Manufacturing confidence score surprises #
This category group contains economic surprise indicators related to manufacturing business confidence . At present it contains only broad manufacturing confidence scores. Economic surprises are deviations of point-in-time quantamental indicators from predicted values. For an in-depth explanation, please read Appendix 2 .
Manufacturing score surprises #
Ticker : MBCSCORE_SA_ARMAS / _3MMA_ARMAS
Label : Manufacturing confidence score, ARMA(1,1)-based surprises: z-score, sa / z-score, sa, 3mma
Definition : Manufacturing confidence score, ARMA(1,1)-based surprises: seasonally adjusted / seasonally adjusted , 3-month moving average
Notes :
-
Refer to the section on manufacturing confidence scores for notes on the underlying data series.
-
Expected values for release dates are based on an “ARMA(1,1)” model. This is a simple univariate time series model that predicts increments based on an autoregressive component, i.e., last period’s value, and a moving average component, represented by last period’s error. The coefficients of the model are estimated sequentially based on the vintages of production indices. And each vintage-specific model produces a one-step-ahead forecast for the subsequent observation period.
Ticker : MBCSCORE_SA_D1M1ML1_ARMAS / _D3M3ML3_ARMAS / _D1Q1QL1_ARMAS / _D6M6ML6_ARMAS / _D2Q2QL2_ARMAS / _D1M1ML12_ARMAS / _3MMA_D1M1ML12_ARMAS / _D1Q1QL4_ARMAS
Label : Manufacturing confidence change, sa, ARMA(1,1)-based surprises: diff m/m / diff 3m/3m / diff q/q / diff 6m/6m / diff 2q/2q / diff oya (m) / diff oya, 3mma / diff oya (q)
Definition : Manufacturing confidence change, seasonally adjusted, ARMA(1,1)-based surprises: difference over 1 month / difference of last 3 months over previous 3 months / difference of last quarter over previous quarter / difference of last 6 months over previous 6 months / difference of last 2 quarters over previous 2 quarters / difference over a year ago, monthly values / difference over a year ago, 3-month moving average / difference over a year ago, quarterly values
Notes :
-
Refer to the section on manufacturing confidence scores for notes on the underlying data series.
-
Expected values for release dates are based on an “ARMA(1,1)” model. This is a simple univariate time series model that predicts increments based on an autoregressive component, i.e., last period’s value, and a moving average component, represented by last period’s error. The coefficients of the model are estimated sequentially based on the vintages of production indices. And each vintage-specific model produces a one-step-ahead forecast for the subsequent observation period.
Imports #
Only the standard Python data science packages and the specialized
macrosynergy
package are needed.
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import math
import json
import yaml
import macrosynergy.management as msm
import macrosynergy.panel as msp
import macrosynergy.signal as mss
import macrosynergy.pnl as msn
import macrosynergy.visuals as msv
from macrosynergy.download import JPMaQSDownload
from timeit import default_timer as timer
from datetime import timedelta, date, datetime
import warnings
warnings.simplefilter("ignore")
The
JPMaQS
indicators we consider are downloaded using the J.P. Morgan Dataquery API interface within the
macrosynergy
package. This is done by specifying
ticker strings
, formed by appending an indicator category code
<category>
to a currency area code
<cross_section>
. These constitute the main part of a full quantamental indicator ticker, taking the form
DB(JPMAQS,<cross_section>_<category>,<info>)
, where
<info>
denotes the time series of information for the given cross-section and category.
The following types of information are available:
-
valuegiving the latest available values for the indicator -
eop_lagreferring to days elapsed since the end of the observation period -
mop_lagreferring to the number of days elapsed since the mean observation period -
gradedenoting a grade of the observation, giving a metric of real time information quality.
After instantiating the
JPMaQSDownload
class within the
macrosynergy.download
module, one can use the
download(tickers,
start_date,
metrics)
method to obtain the data. Here
tickers
is an array of ticker strings,
start_date
is the first release date to be considered and
metrics
denotes the types of information requested.
# Cross-sections of interest
cids_dmca = [
"AUD",
"CAD",
"CHF",
"EUR",
"GBP",
"JPY",
"NOK",
"NZD",
"SEK",
"USD",
] # DM currency areas
cids_dmec = ["DEM", "ESP", "FRF", "ITL", "NLG"] # DM euro area countries
cids_latm = ["BRL", "COP", "CLP", "MXN", "PEN"] # Latam countries
cids_emea = ["CZK", "HUF", "ILS", "PLN", "RON", "RUB", "TRY", "ZAR"] # EMEA countries
cids_emas = [
"CNY",
"HKD",
"IDR",
"INR",
"KRW",
"MYR",
"PHP",
"SGD",
# "THB",
"TWD",
] # EM Asia countries
cids_dm = cids_dmca + cids_dmec
cids_em = cids_latm + cids_emea + cids_emas
cids = sorted(cids_dm + cids_em)
# FX cross-sections lists (for research purposes)
cids_nofx = ["EUR", "USD", "SGD"] + cids_dmec
cids_fx = list(set(cids) - set(cids_nofx))
cids_dmfx = set(cids_dm).intersection(cids_fx)
cids_emfx = set(cids_em).intersection(cids_fx)
cids_eur = ["CHF", "CZK", "HUF", "NOK", "PLN", "RON", "SEK"] # trading against EUR
cids_eud = ["GBP", "RUB", "TRY"] # trading against EUR and USD
cids_usd = list(set(cids_fx) - set(cids_eur + cids_eud)) # trading against USD
# Quantamental categories of interest
main = [
# CONFIDENCE - Forecast and Revision Surprises
f"MBCSCORE_SA{transformation:s}_{model:s}"
for transformation in (
"",
"_3MMA",
"_D1M1ML1",
"_D3M3ML3",
"_D1Q1QL1",
"_D6M6ML6",
"_D2Q2QL2",
"_3MMA_D1M1ML12",
"_D1M1ML12",
"_D1Q1QL4",
)
for model in [
"ARMAS",
]
]
econ = ["IVAWGT_SA_1YMA", "IVAWGT_SA_3YMA"] # economic context
mark = [
"FXXR_NSA",
"FXXR_VT10",
"FXTARGETED_NSA",
"FXUNTRADABLE_NSA",
"DU02YXR_NSA", "DU05YXR_NSA", "DU10YXR_NSA", "DU02YXR_VT10", "DU05YXR_VT10", "DU10YXR_VT10"
] # market links
xcats = main + econ + mark
cids_co = [
"ALM",
"CPR",
"LED",
"NIC",
"TIN",
"ZNC",
]
xcats_co = ["COXR_NSA", "COXR_VT10"]
cotix = [cid + "_" + xcat for cid in cids_co for xcat in xcats_co]
# Download series from J.P. Morgan DataQuery by tickers
start_date = "1995-01-01"
tickers = [cid + "_" + xcat for cid in cids for xcat in xcats] + cotix
print(f"Maximum number of tickers is {len(tickers)}")
# Retrieve credentials
client_id: str = os.getenv("DQ_CLIENT_ID")
client_secret: str = os.getenv("DQ_CLIENT_SECRET")
# Download from DataQuery
with JPMaQSDownload(client_id=client_id, client_secret=client_secret) as downloader:
start = timer()
assert downloader.check_connection()
df = downloader.download(
tickers=tickers,
start_date=start_date,
show_progress=True,
metrics=["value", "eop_lag", "mop_lag", "grading"],
suppress_warning=True,
)
end = timer()
print("Download time from DQ: " + str(timedelta(seconds=end - start)))
dfd = df
Maximum number of tickers is 826
Downloading data from JPMaQS.
Timestamp UTC: 2025-04-10 10:51:26
Connection successful!
Requesting data: 100%|██████████| 166/166 [00:34<00:00, 4.87it/s]
Downloading data: 100%|██████████| 166/166 [00:55<00:00, 2.97it/s]
Some expressions are missing from the downloaded data. Check logger output for complete list.
828 out of 3304 expressions are missing. To download the catalogue of all available expressions and filter the unavailable expressions, set `get_catalogue=True` in the call to `JPMaQSDownload.download()`.
Download time from DQ: 0:01:40.838823
Availability #
xcatx = main
cidx = cids
msm.check_availability(
df,
xcats=xcatx,
cids=cidx,
missing_recent=False,
)
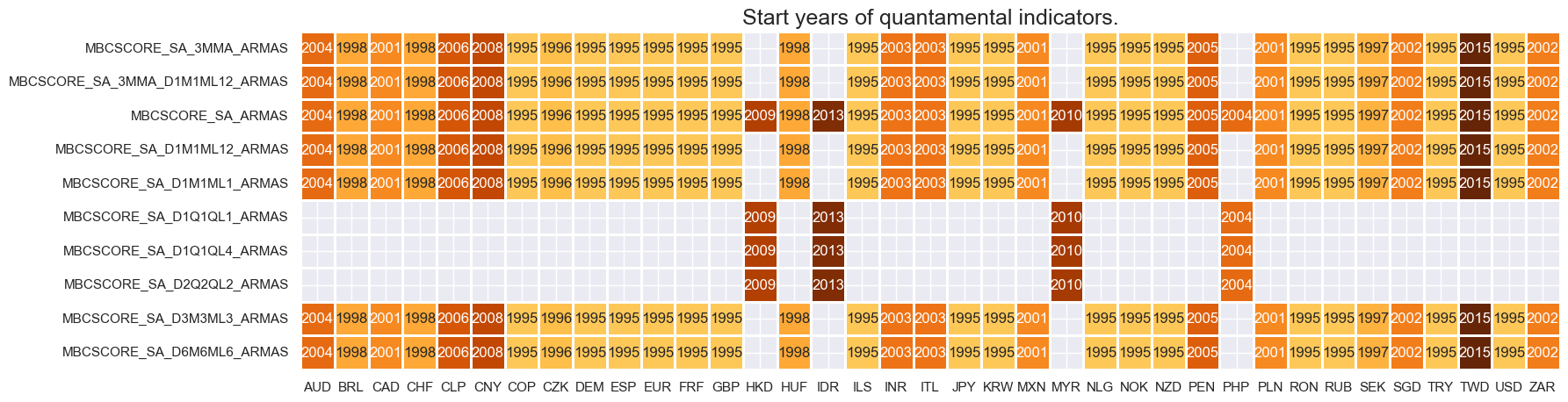
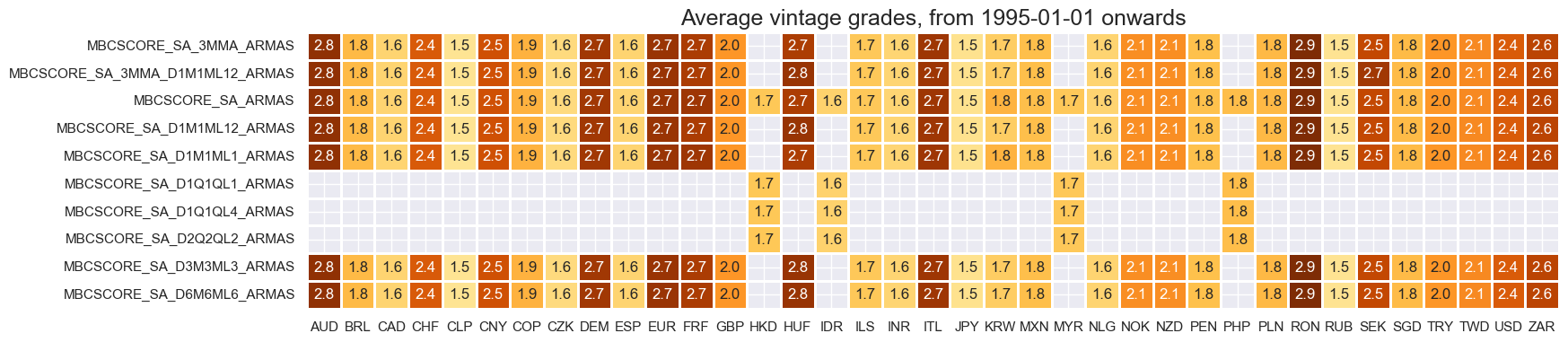
xcatx = main
cidx = cids
plot = msp.heatmap_grades(
dfd,
xcats=xcatx,
cids=cidx,
start=start_date,
size=(18, 4),
title=f"Average vintage grades, from {start_date} onwards",
)
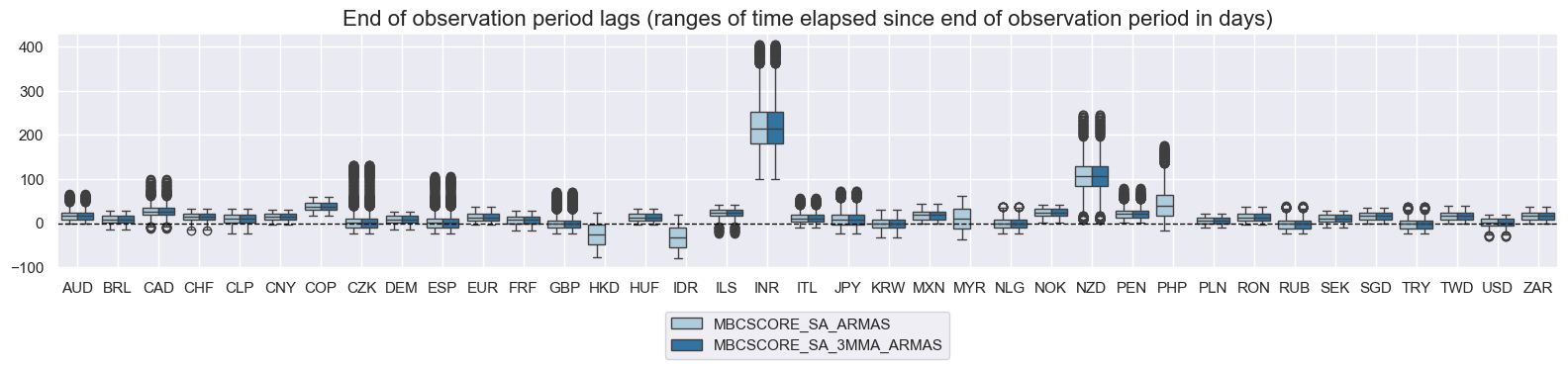
xcatx = main[:2]
cidx = cids
msp.view_ranges(
dfd,
xcats=xcatx,
cids=cidx,
val="eop_lag",
title="End of observation period lags (ranges of time elapsed since end of observation period in days)",
start="2000-01-01",
kind="box",
size=(16, 4),
)
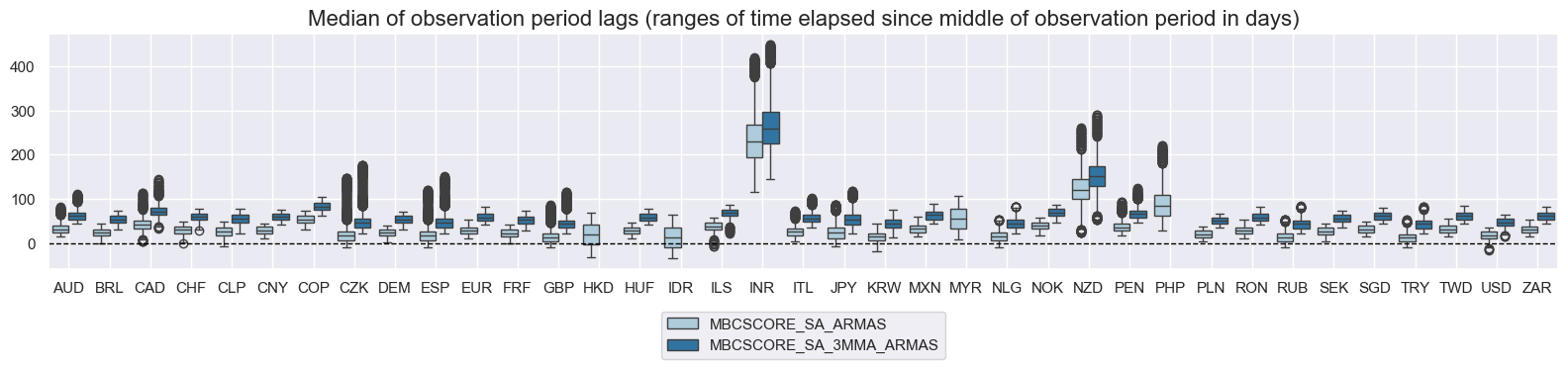
msp.view_ranges(
dfd,
xcats=xcatx,
cids=cidx,
val="mop_lag",
title="Median of observation period lags (ranges of time elapsed since middle of observation period in days)",
start="2000-01-01",
kind="box",
size=(16, 4),
)
For graphical representation, it is helpful to rename some quarterly dynamics into an equivalent monthly dynamics.
dfx = dfd.copy()
dict_repl = {
"MBCSCORE_SA_D1Q1QL1_ARMAS": "MBCSCORE_SA_D3M3ML3_ARMAS",
"MBCSCORE_SA_D2Q2QL2_ARMAS": "MBCSCORE_SA_D6M6ML6_ARMAS",
"MBCSCORE_SA_D1Q1QL4_ARMAS": "MBCSCORE_SA_3MMA_D1M1ML12_ARMAS",
"MBOSCORE_SA_D1Q1QL1_ARMAS": "MBOSCORE_SA_D3M3ML3_ARMAS",
"MBOSCORE_SA_D2Q2QL2_ARMAS": "MBOSCORE_SA_D6M6ML6_ARMAS",
"MBOSCORE_SA_D1Q1QL4_ARMAS": "MBOSCORE_SA_3MMA_D1M1ML12_ARMAS",
"MBISCORE_SA_D1Q1QL1_ARMAS": "MBISCORE_SA_D3M3ML3_ARMAS",
"MBISCORE_SA_D2Q2QL2_ARMAS": "MBISCORE_SA_D6M6ML6_ARMAS",
"MBISCORE_SA_D1Q1QL4_ARMAS": "MBISCORE_SA_3MMA_D1M1ML12_ARMAS",
}
for key, value in dict_repl.items():
dfx["xcat"] = dfx["xcat"].str.replace(key, value)
History #
Manufacturing score surprises #
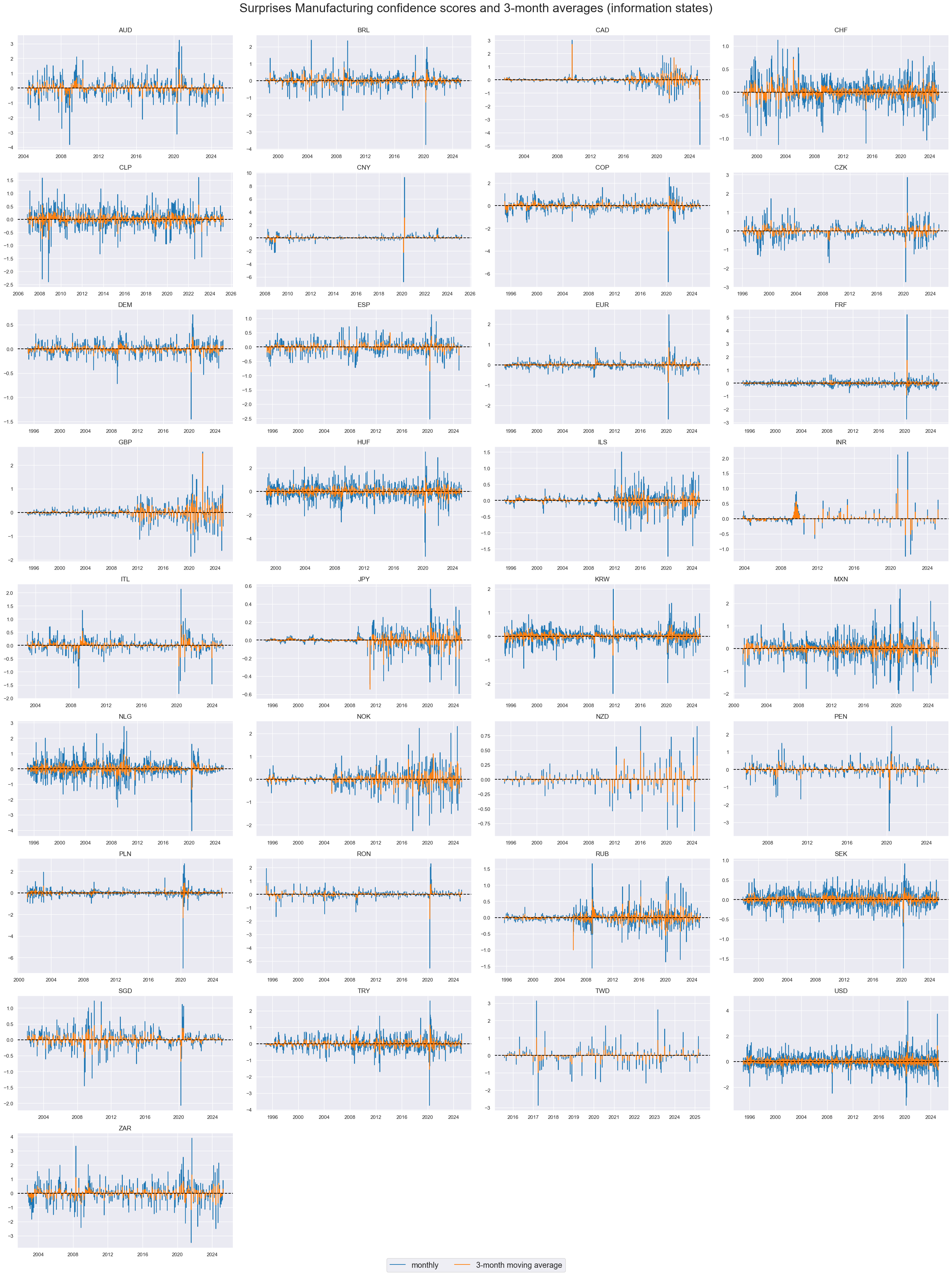
Surprises of survey changes are naturally far more variable than survey levels of even survey changes. Some countries, i.e., Canada, UK, Israel, Japan and Russia display structural breaks in surprise variance. These breaks are due changes in data frequency or grading of the underlying vintages.
cidx = sorted(list(
set(cids) - set(["HKD", "IDR", "MYR", "PHP"])
)) # exclude countries with quarterly surveys
xcatx = ["MBCSCORE_SA_ARMAS", "MBCSCORE_SA_3MMA_ARMAS"]
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
start=start_date,
title="Surprises Manufacturing confidence scores and 3-month averages (information states)",
xcat_labels=[
"monthly",
"3-month moving average",
],
ncol=4,
same_y=False,
legend_fontsize=17,
title_fontsize=27,
size=(12, 7),
aspect=1.7,
all_xticks=True,
legend_ncol=2,
label_adj=0.05,
)
cidx = sorted(
list(set(cids) - set(["HKD", "IDR", "MYR", "PHP"]))
) # exclude countries with quarterly surveys
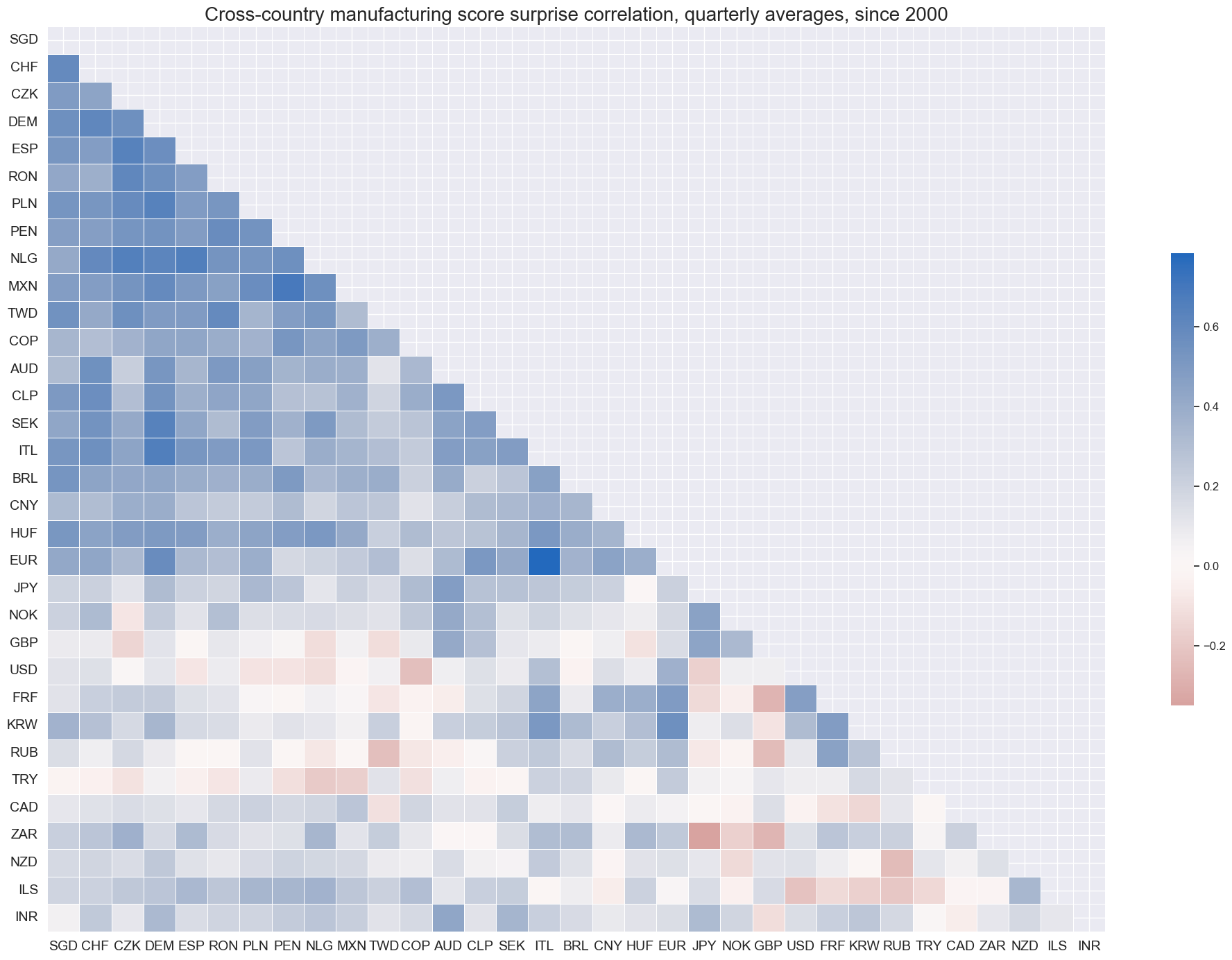
msp.correl_matrix(
dfx,
xcats="MBCSCORE_SA_ARMAS",
cids=cidx,
freq="q",
title="Cross-country manufacturing score surprise correlation, quarterly averages, since 2000",
cluster=True,
size=(20, 14),
)
xcatx = ["MBCSCORE_SA_D3M3ML3_ARMAS", "MBCSCORE_SA_D6M6ML6_ARMAS"]
cidx = cids
msp.view_timelines(
dfx,
xcats=xcatx,
cids=cidx,
start=start_date,
title="Manufacturing confidence score change surprises",
xcat_labels=[
"diff 3m/3m, sa, ARMA(1,1)",
"diff 6m/6m, sa, ARMA(1,1)",
],
legend_fontsize=15,
title_fontsize=27,
ncol=4,
same_y=False,
size=(12, 7),
aspect=1.7,
all_xticks=True,
legend_ncol=2,
label_adj=0.05,
)
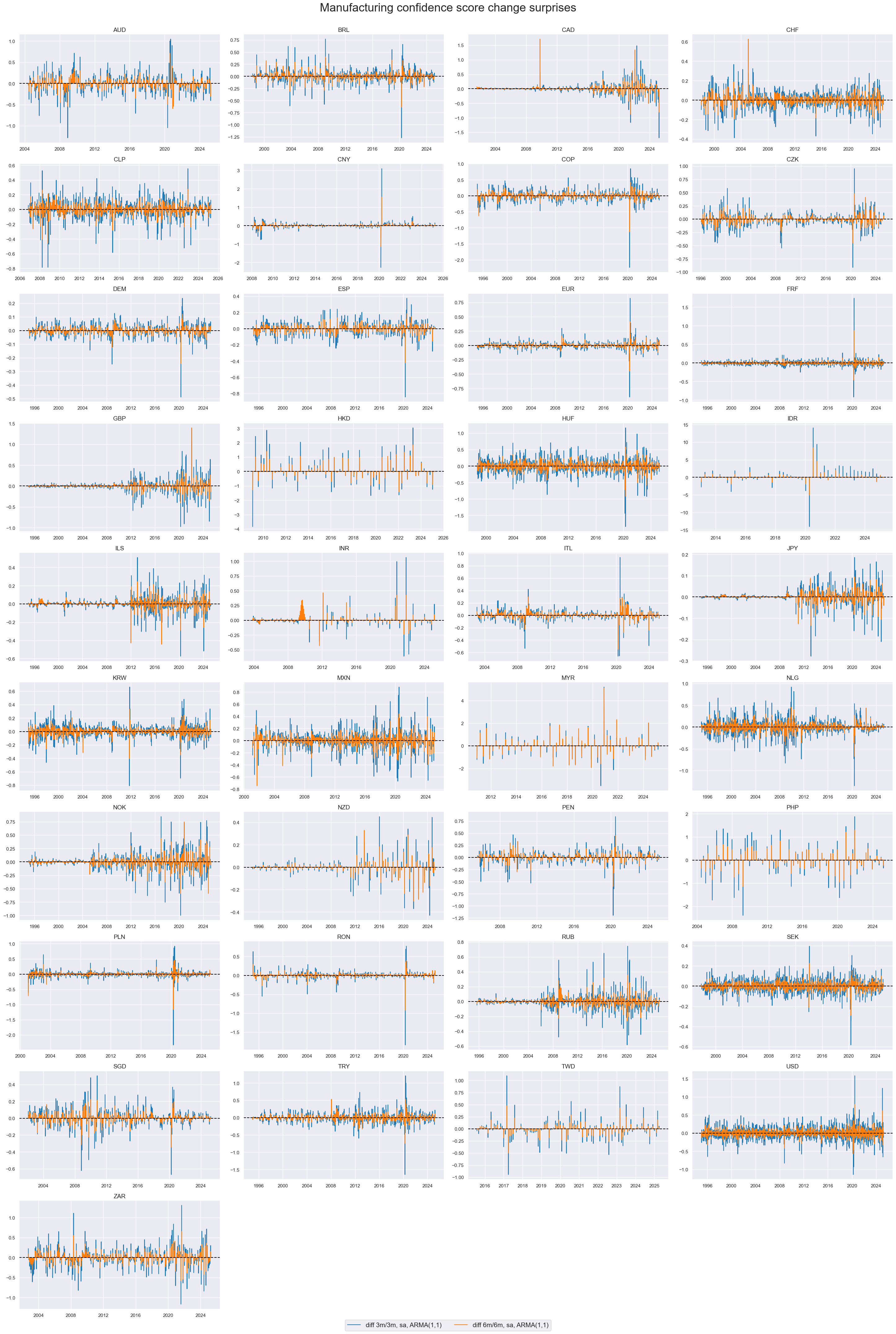
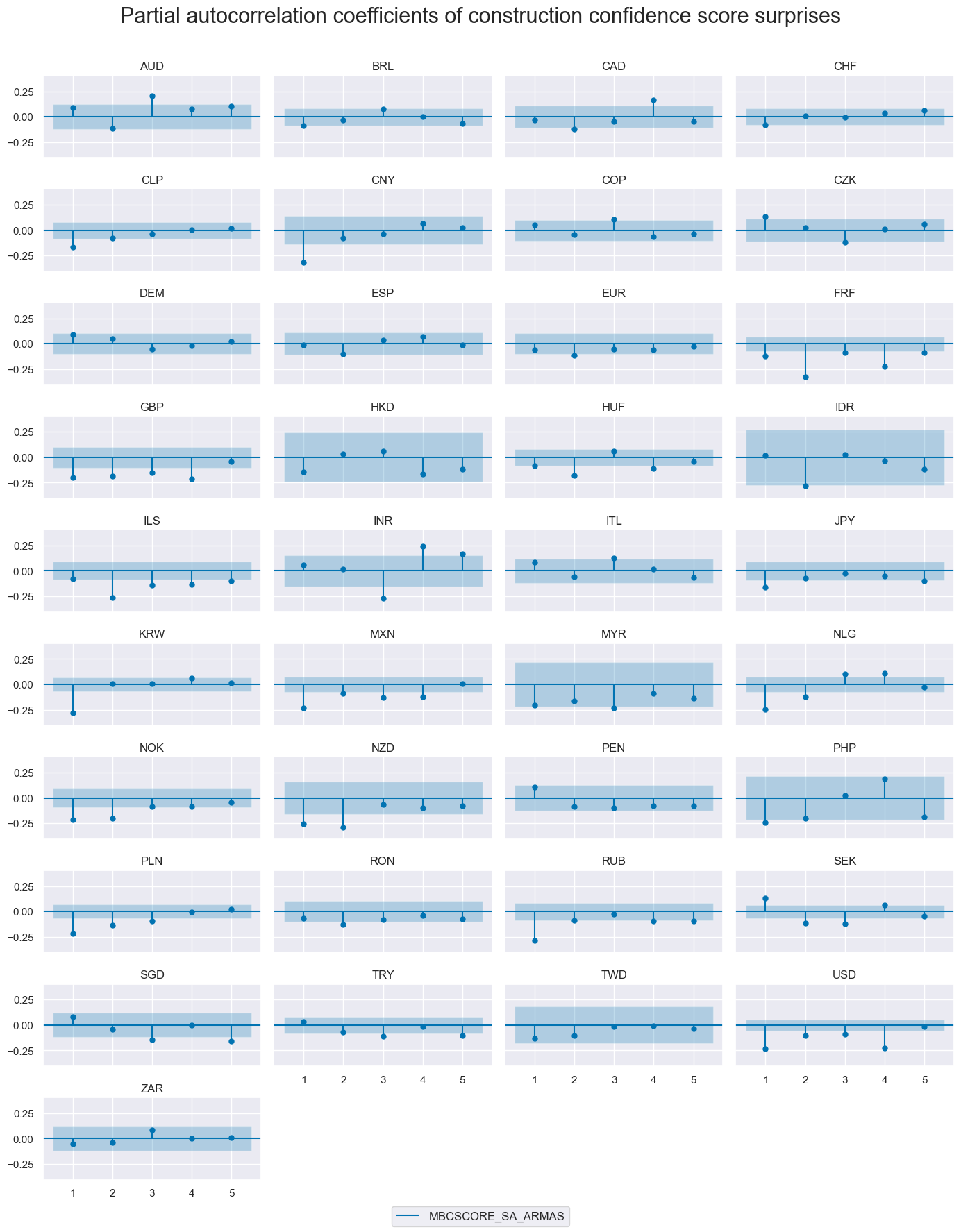
The autocorrelation (ACF) and partial autocorrelation (PACF) plots evaluate the temporal dependence of quantamental surprises across information events. Under the assumption of a well-specified prediction model of first-print releases and unbiased subsequent revisions, these surprises — interpreted as one-step-ahead forecast errors — should be serially uncorrelated.
msv.plot_pacf(
df=dfd,
cids=cidx,
xcat="MBCSCORE_SA_ARMAS",
title="Partial autocorrelation coefficients of construction confidence score surprises",
lags=5,
remove_zero_predictor=True,
figsize=(14, 18),
ncols=4
)
Importance #
Research links #
“Using survey data, we characterize directly the impact of expected business conditions on expected excess stock returns. Expected business conditions consistently affect expected excess returns in a counter-cyclical fashion. […] Our key result, of course, is that expected business conditions are a robust predictor of excess returns.” UPenn
“We find a strong link between currency excess returns and the relative strength of the business cycle. Buying currencies of strong economies and selling currencies of weak economies generates high returns both in the cross-section and time series of countries.” Macrosynergy
Empirical clues #
The information states of manufacturing confidence scores can be aggregated to a global score by using the JPMaQS series for concurrent industrial value added weights (category ticker: IVAWGT_SA_1YMA) for all available countries.
lc_xcats = [
"MBCSCORE_SA_D3M3ML3_ARMAS",
"MBCSCORE_SA_3MMA_ARMAS",
"MBCSCORE_SA_D1M1ML12_ARMAS",
]
# creating the linear composite for each of the Manufacturing categories
for xc in lc_xcats:
dfa = msp.linear_composite(
df=dfx,
xcats=xc,
cids=cids,
weights="IVAWGT_SA_1YMA",
new_cid="GLB",
complete_cids=False,
)
dfx = msm.update_df(dfx, dfa)
contracts = [c + "_CO" for c in cids_co]
bask_co = msp.Basket(df=dfx, contracts=contracts, ret="XR_NSA")
bask_co.make_basket(weight_meth="equal", basket_name="GLB_MTL")
dfa = bask_co.return_basket()
dfx = msm.update_df(dfx, dfa)
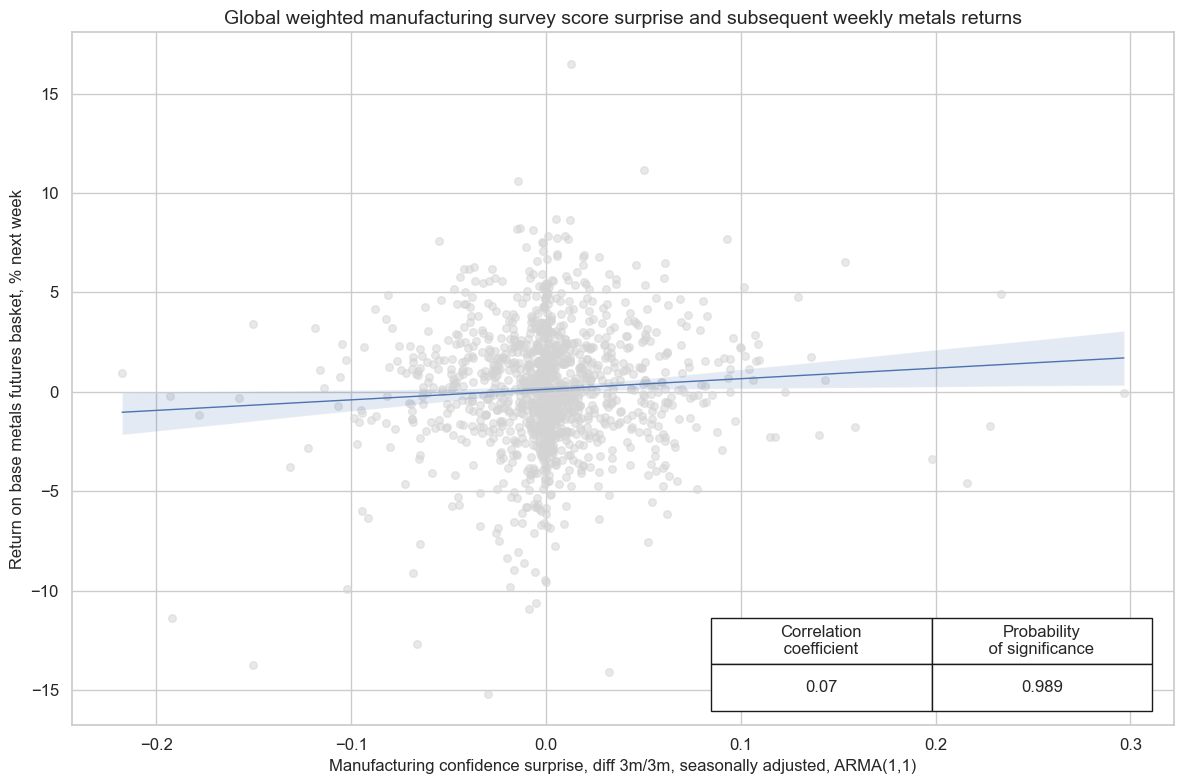
Manufacturing confidence score surprises exhibit a highly statistically significant predictive power for commodity basket returns at both weekly and monthly frequencies.
cr = msp.CategoryRelations(
dfx,
xcats=["MBCSCORE_SA_3MMA_ARMAS", "MTL_XR_NSA"],
cids=["GLB"],
freq="W",
lag=1,
xcat_aggs=["sum", "sum"],
fwin=1,
start="2000-01-01",
years=None,
xcat_trims=[0.4, 1000], # removes single distorting outlier from the plot
)
cr.reg_scatter(
title="Global weighted manufacturing survey score surprise and subsequent weekly metals returns",
labels=False,
coef_box="lower right",
xlab="Manufacturing confidence surprise, seasonally adjusted, ARMA(1,1)",
ylab="Return on base metals futures basket, % next week",
prob_est="pool",
remove_zero_predictor=True,
)
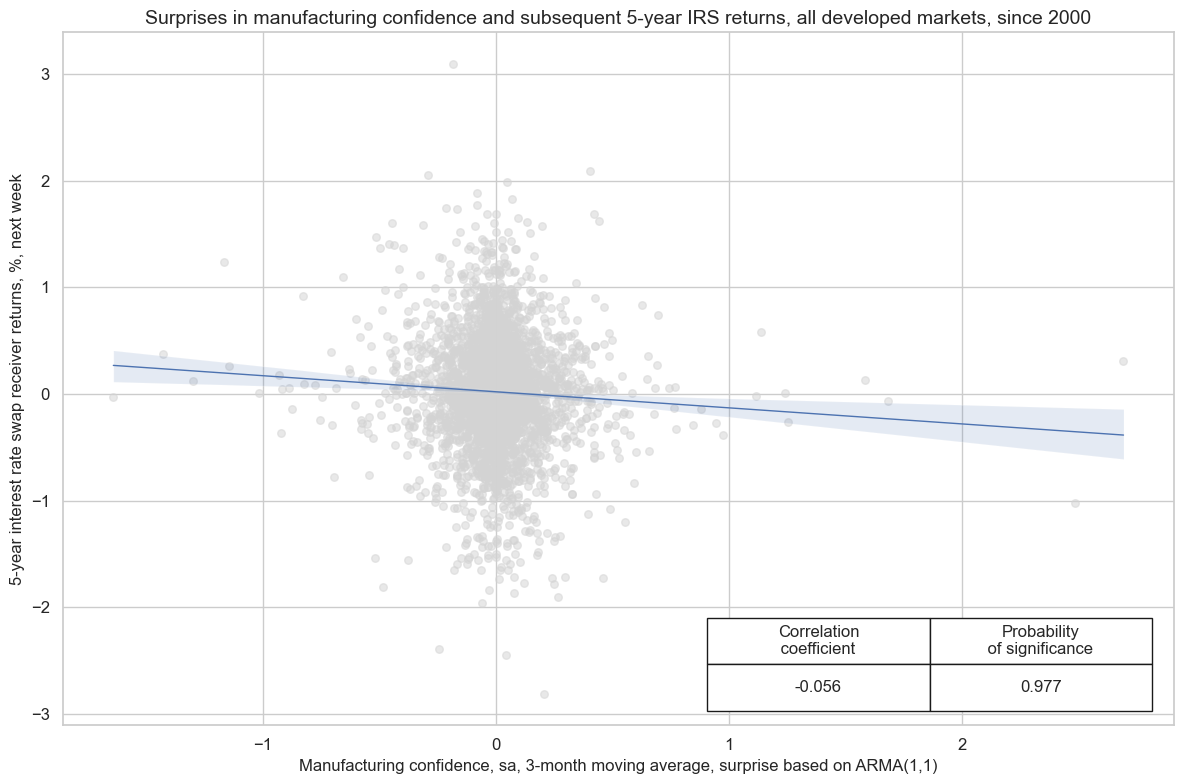
Manufacturing confidence score surprises exhibit a short-term predictive power for duration returns in developed markets. On a panel basis, 1-week ahead predictive power has been statistically significant.
cidx = cids_dmfx
cr = msp.CategoryRelations(
dfx,
xcats=["MBCSCORE_SA_3MMA_ARMAS", "DU05YXR_NSA"],
cids=cids_dmca,
freq="W",
lag=1,
xcat_aggs=["sum", "sum"],
fwin=1,
start="2000-01-01",
years=None,
)
cr.reg_scatter(
coef_box="lower right",
title="Surprises in manufacturing confidence and subsequent 5-year IRS returns, all developed markets, since 2000",
xlab="Manufacturing confidence, sa, 3-month moving average, surprise based on ARMA(1,1)",
ylab="5-year interest rate swap receiver returns, %, next week",
prob_est="map",
remove_zero_predictor=True,
)
Appendices #
Appendix 1: Currency symbols #
The word ‘cross-section’ refers to currencies, currency areas or economic areas. In alphabetical order, these are AUD (Australian dollar), BRL (Brazilian real), CAD (Canadian dollar), CHF (Swiss franc), CLP (Chilean peso), CNY (Chinese yuan renminbi), COP (Colombian peso), CZK (Czech Republic koruna), DEM (German mark), ESP (Spanish peseta), EUR (Euro), FRF (French franc), GBP (British pound), HKD (Hong Kong dollar), HUF (Hungarian forint), IDR (Indonesian rupiah), ITL (Italian lira), JPY (Japanese yen), KRW (Korean won), MXN (Mexican peso), MYR (Malaysian ringgit), NLG (Dutch guilder), NOK (Norwegian krone), NZD (New Zealand dollar), PEN (Peruvian sol), PHP (Phillipine peso), PLN (Polish zloty), RON (Romanian leu), RUB (Russian ruble), SEK (Swedish krona), SGD (Singaporean dollar), THB (Thai baht), TRY (Turkish lira), TWD (Taiwanese dollar), USD (U.S. dollar), ZAR (South African rand).
Appendix 2: Quantamental economic surprises #
Quantamental economic surprises are defined as deviations of point-in-time quantamental indicators from expected values. Expected values are estimated predictions of an informed market participant. Following this definition there are two types of surprises that jointly make up economic surprise indicators:
• A first print event is the difference between a quantamental indicator on a release date and its expected value. A release date is the day on which any underlying economic time series adds an observation period. Expected values are estimated, typically based on econometric models and information prior to the release date. A quantamental data surprise is always specific to the prediction model or statistical learning process.
• A pure revision event is the change in a quantamental indicator on a non-release date. It arises from revisions of data for previously released observation periods. Per default, it is assumed that all revisions are surprises, i.e., that the latest reported value for an observation period is the best predictor its value after revisions. Note that any revisions published on a release date become part of the first print event.
A quantamental indicator of economic surprises records the values of these two events on the dates they become known. It records zero values for all other dates. Models for predicting indicator values always use the latest vintage of the underlying data series. They are typically applied to increments, i.e., differences or log differences of volume, value or price indices. The predicted next increment produces an expected new vintage, and the expected new vintage implies a new derived expected quantamental indicator, such as an annual growth rate or moving average. Note than in this way predictions automatically account for “base effects”, i.e., predictable changes in growth rates that arise from unusually sharp increase of declines in index levels of the base period, for example a year ago.