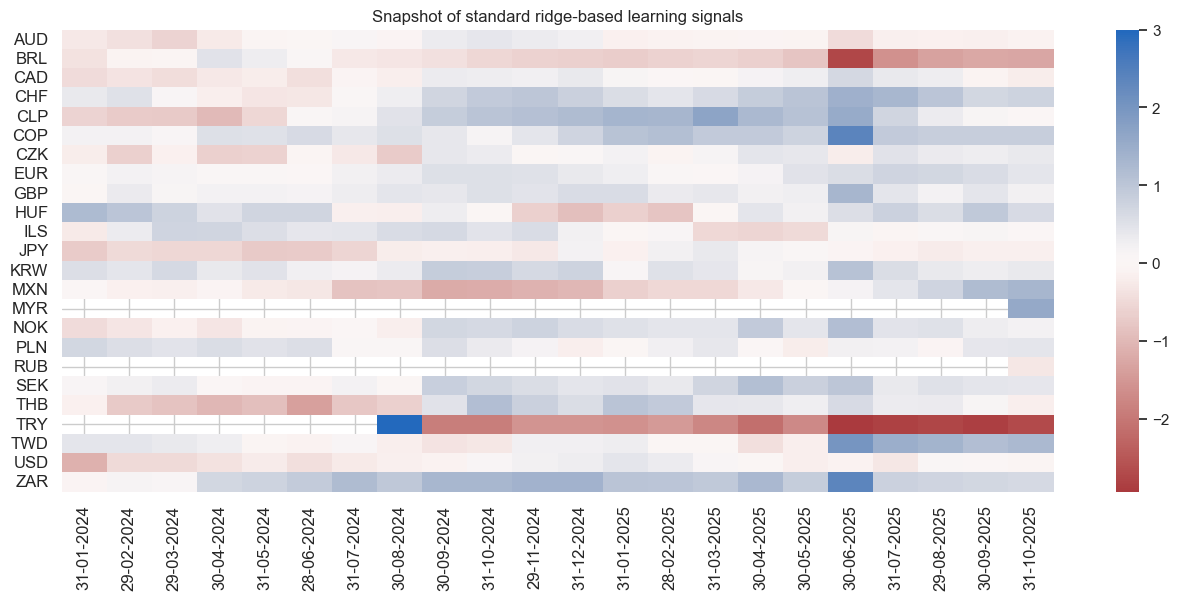
| xcat | PNL_MACRO_AVGZ | PNL_RF | PNL_Ridge |
|---|---|---|---|
| Return % | 13.02969 | 14.110828 | 14.613863 |
| St. Dev. % | 10.0 | 10.0 | 10.0 |
| Sharpe Ratio | 1.302969 | 1.411083 | 1.461386 |
| Sortino Ratio | 1.933513 | 2.110505 | 2.14532 |
| Max 21-Day Draw % | -15.374353 | -12.727549 | -37.076849 |
| Max 6-Month Draw % | -12.073497 | -17.586084 | -19.313699 |
| Peak to Trough Draw % | -16.165687 | -21.674408 | -37.767905 |
| Top 5% Monthly PnL Share | 0.367345 | 0.363474 | 0.357058 |
| USD_GB10YXR_NSA correl | 0.055675 | 0.074601 | -0.013329 |
| Traded Months | 262 | 262 | 262 |
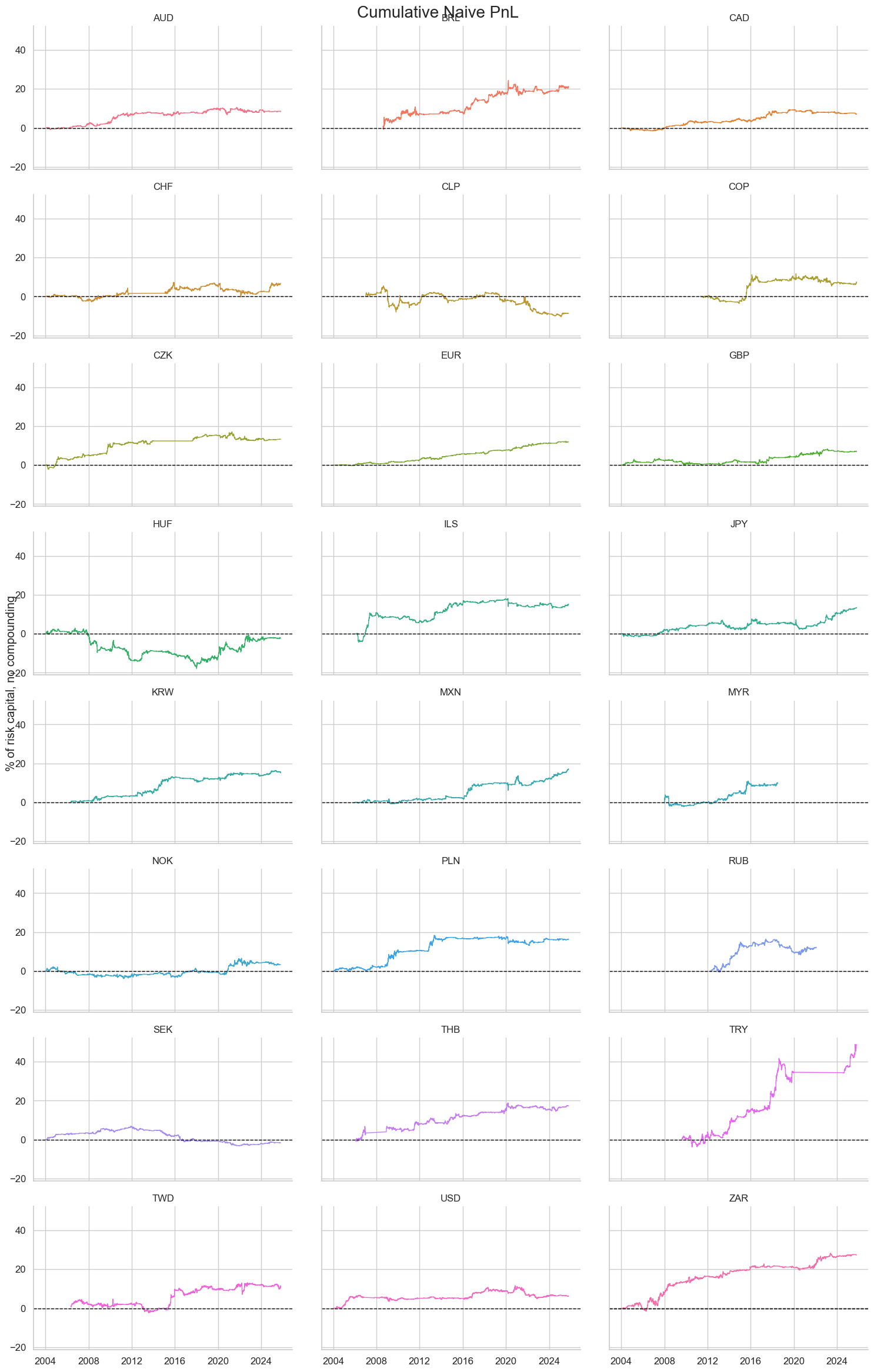
pnl.plot_pnls(pnl_cats=["PNL_MACRO_AVGZ"], pnl_cids=cids_dux, facet=True)
Transaction cost-friendly Naive PnL #
# Transaction cost-friendly strategy
xcatx = ["MACRO_AVGZ", "RF", "Ridge"]
pnl = msn.NaivePnL(
df=dfx,
ret="DU05YXR_VT10R",
sigs=xcatx,
cids=cids_dux,
blacklist=fxblack,
start="2004-01-01",
bms=["USD_GB10YXR_NSA"],
)
for xcat in xcatx:
pnl.make_pnl(
sig=xcat,
sig_op="binary",
rebal_freq="monthly",
rebal_slip=1,
vol_scale=10,
neutral="zero",
thresh=3,
entry_barrier=1,
exit_barrier=0.01,
)
pnl.plot_pnls(
title="Transaction cost-friendly PnL of cross-country 5-year IRS positions (10% annualized volatility)",
title_fontsize=16,
figsize=(14, 8),
xcat_labels=dict_pnl_labs,
)
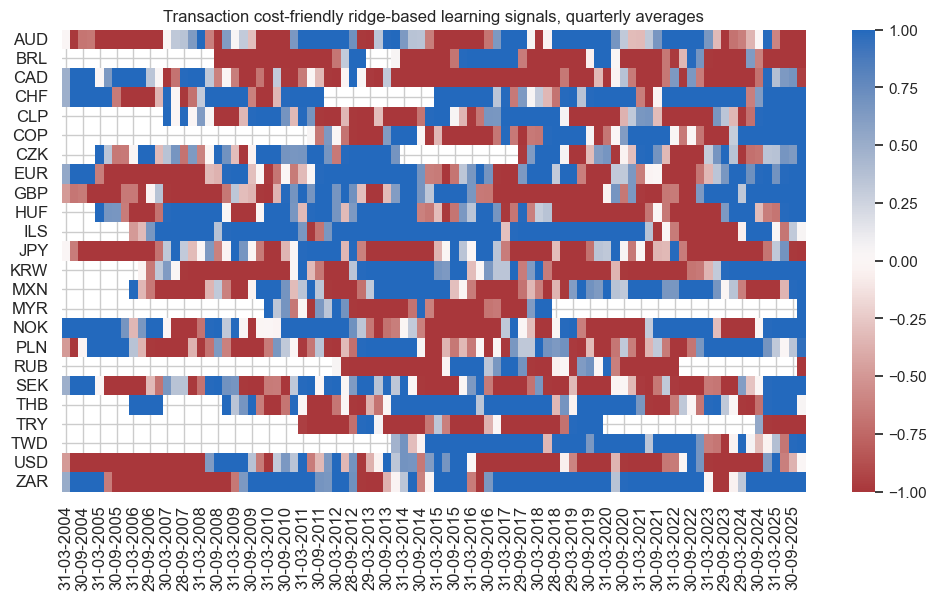
pnl.signal_heatmap(
pnl_name="PNL_Ridge",
title="Transaction cost-friendly ridge-based learning signals, quarterly averages",
freq="Q",
start="2004-01-01",
figsize=(12, 6),
)
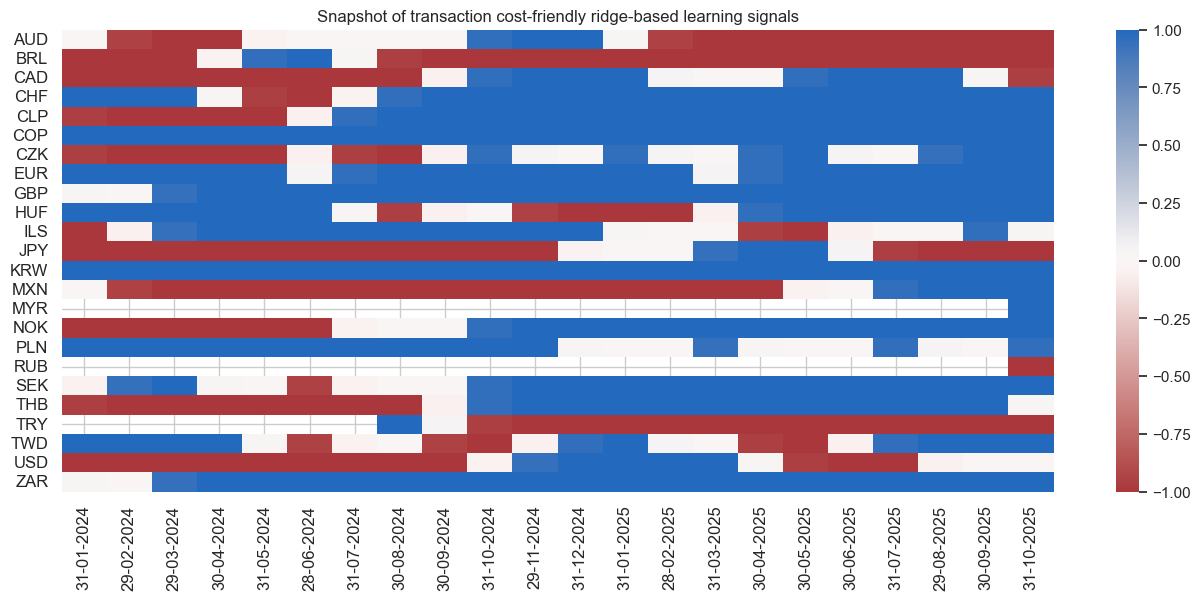
pnl.signal_heatmap(
pnl_name="PNL_Ridge",
title="Snapshot of transaction cost-friendly ridge-based learning signals",
freq="M",
start="2024-01-01",
figsize=(16, 6),
)
pnl.evaluate_pnls(pnl_cats=pnl.pnl_names)
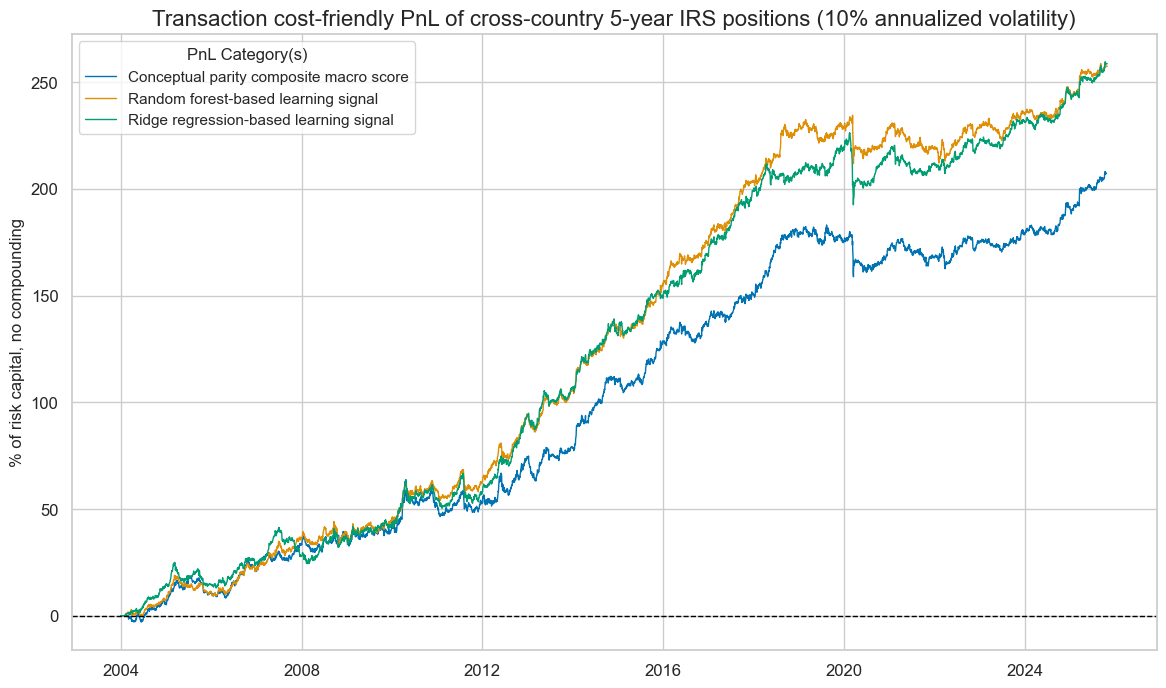
| xcat | PNL_MACRO_AVGZ | PNL_RF | PNL_Ridge |
|---|---|---|---|
| Return % | 9.508542 | 11.835772 | 11.847645 |
| St. Dev. % | 10.0 | 10.0 | 10.0 |
| Sharpe Ratio | 0.950854 | 1.183577 | 1.184764 |
| Sortino Ratio | 1.384235 | 1.716192 | 1.71296 |
| Max 21-Day Draw % | -20.672086 | -21.357749 | -33.334513 |
| Max 6-Month Draw % | -21.220375 | -16.44629 | -22.215746 |
| Peak to Trough Draw % | -24.248707 | -22.650229 | -33.693642 |
| Top 5% Monthly PnL Share | 0.489614 | 0.396567 | 0.373884 |
| USD_GB10YXR_NSA correl | 0.015106 | 0.011364 | -0.012643 |
| Traded Months | 262 | 262 | 262 |